







闲鱼平台API,item_app 获得闲鱼原生数据
num_iid:闲鱼商品ID
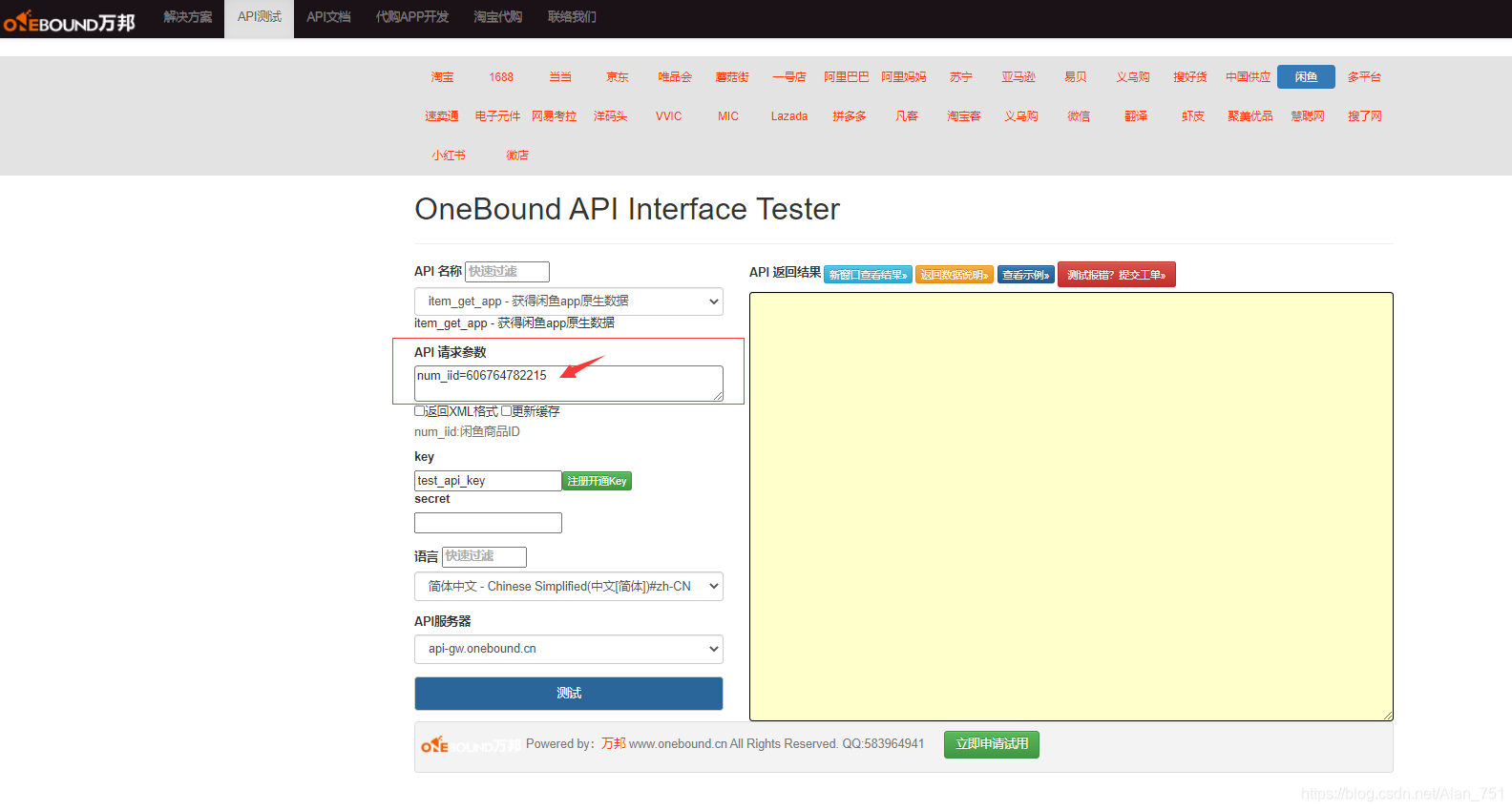
点击获取key和secret*
当你有了账号时候点到测试页面,下面是我测试的结果
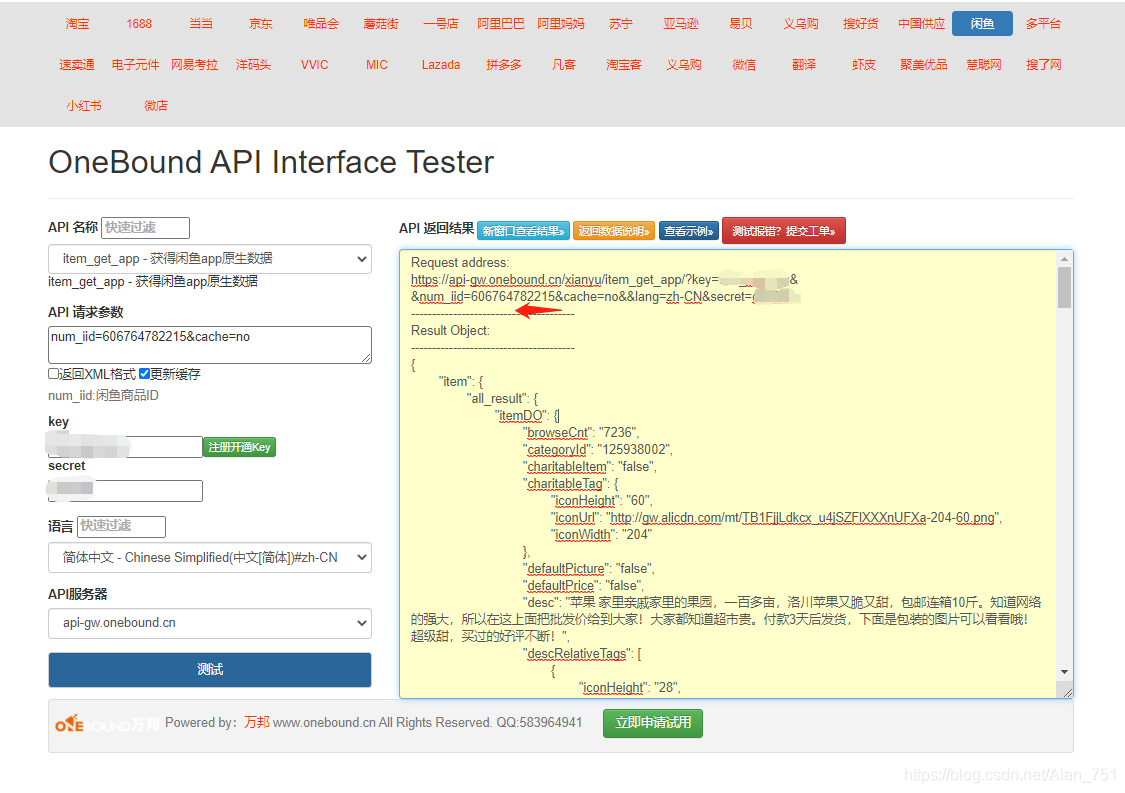
返回参数
Result Object:
---------------------------------------
{
"item": {
"all_result": {
"itemDO": {
"browseCnt": "7236",
"categoryId": "125938002",
"charitableItem": "false",
"charitableTag": {
"iconHeight": "60",
"iconUrl": "http://gw.alicdn.com/mt/TB1FjjLdkcx_u4jSZFlXXXnUFXa-204-60.png",
"iconWidth": "204"
},
"defaultPicture": "false",
"defaultPrice": "false",
"desc": "苹果 家里亲戚家里的果园,一百多亩,洛川苹果又脆又甜,包邮连箱10斤。知道网络的强大,所以在这上面把批发价给到大家!大家都知道超市贵。付款3天后发货,下面是包装的图片可以看看哦!超级甜,买过的好评不断!",
"descRelativeTags": [
{
"iconHeight": "28",
"iconUrl": "https://gw.alicdn.com/bao/uploaded/TB1DMR1chrI8KJjy0FpXXb5hVXa-52-28.png",
"iconWidth": "52"
}
],
"favorCnt": "7",
"imageInfos": [
{
"heightSize": "1080",
"major": "false",
"type": "0",
"url": "http://img.alicdn.com/bao/uploaded/i2/O1CN01OJd5Pz1jKKMFBh8fs_!!0-fleamarket.jpg",
"widthSize": "1080"
},
{
"heightSize": "1440",
"major": "false",
"type": "0",
"url": "http://img.alicdn.com/bao/uploaded/i3/O1CN01gx2L0T22pRyLaM6KK_!!0-fleamarket.jpg",
"widthSize": "1080"
},
{
"heightSize": "1440",
"major": "false",
"type"< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2522
2522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









