







 本文介绍了58业务体系全站行为数据仓库的建设挑战,提出了基于维度建模的方法论,包括ER模型、维度模型、DataVault模型和Anchor模型,并详细阐述了数据仓库的分层思想、建设原则和实施过程。此外,还制定了数据仓库的表规范和编码规范,以确保数据质量和降低维护成本。目前,数据仓库已初具成效,未来将继续关注数据完整性和质量优化。
本文介绍了58业务体系全站行为数据仓库的建设挑战,提出了基于维度建模的方法论,包括ER模型、维度模型、DataVault模型和Anchor模型,并详细阐述了数据仓库的分层思想、建设原则和实施过程。此外,还制定了数据仓库的表规范和编码规范,以确保数据质量和降低维护成本。目前,数据仓库已初具成效,未来将继续关注数据完整性和质量优化。
背景
随着58业务体系的不断建设与发展,数据分析与应用需求越来越丰富,给数据仓库的建设工作带来了很大的挑战。
全站行为数据仓库建设过程中,我们总结的问题包括如下几点:
(1) 数据体系架构已经无法支持业务的快速迭代,数据集成的开发、维护成本高;
(2) 数据业务知识散乱,数据分析与应用成本高;
(3) 数据质量定义模糊,缺乏有效统一的数据质量监控体系;
(4) 缺失数据建设规范,数据开发、表结构定义不统一,数据任务、数据表维护成本高。
综上,全站行为数据仓库的建设,需要在现有的大数据平台基础上,借鉴互联网行业通用的维度建模方法论,构建架构合理,分层清晰,具有统一数据规范的全站行为数据仓库。
大数据领域建模综述
1. 为什么需要数据建模
数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合。数据仓库中的数据需要进行有序、有结构地分类组织和存储。通过建立适合业务和基础数据存储环境的模型,可以带来以下优点:
(1) 性能:快速查询数据,减少数据的I/O吞吐;
(2) 成本:减少数据冗余,计算结果复用;
(3) 效率:改善用户的使用数据体验,提高使用数据效率;
(4) 质量:改善数据统计口径的不一致性,减少数据计算错误的可能性。
2. 典型的数据仓库建模方法论
行业内,典型的数据仓库建模方法论主要分为以下几种:
(1) ER模型——全企业的高度设计一个3NF模型,描述企业业务。
a) 高层模型:高度抽象,主要的主题以及主题间的关系
b) 中层模型:细化主题的数据项
c) 物理模型:基于性能和平台特点进行物理属性的设计,如表合并,分区设计
(2) 维度模型——为分析决策需求服务
a) 选择需要进行分析决策的业务过程;
b) 选择粒度;
c) 识别维表;
d) 选择事实。
(3) Data Vault模型——ER模型的衍生,实现数据整合。
a) Hub:企业核心业务实体;
b) Link:Hub之间的关系。Hub的代理键、装载时间、数据来源组成;
c) Satellite:Hub的详细描述内容。
(4) Anchor模型——k-v结构化模型
a) Anchors:类似Hub,只有主键;
b) Attributes:类似Satellite,规范化,全部k-v结构化;
c) Ties:描述Anchors的关系。单独用表来描述;
d) Knots:可能在多个Anchors中公用的属性的提炼。
全站行为数据仓库落地建设实践过程中,参考互联网行业内采用广泛的维度建模方法论,结合58商业自身特点,分析业务环境构造数据仓库底层数据基础,再按照实际的应用需求构造数据仓库上层数据的方式进行数据仓库的建设。
全站行为数据仓库建设实践
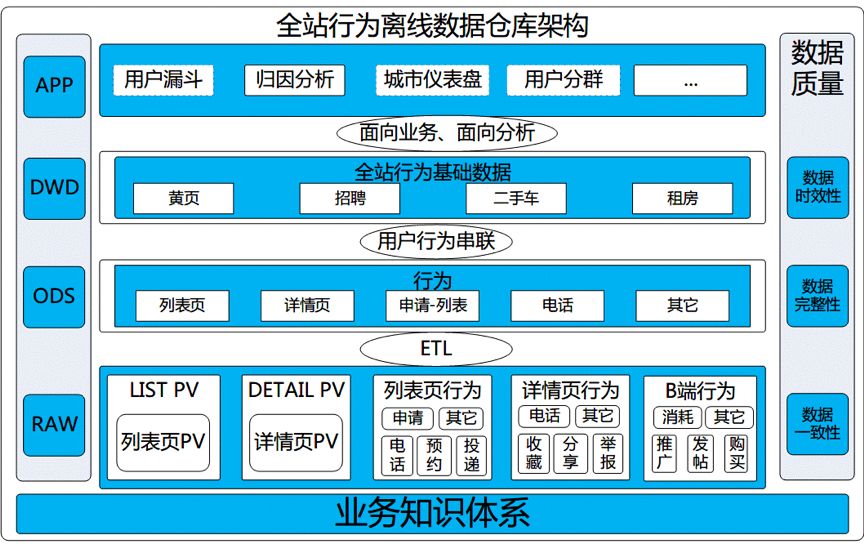
下图为数据仓库中全站行为数据部分数据仓库体系架构图:
_
_
_
_
图1 全站行为数据架构图
1. 全站行为数据概述
全站行为数据是指在主站数据内,一次帖子检索过程,对应的用户浏览、点击、交互行为数据集合。其中用户行为是指:
(1) 主站列表页主列表--> 用户浏览;
(2) 主站详情页展现-->用户点击;
(3) 收藏、拨打电话、投递简历-->用户交互|效果。
目前全站行为数据规模明细数据日均2.5T。
2. 全站行为数据仓库构建原则
全站行为数据仓库建设中,逐步借鉴和沉淀的数据仓库构建原则如下:
(1) 底层业务的数据驱动为导向同时结合业务需求驱动。
(2) 便于数据分析。
a) 屏蔽底层复杂业务;
b) 简单、完整、集成的将数据暴露给分析层;
(3) 底层业务变动与上层需求变动对模型冲击最小化。
a) 业务系统变化削弱在操作数据层;
b) 结合自上而下的建设方法削弱需求变动对模型的影响;
c) 数据水平层次清晰化。
(4) 高内聚松耦合。
a) 主题之内数据高内聚;
b) 主题之间数据松耦合。
(5) 构建仓库基础数据层
a) 使得底层业务数据整合工作与上层应用开发工作相隔离,为仓库大规模开发奠定基础;
b) 仓库层次更加清晰,对外暴露数据更加统一。
3. 数据仓库架构分层思想
数据仓库构建过程中,采用的分层思想,各层的功能及建模方式和原则介绍如下。
(1) ODS层
功能:
a) ODS层是数据仓库准备区;
b) 为DWD层提供基础原始数据;
c) 减少对业务系统影响;
建模方式及原则:
a) 数据保留时间根据实现业务需求而定;
b) 数据清洗转换,统一数据定义;
c) 按主题逻辑划分;
d) 源系统以增量方式经过ETL到ODS;
e) 可以分表进行周期存储,存储周期不长。
(2) DWD层
功能:
a) 为APP层提供来源明细数据;
b) 提供业务系统细节数据的长期沉淀;
c) 为未来分析类需求的扩展提供历史数据支撑;
d) 可以是一些宽表,满足特定查询、数据挖掘应用。
建模方式及原则
a) 保持粒度一致;
b) 指标事实与ODS基本保持一致。
(3) APP层
功能:
a) 对接数据分析需求,提供快速查询、支持。
建模方式及原则:
a) 面向业务、面向分析;
b) 保持数据量小,快速查询、分析;
c) 维度建模,维度+指标汇总;
d) 支持数据重跑;
e) 不分表存储。
4. 模型实施过程
全站行为数据仓库建设过程,整体数据建设模型实施过程如下:
(1) 充分的业务调研和需求分析,决定后续数据仓库模型构建过程的正确性。
(2) 数据总体架构设计,构建统一、合理、清晰的数据仓库架构。
(3) 详细设计。抽象数据需求,保证数据需求&问题解决的完备性。
(4) 代码开发和测试。
(5) 数据DIFF。
a) 模型迭代-字段DIFF,对迭代过程中,模型中非迭代的每个字段的正确性做迭代前后DIFF,保证字段级数据质量;
b) 模型构建-指标DIFF,对模型构建中,模型中的业务数据指标进行DIFF,保证构建过程符合业务逻辑。
(6) 数据验收。从业务逻辑与模型构建方法过程保证数据模型落地的正确性。
a) 字段填充率;
b) 用户行为串联率;
c) 数据逻辑验证。
(7) 编写Wiki,构建统一的业务、数据知识体系,降低后续数据使用、维护成本。
(8) 数据上线;
a) 数据作业运维;
b) SLA质量保证。数据产出时效性、关键业务逻辑指标验证,保证数据可用性、稳定性。
5. 数据仓库建设规范
全站行为数据建设过程中,从表规范、编码规范来减低模型后续开发、维护成本。
1) 表规范
1、表命名规范如下:
(1) 表命名格式:[层次]_[主题][_表内容]_[分表规则];
(2) 表命名格式:T_[层次]_[主题][_表内容];
(3) 临时表命名格式:[tmp]_所属程序名_[自定义序号1…10]或[temp]_[操作者缩写]_YYYYMMDD_[表内容];
(4) 视图命名格式:View_[表名]_[表内容]。
2、表命名解释如下:
(1) 层次:ODS,DWD,APP;
(2) 表内容
a) 表名、视图名总长度不超过64字符;
b) 尽量详尽说明表具体内容。
(3) 分表规则
a) 日表YYYYMMDD;
b) 月表YYYYMM;
c) 日汇总DS,月汇总MS,日累计DT,月累计MT。
3、字段规范:
(1) 命名规范
a) 必须使用小写字母,并采用下划线分割;
b) 字段名禁止超过 32 个字符;
c) 字段名必须见名知意。命名与业务、产品线等相关联;
d) 字段名禁止使用 HIVE 保留字。
(2) 类型规范
a) 区分使用 TINYINT、SMALLINT、INT、BIGINT 数据类型,;建议使用 TINYINT 代替 BOOLEAN, 提高扩展性和类型转换兼容性;尽量使用低存储数据类型以提高运行效率;
b) 金额字段统一使用DECIMAL,时间字段(精确到十分秒)字段统一使用TIMESTAMP以提升比较效率, 分区字段及日期字段(没有时分秒)使用 String(格式统一为 yyyyMMdd)。
2) 编码规范
1、程序代码:每层一个代码目录,用于存放对应层的模型开发工程。
2、HQL代码:
(1) 使用 left semi join 代替 in/exists;
(2) join 时小表尽量放在左边,如小表足够小可使用 map join,hive 已支持自动判断大小表;
(3) 排序尽量使用 distribute+sort 组合,避免全表 order by;
(4) 尽量使用静态分区,提升运行效率;例行补数建议使用动态分区简化代码;
(5) 慎用笛卡尔积 join,卡历史数据建议使用日期维度表作笛卡尔积,以并行循环操作;
(6) 尽量使用窗口函数、udf 简化 sql 逻辑,提升代码可读性;
(7) join/group by/distinct 注意处理 NULL 值,尽量避免数据倾斜;
(8) union 会去重, 不用去重时使用 union all;
(9) 表查询如果是分区表, 尽量加上分区限制。
总结和展望
在全站行为数据建设过程中,
(1) 初步构建相对合理的数据体系结构,能够快速支持数据的集成,降低了业务迭代变化对数据模型的冲击;
(2) 业务知识体系初步建立,降低数据使用成本;
(3) 数据质量监控体系初步建立,能够对核心字段和数据指标进行监控,基本覆盖核心数据应用分析场景。
后续将围绕以下几点继续进行数据建设:
(1) 数据完整性:推进曝光数据覆盖范围,持续集成效果数据,提高全站行为数据内容丰富度;
(2) 数据质量:围绕数据产出稳定性与时效性,持续优化已有数据作业。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









