







本文章是3.6的内容,如果想要源代码和数据可以看以下链接:
https://download.csdn.net/download/Ahaha_biancheng/83338868
3.6 统计分析
3.6.1 通用函数与运算
DataFrame对象和DataFrame、Series、标量之间的算术运算
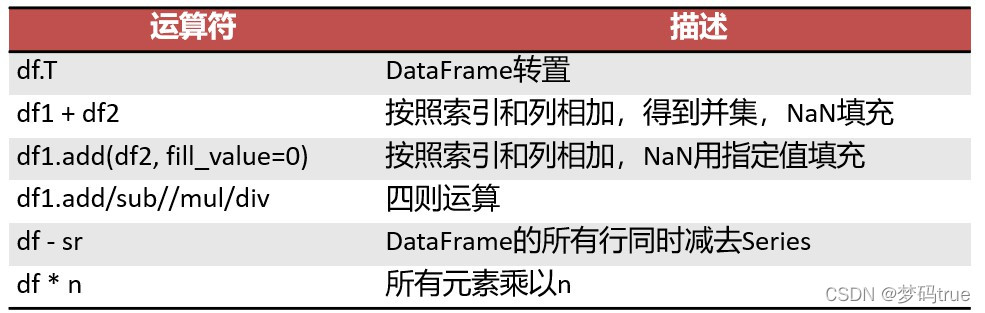
DataFrame对象中的元素级的运算,使用numpy中的通用函数

例3-15 分析例3-13中同学的“身体质量”,即BMI(Body Mass Index)指数。
世界卫生组织对于BMI的定义:BMI(kg/m2) = 体重 / 身高2
我国体质评判标准为:BMI≤18.5,过轻; 18.5-24,正常;24-28,偏胖;≥28肥胖。
计算每位学生的BMI指数,增加到原始数据对象中。
# 读取文件
stuinfo = pd.read_excel('data/studentsInfo.xlsx', index_col=0)
stuinfo[:2]
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
stuinfo['BMI'] = stuinfo['体重']/np.square(stuinfo['身高']/100)
stuinfo
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | BMI | |
|---|---|---|---|---|---|---|---|---|---|---|
| 序号 | ||||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 | 24.221453 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 | 21.913580 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 | 19.135802 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 | 22.981902 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 | NaN |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 | 23.407509 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 | 19.233561 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 | 17.908855 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 | 17.908855 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 | 26.609713 |
3.6.2 统计函数
pandas的常用统计函数

例3-16:对例3-13中学生的“成绩”、“月生活费”进行统计分析
# 计算成绩的平均值
stuinfo['成绩'].mean()
80.0
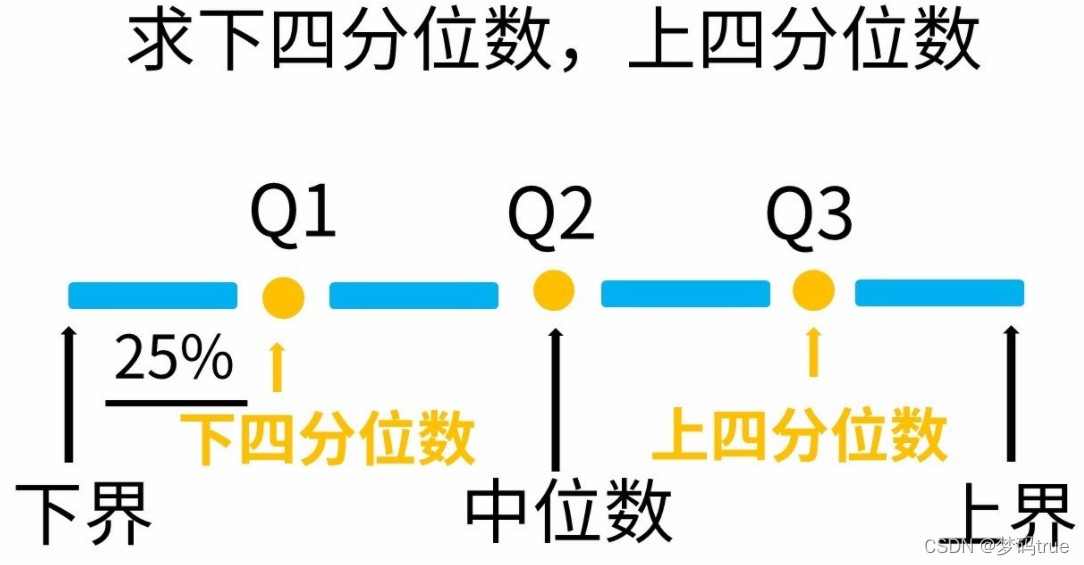
# 计算月生活费的上、下四分位数
stuinfo['月生活费'].quantile([.25, .75])
0.25 950.0
0.75 1100.0
Name: 月生活费, dtype: float64
# 描述统计函数describe() 一次计算多项统计值
stuinfo[['身高','体重','成绩']].describe()
| 身高 | 体重 | 成绩 | |
|---|---|---|---|
| count | 10.000000 | 9.000000 | 9.000000 |
| mean | 171.700000 | 63.666667 | 80.000000 |
| std | 7.071853 | 11.811012 | 10.464225 |
| min | 162.000000 | 47.000000 | 57.000000 |
| 25% | 166.750000 | 53.000000 | 78.000000 |
| 50% | 171.000000 | 70.000000 | 79.000000 |
| 75% | 178.500000 | 72.000000 | 88.000000 |
| max | 180.000000 | 76.000000 | 92.000000 |
分组
根据某些索引将数据对象划分为多个组,对每个分组进行排序或统计计算。

例3-17: 对例3-13学生数据的“身高”、“月生活费”按“性别”,“年龄”进行分组统计
# grouped.function()
stug = stuinfo.groupby(['性别','年龄'])
print(stug['体重'].mean())
stug.mean()
性别 年龄
female 20.0 47.000000
21.0 53.000000
male 19.0 76.000000
20.0 72.333333
22.0 71.000000
Name: 体重, dtype: float64
| 身高 | 体重 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | ||
|---|---|---|---|---|---|---|---|
| 性别 | 年龄 | ||||||
| female | 20.0 | 162.0 | 47.000000 | 78.000000 | 1000.000000 | 4.00 | 4.0 |
| 21.0 | 166.0 | 53.000000 | 80.000000 | 1200.000000 | 4.00 | 5.0 | |
| male | 19.0 | 169.0 | 76.000000 | 88.000000 | 1100.000000 | 5.00 | 5.0 |
| 20.0 | 174.5 | 72.333333 | 87.333333 | 883.333333 | 4.75 | 4.5 | |
| 22.0 | 180.0 | 71.000000 | 77.000000 | 1300.000000 | 3.00 | 4.0 |
# grouped.aggregate({'col1':founction1,'col2':founction2,...})
stug.aggregate({'身高': np.max, '月生活费':np.mean})
| 身高 | 月生活费 | ||
|---|---|---|---|
| 性别 | 年龄 | ||
| female | 20.0 | 162 | 1000.000000 |
| 21.0 | 166 | 1200.000000 | |
| male | 19.0 | 169 | 1100.000000 |
| 20.0 | 179 | 883.333333 | |
| 22.0 | 180 | 1300.000000 |
# grouped.aggregate([function1, function2])
stug['体重'].aggregate([np.mean, np.min])
| mean | amin | ||
|---|---|---|---|
| 性别 | 年龄 | ||
| female | 20.0 | 47.000000 | 47.0 |
| 21.0 | 53.000000 | 53.0 | |
| male | 19.0 | 76.000000 | 76.0 |
| 20.0 | 72.333333 | 70.0 | |
| 22.0 | 71.000000 | 71.0 |
统计函数crosstab()
类似Excel交叉表

按照给定的第一列分组,对第二列计数
pd.crosstab(stu['性别'], stu['月生活费'])
| 月生活费 | 800.0 | 900.0 | 950.0 | 1000.0 | 1100.0 | 1200.0 | 1300.0 |
|---|---|---|---|---|---|---|---|
| 性别 | |||||||
| female | 0 | 0 | 0 | 2 | 0 | 1 | 0 |
| male | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
3.6.3 相关性分析
作用:研究不同总体之间是否存在依存关系
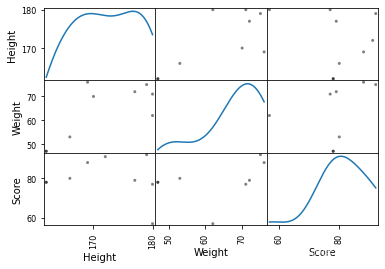
◆ 绘制散点图矩阵,直观地观察列之间的相关性
pd.plotting.scatter_matrix(data,diagonal='kde',color='k') #绘图
◆ 计算样本之间的相关系数 r 推断总体的相关程度
DataFrame相关性分析函数:DataFrame.corr()
◆ 相关系数具有以下特征
相关系数的值介于–1与+1之间;
r=1:两个总体正相关;r=0:不相关;r=-1:负相关;
|r|<0.3:低度相关;0.3≤|r|<0.8:中等相关;0.8≤|r|<1:高度相关。
当样本容量较大(≥30)时,相关性分析判断准确性较高
例3-18:学生“身高”、“体重”与“成绩”之间的相关性分析
# 两列数据之间的相关性
stuinfo['身高'].corr(stuinfo['体重'])
0.7253118364233102
1)身高与体重有一定关系,但不是很高
# 多列数据之间的相关性
stuinfo[['成绩','身高','体重']].corr()
| 成绩 | 身高 | 体重 | |
|---|---|---|---|
| 成绩 | 1.000000 | -0.180604 | 0.337735 |
| 身高 | -0.180604 | 1.000000 | 0.725312 |
| 体重 | 0.337735 | 0.725312 | 1.000000 |
2)两者都与成绩没有相关性
import matplotlib.pyplot as plt
data =stu[['身高','体重','成绩']]
data.columns=['Height','Weight','Score']
# 绘制散点图查看相关性
pd.plotting.scatter_matrix(data,diagonal='kde',color='k') #绘图
plt.show()
3.6.4 案例:调查反馈表分析
案例3-1对50名学生进行抽样调查,反馈数据保存在studentInfo.xlsx文件的5张表中。综合5组数据实现以下分析目标:
•男、女生对《数据科学》课程的兴趣程度和成绩的变化趋势;
•学生来自的省份以及性别与成绩是否存在关系;
•学生身高、体重达标状况。
步骤1:导入所需的方法库
步骤2:从Excel文件的5张表中读取数据,拼接为一个DataFrame对象
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
# 读数据
stu1 = pd.read_excel('data/studentsInfo.xlsx', 'Group1', index_col=0)
stu2 = pd.read_excel('data/studentsInfo.xlsx', 'Group2', index_col=0)
stu3 = pd.read_excel('data/studentsInfo.xlsx', 'Group3', index_col=0)
stu4 = pd.read_excel('data/studentsInfo.xlsx', 'Group4', index_col=0)
stu5 = pd.read_excel('data/studentsInfo.xlsx', 'Group5', index_col=0)
# 按行拼接
stu = pd.concat([stu1, stu2,stu3,stu4,stu5], axis=0)
stu
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
| 1 | female | 21.0 | 162 | 49.0 | YunNan | 89.0 | 800.0 | 5 | 5 |
| 2 | female | 20.0 | 164 | 53.0 | GuiZhou | 79.0 | 1000.0 | 4 | 5 |
| 3 | female | 20.0 | 166 | 43.0 | HaiNan | 12.0 | 1000.0 | 5 | 5 |
| 4 | female | 21.0 | 162 | 52.0 | TianJin | 86.0 | 500.0 | 5 | 5 |
| 5 | male | 20.0 | 175 | 73.0 | AnHui | NaN | 700.0 | 4 | 4 |
| 6 | male | 19.0 | 172 | 20.0 | ShanDong | 75.0 | 900.0 | 5 | 5 |
| 7 | male | 21.0 | 178 | 79.0 | GuiZhou | 74.0 | 650.0 | 4 | 5 |
| 8 | female | 20.0 | 163 | 54.0 | XinJiang | 79.0 | 1400.0 | 4 | 5 |
| 9 | female | 21.0 | 160 | 44.0 | ShangHai | 61.0 | 600.0 | 5 | 5 |
| 10 | female | 19.0 | 163 | 48.0 | GuiZhou | 56.0 | 700.0 | 2 | 5 |
| 21 | female | 21.0 | 165 | 45.0 | ShangHai | 93.0 | 1200.0 | 5 | 5 |
| 22 | female | 19.0 | 167 | 42.0 | HuBei | 89.0 | 800.0 | 5 | 5 |
| 23 | male | 21.0 | 169 | 80.0 | GanSu | 93.0 | 900.0 | 5 | 5 |
| 24 | female | 21.0 | 160 | 49.0 | HeBei | 59.0 | 1100.0 | 3 | 5 |
| 25 | female | 21.0 | 162 | 54.0 | GanSu | 68.0 | 1300.0 | 4 | 5 |
| 26 | male | 21.0 | 181 | 77.0 | SiChuan | 62.0 | 800.0 | 2 | 5 |
| 27 | female | 21.0 | 162 | 49.0 | ShanDong | 65.0 | 950.0 | 4 | 4 |
| 28 | female | 22.0 | 160 | 52.0 | ShanXi | 73.0 | 800.0 | 3 | 4 |
| 29 | female | 20.0 | 161 | 51.0 | GuangXi | 80.0 | 1250.0 | 5 | 5 |
| 30 | female | 20.0 | 168 | 52.0 | JiangSu | 98.0 | 700.0 | 5 | 5 |
| 31 | female | 21.0 | 162 | 45.0 | JiLin | 92.0 | 1400.0 | 5 | 5 |
| 32 | female | 20.0 | 162 | 45.0 | ChongQing | 63.0 | 650.0 | 4 | 4 |
| 33 | male | 20.0 | 171 | 64.0 | JiangXi | 77.0 | 1300.0 | 4 | 5 |
| 34 | male | 21.0 | 172 | 78.0 | BeiJing | 62.0 | 950.0 | 4 | 4 |
| 35 | male | 20.0 | 171 | 66.0 | ShangHai | 97.0 | 650.0 | 5 | 5 |
| 36 | male | 21.0 | 174 | 78.0 | GanSu | 87.0 | 1300.0 | 5 | 5 |
| 37 | male | 21.0 | 177 | 68.0 | XinJiang | 95.0 | 500.0 | 5 | 5 |
| 38 | male | 19.0 | 170 | 79.0 | YunNan | 63.0 | 1000.0 | 3 | 5 |
| 39 | female | 19.0 | 159 | 46.0 | ShanDong | 64.0 | 1100.0 | 4 | 4 |
| 40 | female | 21.0 | 163 | 52.0 | JiangXi | 62.0 | 1500.0 | 3 | 4 |
| 41 | male | 19.0 | 174 | 63.0 | HeiLongJiang | 91.0 | 600.0 | 5 | 5 |
| 42 | male | 21.0 | 177 | 73.0 | SiChuan | 89.0 | 700.0 | 4 | 5 |
| 43 | female | 21.0 | 161 | 55.0 | XiZang | 93.0 | 1250.0 | 5 | 5 |
| 44 | male | 20.0 | 171 | 63.0 | ChongQing | 82.0 | 600.0 | 4 | 5 |
| 45 | male | 20.0 | 168 | 63.0 | JiangXi | 87.0 | 800.0 | 5 | 5 |
| 46 | male | 21.0 | 174 | 73.0 | GuangDong | 71.0 | 1300.0 | 5 | 5 |
| 47 | female | 21.0 | 163 | 53.0 | ShanXi | 73.0 | 600.0 | 4 | 5 |
| 48 | male | 21.0 | 175 | 74.0 | GuangDong | 64.0 | 700.0 | 3 | 4 |
| 49 | male | 21.0 | 172 | 79.0 | ChongQing | 81.0 | 1000.0 | 5 | 5 |
| 50 | female | 20.0 | 166 | 48.0 | GuangXi | 76.0 | 1100.0 | 4 | 4 |
步骤3:去除完全重复以及缺失项较多(≥2)的数据行,检测是否还有缺失数据
# 去除重复行,且更新数据集
stu.drop_duplicates(inplace=True)
stu.dropna(thresh=8, inplace=True)
print('形状:', stu.shape)
print("是否有缺失列",stu.isnull().any())
形状: (48, 9)
是否有缺失列 性别 False
年龄 True
身高 False
体重 False
省份 False
成绩 True
月生活费 False
课程兴趣 False
案例教学 False
dtype: bool
步骤4:填充缺失值:成绩按照平均分填充;接受调查同学为二年级,用默认值“20”来填充
# 填充
# stu['年龄'].mode()
stu.fillna({'年龄':20, '成绩':stu['成绩'].mean()}, inplace=True)
步骤5:将同学数据按照“成绩”排序,统计优秀(≥90)和不合格(<60) 学生个数。并分别计算优秀与不合格同学的平均课程兴趣度,以及全体同学 课程的平均分与课程兴趣度
#按照成绩排序
stu_grade = stu.sort_values(by='成绩', ascending=False)
stu_grade
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 30 | female | 20.0 | 168 | 52.0 | JiangSu | 98.000000 | 700.0 | 5 | 5 |
| 35 | male | 20.0 | 171 | 66.0 | ShangHai | 97.000000 | 650.0 | 5 | 5 |
| 37 | male | 21.0 | 177 | 68.0 | XinJiang | 95.000000 | 500.0 | 5 | 5 |
| 21 | female | 21.0 | 165 | 45.0 | ShangHai | 93.000000 | 1200.0 | 5 | 5 |
| 23 | male | 21.0 | 169 | 80.0 | GanSu | 93.000000 | 900.0 | 5 | 5 |
| 43 | female | 21.0 | 161 | 55.0 | XiZang | 93.000000 | 1250.0 | 5 | 5 |
| 31 | female | 21.0 | 162 | 45.0 | JiLin | 92.000000 | 1400.0 | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.000000 | 950.0 | 5 | 5 |
| 41 | male | 19.0 | 174 | 63.0 | HeiLongJiang | 91.000000 | 600.0 | 5 | 5 |
| 42 | male | 21.0 | 177 | 73.0 | SiChuan | 89.000000 | 700.0 | 4 | 5 |
| 22 | female | 19.0 | 167 | 42.0 | HuBei | 89.000000 | 800.0 | 5 | 5 |
| 1 | female | 21.0 | 162 | 49.0 | YunNan | 89.000000 | 800.0 | 5 | 5 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.000000 | 1100.0 | 5 | 5 |
| 45 | male | 20.0 | 168 | 63.0 | JiangXi | 87.000000 | 800.0 | 5 | 5 |
| 36 | male | 21.0 | 174 | 78.0 | GanSu | 87.000000 | 1300.0 | 5 | 5 |
| 4 | female | 21.0 | 162 | 52.0 | TianJin | 86.000000 | 500.0 | 5 | 5 |
| 44 | male | 20.0 | 171 | 63.0 | ChongQing | 82.000000 | 600.0 | 4 | 5 |
| 49 | male | 21.0 | 172 | 79.0 | ChongQing | 81.000000 | 1000.0 | 5 | 5 |
| 29 | female | 20.0 | 161 | 51.0 | GuangXi | 80.000000 | 1250.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.000000 | 1200.0 | 4 | 5 |
| 2 | female | 20.0 | 164 | 53.0 | GuiZhou | 79.000000 | 1000.0 | 4 | 5 |
| 8 | female | 20.0 | 163 | 54.0 | XinJiang | 79.000000 | 1400.0 | 4 | 5 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.000000 | 900.0 | 4 | 4 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.000000 | 1000.0 | 4 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.000000 | 1300.0 | 3 | 4 |
| 33 | male | 20.0 | 171 | 64.0 | JiangXi | 77.000000 | 1300.0 | 4 | 5 |
| 5 | male | 20.0 | 175 | 73.0 | AnHui | 76.326087 | 700.0 | 4 | 4 |
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | 76.326087 | 800.0 | 5 | 4 |
| 50 | female | 20.0 | 166 | 48.0 | GuangXi | 76.000000 | 1100.0 | 4 | 4 |
| 6 | male | 19.0 | 172 | 20.0 | ShanDong | 75.000000 | 900.0 | 5 | 5 |
| 7 | male | 21.0 | 178 | 79.0 | GuiZhou | 74.000000 | 650.0 | 4 | 5 |
| 28 | female | 22.0 | 160 | 52.0 | ShanXi | 73.000000 | 800.0 | 3 | 4 |
| 47 | female | 21.0 | 163 | 53.0 | ShanXi | 73.000000 | 600.0 | 4 | 5 |
| 46 | male | 21.0 | 174 | 73.0 | GuangDong | 71.000000 | 1300.0 | 5 | 5 |
| 25 | female | 21.0 | 162 | 54.0 | GanSu | 68.000000 | 1300.0 | 4 | 5 |
| 27 | female | 21.0 | 162 | 49.0 | ShanDong | 65.000000 | 950.0 | 4 | 4 |
| 48 | male | 21.0 | 175 | 74.0 | GuangDong | 64.000000 | 700.0 | 3 | 4 |
| 39 | female | 19.0 | 159 | 46.0 | ShanDong | 64.000000 | 1100.0 | 4 | 4 |
| 32 | female | 20.0 | 162 | 45.0 | ChongQing | 63.000000 | 650.0 | 4 | 4 |
| 38 | male | 19.0 | 170 | 79.0 | YunNan | 63.000000 | 1000.0 | 3 | 5 |
| 40 | female | 21.0 | 163 | 52.0 | JiangXi | 62.000000 | 1500.0 | 3 | 4 |
| 26 | male | 21.0 | 181 | 77.0 | SiChuan | 62.000000 | 800.0 | 2 | 5 |
| 34 | male | 21.0 | 172 | 78.0 | BeiJing | 62.000000 | 950.0 | 4 | 4 |
| 9 | female | 21.0 | 160 | 44.0 | ShangHai | 61.000000 | 600.0 | 5 | 5 |
| 24 | female | 21.0 | 160 | 49.0 | HeBei | 59.000000 | 1100.0 | 3 | 5 |
| 3 | male | 20.0 | 180 | 62.0 | FuJian | 57.000000 | 1000.0 | 2 | 4 |
| 10 | female | 19.0 | 163 | 48.0 | GuiZhou | 56.000000 | 700.0 | 2 | 5 |
| 3 | female | 20.0 | 166 | 43.0 | HaiNan | 12.000000 | 1000.0 | 5 | 5 |
# 统计优秀和不及格人数
ex = (stu_grade['成绩']>=90).sum()
fail = (stu_grade['成绩']<60).sum()
print('优秀:'+str(ex)+' 不合格:'+ str(fail))
print('优秀:{} 不合格:{}'.format(ex,fail))
优秀:9 不合格:4
优秀:9 不合格:4
#条件表达式stu_grade[‘成绩’]>=90 得到布尔型Series对象,sum()函数统计其中True的个数
# ex = (stu_grade['成绩']>=90 )
# ex
#ex.sum()
#计算优秀成绩与课程兴趣平均值
ex_mean = stu_grade[0:9][['成绩','课程兴趣']].mean()
total_mean = stu_grade[['成绩','课程兴趣']].mean()
fail_mean = stu_grade[-4:][['成绩','课程兴趣']].mean()
print('优秀成绩平均分\n',ex_mean,'\n总成绩平均分\n',total_mean,'\n不合格成绩平均分\n',fail_mean)
优秀成绩平均分
成绩 93.777778
课程兴趣 5.000000
dtype: float64
总成绩平均分
成绩 76.326087
课程兴趣 4.208333
dtype: float64
不合格成绩平均分
成绩 46.0
课程兴趣 3.0
dtype: float64
# 计算两列相关性
stu['成绩'].corr(stu['课程兴趣'])
0.49184633480796774
步骤6:分析性别、省份与成绩是否存在相关性,由于性别和省份数据均为字符型, 无法用corr()函数来计算。简单的方法是分组计算均值:
# 按照性别分组
gen = stu.groupby(['性别'])
# 分组统计个数
gen_cnt = gen.count()
gen_cnt
| 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|
| 性别 | ||||||||
| female | 24 | 24 | 24 | 24 | 24 | 24 | 24 | 24 |
| male | 24 | 24 | 24 | 24 | 24 | 24 | 24 | 24 |
# 分组统计成绩平均值
# stu.groupby(['性别']).mean()
stu.groupby(['性别']).aggregate({'成绩':np.mean })
| 成绩 | |
|---|---|
| 性别 | |
| female | 73.666667 |
| male | 78.985507 |
sf = stu.groupby(['省份'])
sf.count()
| 性别 | 年龄 | 身高 | 体重 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|
| 省份 | ||||||||
| AnHui | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| BeiJing | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| ChongQing | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| FuJian | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| GanSu | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| GuangDong | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| GuangXi | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| GuiZhou | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| HaiNan | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| HeBei | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| HeiLongJiang | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| HuBei | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| JiLin | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| JiangSu | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| JiangXi | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| LiaoNing | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| ShanDong | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| ShanXi | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| ShangHai | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| SiChuan | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| TianJin | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| XiZang | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| XinJiang | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| YunNan | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
sf['成绩'].mean()
省份
AnHui 77.163043
BeiJing 62.000000
ChongQing 75.333333
FuJian 57.000000
GanSu 82.666667
GuangDong 67.500000
GuangXi 77.666667
GuiZhou 69.666667
HaiNan 12.000000
HeBei 59.000000
HeiLongJiang 89.500000
HuBei 89.000000
JiLin 92.000000
JiangSu 98.000000
JiangXi 75.333333
LiaoNing 78.442029
ShanDong 68.000000
ShanXi 73.000000
ShangHai 83.666667
SiChuan 75.500000
TianJin 86.000000
XiZang 93.000000
XinJiang 87.000000
YunNan 81.333333
Name: 成绩, dtype: float64
步骤7:计算同学的BMI值,找出各个四分位数,并与国家标准进行比较:
#新增BMI列
stu['BMI'] = stu['体重'] / ( np.square(stu['身高']/100) )
print( stu['BMI'].quantile( [.25,0.5,.75] ) ) #计算四分位数
print('BMI>28 肥胖人数:', (stu['BMI']>=28 ).sum() )
0.25 18.609210
0.50 20.450285
0.75 23.431521
Name: BMI, dtype: float64
BMI>28 肥胖人数: 1














 1545
1545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









