








嘿,各位科技界的狂热粉丝、AI领域的探索先锋,你们是否正站在高性能计算(HPC)的十字路口,寻找那把能开启全新纪元的钥匙?今天,就让我带你深入剖析NVIDIA的最新力作——B100与B200,一同见证它们在HPC领域掀起的革命性风暴!

SXM架构,重塑计算未来
想象一下,你的科研服务器挣脱了传统PCIe接口的束缚,拥抱了NVIDIA的SXM架构。这不仅仅是一次技术的升级,更是对高性能计算边界的勇敢探索。SXM,这个听起来就充满科技感的名词,实则是NVIDIA专为DGX和HGX系统量身打造的高带宽插座式解决方案。从P100到H100,每一代企业级计算产品的辉煌背后,都有SXM架构的默默支撑。
介绍一下 SXM,SXM 架构是一种高带宽插座式解决方案,用于将 NVIDIA Tensor Core 加速器连接到其专有的 DGX 和 HGX 系统。而 SXM 架构其实并不算 "新鲜玩意",在 NVIDIA 的每一代企业级计算产品中都是有 SXM 形态的,比如 P100、V100、A100、H100。
SXM为何能成为宠儿?
SXM之所以能在众多架构中脱颖而出,关键在于其无可比拟的效率优势。与PCIe相比,SXM在带宽互联和多GPU互联方面拥有显著的领先。这意味着,在处理大规模数据集和复杂模型时,SXM能够提供更高速、更稳定的数据传输通道,从而显著提升计算效率。此外,SXM架构还摆脱了板卡外壳的束缚,使得同样大小的机箱能够容纳更多计算卡,进一步提升了计算资源的密度和整体性能。
英伟达是在弱化 PCIe 板卡的概念,并在向 SXM 架构收敛。
SXM相对于PCIe的优势主要体现在带宽互联和体型体态上。虽然PCIe可以通过NVLInk桥接达到与SXM相近的带宽,但依然受限于PCIe总线的限制。而在多GPU互联方面,SXM具有明显的优势,特别是在处理大模型时尤为重要。此外,由于SXM没有板卡外壳,不依赖于PCIe卡槽,相同体积的机箱可以容纳更多的计算卡,从而显著提升计算卡的布置密度。因此,在构建大模型AI计算中心时,SXM架构的优势尤为明显。下面是H100 SXM的产品图。

B系列新贵:B200的璀璨登场
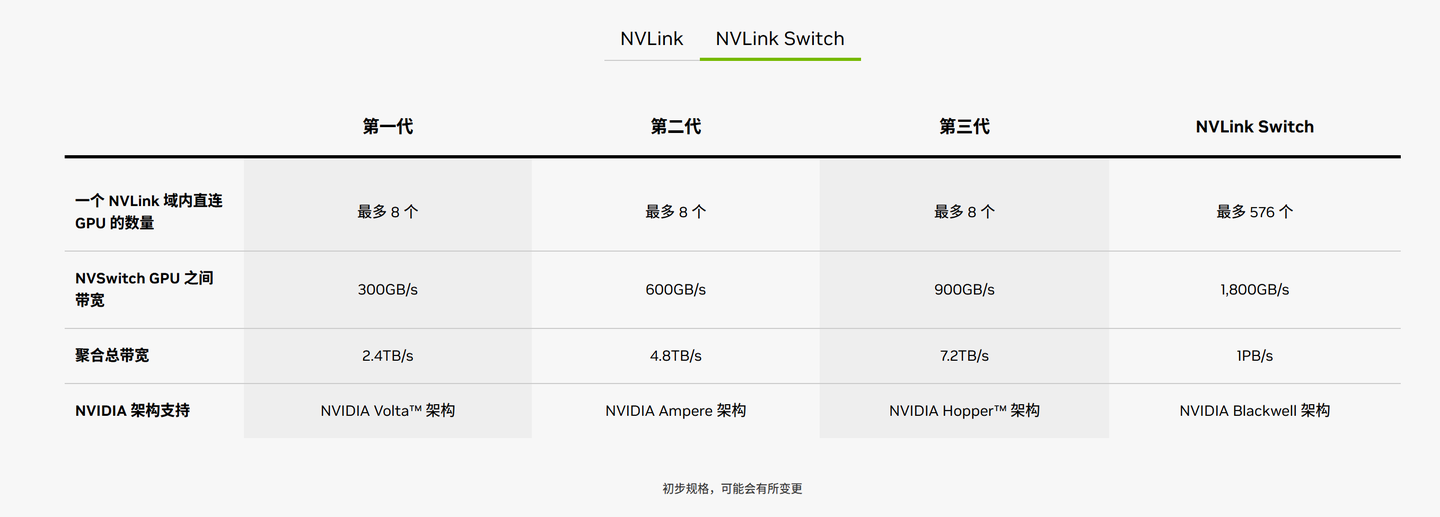
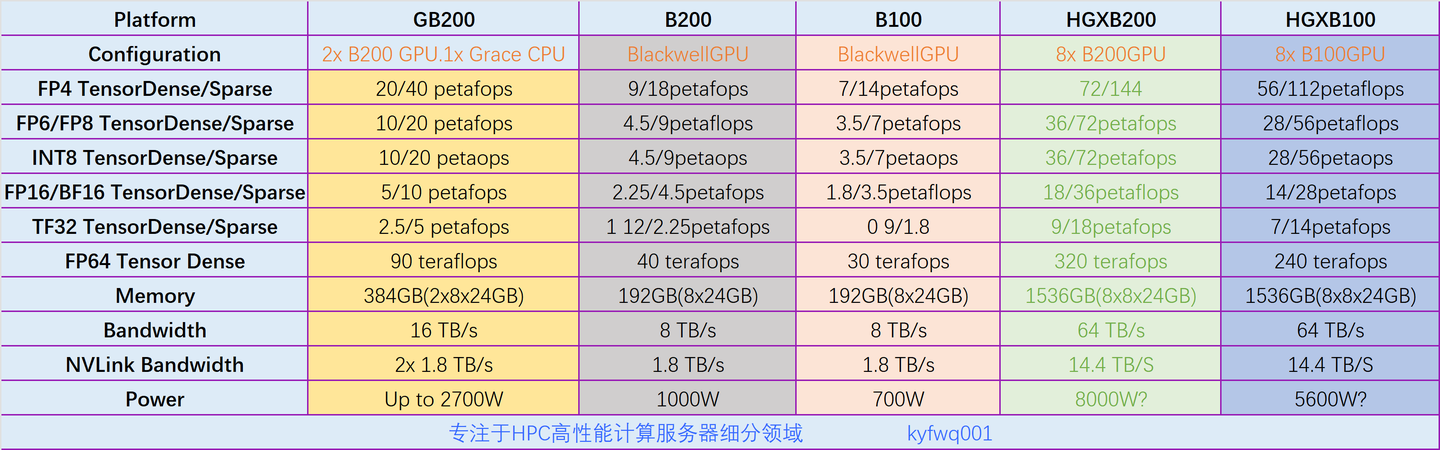
当我们还在回味B100带来的惊喜时,NVIDIA已经悄然将重心转向了B200。这不仅仅是一次简单的迭代升级,而是一次全面的性能飞跃。B200采用了先进的die-to-die架构,将两颗B100 die Chiplet紧密结合,实现了性能的显著提升。然而,B200的魅力远不止于此。从显存容量到算力表现,B200都实现了全方位的进化。特别是新增的FP4和FP6计算精度,让计算效率与精度再次迈上新的台阶。
🔍 揭秘NVIDIA的“隐藏实力”
你可能会好奇,为什么B200相比B100的算力提升并不是简单的两倍?这正是NVIDIA的“小心机”所在。他们显然在保留一部分实力,为未来预留升级空间。同时,这样的设计也让用户在现有基础上就能感受到显著的性能提升,从而更加期待NVIDIA后续的技术革新。
🎁 结语:拥抱未来,升级你的HPC
现在,你是否已经对NVIDIA B200充满了期待?作为提升计算效率的得力助手和探索AI新世界的强大引擎,B200无疑是你不可多得的选择。别再犹豫,点击下方链接了解更多详情,或者直接咨询我们的专业团队。让我们一起携手并进,开启高性能计算的新篇章!
附加知识点:B100与B200的显存与算力对比
值得一提的是,B200与B100在显存容量上保持一致,均为192GB HBM3e。这一数字不仅令人印象深刻,更彰显了NVIDIA在显存技术上的领先地位。然而,在算力方面,B200相比B100实现了全面提升,但并非简单的两倍关系。这再次印证了NVIDIA在性能优化上的深思熟虑与巧妙布局。
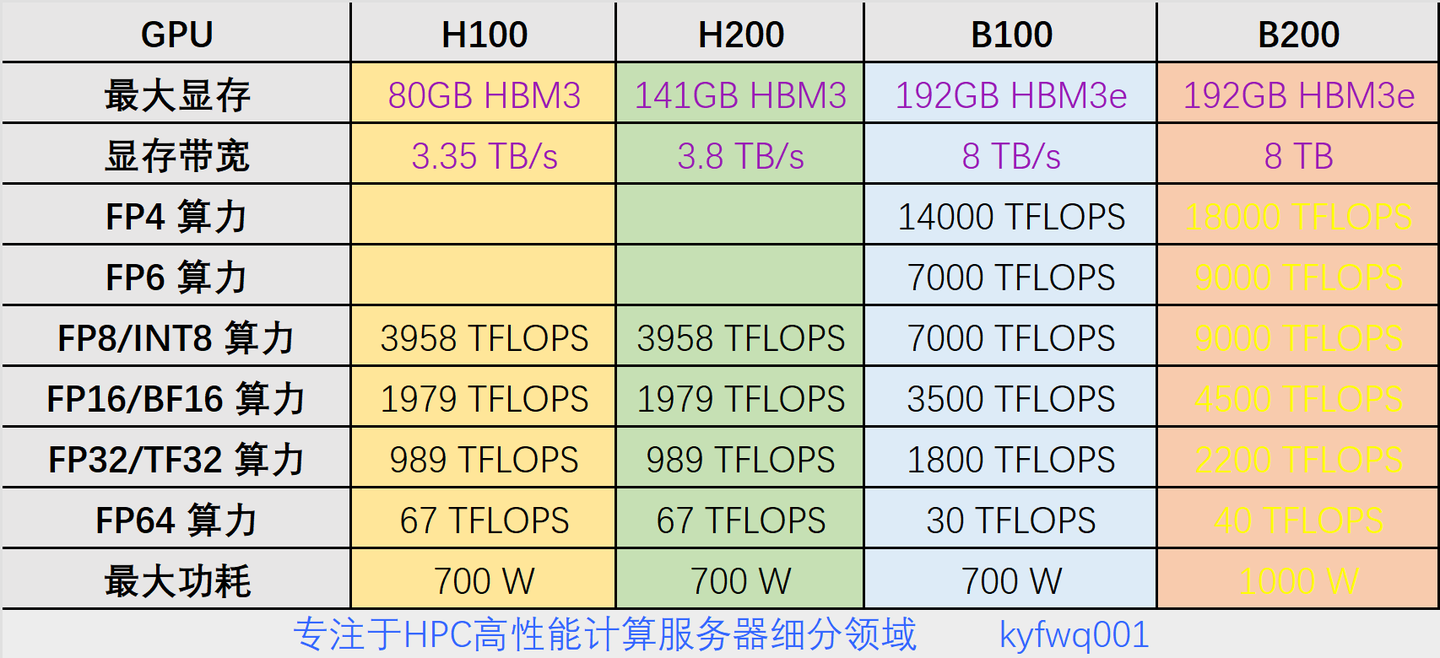
此外,我们还需要注意到Blackwell架构新增的FP4和FP6计算精度。这些新精度的引入不仅丰富了NVIDIA的计算生态体系,更为用户提供了更多样化的计算选择。在未来的AI研究和应用中,这些新精度将发挥越来越重要的作用。
原创声明:本文内容基于公开信息及个人理解整理而成,旨在为读者提供有价值的科技资讯与见解。我们尊重原创精神并致力于维护网络环境的健康与和谐。欢迎转发分享本文内容但请务必注明出处以尊重原作者的劳动成果。

一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
如何制造出比英伟达更好的GPU? - 知乎 (zhihu.com)
SLAM究竟是什么?让你从0到1了解SLAM - 知乎 (zhihu.com)

添加图片注释,不超过 140 字(可选)
Nvidia B100/B200/GB200 关键技术解读 - 知乎 (zhihu.com)
大模型训练推理如何选择GPU?一篇文章带你走出困惑(附模型大小GPU推荐图) - 知乎 (zhihu.com)
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
AI核弹B200发布:超级GPU新架构30倍H100单机可训15个GPT-4模型,AI进入新摩尔时代 - 知乎 (zhihu.com)
紧跟“智算中心”这波大行情!人工智能引领算力基建革命! - 知乎 (zhihu.com)
先进计算技术路线图(2023) - 知乎 (zhihu.com)
建议收藏!大模型100篇必读论文 - 知乎 (zhihu.com)
马斯克起诉 OpenAI:精彩程度堪比电视剧,马斯克与奥特曼、OpenAI的「爱恨纠缠史」 - 知乎 (zhihu.com)
2023第一性原理科研服务器、量化计算平台推荐 - 知乎 (zhihu.com)
Llama-2 LLM各个版本GPU服务器的配置要求是什么? - 知乎 (zhihu.com)
人工智能训练与推理工作站、服务器、集群硬件配置推荐

整理了一些深度学习,人工智能方面的资料,可以看看
机器学习、深度学习和强化学习的关系和区别是什么? - 知乎 (zhihu.com)
人工智能 (Artificial Intelligence, AI)主要应用领域和三种形态:弱人工智能、强人工智能和超级人工智能。
买硬件服务器划算还是租云服务器划算? - 知乎 (zhihu.com)
深度学习机器学习知识点全面总结 - 知乎 (zhihu.com)
自学机器学习、深度学习、人工智能的网站看这里 - 知乎 (zhihu.com)
2023年深度学习GPU服务器配置推荐参考(3) - 知乎 (zhihu.com)

多年来一直专注于科学计算服务器,入围政采平台,H100、A100、H800、A800、L40、L40S、RTX6000 Ada,RTX A6000,单台双路256核心服务器等。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









