







文章目录
前言
在前面的文章里(基于状态机方法构建高容错性服务, Apache Ratis的Ratis Server主从同步机制),笔者谈论过如何利用状态机理论来构建replicated server的文章,以此做到服务的高可用性,可做到随时的动态切换。前面文章已经详细阐述里面replicated的原理细节内容,本文笔者打算谈论其中一类特殊的数据服务:纯内存式的replicated server,即In memory的replicated server。纯内存式的数据服务在读写性能上毫无疑问有着极快的响应时间,在实际用途中也有很多的适用场景。下面我们来聊聊这块的内容以及对此的一个简单代码实现。
内存式元数据服务概述
内存元数据服务,顾名思义,就是将系统的元数据信息全部加载到内存中进行访问。鉴于内存访问速度远远快于磁盘读写速度,因此内存元数据服务有着其固有的一大优势:数据读写快。但是它同样有着相比于磁盘做存储而言的一些劣势,
- 内存空间有限,不如磁盘空间大,论单节点而言,一个系统服务所在节点的可用内存大的会达到百GB级别,但是磁盘一个节点可达到TB级别。
- 内存数据转瞬即逝,需要有好的策略定期持久化内存数据出去。
不过回头来看,上百GB级别的内存空间用来做元数据的存储还是足够的,毕竟每个元数据单位空间占据不至于那么大。以HDFS NameNode为例,上100GB的NN内存使用可以容纳2亿级别的block元数据信息了。
通用的简单K-V内存存储的replicated server
如小标题所示,本文笔者想要阐述的是一种较为简单的,纯内存存储的K-V键值对的replicated server。这类replicated server将会提供以下基本的服务要求:
- 内存存储元数据数据,操作响应时间短
- K-V存储的使用方式,对用户友好,易于使用
- 对上层应用提供通用的元数据存储功能
- 具有replicated server属性,能做到高可用性,错误出现时能做到容灾切换
以下是内存存储replicated server的架构模式图:
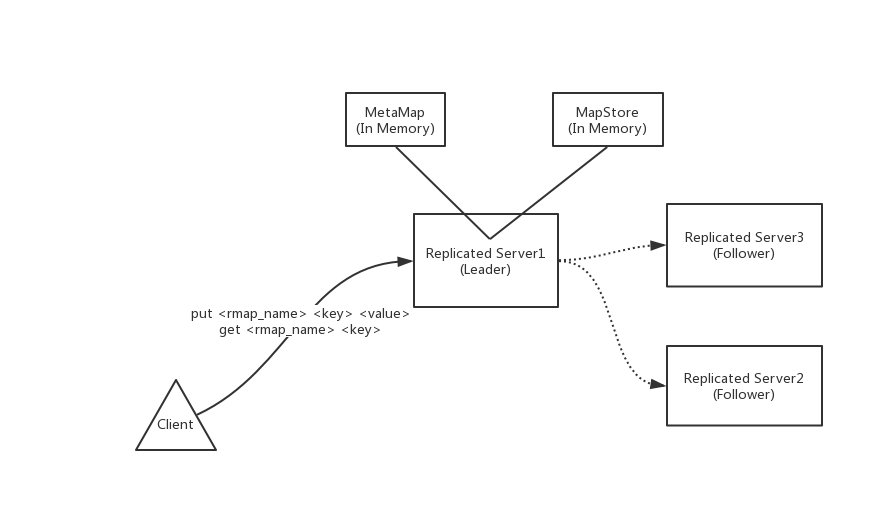
在上图中,MapStore是实质存储KV键值的map存储数据结构,MetaMap是map store的元数据存储集。Client到Replicated Server1连线部分的文字即为Client实际操作的使用命令方式:
put操作 <目标操作map名称> <key名称> <value待存储的值>
get操作 <目标操作map名称> <待取出的key名称>
了解完内存式的replicated server后,我们来了解对此server的一个简单实现,来自于Apache Ratis的JIRA: RATIS-40: Replicated Map。
内存式Replicated server的实现
在内存式Replicated server的整个模块实现中,可以进一步划分为client side和server side的实现。
Client side的实现
Client side端的实现相比较Server端要简化许多。在Client端,暴露给用户使用的CLI命令如下所示:
Usage: ratis rmap <command> [<args>]");
Commands:
create <rmap_name> <key_class> <value_class>
put <rmap_name> <key> <value>
get <rmap_name> <key>
这里的rmap即replicated map的意思,map为KV内存键值对存储map,以下是对应crete操作方法:
private int create(String[] args) throws ClassNotFoundException, IOException {
if (args.length < 3) {
return printUsage();
}
// 1)构造replicated map的元信息
RMapInfo info = RMapInfo.newBuilder()
.withName(RMapName.valueOf(args[0]))
.withKeyClass(Class.forName(args[1]))
.withValueClass(Class.forName(args[2]))
.build();
// 2)获取admin接口创建Rmap
try (Client client = ClientFactory.getClient(new FileQuorumSupplier()) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









