







主要内容
- MapReduce的编程
- 在集群上的运作
- MapReduce类型与格式
一、MapReduce的编程
1.设计思路
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
-
map: (k1; v1) → [(k2; v2)]
-
输入:键值对(k1; v1)表示的数据
-
处理:文档数据记录(如文本文件中的行,或数据表格中的行)将以“键值对”形式传入map函数;map函数将处理这些键值对,并以另一种键值对形式输出处理的一组键值对中间结果[(k2; v2)]
-
输出:键值对[(k2; v2)]表示的一组中间数据
-
reduce: (k2; [v2]) → [(k3; v3)]
-
输入: 由map输出的一组键值对[(k2; v2)] 将被进行合并处理将同样主键下的不同数值合并到一个列表[v2]中,故reduce的输入为(k2; [v2])
-
处理:对传入的中间结果列表数据进行某种整理或进一步的处理,并产生最终的某种形式的结果输出[(k3; v3)]
-
输出:最终输出结果[(k3; v3)]
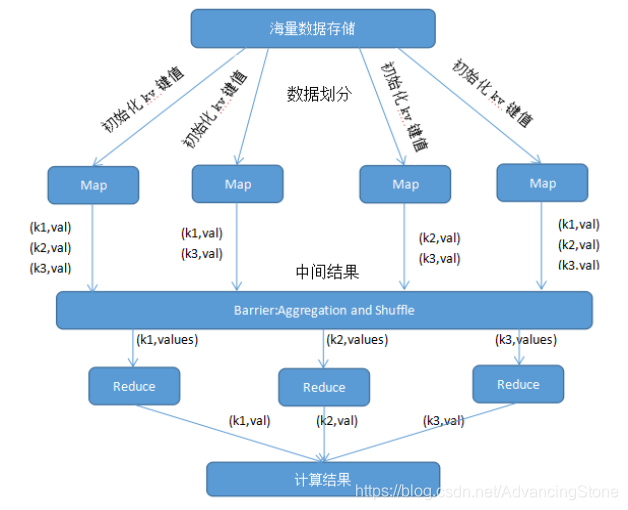
- 各个map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出
- 各个reduce也各自并行计算,各自负责处理不同的中间结果
- 数据集合进行reduce处理之前,必须等到所有的map函数做完
- 在进入reduce前需要有一个同步障(barrier)
这个阶段也负责对map的中间结果数据进行收集整理(aggregation & shuffle)处理,以便reduce更有效地计算最终结果, 最终汇总所有reduce的输出结果即可获得最终结果。
public class Sogou500wDemo {
private static class UidMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
context.write(new Text(fields[1]), new IntWritable(1));
}
}
private static class UidReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, Sogou500wDemo.class.getSimpleName());
job.setJarByClass(Sogou500wDemo.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(UidMapper.class);
job.setReducerClass(UidReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
二、在集群上的运作
1、打包作业
- 单机上运行的程序不需要任何修改就可以直接在集群上运行,但是需要把程序打包为JAR文件发给集群
- 如果每个JAR文件都有一个作业,可以在JAR文件的manifest中指定要运行的main类。如果main类不在manifest中,则必须在命令行指定。
2、启动作业
- 为了启动作业,需要运行驱动程序,使用-conf选项来指定想要运行作业的集群(同样,也可以使用-fs和-jt选项)
- 如:hadoop jar hdfs.jar hdfs://master1:9000/sogou500w hdfs://master1:9000/tmp/demo2
- JobClient的runjob()方法启动作业并检查进程,有任何变化,就输出一行map和reduce进度总结。输入如下:

3、通过web UI查看Job状态
- Hadoop的Web界面用来浏览作业信息,对于跟踪作业运行进度、查找作业完成后的统计信息和日志非常有用。
- 关于集群的概要信息,包括集群的负载情况和使用情况。这表明当前正在集群上运行的map和reduce的数量,作业提交的数量,可用的tasktracker节点数和集群的负载能力,集群中可用map和reduce的任务槽数(“Map Task Capacity”和“Reduce Task CapaciLy”),每个节点平均可用的任务槽数等信息。
YARN对job的监控

4、获取结果
一旦作业完成,有许多方法可以获取结果。每个reducer产生一个输出文件,因此,在输出的目录中会有part file,命名为part-00000。

5、查看part-r-00000文件结果如下:

6、作业调试
最经典的方法通过打印语句来调试程序,这在Hadoop中同样适用。然而,需要考虑复杂的情况:当程序运行在几十台、几百台甚至几千台节点上时,如何找到并检测调试语句分散在这些节点中的输出呢?为了处理这种情况,要查找一个特殊情况,用一个调试语句记录到一个标准错误中,它将发送一个信息来更新任务的状态信息以提示查看错误日志。Web UI简化了这个操作。
三、MapReduce类型与格式
1、MapReduce中的键值对
-
Hadoop的MapReduce中,map和reduce函数遵循如下常规格式:
map: (K1, V1) list(k2, v2)
reduce: (K2,list(v2)) list(k3, v3) -
一般来说,map函数输入的键/值的类型(K1和V1)类型不同于输出类型(K2和V2)。虽然,reduce函数的输入类型必须与map函数的输出类型相同,但reduce函数的输出类型(K3和V3)可以不同于输入类型。
-
combiner函数,它与reduce函数的形式相同(它是Reducer的一个实现),不同之处是它的输出类型是中间的键/值对类型(K2和V2),这些中间值可以输入reduce函数:
-
map: (K1, V1) list(k2, v2)
-
combine: (K2,list(v2)) list(k2, v2)
-
reduce: (K2,list(v2)) list(k3, v3)
-
combine与reduce函数通常是一样的,在这种情况下,K3与K2类型相同.V3与V2类型相同。
-
partition函数将中间的键/值对(K2和V2)进行处理,并且返回一个分区索引(partition index)。实际上,分区单独由键决定(值是被忽略的)。
-
panition: (K2, V2) integer
输入格式
1.输入分片与记录
- 层次关系是:输入分片(split)与map对应,是每个map处理的唯一单位。每个分片包括多条记录,每个记录都有对应键值对。
- 输入切片的接口:InputSplit接口(在org.apache.hadoop.mapred 包)
public interface InputSplit extends Writable{
long getLength() throws IOException;
String[] getLocations() throws IOException;
}
- 一个分片并不包含数据本身,而是指向数据的引用。存储位置供MapReduce系统使用以便将map任务尽量放在分片数据附近,而长度用来排序分片,以便优化处理最大的分片,从而最小化作业运行时间。InputSplit不需要开发人员直接处理,由InputFormat创建。
FileInputFormat类:
- FileInputFormat 是所有使用文件作为其数据源的 InputFormat 实现的基类。它 提供了两个功能:一个定义哪些文件包含在一个作业的输入中;一个为输入文件生成分片的实现。把分片分割成记录的作业由其子类来完成。
FileInputFormat.add(job, new Path(a.txt))
- FilelnputFormat 类的输入路径:
作业的输入被设定为一组路径, 这对限定作业输入提供了很大的灵活性。FileInputFormat 提供四种静态方法来设定 JobConf 的输入路径:
Public static void addInputPath(JobConf, Path path)
Public static void addInputPaths(JobConf,String commaSeparatedPaths)
Public static void setInputPaths(JobConf, Path… inputPaths)
Public static void setInputPaths(JobConf, String commaSeparatedPaths)
2、文本输入
TextlnputFormat
-
TextInputFormat 是默认的 InputFormat。每条记录是一行输入。键是 LongWritable 类型,存储该行在整个文件中的字节偏移量。值是这行的内容,不包括任何行终止符(换行符和回车符),它是 Text 类型的。所以,包含如下文本的文件:
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat. -
被切分为每个分片 4 条记录:
(0,On the top of the Crumpetty Tree)
(33,The Quangle Wangle sat,)
(57,But his face you could not see,)
(89,On account of his Beaver Hat.)
输入分片和HDFS块之间可能不能很好的匹配,出现跨块的情况
KeyValueTextlnputFormat
- TextInputFormat 的键,即每一行在文件中的字节偏移量,通常并不是特别有用。通常情况下,文件中的每一行是一个键/值对,使用某个分界符进行分隔,比如制表符。例如 以下由 Hadoop 默认 OutputFormat(即 TextOutputFormat)产生的输出。如果要正确处理这类 文件,KeyValueTextInputFormat 比较合适。
可以通过 key.value.separator.in.input.line 属性来指定分隔符。它的默认值是一个制表符。
NLineInputFormat
-
NLineInputFormat:与TextInputFormat一样,键是文件中行的字节偏移量,值是行本身。主要是希望mapper收到固定行数的输入。
-
以下是一个示例,其中一表示一个(水平方向的)制表符:
linel->On the top of the Crumpetty Tree
line2->The Quangle Wangle sat,
line3->But his face you could not see.
line4->On account of his Beaver Hat. -
与 TextInputFormat 类似,输入是一个包含 4 条记录的分片,不过此时的键是每行排在Tab 之前的 Text 序列:
(linel, On the top of the Crumpetty Tree)
(line2, The Quangle Wangle sat,)
(line3, But his face you could not see,)
(line4, On account of his Beaver Hat.)
3、多种输入
- MultipleInputs类处理多种格式的输入,允许为每个输入路径指定InputFormat和Mapper。
- 两个mapper的输出类型是一样的,所以reducer看到的是聚集后的map输出,并不知道输入是不同的mapper产生的。
- 重载版本:addInputPath(),没有mapper参数,主要支持多种输入格式只有一个mapper。
- 案例
从下列城市中统计出没有飞机场的城市
allCity.txt山东省的全部城市,someCity.txt拥有飞机场的城市


public class CityMapJoinDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//判断输入路径
if(args.length!=3 || args==null){
System.err.println("Please Input Full Path!");
System.exit(1);
}
Job job = Job.getInstance(new Configuration(), CityReducer.class.getSimpleName());
job.setJarByClass(CityReducer.class);
//通过MultipleInputs多输入的方式添加多个Map的处理类
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, AllCityMapper.class);
MultipleInputs.addInputPath(job ,new Path(args[1]), org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class, SomeCityMapper.class);
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置Reducer阶段处理的类
job.setReducerClass(CityReducer.class);
System.exit(job.waitForCompletion(true)?0:1);
}
/**
* 处理所有城市的map
* <济南,a_济南>
* <青岛,a_青岛>
* <德州,a_德州>
*/
static class AllCityMapper extends Mapper<LongWritable, Text, Text, Text>{
public static final String LABEL = "a_";
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String cityName = value.toString();
context.write(new Text(cityName), new Text(LABEL+cityName));
}
}
/**
* 处理只有飞机场的城市
* <济南,s_济南 济南飞机场>
* <青岛,s_青岛 青岛飞机场>
*/
static class SomeCityMapper extends Mapper<LongWritable, Text, Text, Text>{
public static final String LABEL = "s_";
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
String cityName = lines[0];
context.write(new Text(cityName), new Text(LABEL+value.toString()));
}
}
/**
* 经过shuffle之后变成:
* <济南,{a_济南,s_济南 济南飞机场}>
* <德州,{a_德州}>
* 青岛,{a_青岛,s_青岛 青岛机场}
*/
static class CityReducer extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//城市的名字
String cityName = null;
//存放符合条件过滤出来的城市
List<String> list = new ArrayList<String>();
for(Text value : values){
//如果列表中有包含有s_开头的数据吗,则表明该数据是已经有飞机场的城市
if(value.toString().startsWith(SomeCityMapper.LABEL)){
int index = value.toString().indexOf("_");
cityName = value.toString().substring(index+1, index+3);
} else if(value.toString().startsWith(AllCityMapper.LABEL)){
list.add(value.toString().substring(2));
}
}
//如果城市名为空并且list列表中有值,则列表中的值就是符合条件的数据
if(cityName==null && list.size()>0){
for(String str : list){
context.write(new Text(str), new Text(""));
}
}
}
}
}
小结
1、掌握MapReduce的编程,编写Mapper类,Reducer类和main类。
2、知道作业是如何在集群上运作的,打包、启动、查看结果。
3、知道如何从web UI查看Job状态。
4、掌握MapReduce的出入输出格式。
5、理解MapReduce中键值对的概念














 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









