







朴素贝叶斯与正态贝叶斯
优点:在数据较少的情况下任然有效,可以处理多类别问题
缺点:对输入数据较为敏感
概念:朴素贝叶斯主要是从两个方面展开的,也就是朴素:1.假定各个条件之间是独立的,2 特征向量之间的地位是相等的。然后就是贝叶斯公式,如下所示
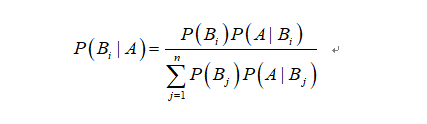
公式描述:
公式中,事件Bi的概率为P(Bi),事件Bi已发生条件下事件A的概率为P(A│Bi),事件A发生条件下事件Bi的概率为P(Bi│A)。
问题大概已经描述清楚,理论知识就这么多,那我们怎么利用呢?举个例子,我们现在已知某年某个月天晴20天,下雨10天。第二年的是个这个月某天下雨的概率我们是不是认为更高呢?如果事实不是这样的时候我们就会疑惑,为啥这个月下了这么多雨呢?我们在潜意识中已经使用了贝叶斯公式了,这就是所谓的先验概率,我们会用预先知道的信息去推断未知的信息。下面我们以一个例子从头到尾的介绍朴素贝叶斯。
引例
样本:1000封邮件,每个邮件被标记为垃圾邮件或者非垃圾邮件
分类目标:给定第1001封邮件,确定它是垃圾邮件还是非垃圾邮件
类别c:垃圾邮件c1,非垃圾邮件c2
词汇表,两种建立方法:
使用现成的单词词典;
将所有邮件中出现的单词都统计出来,得到词典。
记单词数目为N
将每个邮件m映射成维度为N的向量x
若单词wi在邮件m中出现过,则xi=1,否则,xi=0。即邮件的向量化:m(x1,x2……xN)
贝叶斯公式:P(c|x)=P(x|c)*P© / P(x)
P(c1|x)=P(x|c1)*P(c1) / P(x)
P(c2|x)=P(x|c2)*P(c2) / P(x)
故我们只需要比较P(c1|x)和P(c2|x)的大小,我们即可认为它属于垃圾邮件还是正常邮件,下面开始介绍怎么去一一计算这些值的大小。
朴素贝叶斯的计算过程:
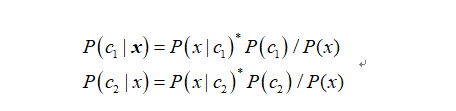
以上公式是我们的目标。
首先是P(c)这是最简单的,只需要用垃圾邮件或者非垃圾邮件除以邮件总数。如果垃圾邮件和非垃圾邮件数目是相等的,那么这个值会是相等的,我们把这种模型称之为贝努力模型。
其次是p(x)和p(x|c1)的计算,这个时候就用到了我们的第一个假设,各个条件之间是独立的。即
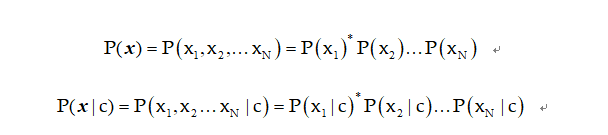
正是因为独立,所以可以展开,那每一个P(x1)和P(x1|c)怎么计算呢?
我们从他的意义展开P(x1)表示词x1出现的概率,那是不是就是x1在邮件中出现的次数除以所有词的个数。
P(xi|cj):在cj(此题目,cj要么为垃圾邮件1,要么为非垃圾邮件2)的前提下,第i个单词xi出现的概率。
如果对于贝努力模型P(c)和p(x)都是相等的,本质上我们只需要计算p(x|ci)即可。
为了避免出现小数过小,我们通常用取对数的方式,减少小数乘积的溢出。
拉普拉斯平滑
问题到这里似乎已经解决了,但是实际和这个又是有差距的,如果出现一种情况,某个词xi在整个邮件中一次都没出现过那p(xi|ci) = 0,如果带入公式中连乘的结果就是0了,为了避免这种情况出现,我们引入一个数值,使得它的概率不可能为0.
 我们把以上方法称之为拉普拉斯平滑。至此朴素贝叶斯方法理论基本就是这些。如果是python编程的话,在sklearn库中有朴素贝叶斯的方法,我们只需要调用其方法,修改对应参数即可。
我们把以上方法称之为拉普拉斯平滑。至此朴素贝叶斯方法理论基本就是这些。如果是python编程的话,在sklearn库中有朴素贝叶斯的方法,我们只需要调用其方法,修改对应参数即可。
高斯朴素贝叶斯


正态贝叶斯分类器
该分类器只能处理特征属性是连续值的分类问题



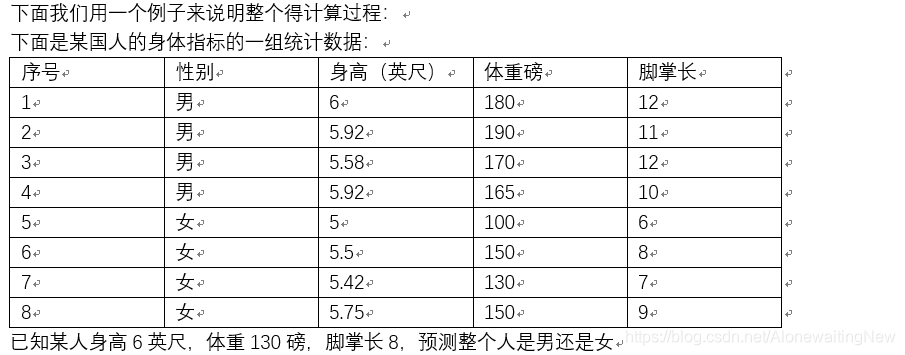

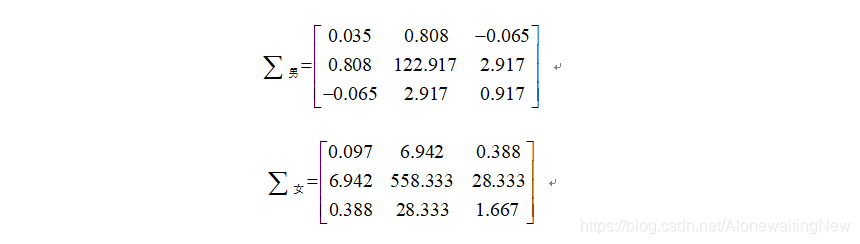
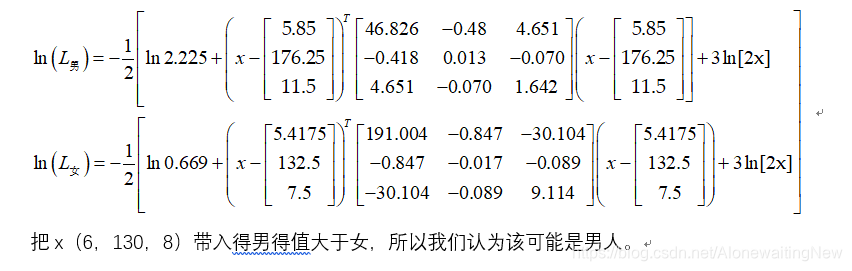 ##
##
C++ opencv示例代码
#include<opencv2/opencv.hpp>
#include<opencv2/ml/ml.hpp>
using namespace std;
using namespace cv;
using namespace ml;
int main()
{
const int Kwidth = 512;
const int Kheight = 512;
//用于显示分类结果的图像
Mat image = Mat::zeros(Kheight, Kwidth, CV_8UC3);
//组织分类标签
int labels[30];
for (int i = 0; i < 10; i++)
labels[i] = 1;
for (int i = 10; i < 20; i++)
labels[i] = 2;
for (int i = 20; i < 30; i++)
labels[i] = 3;
Mat labelsMat(30, 1, CV_32SC1, labels);
//组织训练数据,三类数据,每个数据点为二维特征向量
float trainDataArray[30][2];
RNG rng;
for (int i = 0; i < 10; i++)
{
trainDataArray[i][0] = 250 + static_cast<float>(rng.gaussian(30));
trainDataArray[i][1] = 250 + static_cast<float>(rng.gaussian(30));
}
for (int i = 10; i < 20; i++)
{
trainDataArray[i][0] = 150 + static_cast<float>(rng.gaussian(30));
trainDataArray[i][1] = 150 + static_cast<float>(rng.gaussian(30));
}
for (int i = 20; i < 30; i++)
{
trainDataArray[i][0] = 320 + static_cast<float>(rng.gaussian(30));
trainDataArray[i][1] = 150 + static_cast<float>(rng.gaussian(30));
}
Mat trainingDataMat(30, 2, CV_32FC1, trainDataArray);
// 创建贝叶斯分类器
Ptr<NormalBayesClassifier> model = NormalBayesClassifier::create();
// 设置训练数据
Ptr<TrainData> tData = TrainData::create(trainingDataMat, ROW_SAMPLE, labelsMat);
//训练分类器
model->train(tData);
//对图像内所有512*512个背景点进行预测,不同的预测结果,图像背景区域显示不同的颜色
Vec3b red(0, 0, 255), green(0, 255, 0), blue(255, 0, 0);
for (int i = 0; i < image.rows; ++i)
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1, 2) << j, i); //生成测试数据
float response = model->predict(sampleMat); //进行预测,返回1或-1
if (response == 1)
image.at<Vec3b>(i, j) = red;
else if (response == 2)
image.at<Vec3b>(i, j) = green;
else
image.at<Vec3b>(i, j) = blue;
}
//把训练样本点,显示在图相框内
for (int i = 0; i < trainingDataMat.rows; i++)
{
const float * v = trainingDataMat.ptr<float>(i);
Point pt = Point((int)v[0], (int)v[1]);
if (labels[i] == 1) //不同的圆点,标记不同的颜色
circle(image, pt, 5, Scalar::all(0), -1, 8);
else if (labels[i] == 2)
circle(image, pt, 5, Scalar::all(128), -1, 8);
else
circle(image, pt, 5, Scalar::all(255), -1, 8);
}
//显示分类结果图像
imshow("贝叶斯分类器示例", image);
waitKey(0);
return 0;
}
实例二
int main() {
//训练数据集
float trainData[8][3] = { { 6,180,12 },{ 5.92,109,11 },{ 5.58,170,12 },{ 5.92,165,10 },{ 5,100,6 },{ 5.5,150,8 },{ 5.42,130,7 },{ 5.75,150,9 } };
Mat trainDataMat(8, 3, CV_32FC1, trainData);
//数据标签
int responses[8] = { 1.0,1.0,1.0,1.0,0,0,0,0 }; //此处的类型最好为int 如果是float结果可能是你想不到的,转成CV_32SC的时候变成了1*10^19。
Mat responsesMat(8, 1, CV_32SC1, responses); //貌似只有CV_32SC数据类型是有效的
//创建贝叶斯分类器
Ptr<NormalBayesClassifier> model = NormalBayesClassifier::create();
Ptr<TrainData> data = TrainData::create(trainDataMat, ml::ROW_SAMPLE, responsesMat);
//训练
model->train(data);
float myData[3] = { 6,130,8 };
Mat myDataMat(1, 3, CV_32FC1, myData);
//预测
float r = model->predict(myDataMat);
cout << endl << "result = " << r << endl;
system("pause");
}
以上两个实例的平台都是Opencv4.1实现的。
小结,
1.这是opencv机器学习的开篇,后期将会更深层的分析各种机器学习算法,尽可能的做到简洁明了,也是为C++做机器学习提供了一个好的办法吧。如果大家需要所有的源码,部署到嵌入式的环境中,可以参考opencv官方文档,查看整个目录结构。在opencv中,整个机器学习算法都继承一个虚类
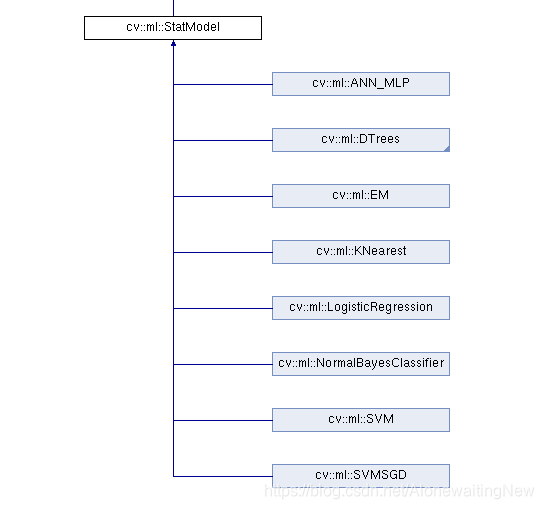
2.下一篇将介绍整个机器学习中最重要的一个算法SVM Support Vector Machine.至于更新时间,看情况,如果这篇文章看的人多,点赞的多,我就尽早更新。希望大家多多支持。














 1972
1972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









