







A、简介
1. HBase是Apache提供的一个基于Hadoop的、开源的、分布式的、可扩展的非关系型数据库 - 目标是存储billions of rows * millions of columns
2. HBase是Doug根据Google的实现的
3. HBase不同于关系型数据库,采用的是列存储的思想
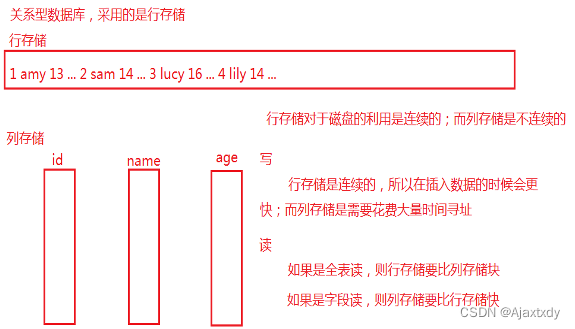
4. HBase的单机模式是利用了本地文件系统来存储数据;如果是伪分布式和完全分布式则利用HDFS来存储数据 - HBase的完全分布式+Hadoop的伪分布式 + Zookeeper的完全分布式
5. HBase不支持SQL
6. HBase适合于存储稀疏数据 - 半结构化数据,例如json
7. 一个表如果需要删除,那么需要先禁用这个表然后再删除
8. HBase是基于Hadoop存储数据的,本质上就是基于HDFS来存储数据。 HDFS的特点是一次写入多次读取不支持修改。HBase作为数据库,提供了完整的增删改查的能力,如何实现"改"的能力? - HBase在添加每一条数据的时候都会附带时间戳,时间戳称之为是数据的VERSION。当需要修改数据的时候,在HDFS上实际上并不是修改原始数据而是在文件尾部追加数据,在进行查询的时候默认获取版本最新的数据。默认情况下,数据在获取的时候只能获取一个版本
9. 表在建好之后,数据的版本个数就固定了,所以需要在建表的时候指定数据能够获取的版本个数
10. 行键+列+版本能够锁定唯一的一条数据 - cell。一个cell中包含一条数据
二、基本概念
1. Rowkey - 行键:
a. 行键类似于MySQL中的主键
b. 行键在建表的时候不需要指定,而是在添加数据的时候动态指定
c. 行键默认是字典序排序
2. Column family - 列族/列簇:
a. 列族类似于传统关系型数据库中的单个表
b. 一个表中至少要包含一个列族,可以包含多个列族
c. 一个列族中可以包含0到多个列,在建表的时候只需要指定列族即可,列可以在添加数据的时候动态增删
d. 列族在建表的时候需要指定,指定之后就不能更改
e. 理论上一个表中不限制列族的数量,但是实际过程中一个表中一般不超过3个列族
3. namespace - 名称空间
a. 作用类似于MySQL中的database
b. 用于区分同名表
c. 如果在建表的时候没有指定表所在的namespace,那么默认使用的default的namespace中
d. 如果需要删除某个名称空间,则需要删除其中所有的表
B、细节
一、HRegion
1. 从行键方向上,将表进行了划分,划分为了1个或者多个HRegion
2. HRegion中的数据不会产生交叉 - 行键是有序的
3. 每一个HRegion会交给一个HRegionServer来进行管理 - HRegionServer之间的数据也不会产生交叉
4. 划分HRegion的目的是为了提高HBase的吞吐量
5. 当HRegion大小达到一定限度(默认是10G,这个值可以在1~20G的范围内调节)的时候,HRegion会产生分裂,均分为2个HRegion,其中的一个HRegion会转移到其他的HRegionServer上 - HRegion的数据最终是落地在HDFS上,HRegionServer负责管理HRegion,所以所谓的将一个HRegion转移到另一个HRegionServer上实际上不是数据产生转移,只是管理权产生了转移
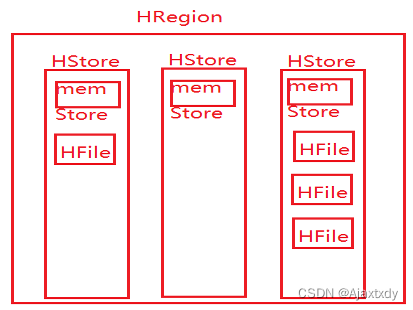
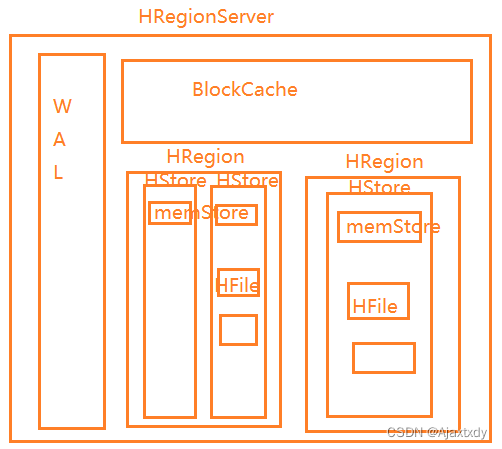
6. HRegion包含一个到多个HStore,HStore的个数由列族的数量来决定
7. 每一个HStore包含1个memStore以及0到多个StoreFile/HFile
二、Zookeeper在HBase中的作用
1. HBase启动的时候会在Zookeeper上注册一个/hbase节点
2. HRegionServer在Zookeeper的/hbase/rs节点下注册一个临时节点
3. Active HMaster会在Zookeeper上注册一个临时节点/hbase/master;Backup HMaster会在/hbase/backup-masters来注册临时子节点
4. Active HMaster实时监控/hbase/backup-masters下边子节点的变化,当某个Backup HMaster宕机,那么这个HMaster对应的临时节点就消失,那么Active HMaster就监控到这个节点的丢失,那么就不需要再和这个节点进行数据同步;如果发现/hbase/backup-masters多了子节点,那么说明新增了Backup HMaster,那么需要进行数据的同步
5. Backup HMaster实时监控/hbase/master节点,如果发现这个节点丢失了,则说明Active HMaster宕机,那么会自动从Backup HMaster中选取一个切换为Active状态
三、HMaster
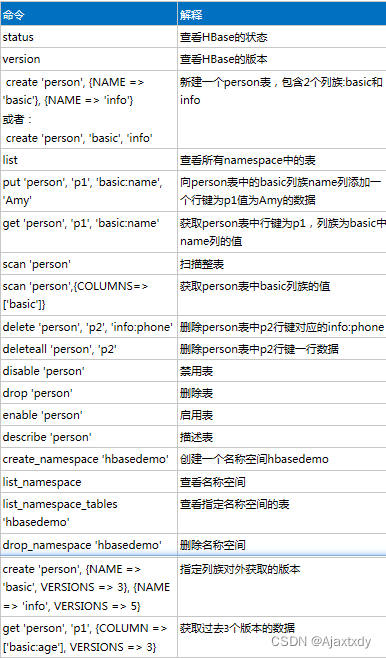
1. HBase中,HMaster节点不存在单点故障的说法,可以在任何一个HBase节点上启动HMaster - sh hbase-daemon.sh start master
2. HMaster的状态由启动顺序来决定。哪个节点先启动HMaster,那么这个节点就是Active状态,后启动HMaster的节点自动成为Backup状态
3. 虽然理论上不限制Backup HMaster的个数,但是实际过程中Backup HMaster一般不超过2个
4. 如果是对表结构进行操作,那么这个操作会经过HMaster(create/drop/ disable/enable/list),而如果是对表中的数据进行操作,这些操作不经过HMaster(put/delete/deleteall/get/scan) - HMaster的作用之一是对表结构进行管理
5. HMaster负责管理HRegionServer
四、数据的读写流程
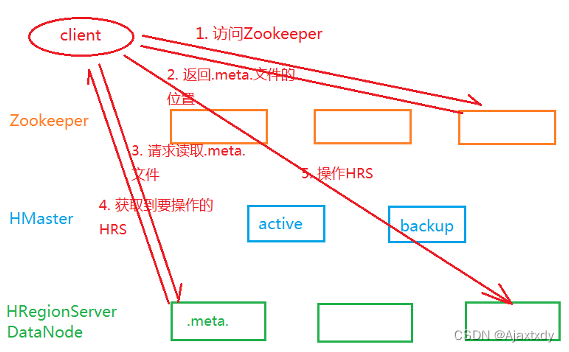
1. HBase0.96之前
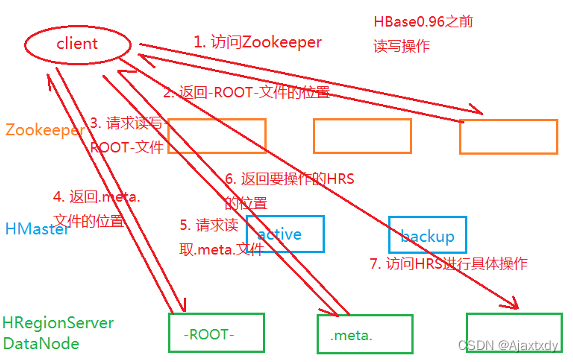
2. HBase0.96开始
a. 减少了访问-ROOT-文件的步骤
b. 客户端在第一次访问Zookeeper之后,自动缓存.meta.文件的位置 - Zookeeper中通过/hbase/meta-region-server节点来存储.meta.文件的位置
c. 每一个HRegion都把持了起始行键和结束行键,每一个HRegionServer也记录了HRegion的起始和结束行键 - 客户端也会自动缓存访问过的HRegion所在的HRegionServer - 如果发生了HRegion的转移或者客户端宕机,那么建立的缓存是无效的
五、HRegionServer
1. HRegionServer的职责是管理HRegion,每一个HRegionServer能够管理1000个HRegion
2. HRegionServer由WAL、BlockCache、HRegion组成的:
a. WAL/HLog:Write Ahead Log。
i. 当HRegionServer接受到写操作的时候,会先将写操作记录到WAL中,如果记录成功则将操作更新到memStore中,如果memStore达到一定条件之后会将数据冲刷到StoreFile中。这样设计的目的是保证数据不丢失
ii. WAL的清理需要适当的时机
b. BlockCache - 读缓存
i. 读缓存是维系在内存中,读缓存大小是128M
ii. 采用了"局部性"原理:局部性原理本质上就是在提高猜测的命中率
1) 时间局部性:在HBase中,如果一条数据被读取了一次,那么HBase会认为这条数据被读取第二次的概率会比其他的数据读取第一次的概率要大,那么此时HBase会将这条数据放入读缓存中 - 读过的数据就会放入缓存
2) 空间局部性:如果一条数据被读取,那么HBase会认为与这条数据相邻的数据被读取的概率会比其他数据被读取的概率大,那么此时与这条数据相邻的数据就会放入缓存中
iii. 采取了LRU策略 - 清理最早或者最长时间不用的数据
iv. 读缓存能够有效的提高读取效率,但是在扫描整表的时候不建议使用读缓存
C、流程
一、写流程
1. 当HRegionServer接受到写请求的时候,会将这个请求先记录到WAL中
2. WAL记录成功之后会写到memStore中,memStore是维系在内存中
3. 数据在memStore中会进行排序:行键字典序 - 列族名字典序 - 列名字典序 - 时间戳倒序
4. memStore达到一定条件的时候会冲刷到StoreFile中
a. 当memStore的大小达到128M的时候会产生冲刷
b. 当WAL达到1G的时候会产生一个新的WAL,memStore也会产生冲刷
c. 当HRegionServer上所有memStore所占内存之和达到物理内存的35%的时候,会冲刷较大的memStore
5. 单个StoreFile中的数据是有序的,但是所有的HFile是局部有序
6. HFile最终落地在HDFS上
7. HFile的结构包含6个部分:
a. DataBlock:存储的是具体的数据
i. 包含Magic和KeyValue
1) Magic称之为魔数,本质上就是一个随机数,用于进行校验
2) 实际的数据是存储在KeyValue中
ii. 默认情况下DataBlock大小是64K
iii. 每一个DataBlock都会记录当前块中的起始行键和结束行键
iv. 小的DataBlock便于查找;大的DataBlock便于遍历
v. 在HBase,DataBlock才是最小存储单位
vi. 读缓存的空间局部性是以DataB lock为单元来进行的 - 如果某个DataBlock中的数据被读取,那么整个DataBlock就会放入读缓存中
b. MetaBlock:存储的是元数据。并不是每一个HFile都有这一部分,一般只有.meta.文件中会包含这一部分
c. File Info:对HFile的描述信息
d. Data Index:对DataBlock的索引。记录了每一个DataBlock的起始字节
e. Meta Index:对MetaBlock的索引。记录了每一个MetaBlock的起始字节
f. Trailer:记录Data Index和Meta Index的起始位置。这个Trailer固定是4个字节
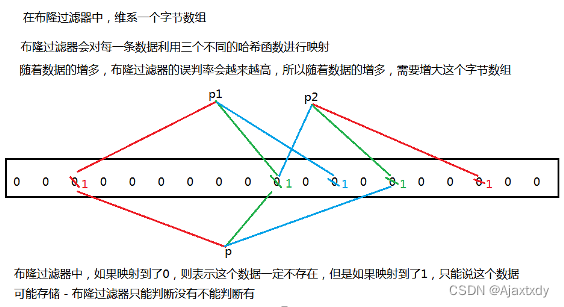
8. 在HFile的V2版本中,引入了Bloom Filter - 布隆过滤器
二、读取流程
1. 客户端通过元数据锁定唯一的一个HRegionServer。先从HRegionServer的BlockCache读数据,如果没有则从memStore中读取
2. 如果memStore中也没有,则从HFile中读取
3. 从HFile中读取的时候,会先利用行键范围先筛选掉不符合的HFile,然后利用布隆过滤器再次筛选,筛选掉不符合的HFile
D、API操作
package cn.Ajaxtxdy.hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6854
6854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









