








- Cluster Number : 集群数量
- Frontends Status : Frontend 的状态
- Backends Status : Backend 的状态

- Cluster FE JVM Heap Stat : 每个 StarRocks 集群的每个 FE 的 JVM 堆使用百分比。
- Cluster BE CPU ldle : 每个 StarRocks 集群的 BE CPU 空闲情况
- Cluster BE Mem Stat : 每个 StarRocks 集群的 BE 内存使用情况概览。

- Cluster QPS Stat : 按集群分组的 QPS 统计信息。每个集群的 QPS 是在所有FE处理的所有查询的总和。
- Disk Stat : 磁盘状态。绿色点表示该磁盘处于联机状态。红点表示该磁盘处于离线状态,处理离线状态的磁盘表示可能磁盘损坏,需要运维修复或者更换磁盘进行处理。

- FE Node:总的FE节点数
- FE Alive:当前正常的FE节点数
- BE Node:集群中BE的节点总数
- BE Alive:当前集群中正常存活的BE节点数,如果这个数量和BE Node的数量不一致说明集群中有掉线的BE节点,需要去查看处理
- Uesd Capacity:当前集群已使用的磁盘空间
- Total Capacity:集群整体存储空间

- Max Replayed journal id : StarRocks FE 的最大重播元数据日志 ID。正常Master的journal id最大,其他非Master FE节点的这个值基本保持一致,小于Master节点的这值,如果有FE节点这个值和其他节点差别特别大,说明这个节点元数据版本太旧,数据会存在不一致的情况,这种情况下可以将该节点从集群中删除,然后在作为一个新的FE节点加入进来,这样正常情况下这个值和其他节点就会保持一致。
- Image counter : StarRocks Master FE 元数据image生成计数器。并且 Image 计数器成功推送到其他非Master节点。这些指标预计会以合理的时间间隔增加通常,它们应该相等。
- BDBJE Writer : BDBJE 写入情况,正常都是毫秒级别,如果出现秒级的写入速度就要警惕了,可能会出现元数据写入延迟,严重可能会引起写入错误。BDBJE:Oracle Berkeley DB Java Edition (opens new window)。在 StarRocks 中,使用 bdbje 完成元数据操作日志的持久化、FE 高可用等功能。左侧 Y 轴显示 99th 写入延迟。右侧的 Y 轴显示日志的每秒写入次数。
- Schedulings Tablets : 开始调度运行的Tablet数量。这些 tablet 可能处于recovery 或Balance 过程中

- BE IO Util : IO Util 监控
- BE Compaction Score : 正常这个值在100以内算是正常,不过如果持续接近100这个值,说明你的集群可能存在风险,需要去关注。
这里反映的是集群中每个 BE 节点,所有 Tablet 中数据版本最多的那个 Tablet 的版本数量,可以反映出当前版本堆积情况,- 观察数据版本数量的趋势,如果趋势平稳,则说明 Compaction 和导入速度基本持平。如果呈上升态势,则说明 Compaction 速度跟不上导入速度了。如果呈下降态势,说明 Compaction 速度超过了导入速度。如果呈上升态势,或在平稳状态但数值较高,则需要考虑调整 Compaction 参数以加快 Compaction 的进度。这里需要去参考第七部分BE的 7.10小节 :Base Compaction 和 Cumulative Compaction
- 通常版本数量维持在 100 以内可以视为正常。而在大部分批量导入或低频导入场景下,版本数量通常为10-20甚至更低。

- RPS : 每个FE的每秒请求数。请求包括发送到FE的所有请求。
- QPS :每个FE的每秒查询数。查询仅包括 Select 请求。
- 99th Latency:每个FE 的 99th个查询延迟情况。

- Query Percentile:左 Y 轴表示每个FE的 95th 到 99th 查询延迟的情况。右侧 Y 轴表示每 1 分钟的查询率。
- Query Error:左 Y 轴表示累计错误查询次数。右侧 Y 轴表示每 1 分钟的错误查询率。通常,错误查询率应为 0。
- Connections:每个FE的连接数量
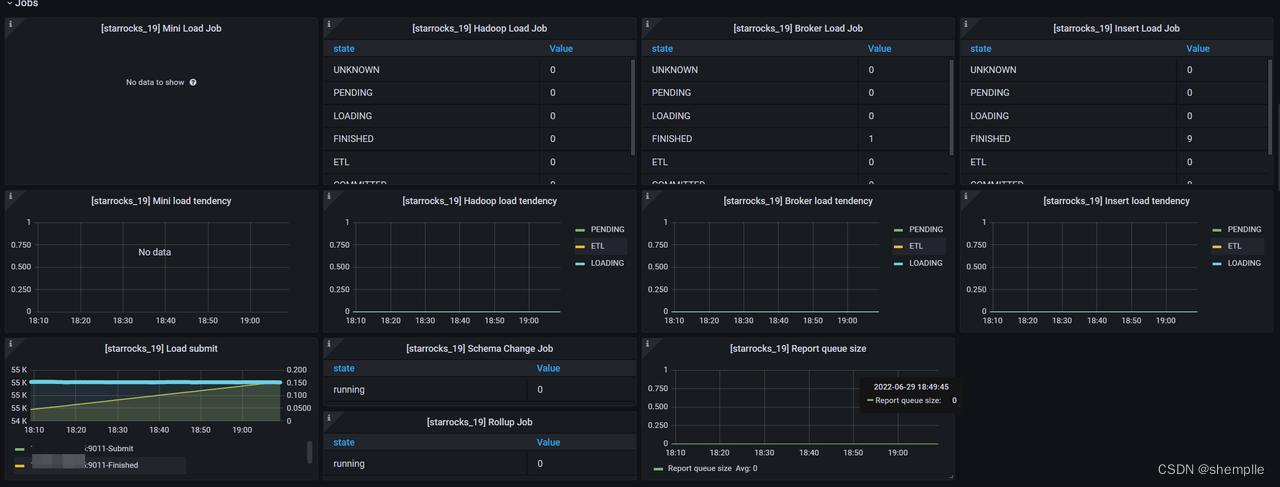
- Mini Load Job:每个负载状态下的Mini Load 作业数量的统计。这个已经慢慢废弃不再使用
- Hadoop Load Job:每个负载状态下的Hadoop Load 作业数量的统计。
- Broker Load Job :每个负载状态下的Broker Load 作业数量的统计。
- Insert Load Job : 由 Insert Stmt 生成的每个 Load State 中的负载作业数量的统计。
- Mini load tendency:Mini Load 作业趋势报告
- Hadoop load tendency:Hadoop Load 作业趋势报告
- Broker load tendency:Broker Load 作业趋势报告
- Insert Load tendency:Insert Stmt 生成的 Load 作业趋势报告
- Load submit:显示已提交的 Load 作业和 Load 作业完成的计数器。如果Load 提交是Routine 操作,则这两行显示为并行。右侧 Y 轴显示加载作业的提交率
- SC Job:正在运行的Schema 更改作业的数量。
- Rollup Job:正在运行Rollup 构建作业数量
- Report queue size:Master FE 中报告的队列大小。
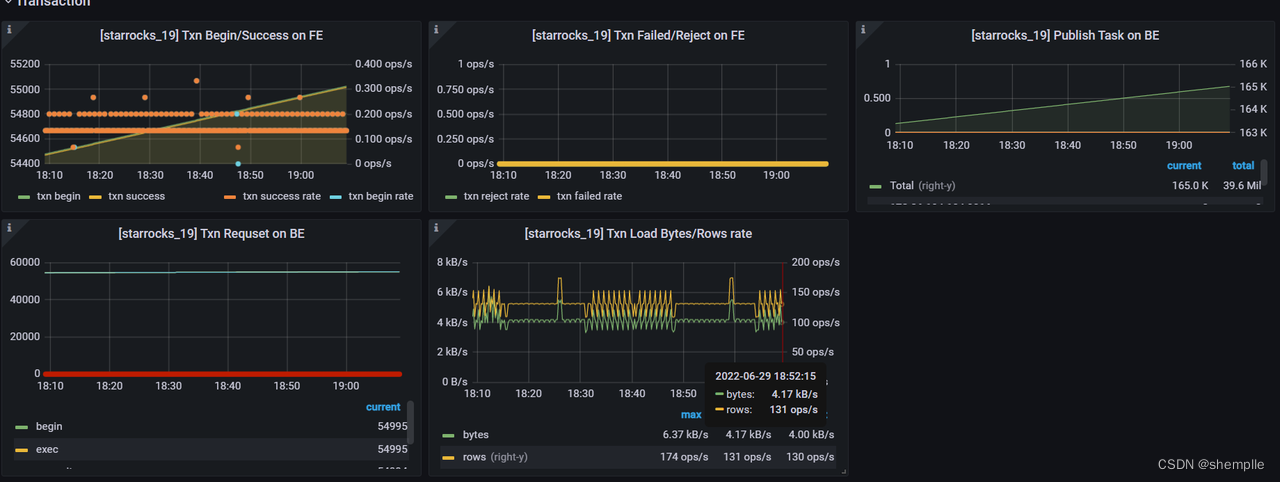
- Txn Begin/Success on FE:显示Txn 开始和成功的数量和比率
- Txn Failed/Reject on FE:显示失败的 txn 请求。包括被拒绝的请求和失败的 txn
- Publish Task on BE:发布任务请求总数和错误率。
- Txn Requset on BE:在 BE 上显示 txn 请求 这里包括:begin,exec,commit,rollback四种请求的统计信息
- Txn Load Bytes/Rows rate:左 Y 轴表示 txn 的总接收字节数。右侧 Y 轴表示 txn 的Row 加载率。

- FE JVM Heap :指定FE 的 JVM 堆使用情况。左 Y 轴显示已使用/最大堆大小。右 Y 轴显示使用的百分比。
- JVM Non Heap :指定FE 的 JVM 非堆使用情况。左 Y 轴显示使用/提交的非堆大小。
- JVM Direct Buffer :指定 FE 的 JVM 直接缓冲区使用情况。左 Y 轴显示已用/容量直接缓冲区大小。
- JVM Threads :集群FE JVM线程数

- JVM Young : 指定 FE 的 JVM 年轻代使用情况。左 Y 轴显示已使用/最大年轻代大小。右 Y 轴显示使用的百分比。
- JVM Old : 指定 FE 的 JVM 老年代使用情况。左 Y 轴显示已使用/最大老年代大小。右 Y 轴显示使用的百分比。通常,使用百分比应小于 80%。
- JVM Young GC : 指定 FE 的 JVM 年轻 gc 统计信息。左 Y 轴显示年轻 gc 的时间。右 Y 轴显示每个年轻 gc 的时间成本。
- JVM Old GC : 指定 FE 的 JVM 完整 gc 统计信息。左 Y 轴显示完整 gc 的次数。右 Y 轴显示每个完整 gc 的时间成本。

- BE CPU Idle : BE 的 CPU 空闲状态。低表示 CPU 忙。说明CPU的利用率越高
- BE Mem :这里是监控集群中每个BE的内存使用情况

- Net send/receive bytes : 每个BE节点的网络发送(左 Y)/接收(右 Y)字节速率,除了“IO”
- Disk Usage : BE节点的磁盘利用率
- Tablet Distribution : 每个BE节点上的Tablet分布情况,原则上分布式均衡的,如果差别特别大,就需要去分析原因

- BE FD count :
BE的文件描述符( File Descriptor)使用情况。左 Y 轴显示使用的 FD 数量。右侧 Y 轴显示软限制打开文件数。
FileDescriptor 顾名思义是文件描述符,FileDescriptor 可以被用来表示开放文件、开放套接字等。比如用 FileDescriptor 表示文件来说: 当 FileDescriptor 表示文件时,我们可以通俗的将 FileDescriptor 看成是该文件。但是,我们不能直接通过 FileDescriptor 对该文件进行操作。
若需要通过 FileDescriptor 对该文件进行操作,则需要新创建 FileDescriptor 对应的 FileOutputStream或者是 FileInputStream,再对文件进行操作,应用程序不应该创建他们自己的文件描述符。 - BE Thread Num BE的线程数
- Disk IO util :BE 的IO util。高表示 I/O 繁忙。

- BE BC(Base Compaction)和CC(Compaction Cumulate):
Base Compaction : BE全量压缩率,通常,基本压缩仅在 20:00 到 4:00 之间运行并且它是可配置的。右 Y 轴表示总基本压缩字节。
Compaction Cumulate: BE增量压缩率,右 Y 轴表示总累积压缩字节。
StarRocks 的 Compaction分为两种类型:base compaction和cumulative compaction。其中cumulative compaction则主要负责将多个最新导入的rowset合并成较大的rowset,而base compaction会将cumulative compaction产生的rowset合入到start version为0的基线数据版本(Base Rowset)中,是一种开销较大的compaction操作。这两种compaction的边界通过cumulative point来确定。base compaction会将cumulative point之前的所有rowset进行合并,cumulative compaction会在cumulative point之后选择相邻的数个rowset进行合并。

- BE Scan / Push:Scan Bytes:BE扫描效率,这表示处理查询时的读取率。Push Rows:BE的Load Rows效率,这表示在Load作业的 LOADING 状态下加载的行的速率。右侧 Y 轴显示集群的总推送率。

- BE Scan Rows : BE 的行扫描速率,这表示处理查询时的读取行率。
- BE Scan Bytes : BE的扫描速率,这表示处理查询时的读取字节速率。

- Tablet Meta Write : Y 轴显示了保存在rocksdb 中的tablet header 的写入速率。右侧 Y 轴显示每次写入操作的持续时间。
- Tablet Meta Read : Y 轴显示了保存在rocksdb 中的tablet header 的写入速率。右侧 Y 轴显示每次写入操作的持续时间。

- Tablet Report 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Single Tablet Report : 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Finish task report :左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。

- Push Task : 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Push Task Cost Time : 每个BE推送任务的平均消耗时间。
- Delete Task : 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。

- Base Compaction Task : 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Cumulative Compaction Task : 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Clone Task : 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。

- Create rollup task : 创建rollup的任务统计 , 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Schema Change Task : Schema 变更任务统计 , 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。
- Create tablet task : create tablet 任务统计 , 左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。














 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









