






 本文介绍了如何使用Python爬虫技术,特别是正则表达式,从快代理网站动态加载的JavaScript数据中抓取IP和Port。作者分享了实战代码,以及在爬取过程中需要注意的事项,如请求间隔和正确定位数据源。
本文介绍了如何使用Python爬虫技术,特别是正则表达式,从快代理网站动态加载的JavaScript数据中抓取IP和Port。作者分享了实战代码,以及在爬取过程中需要注意的事项,如请求间隔和正确定位数据源。
python爬取快代理
快代理的网络地址: https://www.kuaidaili.com/free/inha/
任务要求:爬取代理的ip和port,并且将他们写入一个文件当中
一、对网站进行解析
在此使用的是chrome浏览器自带的抓包工具
在进入快代理的网页之后,右键点击,在弹出胡选项框中点击检查,在elements中可以看到想要的数据在一个“table”标签当中,一共有12条数据,每一条数据都在“table”标签下的“tbody”标签之下的“td” 标签之中。于是我便用requests.get()请求,但是当我使用bs4解析请求到的网页源代码时发现找不到“table”标签。
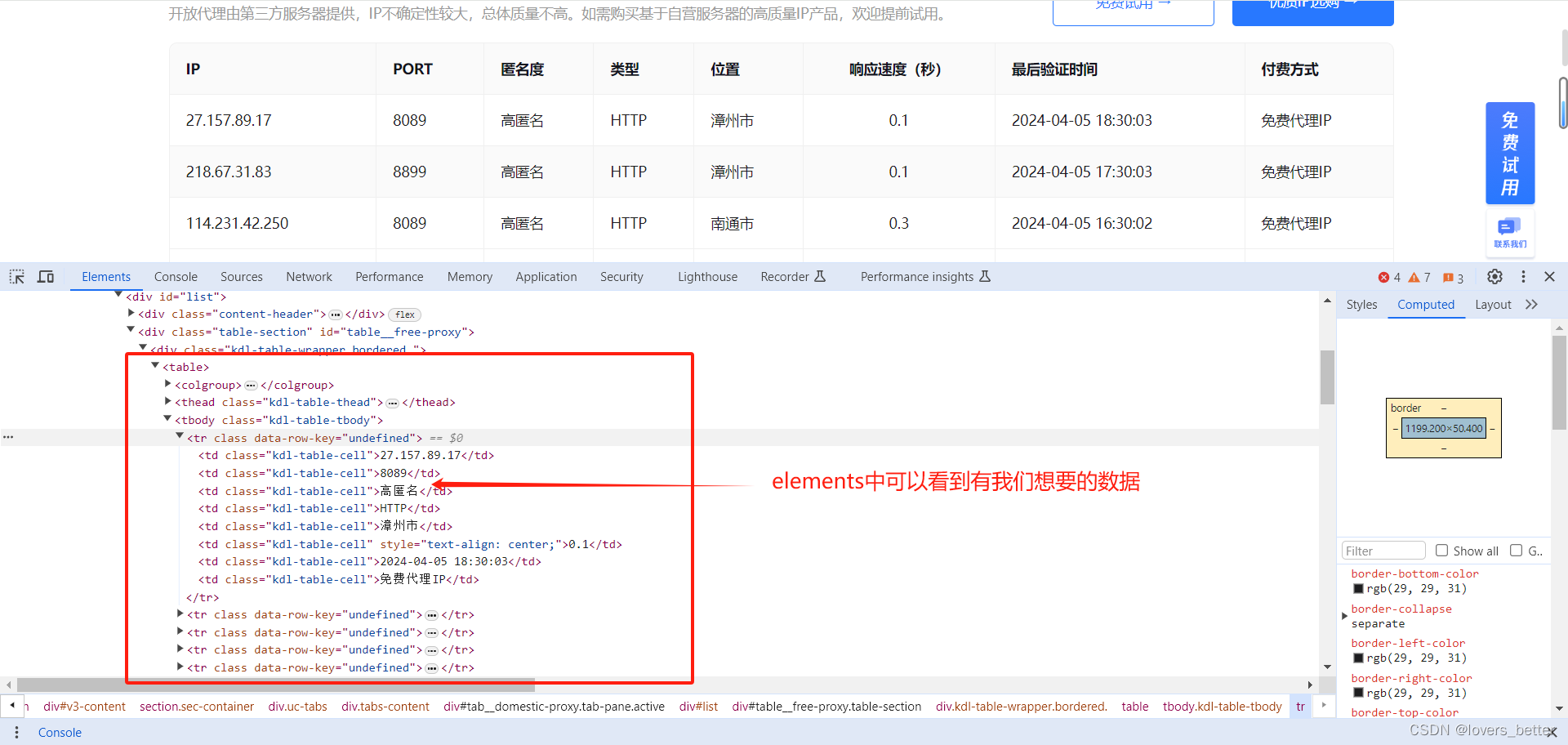
当我再次右击该网页,并且在弹出的选项卡中选择 “查看网页源代码”时,发现源代码当中并没有"table"标签,复制了一条数据,并且crl + F 然后搜索,发现数据竟让出现在网页的"script"标签当中,这才意识到,数据不是写死的,而是通过javascrip代码填充上的。
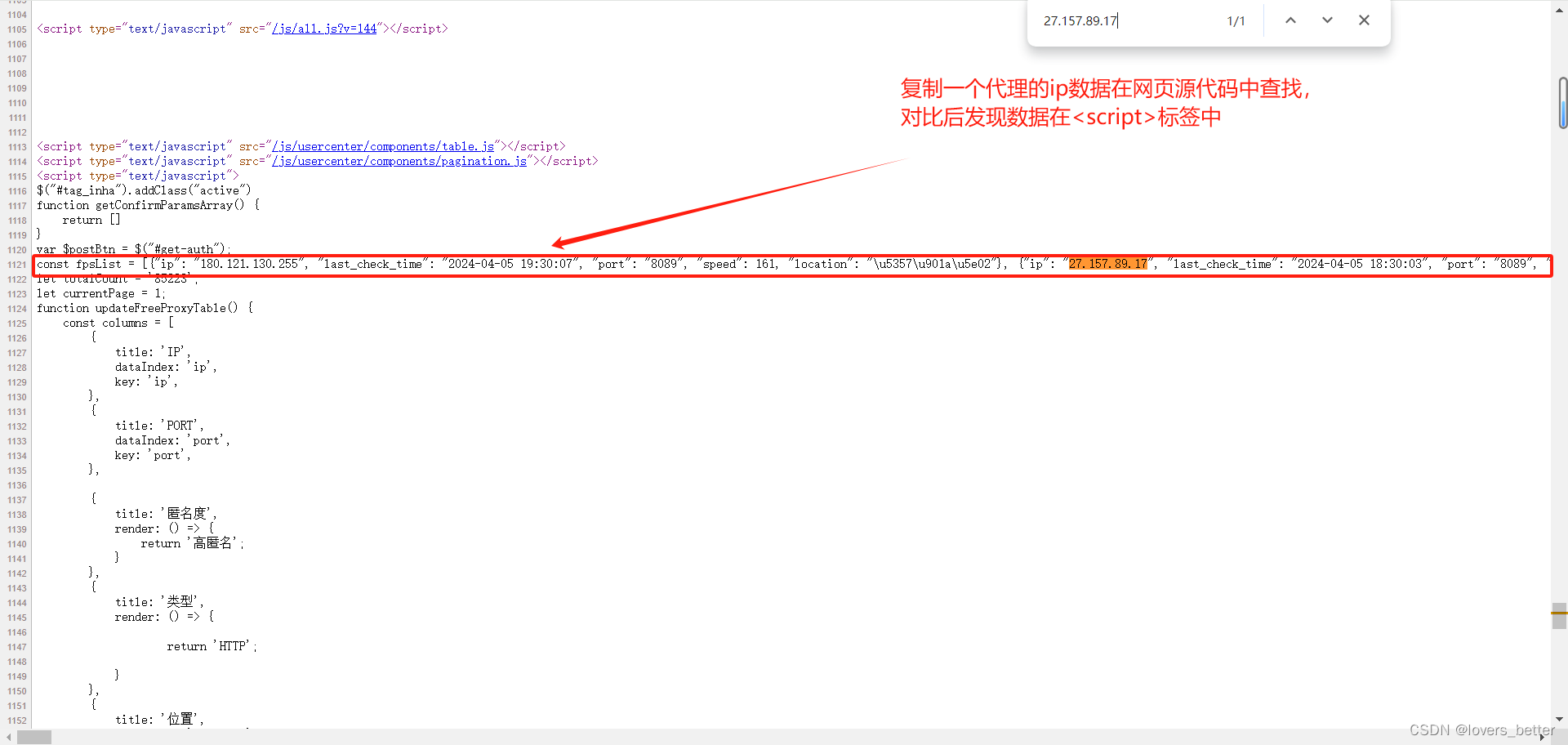
数据存在于javascript中,并且该网页有多个“script"标签,且该标签中间包含了大量的文本内容。我本来打算使用bs4对爬取到的内容进行数据解析,但是通过分析之后我决定选择使用python的正则表达式(re)进行提取,因为“script"标签当中的内容量比较大,然而无论是bs4还是xpath解析,都适用于对html的标签进行操作,而不是对标签中的内容进行提取操作。无疑选择正则表达式是最合理的。
二、代码实战与注意事项
2.1 实战代码
本次的实战代码如下:
import requests,re
import time
def getinfo(page):
# 请求地址
url = f"https://www.kuaidaili.com/free/inha/{page}/"
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
response = requests.get(url,headers=headers)
# 设置编码
response.encoding="utf-8"
# 准备匹配规则
rule = r'"ip": "(.*?)".*?"port": "(.*?)"' # 忽略了:后的空格让我找了半天
# 根据规则匹配数据 匹配到的形式是:[(ip,port),(ip,port),...,(ip,port)]
matchs_list = re.findall(rule,response.text,re.S)
print(f"获取第{page}页数据")
# 在文件中写入是具体几页数据
file.write(f"第{page}页数据:\n")
for ip,port in matchs_list:
# 在文件当中写入,ip和端口号
file.write(f"{ip}:{port}\n")
print(f"ip为{ip},端口号为{port}")
print("-" * 20)
# 控制爬取页数 1-5
if __name__ == "__main__":
# 在同级目录之下创建文件用于存储数据
file = open("./ip.txt", "w")
# 调用 getinfo 函数依次请求每一页数据
for i in range(1,11):
getinfo(i)
# 设置请求间隔为1s,防止请求过于频繁遭到服务器拒绝
time.sleep(1)
# 关闭文件
file.close()
通过以上的代码,我们可以爬取快代理前十页代理的ip和port,并且存储在一个文件中。
2.2 注意事项
以下主要讲述了我,在分析和爬取过程当中所遇到的问题,希望它能够帮助大家:
- 请求时注意请求的间隔,避免由于频繁的访问而遭到服务器拒绝。time.sleep()用上,本人就是请求的 过于频繁了,发现数据一页一页的爬都可以,若一次爬多页就只能请求成功一次,后面就失败了。
- 请求前务必确定自己想要数据在哪里,确定是资源在哪一个url之下。
- 分析错误,在编写代码的时候务必认真查看请求所获取的数据内容再尝试进行数据分析操作。
- 在使用正则表达式的时候务必注意空格,空格也是会被匹配的。(本人就是在写正则的时候忽略了空格,结果什么也没匹配上)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









