




Dataset Distillation with Neural Characteristic Function: A Minmax Perspective
一句话介绍
-
将数据集蒸馏表述为minmax优化问题,引入了神经特征函数差异(NCFD),实现了合成样本的真实性和多样性的平衡
-
在低分辨率和高分辨率数据集上达到SOTA,GPU内存使用量减少了300x,速度提升20x,仅使用2.3GB的显存2080TI在CIFAR100上无损压缩
背景
-
数据依赖问题:深度学习依赖大规模数据,但存储、传输和标注成本高,特别是在隐私保护、医疗图像等场景
-
数据蒸馏(Dataset Distillation):将大规模真实数据压缩为小规模合成数据集,保留关键信息以维持模型性能
-
传统方法(MSE、MMD)使用固定度量,无法全面捕捉分布差异。MSE 仅匹配欧氏空间点特征,忽略语义结构;MMD 对齐希尔伯特空间矩,但矩等价≠分布等价
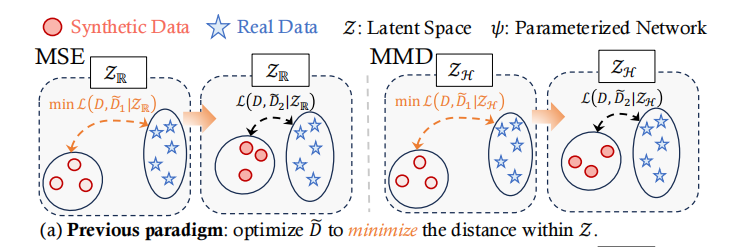
使用方法
-
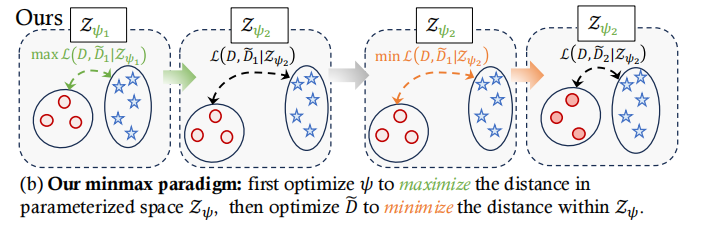
将分布匹配重新表述为一个对抗性的Minmax优化问题,引入一个NN化的网络,自适应地学习差异度量,分布差异由神经网络 ψ 进行参数化。
-
首先优化 ψ 以最大化差异(使合成数据和真实数据差异最大化,使用NCFD来判断),从而建立潜在空间 Zψ,随后优化合成数据 D~ 以在 Zψ 内最小化这种差异(努力生成尽可能“逼真”的合成数据)。
-
引入了神经特征函数差异(NCFD),这是一种基于特征函数(CF)的参数化度量,它提供了底层概率分布的精确且全面的表示。作为概率密度函数的傅里叶变换,CF封装了关于一个分布的所有相关信息。CF与累积密度函数之间存在一一对应关系,确保了其稳健性和可靠性。
-
在蒸馏过程中,迭代最小化NCFD,使合成数据更接近真实数据,同时训练采样网络以最大化NCFD,从而提高度量的稳健性和准确性,NCFD实现了线性时间计算复杂度,合成数据的分布上经过迭代后,越来越接近真实数据。
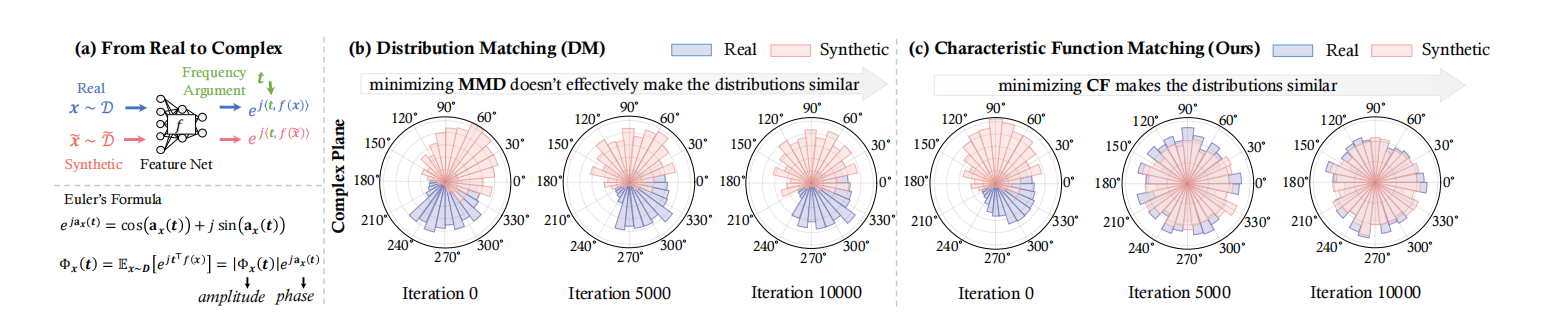
成果
-
将分布匹配问题重新表述为一个minamx优化问题,在该问题中,采样网络最大化分布差异CF,而合成图像则被优化以最小化这种差异。
-
引入了神经特征函数匹配(NCFM),它在复平面上对真实数据和合成数据的神经特征的相位和振幅信息进行对齐,实现了合成数据的真实性和多样性的平衡。
-
在多个基准数据集上的广泛实验表明了NCFM的卓越性能和效率。(真迭代1w次之后与真实数据的对比)
-
NCFM在计算资源方面更少。与DATM相比,GPU内存使用量减少了300倍以上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









