






前置条件

*索引值常用来查找列表、字符串或数组中的元素,如List.get(int), String.charAt(int)
*位置值和位置范围常用来截取列表、字符串或数组,如List.subList(int,int), String.substring(int)
常见Object方法
equals
当一个对象中的字段可以为null时,实现Object.equals方法会很痛苦,因为不得不分别对它们进行null检查。使用Objects.equal帮助你执行null敏感的equals判断,从而避免抛出NullPointerException。例如:
Objects.equal("a", "a"); // returns true
Objects.equal(null, "a"); // returns false
Objects.equal("a", null); // returns false
Objects.equal(null, null); // returns true
hashCode
用对象的所有字段作散列[hash]运算应当更简单。Guava的Objects.hashCode(Object…)会对传入的字段序列计算出合理的、顺序敏感的散列值。你可以使用Objects.hashCode(field1, field2, …, fieldn)来代替手动计算散列值。
toString
好的toString方法在调试时是无价之宝,但是编写toString方法有时候却很痛苦。使用 Objects.toStringHelper可以轻松编写有用的toString方法。例如:
// Returns "ClassName{x=1}"
Objects.toStringHelper(this).add("x", 1).toString();
// Returns "MyObject{x=1}"
Objects.toStringHelper("MyObject").add("x", 1).toString();
compare/compareTo
实现一个比较器[Comparator],或者直接实现Comparable接口有时也伤不起。考虑一下这种情况:
class Person implements Comparable<Person> {
private String lastName;
private String firstName;
private int zipCode;
public int compareTo(Person other) {
int cmp = lastName.compareTo(other.lastName);
if (cmp != 0) {
return cmp;
}
cmp = firstName.compareTo(other.firstName);
if (cmp != 0) {
return cmp;
}
return Integer.compare(zipCode, other.zipCode);
}
}
这部分代码太琐碎了,因此很容易搞乱,也很难调试。我们应该能把这种代码变得更优雅,为此,Guava提供了ComparisonChain。
ComparisonChain执行一种懒比较:它执行比较操作直至发现非零的结果,在那之后的比较输入将被忽略。
1
public int compareTo(Foo that) {
2
return ComparisonChain.start()
3
.compare(this.aString, that.aString)
4
.compare(this.anInt, that.anInt)
5
.compare(this.anEnum, that.anEnum, Ordering.natural().nullsLast())
6
.result();
7
}
不可变集合
ImmutableSet<Integer> set = ImmutableSet.of(1,3);
ImmutableSet<Integer> set1 = ImmutableSet.copyOf(set);
ImmutableSet<Integer> set2 = ImmutableSet.<Integer>builder().add(1).addAll(set).build();
ImmutableList<Integer> list = set.asList();
不可变对象有很多优点,包括:
当对象被不可信的库调用时,不可变形式是安全的;
不可变对象被多个线程调用时,不存在竞态条件问题
不可变集合不需要考虑变化,因此可以节省时间和空间。所有不可变的集合都比它们的可变形式有更好的内存利用率.
不可变对象因为有固定不变,可以作为常量来安全使用。

新集合类型
Guava提供了一个新集合类型 Multiset,Multiset元素的顺序是无关紧要的:Multiset {a, a, b}和{a, b, a}是相等的”。
可以用两种方式看待Multiset:
没有元素顺序限制的ArrayList
Map<E, Integer>,键为元素,值为计数
Guava的Multiset API也结合考虑了这两种方式:
当把Multiset看成普通的Collection时,它表现得就像无序的ArrayList:
add(E)添加单个给定元素
iterator()返回一个迭代器,包含Multiset的所有元素(包括重复的元素)
size()返回所有元素的总个数(包括重复的元素)
当把Multiset看作Map<E, Integer>时,它也提供了符合性能期望的查询操作:
count(Object)返回给定元素的计数。HashMultiset.count的复杂度为O(1),TreeMultiset.count的复杂度为O(log n)。
entrySet()返回Set<Multiset.Entry>,和Map的entrySet类似。
elementSet()返回所有不重复元素的Set,和Map的keySet()类似。
所有Multiset实现的内存消耗随着不重复元素的个数线性增长。

HashMultiset<Integer> set = HashMultiset.create();
set.add(1);
set.add(2);
set.add(1);
System.out.println(set.size()); //3
System.out.println(set.count(1)); //2
Set<Integer> s = set.elementSet();
System.out.println(JsonHelper.toJson(s)); //[1,2]

Multimap
每个有经验的Java程序员都在某处实现过Map<K, List>或Map<K, Set>,并且要忍受这个结构的笨拙。例如,Map<K, Set>通常用来表示非标定有向图。Guava的 Multimap可以很容易地把一个键映射到多个值。换句话说,Multimap是把键映射到任意多个值的一般方式。
可以用两种方式思考Multimap的概念:”键-单个值映射”的集合:
a -> 1 a -> 2 a ->4 b -> 3 c -> 5
或者”键-值集合映射”的映射:
a -> [1, 2, 4] b -> 3 c -> 5
一般来说,Multimap接口应该用第一种方式看待,但asMap()视图返回Map<K, Collection>,让你可以按另一种方式看待Multimap。重要的是,不会有任何键映射到空集合:一个键要么至少到一个值,要么根本就不在Multimap中。

Multimap的视图
Multimap还支持若干强大的视图:
asMap为Multimap<K, V>提供Map<K,Collection>形式的视图。返回的Map支持remove操作,并且会反映到底层的Multimap,但它不支持put或putAll操作。更重要的是,如果你想为Multimap中没有的键返回null,而不是一个新的、可写的空集合,你就可以使用asMap().get(key)。(你可以并且应当把asMap.get(key)返回的结果转化为适当的集合类型——如SetMultimap.asMap.get(key)的结果转为Set,ListMultimap.asMap.get(key)的结果转为List——Java类型系统不允许ListMultimap直接为asMap.get(key)返回List——译者注:也可以用Multimaps中的asMap静态方法帮你完成类型转换)
entries用Collection<Map.Entry<K, V>>返回Multimap中所有”键-单个值映射”——包括重复键。(对SetMultimap,返回的是Set)
keySet用Set表示Multimap中所有不同的键。
keys用Multiset表示Multimap中的所有键,每个键重复出现的次数等于它映射的值的个数。可以从这个Multiset中移除元素,但不能做添加操作;移除操作会反映到底层的Multimap。
values()用一个”扁平”的Collection包含Multimap中的所有值。这有一点类似于Iterables.concat(multimap.asMap().values()),但它直接返回了单个Collection,而不像multimap.asMap().values()那样是按键区分开的Collection。

ArrayListMultimap<String,Integer> map = ArrayListMultimap.create();
map.put("key1",2);
map.put("key1",2);
map.put("key1",3);
map.put("key2",2);
System.out.println(map.get("key1")); //[2, 2, 3]
Map<String, Collection<Integer>> m = map.asMap();
BiMap
传统上,实现键值对的双向映射需要维护两个单独的map,并保持它们间的同步。但这种方式很容易出错,而且对于值已经在map中的情况,会变得非常混乱。例如:
Map<String, Integer> nameToId = Maps.newHashMap();
Map<Integer, String> idToName = Maps.newHashMap();
nameToId.put("Bob", 42);
idToName.put(42, "Bob");
//如果"Bob"和42已经在map中了,会发生什么?
//如果我们忘了同步两个map,会有诡异的bug发生...


Table
Table<Vertex, Vertex, Double> weightedGraph = HashBasedTable.create();
weightedGraph.put(v1, v2, 4);
weightedGraph.put(v1, v3, 20);
weightedGraph.put(v2, v3, 5);
weightedGraph.row(v1); // returns a Map mapping v2 to 4, v3 to 20
weightedGraph.column(v3); // returns a Map mapping v1 to 20, v2 to 5
通常来说,当你想使用多个键做索引的时候,你可能会用类似Map<FirstName, Map<LastName, Person>>的实现,这种方式很丑陋,使用上也不友好。Guava为此提供了新集合类型Table,它有两个支持所有类型的键:”行”和”列”。Table提供多种视图,以便你从各种角度使用它:
rowMap():用Map<R, Map<C, V>>表现Table<R, C, V>。同样的, rowKeySet()返回”行”的集合Set。
row® :用Map<C, V>返回给定”行”的所有列,对这个map进行的写操作也将写入Table中。
类似的列访问方法:columnMap()、columnKeySet()、column©。(基于列的访问会比基于的行访问稍微低效点)
cellSet():用元素类型为Table.Cell<R, C, V>的Set表现Table<R, C, V>。Cell类似于Map.Entry,但它是用行和列两个键区分的。
Table有如下几种实现:
HashBasedTable:本质上用HashMap<R, HashMap<C, V>>实现;
TreeBasedTable:本质上用TreeMap<R, TreeMap<C,V>>实现;
ImmutableTable:本质上用ImmutableMap<R, ImmutableMap<C, V>>实现;注:ImmutableTable对稀疏或密集的数据集都有优化。
ArrayTable:要求在构造时就指定行和列的大小,本质上由一个二维数组实现,以提升访问速度和密集Table的内存利用率。ArrayTable与其他Table的工作原理有点不同,请参见Javadoc了解详情。

强大的集合工具类:java.util.Collections中未包含的集合工具

静态工厂方法
在JDK 7之前,构造新的范型集合时要讨厌地重复声明范型:
List<TypeThatsTooLongForItsOwnGood> list = new ArrayList<TypeThatsTooLongForItsOwnGood>();
我想我们都认为这很讨厌。因此Guava提供了能够推断范型的静态工厂方法:
List<TypeThatsTooLongForItsOwnGood> list = Lists.newArrayList();
Map<KeyType, LongishValueType> map = Maps.newLinkedHashMap();
可以肯定的是,JDK7版本的钻石操作符(<>)没有这样的麻烦:
List<TypeThatsTooLongForItsOwnGood> list = new ArrayList<>();
但Guava的静态工厂方法远不止这么简单。用工厂方法模式,我们可以方便地在初始化时就指定起始元素。
Set<Type> copySet = Sets.newHashSet(elements);
List<String> theseElements = Lists.newArrayList("alpha", "beta", "gamma");
此外,通过为工厂方法命名(Effective Java第一条),我们可以提高集合初始化大小的可读性:
List<Type> exactly100 = Lists.newArrayListWithCapacity(100);
List<Type> approx100 = Lists.newArrayListWithExpectedSize(100);
Set<Type> approx100Set = Sets.newHashSetWithExpectedSize(100);
确切的静态工厂方法和相应的工具类一起罗列在下面的章节。
注意:Guava引入的新集合类型没有暴露原始构造器,也没有在工具类中提供初始化方法。而是直接在集合类中提供了静态工厂方法,例如:
Multiset<String> multiset = HashMultiset.create();
Iterables
在可能的情况下,Guava提供的工具方法更偏向于接受Iterable而不是Collection类型。在Google,对于不存放在主存的集合——比如从数据库或其他数据中心收集的结果集,因为实际上还没有攫取全部数据,这类结果集都不能支持类似size()的操作 ——通常都不会用Collection类型来表示。
因此,很多你期望的支持所有集合的操作都在Iterables类中。大多数Iterables方法有一个在Iterators类中的对应版本,用来处理Iterator。
截至Guava 1.2版本,Iterables使用FluentIterable类进行了补充,它包装了一个Iterable实例,并对许多操作提供了”fluent”(链式调用)语法。

Iterable<Integer> concatenated = Iterables.concat(
Ints.asList(1, 2, 3),
Ints.asList(1, 5, 6));
List<Integer> list = new ArrayList<>();
int count = Iterables.frequency(concatenated,1);
System.out.println(count); // 2
int first = Iterables.getFirst(concatenated,-1);
System.out.println(first); //1

Sets

Set<Integer> set1 = Sets.newHashSet(1,2,3,5);
Set<Integer> set2 = Sets.newHashSet(2,3,4);
Set<Integer> union = Sets.union(set1,set2);
Set<Integer> intersection = Sets.intersection(set1,set2);
Sets.SetView<Integer> setView = Sets.difference(set1,set2); ///set1中比set2中多的
Set<Integer> difference = new HashSet<>();
setView.copyInto(difference);
System.out.println(union); //[1, 2, 3, 5, 4]
System.out.println(difference); //[1, 5]
System.out.println(intersection); // [2, 3]
Maps
uniqueIndex
Maps.uniqueIndex(Iterable,Function)通常针对的场景是:有一组对象,它们在某个属性上分别有独一无二的值,而我们希望能够按照这个属性值查找对象——译者注:这个方法返回一个Map,键为Function返回的属性值,值为Iterable中相应的元素,因此我们可以反复用这个Map进行查找操作。
List<String> list = new ArrayList<>();
list.add("a");
list.add("ab");
list.add("abc");
ImmutableMap<Integer, String> stringsByIndex = Maps.uniqueIndex(list,new Function<String,Integer>(){
@Override
public Integer apply(String input) {
return input.length();
}
});
String s= stringsByIndex.get(2);
System.out.println(s); //ab
源码:
public static <K, V> ImmutableMap<K, V> uniqueIndex(
Iterable<V> values, Function<? super V, K> keyFunction) {
// TODO(lowasser): consider presizing the builder if values is a Collection
return uniqueIndex(values.iterator(), keyFunction);
}
difference

Map<String, Integer> left = ImmutableMap.of("a", 1, "b", 2, "f", 3);
Map<String, Integer> right = ImmutableMap.of("a", 1, "e", 3, "c", 4);
MapDifference<String, Integer> diff = Maps.difference(left, right);
Map<String, Integer> common = diff.entriesInCommon(); //{a=1}
Map<String, MapDifference.ValueDifference<Integer>> Differing = diff.entriesDiffering();
Map<String, Integer> OnlyOnLeft = diff.entriesOnlyOnLeft(); //{b=2, f=3}
Map<String, Integer> OnlyOnRight = diff.entriesOnlyOnRight(); //{e=3, c=4}
字符串处理:分割,连接,填充
连接器[Joiner]
用分隔符把字符串序列连接起来也可能会遇上不必要的麻烦。如果字符串序列中含有null,那连接操作会更难。Fluent风格的Joiner让连接字符串更简单。
Joiner joiner = Joiner.on("; ").skipNulls();
return joiner.join("Harry", null, "Ron", "Hermione");
Joiner.on(",").join(Arrays.asList(1, 5, 7)); // returns "1,5,7"
读guavaCache源码并记录
Guava Cache 原理分析与最佳实践
public class GuavaTest {
public static void main(String[] args) throws ExecutionException {
LoadingCache<String, String> graphs = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(
new CacheLoader<String, String>() {
public String load(String key) {
return get(key);
}
});
String r1 = graphs.get("wang");
String r2 = graphs.get("wang");
}
public static String get(String key){
System.out.println("啦啦啦啦"+key);
return "嘻嘻"+key;
}
}
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
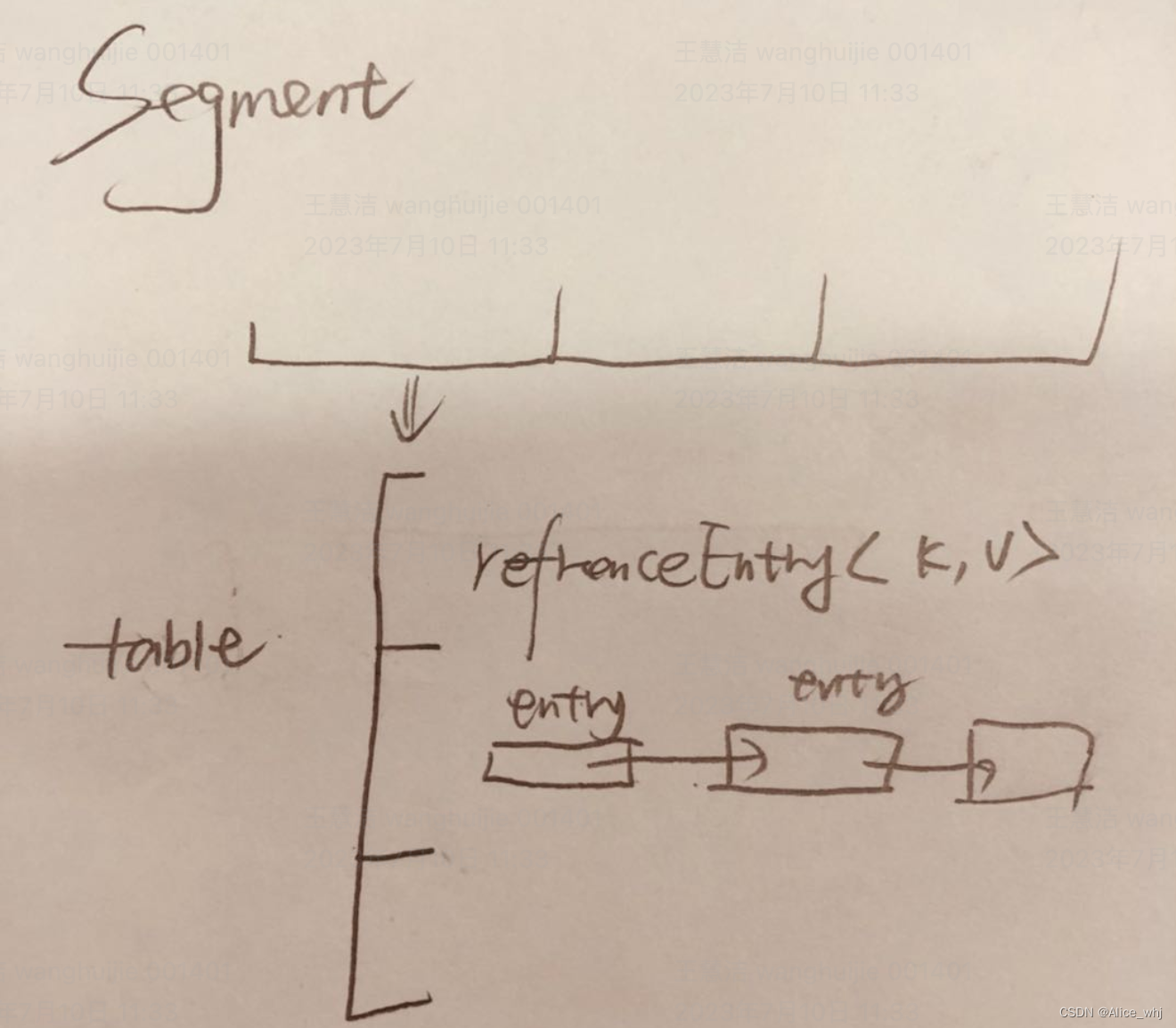
/** The segments, each of which is a specialized hash table. */
final Segment<K, V>[] segments;
static class Segment<K, V> extends ReentrantLock {
volatile @Nullable AtomicReferenceArray<ReferenceEntry<K, V>> table;
}
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
lock();
try {
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1); //根据key的hash值,找到table的index
ReferenceEntry<K, V> first = table.get(index); //获取第一个entry
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
if (value == null) {
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accommodate an incorrect expiration queue.
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED);
} else {
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// immediately reuse invalid entries
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
if (createNewEntry) { //key不存在,跳过上面的循环
loadingValueReference = new LoadingValueReference<>();
if (e == null) {
e = newEntry(key, hash, first); //创建entry
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
unlock();
postWriteCleanup();
}
if (createNewEntry) {
try {
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader); //真正去获取value,
填充loadingValueReference
}
} finally {
statsCounter.recordMisses(1);
}
} else {
return waitForLoadingValue(e, key, valueReference);
}
}
创建entry时,将segment锁住,并将新创建的放在头上,最前面
ReferenceEntry<K, V> newEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
LocalCache.Segment<K, V> segment = this.segmentFor(hash);
segment.lock();
ReferenceEntry var5;
try {
var5 = segment.newEntry(key, hash, next);
} finally {
segment.unlock();
}
return var5;
}
V loadSync(
K key,
int hash,
LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader)
throws ExecutionException {
ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
//如果值不存在的话,调自己写的load方法加载
return getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
}
在存储value时,有一个判断是否扩容的动作
if (newCount > this.threshold) { //大于阈值就扩容
expand();
newCount = this.count + 1;
}
void expand() {
AtomicReferenceArray<ReferenceEntry<K, V>> oldTable = table;
int oldCapacity = oldTable.length();
if (oldCapacity >= MAXIMUM_CAPACITY) { //如果已大于最大容量,则不在扩容
return;
}
int newCount = count;
AtomicReferenceArray<ReferenceEntry<K, V>> newTable = newEntryArray(oldCapacity << 1); //扩容两倍
threshold = newTable.length() * 3 / 4; //阈值为总长度的0.75倍
int newMask = newTable.length() - 1;
for (int oldIndex = 0; oldIndex < oldCapacity; ++oldIndex) {
ReferenceEntry<K, V> head = oldTable.get(oldIndex);
if (head != null) { //对table[i]中entry,,进行移动的
ReferenceEntry<K, V> next = head.getNext();
int headIndex = head.getHash() & newMask; //将老表数据rehash到新表新的位置
if (next == null) {
newTable.set(headIndex, head);
} else {
ReferenceEntry<K, V> tail = head;
int tailIndex = headIndex;
for (ReferenceEntry<K, V> e = next; e != null; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
if (newIndex != tailIndex) {
tailIndex = newIndex;
tail = e;
}
}
newTable.set(tailIndex, tail);
for (ReferenceEntry<K, V> e = head; e != tail; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
ReferenceEntry<K, V> newNext = newTable.get(newIndex);
ReferenceEntry<K, V> newFirst = copyEntry(e, newNext);
if (newFirst != null) {
newTable.set(newIndex, newFirst);
} else {
removeCollectedEntry(e);
newCount--;
}
}
}
}
}
table = newTable;
this.count = newCount;
}















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









