







本文主要总结吴恩达老师机器学习公开课的知识点。课程共8次编程作业已经上传到我的GitHub上了。这是作业链接
回归和分类
回归问题是指用已知数据拟合一个合适的假设函数h(x),或者可以理解为曲线,来预测新输入的变量的输出结果,如给定房间的大学位置等信息,预测房价。
而分类问题,顾名思义,是指用已知数据拟合一个合适的假设函数h(x),对未知数据进行分类。在分类问题中,用到的假设函数为logistic函数:
h
θ
(
x
)
=
g
(
θ
T
X
)
=
1
1
+
e
−
θ
T
X
{h\mathop{ { } }\nolimits_{ { \theta } } \left( x \left) =g \left( \theta \mathop{ { } }\nolimits^{ {T} }X \left) =\frac{ {1} } { {1+e{ }_{ }^{- \theta \mathop{ { } }\nolimits^{ {T} }X} { }_{ }^{ } } }\right. \right. \right. \right. }
hθ(x)=g(θTX)=1+e−θTX1
回归问题和分类问题的代价函数也有所不同。回归问题的代价函数为:
J
(
θ
)
=
1
2
m
(
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
)
{ {J \left( \theta \left) =\right. \right. }\frac{ {1} } { {2m} } { \left( { {\mathop{ \sum }\limits_{ {i=1} }^{ {m} } { { \left( {h\mathop{ { } }\nolimits_{ { \theta } } { \left( {x\mathop{ { } }\nolimits^{ { \left( i \right) } } } \right) }-y\mathop{ { } }\nolimits^{ { \left( i \right) } } } \right) }\mathop{ { } }\nolimits^{ {2} } } } } \right) } }
J(θ)=2m1(i=1∑m(hθ(x(i))−y(i))2)
含义显而易见,就是要最小化预测值和真实值之间的误差。其中m为样本个数,x^i为第i个样本。前面的分母为2m的原因可能是求导方便。
分类问题的代价函数为:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
]
{J{ \left( { \theta } \right) }=-\frac{ {1} }{ {m} }{\mathop{ \sum }\limits_{ {i=1} }^{ {m} }{ { \left[ {y\mathop{ { } }\nolimits^{ { \left( i \right) } }log{ \left( {\mathop{ {h} }\nolimits_{ { \theta } } { \left( {\mathop{ {x} }\nolimits^{ { \left( i \right) } } } \right) } } \right) }+{ \left( {1-y\mathop{ {} }\nolimits^{ { \left( i \right) } } } \right) }log{ \left( {1-\mathop{ {h} }\nolimits_{ { \theta } }{ \left( {\mathop{ {x} }\nolimits^{ { \left( i \right) } } } \right) } } \right) } } \right] } } } }
J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
由于标签只有0和1,而预测值是0~1之间的小数,所以采用这个代价函数更能反映预测的误差。
梯度下降算法
对代价函数求导,以一个学习率来逐渐更新需要学习的参数。
θ
←
θ
−
α
∂
J
∂
θ
{ \theta \leftarrow \theta - \alpha \frac{ { \partial J} } { { \partial \theta } } }
θ←θ−α∂θ∂J
其中,mini-batch算法可以在训练集中取一部分求损失,然后进行梯度下降,这样可以提升速度。
正则化
正则化是防止过拟合的算法。在损失函数的基础上,加入参数项的惩罚项,目的是不让参数的值过大而产生比较歪歪曲曲的函数。如分类问题正则化代价函数为:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
+
λ
2
m
∑
j
=
1
n
θ
j
2
]
{J{ \left( \theta \right) }=-\frac{ {1} }{ {m} }{\mathop{ \sum }\limits_{ {i=1} }^{ {m} }{ \left[ {y\mathop{ {} }\nolimits^{ { \left( i \right) } }log{ \left( {\mathop{ {h} }\nolimits_{ \theta }{ \left( \mathop{ {x} }\nolimits^{ { \left( i \right) } } \right) } } \right) }+{ \left( {1-y\mathop{ {} }\nolimits^{ { \left( i \right) } } } \right) }log{ \left( {1-\mathop{ {h} }\nolimits_{ \theta } { \left( \mathop{ {x} }\nolimits^{ { \left( i \right) } } \right) } } \right) }+\frac{ { \lambda } }{ {2m} }{ {\mathop{ \sum }\limits_{ {j=1}}^{ {n} }{ \theta \mathop{ { } }\nolimits_{ {j} }^{ {2} } } } } } \right] } } }
J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))+2mλj=1∑nθj2]
需要注意的是,正则化不作用于偏移项。
神经网络
(略,在我的吴恩达深度学习课程笔记中有这一部分的介绍。)
支持向量机
支持向量机是一个分类器,具体来说是最大间距分类器。
其优化目标和前面提到的logistic分类问题有些相似,具体是:
m
i
n
θ
C
∑
i
=
1
m
[
y
(
i
)
c
o
s
t
1
(
θ
T
x
(
i
)
)
+
(
1
−
y
(
i
)
)
c
o
s
t
0
(
θ
T
x
(
i
)
)
]
+
1
2
∑
j
=
1
n
θ
j
2
{ \mathop{ {min} }\limits_{ { \theta } }\text{ }C{\mathop{ \sum }\limits_{ {i=1} }^{ {m} }{ { \left[ {y\mathop{ {} }\nolimits^{ { \left( i \right) } }cost\mathop{ {} }\nolimits_{ {1} }{ \left( { \theta \mathop{ {} }\nolimits^{ {T} }\mathop{ {x} }\nolimits^{ { \left( i \right) } } } \right) }+ \left( 1-y\mathop{ {} }\nolimits^{ { \left( i \right) } } \left) cost\mathop{ {} }\nolimits_{ {0} }{ \left( { \theta \mathop{ {} }\nolimits^{ {T} }x\mathop{ {} }\nolimits^{ { \left( i \right) } } } \right) }\right. \right. } \right] } } }+\frac{ {1} }{ {2} }{\mathop{ \sum }\limits_{ {j=1} }^{ {n} }{ \theta \mathop{ {} }\nolimits_{ {j} }^{ {2} } } } }
θmin Ci=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21j=1∑nθj2
C为调节正则化的参数。
支持向量机和logistic分类不同的是支持向量机只返回0或1(是正样本还是负样本)的结果,并不会返回一个0~1之间的小数来表征概率。因为支持向量机是通过超平面将特征划分为两类的,其中法向量指向的是正类,另一侧为负类。
支持向量机的大边界分类的原理可以简单概括为在满足两个cost函数为0的情况下,最小化后面的正则项,即:
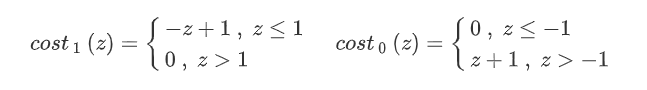
其中,pi为xi在向量θ上的投影。
要使得θ越小,所以p就得越大,由于θ参数是分类超平面的法向量,也就是说每个样本的特征向量在分类超平面的法向量的投影需要越大越好,也就是说每个样本的特征向量和分类超平面的法向量夹角越小越好。如图所示:
为了解决分类中的非线性问题,支持向量机引入了核函数的方法。
由于SVM分类器(未引入核函数之前)的模型是线性的,不能很好的对如下图所示的情况进行分类。所以需要引入核函数来处理非线性的问题。
核函数的解决方案是用新的特征f来代替输入向量的特征x,从而构造新的假设函数:
h
θ
(
x
)
=
θ
1
f
1
+
θ
2
f
2
+
.
.
.
+
θ
n
f
n
{ {\mathop{ {h} } \nolimits_{ { \theta } } { \left( {x} \right) } } =\mathop{ { \theta } } \nolimits_{ {1} } \mathop{ {f} } \nolimits_{ {1} } +\mathop{ { \theta } } \nolimits_{ {2} } \mathop{ {f} } \nolimits_{ {2} } +...+\mathop{ { \theta } } \nolimits_{ {n} } \mathop{ {f} } \nolimits_{ {n} } }
hθ(x)=θ1f1+θ2f2+...+θnfn
新的特征f如何构造呢?首先我们选取标定向量l,l的选取方法为训练集中每个x的位置。即:
l
(
1
)
=
x
(
1
)
,
l
(
2
)
=
x
(
2
)
.
.
.
l
(
n
)
=
x
(
n
)
{l\mathop{ {} } \nolimits^{ { { \left( {1} \right) } } } =x\mathop{ {} } \nolimits^{ { { \left( {1} \right) } } } ,{l\mathop{ {} } \nolimits^{ { { \left( {2} \right) } } } =x\mathop{ {} } \nolimits^{ { { \left( {2} \right) } } } ...{l\mathop{ {} } \nolimits^{ { { \left( {n} \right) } } } =x\mathop{ {} } \nolimits^{ { { \left( {n} \right) } } } } } }
l(1)=x(1),l(2)=x(2)...l(n)=x(n)
给定一个训练实例x^i,分别对每个l求近似程度来构成新的特征f。求近似程度(f与x/l之间的映射关系)的方法就是我们说的核函数。下面以常用的高斯核函数为例说明其过程:
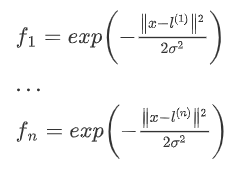
经过以上过程的处理,成功的在假设函数中用f替代了x,接下来的处理过程同上面介绍的线性的SVM。
K-means聚类
K-means是一种聚类算法,属于无监督学习。
可以设置K个聚类中心,也就是将你的训练样本分为K类。算法原理是首先,随机设置K个点,然后将每个训练样本归类到最近的聚类中心,然后将每个聚类中心移动到所以这一类的样本的平均值的位置。重复执行这个过程,直到距离中心不再变化。
需要充分理解K-means算法的损失函数,即:
J
(
c
(
1
)
,
.
.
.
c
(
m
)
,
μ
1
,
.
.
.
,
μ
K
)
=
1
m
∑
i
=
1
m
∥
X
(
i
)
−
μ
c
(
i
)
∥
2
{J{ \left( {c\mathop{ {} } \nolimits^{ { \left( 1 \right) } } ,...c\mathop{ {} } \nolimits^{ { \left( m \right) } } , \mu \mathop{ {} } \nolimits_{ {1} } ,...,\mathop{ { \mu } } \nolimits_{ {K} } } \right) } =\frac{ {1} } { {m} } {\mathop{ \sum } \limits_{ {i=1} } ^{ {m} } { { \left\Vert {X\mathop{ {} } \nolimits^{ { \left( i \right) } } - \mu \mathop{ {} } \nolimits_{ {c\mathop{ {} } \nolimits^{ { \left( i \right) } } } } } \right\Vert } \mathop{ {} } \nolimits^{ {2} } } } }
J(c(1),...c(m),μ1,...,μK)=m1i=1∑m∥∥∥X(i)−μc(i)∥∥∥2
其中,ci是指xi所属于是聚类中心,μ是指各个聚类中心的位置。
PCA
PCA (Principal Component Analysis,主成分分析)是一种降维算法。比如需要将三维的数据集降为二维,就是寻找一个离数据点最近的平面,将数据点映射到此平面内。下图为二维数据集降为一维:
PCA算法的数学原理可以参考我的另一篇文章。
异常检测
感觉异常检测算法既可以看做监督学习,又可以看做无监督学习,有点迷。
异常分析简单讲就是将数据归一化之后,建立高斯分布模型。然后设置阈值,未能达到阈值的样本就认为是异常样本。
算法具体步骤是对给定数据集,计算每一个维度特征的均值μ和方差σ2。
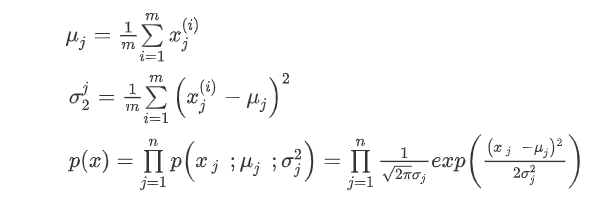
当
p
(
x
)
<
ε
p(x)<ε
p(x)<ε时认为是异常。
但是上述算法存在问题,如图所示:
可以通过构建协方差矩阵来解决。当然通过自己根据特征的相关性添加新的组合特征向量也可以解决此问题。
推荐系统
推荐系统是根据用户对已有部分产品的评价来自动的为用户推荐同类产品,从而产生广告效益。(ps:很赚钱)
课程中讲的问题实例是推荐电影。利用已有的各个用户的评分数据去学习下图中?的数据。其中x1,x2可以看做是每个电影的类别信息,x项的多少可以根据情况设定。
采用的方法是协同过滤算法:
J
(
x
(
1
)
,
.
.
.
,
x
(
n
m
)
,
θ
(
1
)
,
.
.
.
,
θ
(
n
u
)
)
=
1
2
∑
(
i
,
j
)
:
r
(
i
,
j
)
=
1
(
(
θ
(
j
)
)
T
x
(
i
)
−
y
(
i
,
j
)
)
2
+
λ
2
∑
i
=
1
n
m
∑
k
=
1
n
(
x
k
(
i
)
)
2
+
λ
2
∑
j
=
1
n
u
∑
k
=
1
n
(
θ
k
(
j
)
)
2
{J{ \left( {x\mathop{ {} } \nolimits^{ { \left( 1 \right) } } ,...,x\mathop{ {} } \nolimits^{ { \left( \mathop{ {n} } \nolimits_{ {m} } \right) } } , \theta \mathop{ {} } \nolimits^{ { \left( 1 \right) } } ,..., \theta \mathop{ {} } \nolimits^{ { \left( \mathop{ {n} } \nolimits_{ {u} } \right) } } } \right) } =\frac{ {1} } { {2} } {\mathop{ \sum } \limits_{ { \left( i,j \left) :r \left( i,j \left) =1\right. \right. \right. \right. } } { { \left( { { \left( {\mathop{ { \theta } } \nolimits^{ { \left( j \right) } } } \right) } \mathop{ {} } \nolimits^{ {T} } x\mathop{ {} } \nolimits^{ { \left( i \right) } } -\mathop{ {y} } \nolimits^{ { \left( i,j \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } +\frac{ { \lambda } } { {2} } {\mathop{ \sum } \limits_{ {i=1} } ^{ {\mathop{ {n} } \nolimits_{ {m} } } } { {\mathop{ \sum } \limits_{ {k=1} } ^{ {n} } { { \left( {x\mathop{ {} } \nolimits_{ {k} } ^{ { \left( i \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } } } +\frac{ { \lambda } } { {2} } {\mathop{ \sum } \limits_{ {j=1} } ^{ {\mathop{ {n} } \nolimits_{ {u} } } } { {\mathop{ \sum } \limits_{ {k=1} } ^{ {n} } { { \left( { \theta \mathop{ {} } \nolimits_{ {k} } ^{ { \left( j \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } } } }
J(x(1),...,x(nm),θ(1),...,θ(nu))=21(i,j):r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λi=1∑nmk=1∑n(xk(i))2+2λj=1∑nuk=1∑n(θk(j))2
算法执行的过程是先对给定的x来优化θ:
m
i
n
θ
(
1
)
,
.
.
.
,
θ
(
n
u
)
1
2
∑
j
=
1
n
u
∑
i
:
r
(
i
,
j
)
=
1
(
(
θ
(
j
)
)
T
x
(
i
)
−
y
(
i
,
j
)
)
2
+
λ
2
∑
j
=
1
n
u
∑
k
=
1
n
(
θ
k
(
j
)
)
2
{\mathop{ {min} } \limits_{ { \theta \mathop{ {} } \nolimits^{ { \left( 1 \right) } } ,..., \theta \mathop{ {} } \nolimits^{ { \left( nu \right) } } } } \text{ } \text{ } \frac{ {1} } { {2} } {\mathop{ \sum } \limits_{ {j=1} } ^{ {\mathop{ {n} } \nolimits_{ {u} } } } {\mathop{ \sum } \limits_{ {i:r \left( i,j \left) =1\right. \right. } } { { \left( { { \left( \mathop{ \theta } \nolimits^{ { \left( j \right) } } \right) } \mathop{ {} } \nolimits^{ {T} } x\mathop{ {} } \nolimits^{ { \left( i \right) } } -\mathop{ {y} } \nolimits^{ { \left( i,j \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } } +\frac{ \lambda } { {2} } {\mathop{ \sum } \limits_{ {j=1} } ^{ {\mathop{ {n} } \nolimits_{ {u} } } } {\mathop{ \sum } \limits_{ {k=1} } ^{ {n} } { { \left( { \theta \mathop{ {} } \nolimits_{ {k} } ^{ { \left( j \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } } }
θ(1),...,θ(nu)min 21j=1∑nui:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λj=1∑nuk=1∑n(θk(j))2
让用给定的θ来优化x:
m
i
n
x
(
1
)
,
.
.
.
,
x
(
n
m
)
1
2
∑
i
=
1
n
m
∑
j
:
r
(
i
,
j
)
=
1
(
(
θ
(
j
)
)
T
x
(
i
)
−
y
(
i
,
j
)
)
2
+
λ
2
∑
i
=
1
n
m
∑
k
=
1
n
(
x
k
(
i
)
)
2
{\mathop{ {min} } \limits_{ {x\mathop{ {} } \nolimits^{ { \left( 1 \right) } } ,...,x\mathop{ {} } \nolimits^{ { \left( \mathop{ {n} } \nolimits_{ {m} } \right) } } } } \text{ } \text{ } \frac{ {1} } { {2} } {\mathop{ \sum } \limits_{ {i=1} } ^{ {\mathop{ {n} } \nolimits_{ {m} } } } { {\mathop{ \sum } \limits_{ {j:r \left( i,j \left) =1\right. \right. } } { { \left( { { \left( {\mathop{ { \theta } } \nolimits^{ { \left( j \right) } } } \right) } \mathop{ {} } \nolimits^{ {T} } x\mathop{ {} } \nolimits^{ { \left( i \right) } } -\mathop{ {y} } \nolimits^{ { \left( i,j \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } } } +\frac{ { \lambda } } { {2} } {\mathop{ \sum } \limits_{ {i=1} } ^{ {\mathop{ {n} } \nolimits_{ {m} } } } { {\mathop{ \sum } \limits_{ {k=1} } ^{ {n} } { { \left( {x\mathop{ {} } \nolimits_{ {k} } ^{ { \left( i \right) } } } \right) } \mathop{ {} } \nolimits^{ {2} } } } } } }
x(1),...,x(nm)min 21i=1∑nmj:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λi=1∑nmk=1∑n(xk(i))2
迭代执行上述两个优化过程,从而实现对总的损失函数J(x,θ)进行优化。














 6992
6992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









