







前言
通过前两章的学习,大体了解了云计算,虽然有些内容并不是很了解,包括JMeter、JConsole的使用,ISF虚拟化平台搭建,Tomcat负载均衡器的配置都没有写文章单独介绍,下一步我会逐个补充上,谈到JConsole,好巧不巧,这几天在看的《HotSpot实战》中就提到了它,由JMX模块提供对外访问接口,提前说下,HotSpot是Java的一种JVM内核,和OpenJDK算是java的核心,待这个完成后也会以文章形式写下总结,好,开始今天后面的学习。
第三章并行计算技术介绍
之前一直在学习Hadoop开发,却一直不清楚它在云计算中的位置,现在了解了,它属于并行计算技术,处在计算架构中的PaaS层,至于文章 中介绍的Hadoop的HDFS和MapReduce,以及多机环境配置,关键字计数,排序等内容,之前的文章都有详细介绍,我在这里就不在赘述了。咱们接着介绍下一个分布式计算软件--Platform Symphony。他与Hadoop最大的区别在于拥有商业支持,意思就是当出现问题时,能有所维护保障。至于Platform Symphony项目开发,我也是没有实战,只是了解下大概内容,大体感觉和Hadoop开发差不多,他也是主从式结构,主服务器运行SD和SSM,SD相当于namenode,SSM则是jobtracker,从服务器是SIM,相当于tasktracker,整个部署在集群资源管理模块上。就开发语言,它也是支持各种语言,而且拥有较好的集成开发环境Eclipse,可以免费使用,遇到问题也可以选择商业支持。
下面接着说说处理并行计算业务的数据存储,我们知道数据是存储在数据库上,那对于这种数据量很大,如何高效的使用和维护这些数据确实是个问题,云计算中提供了这种数据库解决方案,当然,提出这个云计算数据库框架的依然是Google公司,由Google的Bigtable引申而来,名为Hbase,Bigtable数据库具有良好的大数据存储和实时数据处理能力,原话为“Bigtable是一个稀疏式的,分布式的,持久化存储的,多维排序的图(Map)”,这也是基于Google自身业务而发展来的实时性要求。同样,HBase也具备上面的功能,专注于解决大数据量的表,并且提供较为快速的读写这些数据量的操作,对于HBase具体的安装,配置我们后面也是专门介绍,这里重点实现方式,Map是HBase和Bigtable的核心概念,那Map这种数据类型就是<key,value>键值对的集合,结合Multidimensional多维的概念,就是列的思想,这与传统型数据库有很大的不同,列概念我们可以理解为嵌套的Map中键值的数据结构,用代码讲就是:
这里有几个概念:表、行名称(person对象)、列族(对象中键值集合)、列(对象具体属性)。关系也是从前往后,所以说,HBase就是将内存中的Map数据类型固话到了文件系统中。
在HBase中存储的数据会按照键值对的字母顺序进行排序,使用这种存储结构第一个优点就是大大的节省了查询时排序的时间损耗,因为在存储的时候就已经按照一定的顺序存放了数据,另一个优点就是由于使用了行名作为键值,与某一行名类似的行名在存储上也是相邻的,这就提高了相关关键字的查找效率,比如查找开头为“s”的记录,HBase只需找到第一个为"s"的记录,再找到第一个开头不为"s"的记录就找到了所有以"s"开头的记录。
以上可以看出分布式HBase是需要Hadoop HDFS的支持,而且还需要另外一个开源项目zookeeper(分布式应用服务器框架)的支持,我先了解下,慢慢在学,通过并行分布式计算软件,对于提高应用程序的执行效率有很大的帮助,对解决实际问题提供理论支持。
第四章公共云计算介绍
前面的学习可以充分利用企业内部的计算资源,搭建属于企业自己的云计算平台,称作私有云计算系统,也只对内开放,今天看比较重要的公有云计算平台,Google GAE,Amazon AWS,Microsoft Azure,国内的新浪SAE等,谈及公有云,首先就是IDC(Internet Data Center)因特网内容提供商,提供租用、维护服务器(虚拟主机、VPS主机等),带宽管理、流量分析、负载均衡、入侵检测的服务,算是在IaaS进行的,具体IDC环境配置,部署应用,主机业务实现,在我看来,不是我关注的方向,所以有兴趣的可以Google下。针对IDC这种服务,各大公司也愈加关注起来,纷纷投入进来,于是Google针对网络应用程序推出云计算平台Google App Engine,它支持Java和Python语言,具有如下特性:动态网络服务,提供持久存储空间,支持查询,分类和事务,能够自动扩展和负载均衡,有自带的Google账户对用户身份验证,提供网页抓取,电子邮箱服务,不过只能通过HTTP请求连接这些应用。还有就是Google不支持直接对文件系统执行写入操作,只能通过应用程序代码上传文件,如果要保存数据,则需要定制数据库存储等服务,谈到存储,我们都知道Google的Bigtable分布式数据库,但它是不对外的,GAE通过JDO封装的方式将Bigtable为用户提供数据存储服务;还有GAE使用的WEB服务器是一种和Tomcat类似的Java web服务器,名字叫Jetty,都遵循java EE规范,可以相互运行。对于我们,只需要安装其SDK在Eclipse,按照SDK附带的编程接口调用服务(用户服务、数据库服务、网页抓取)即可。具体操作待日后有机会使用我便会给大家文档展现,说明下,我们是可以免费使用它的,只要不开启收费功能,在其使用额度内。
下面接着说下Amazon的AWS(Amazon Web Service),它虽是图书起家,却两年时间成为全球最大图书平台,随后向云计算领域进军,提供Amazon EC2(弹性计算资源服务,管理购买资源)、Amazon S3(Sample Storage Service文件存储服务)、Amazon simpleDB(类型Bigtable、HBase的数据库),Amazon也是通过提供编程接口给开发人员使用,不过Amazon不会默认关闭收费项目,当注册完使用时(注册过程相对繁琐,好像要预扣费),一旦超过免费的使用额度,便自动扣费。开发方式大体和GAE相同,Eclipse上SDK开发,因为其数据库不同,数据库操作代码固然也不尽相同,稍后我会谈到JPA如何访问NoSQl数据库,到时再详解,同时,他们的部署方式也不相同,这就让我们很担心,平台移植性的问题(当然这些国外的云平台我们基本上不用,因为服务器都在国外),我将在下面具体谈。
除了上面谈到的Google、Amazon,Microsoft也推出了自己的云平台Azure,主导软件+服务,个性化自定义组合,提供了很多第三方软件租赁服务,可以说,无论用户需要的是SaaS,PaaS还是IaaS,微软都有丰富的服务提供,用户可以选择各种运营模式。简单讲,就是企业可以将一些公有的管理平台托管到云平台上,也可以租用云平台基础设施来做自己的私有管理。至于国内的云计算平台,新浪是国内首个推出公有云的,Sina App Engine,它是支持PHP语言,通过MySQL部署RDC分布式数据库集群。总体讲它是借鉴Google和Amazon的基础开发来的,对用PHP用户是不错的选择。下图是微软软件+服务架构图:
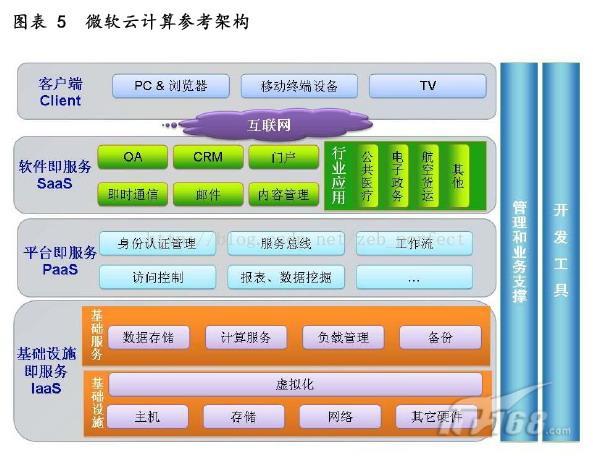
总结
最后,我们可以感觉到,其实,公有云和私有云有着密切的关系,是可以相互转化的,公有云是对私有云的良好补充,当私有云资源不足时,可以通过购买公有云资源来扩展私有云。在技术特点上基本上相同,只不过发展到最后,将自己私有云资源包装下对外部用户或企业提供服务来获得更多的利益。好了,今天算是把几个云平台介绍了一下,具体搭建自己也没有实施,有兴趣的小伙伴们可以试下。
我休息下,回头接着总结















 2380
2380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









