







本讲大纲:
1.核(kernels)
2.软边界(soft margin)
3.SMO算法(SMO algorithm)
1.核
属性(attributes):原始的输入值(房价的例子中,x,住房的面积)
特征(features):由原始数据映射的一些数据
用
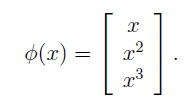
用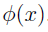
定义核为: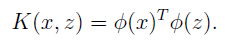
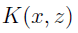
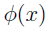
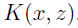
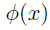
假设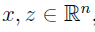
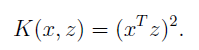
可以写成,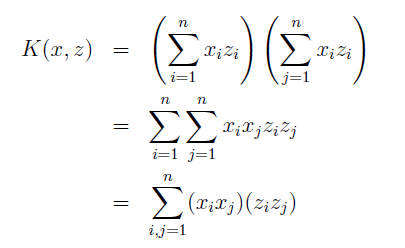
以n=3为例,
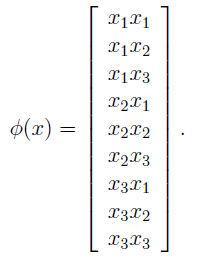
直观上来说,如果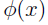
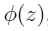
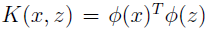
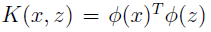
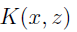
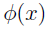
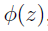
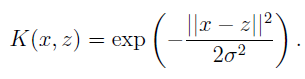
定理(Mercer):给定K,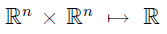
利用核的例子:
数字的识别,分类字符
2.软边界
正则化和不可分的例子(regularization and the non-separable case)
到目前为止,我们讨论SVM时认为数据是线性可分的, 把数据映射到高维空间一般会增加线性可分的可能性,但是我们不能保证一定可以.
左图显示的是一个最优间隔分类器,但是如果在左上区域加上一个异常值,决定边界线会发生剧烈的变化,
导致分类器有更小的边界.
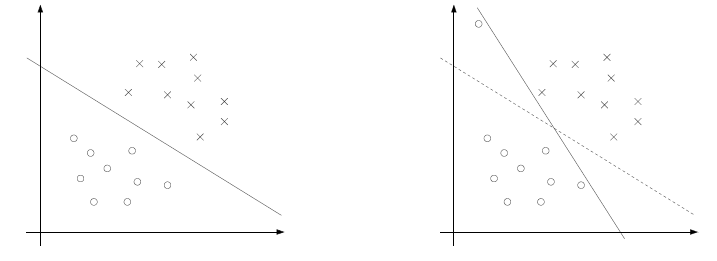
为了使算法能够处理非线性可分的数据集并且对异常值不会这么敏感, 修订优化问题如下:
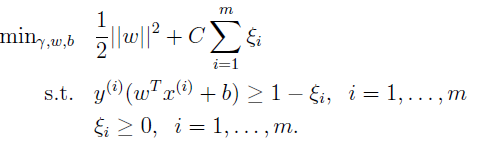
因此,样本现在允许边界小于1.
3.SMO算法
SMO(sequential minimal optimization)算法起源于SVM, John Platt起初了一个高效解决对偶问题的方法.
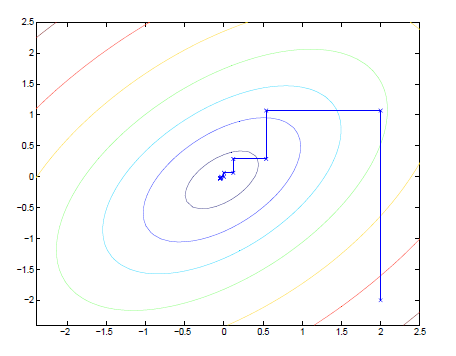
坐标上升(Coordinate ascend)
对于没有限制的优化问题:
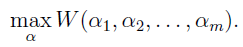

下图是坐标上升执行的一个过程:
这是我们要解决的对偶问题:
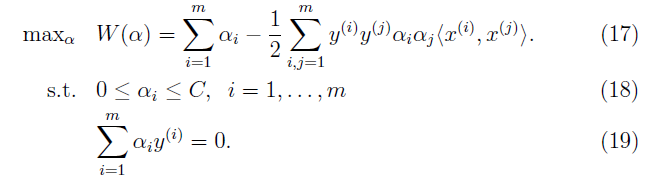
这里不能直接使用坐标上升算法,因此(19)的限制. 因此我们至少要同时改变两个才能满足限制. 因此:

SMO算法之所以高效是能够很高效的计算出ai,aj.
以改变a1,a2为例,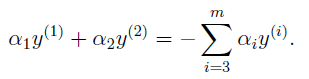
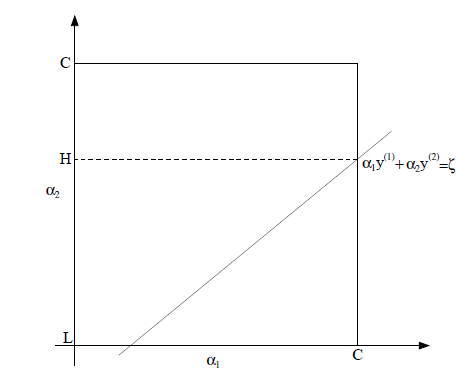
得到:
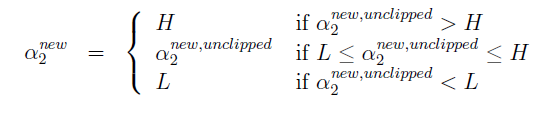
之后计算出a1的值.














 3180
3180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









