




报告主题:“知人者智”:以用户为中心的智能体交互与训练
报告日期:10月16日(周四) 10:30-11:30
报告要点:
大语言模型虽在各种评测体系中表现出色,却常在面对真实用户时把握不准需求,显得有些笨拙。现实中,用户意图通常以暗示、含蓄、间接的方式表达,且往往要在多轮对话中慢慢显露。如何让模型从仅仅“会解题”过渡到完全“懂用户”,是交互智能的核心难题,也是 UIUC 与 Salesforce 团队在以下两篇论文里试图回答的关键问题。
1. UserBench:先有“明镜”,才能照出“懂人”与否
UserBench 最标志性的设计,是旅行规划任务,覆盖五个子场景,每个场景都设有数十条隐式偏好表述,例如“行程很紧”就暗含“直飞/少中转”的飞行偏好。模型需要与环境中的模拟用户互动,理解每一句话背后的语义逻辑,再结合数据库作出推荐。
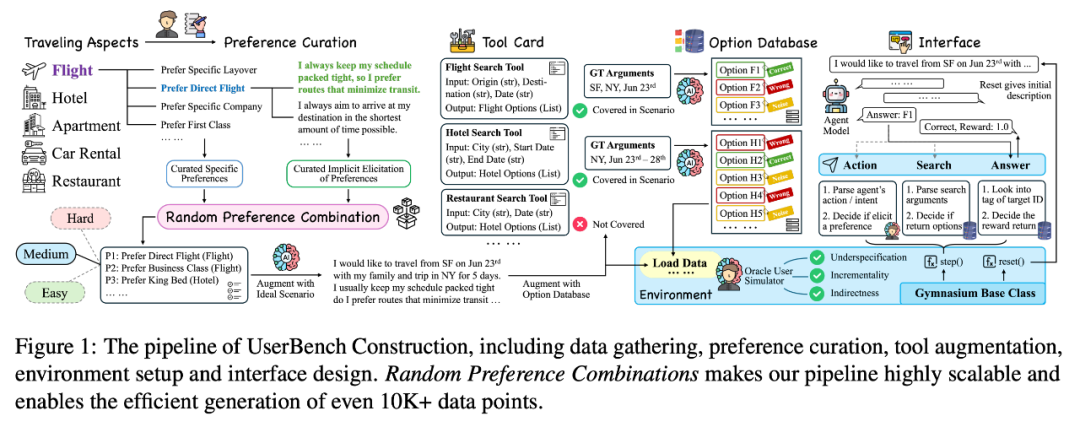
以往模型、用户和环境三方交互接口复杂且难以复用,UserBench 将其高度抽象为三类操作:
- Action:与用户对话(澄清、追问、确认偏好);
- Search:检索数据库(返回混合候选集,模拟真实世界的不完美检索);
- Answer:提交推荐(完成用户需求)。
不同任务得以在同一坐标系下评估比较,为后续 UserRL 的训练框架打下了接口基础。
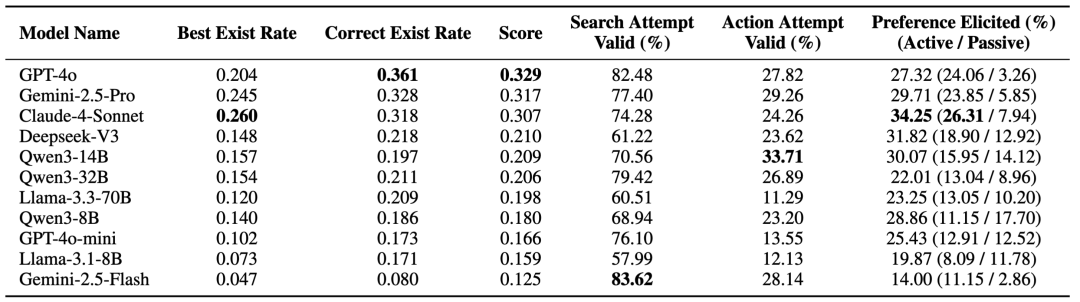
研究结果揭示了许多关键信息:
单选比多选难很多:把模型可回答次数限制为一次,平均分数下滑约 40%,暴露了“一次答题”的抉择困难;
用户偏好揭示率普遍偏低:主流模型仅 ~20% 的答案完全贴合全部用户意图,即便是强模型,通过主动互动挖掘到的用户偏好也不到 30%;
会用工具≠真懂用户:模型普遍有效搜索>80%,但有效对话显著更低,“循证澄清”难度更高;
偏好集中时更难:总偏好数固定时,把偏好平均分散到多个需求更容易,而集中在少数需求上会显著拉低分数,说明挑战来自局部约束的组合复杂度;
更多对话轮数≠更好表现:盲目拉长交互轮数并不能带来收益;命中答案的“时效性”与整体模型对话质量也不总是正相关:小模型“早早猜中”整体也不如大模型的“稳扎稳打”。
2. UserRL:让交互进入训练循环
如果说 UserBench 是一面明镜,那 UserRL 就是一块磨刀石,在 UserBench 抽象出的三个接口上,构建八大统一 Gym 环境,把 User-in-the-Loop 的多轮交互转化为一个可训练的强化学习问题。在每个环境中,用户同样由 LLM 模拟,并且可以更换不同用户模型,实现交互多样性。
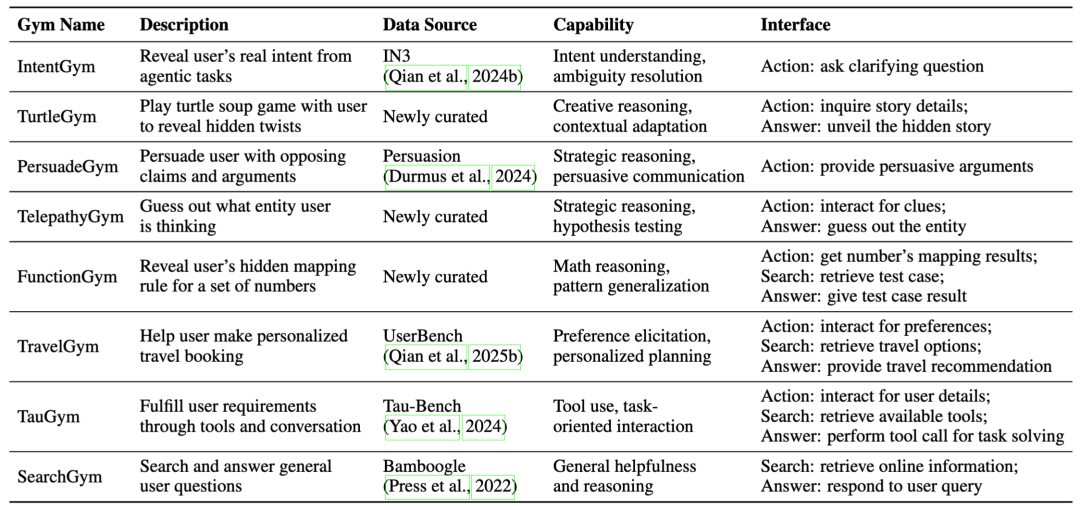
UserRL 框架的核心特点:
- 确定性任务状态和可验证奖励函数;
- 自然语言互动,保留动态模拟用户对话的开放性;
- 多轮 rollout,让模型在交互中做出策略性选择。
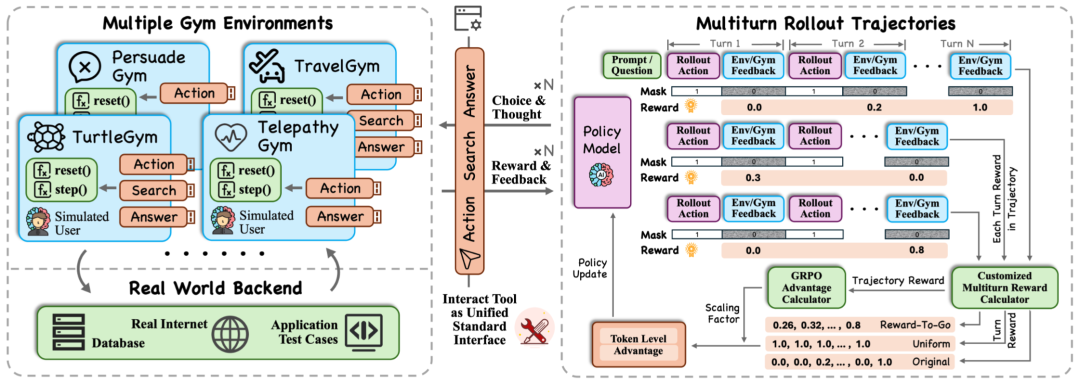
实际训练中,采用回合层、轨迹层双层奖励,可灵活组合,适配不同交互任务。
回合层(Turn-level):
- Naive:直接用环境奖励,但往往稀疏;
- Equalized:为所有回合赋予同样奖励;
- R2G:把未来预期奖励折扣回流;
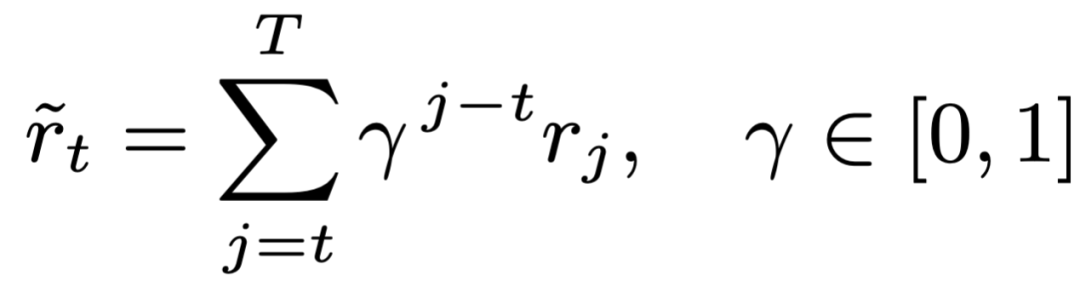
- EM:非线性映射,小进展也能带来正反馈。
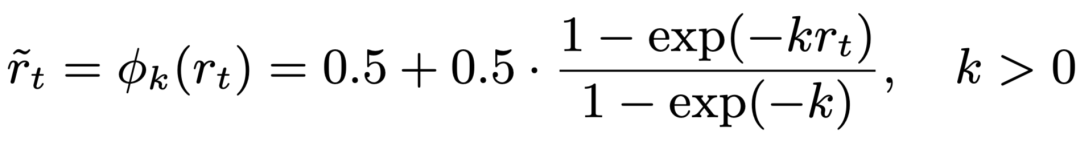
轨迹层(Trajectory-level):
- Sum:直接累积每回合奖励;
- R2G:早期进展赋予更高价值,更强调任务完成效率。
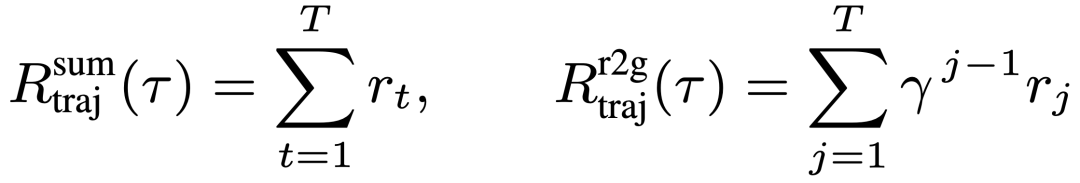
研究主要发现:
“回合均等 + 轨迹 R2G”在 4B/8B 模型上最稳健、平均最好;
“回合均等 + 轨迹 Sum”最弱,说明轨迹级计分比回合级奖励细分更具决定性价值;
经过 UserRL 训练的 Qwen3 在 TravelGym、PersuadeGym、IntentionGym 等交互型任务上能够超过强闭源模型;跨 8 个 Gym 的平均也领先闭源对照;
用户模拟器选择很关键:GPT-4o 做模拟用户下游更强,但 Qwen3-32B 具备高性价比和可迁移优势。

UserBench 论文链接:https://arxiv.org/pdf/2507.22034
UserBench 代码仓库:https://github.com/SalesforceAIResearch/UserBench
UserRL 论文链接:https://arxiv.org/pdf/2509.19736
UserRL 代码仓库:https://github.com/SalesforceAIResearch/UserRL
(所有代码,环境以及训练框架全部开源,欢迎研究者们使用)
报告嘉宾:
钱成,伊利诺伊大学香槟分校 (UIUC) 二年级博士生,导师为季姮教授。本科就读于清华大学计算机系,导师为刘知远教授。目前工作集中在大语言模型工具使用与推理,以及人工智能体方向。曾在 ACL,EMNLP,COLM,COLING,NAACL,ICLR 等多个学术会议发表论文十余篇,一作及共一论文十余篇,谷歌学术引用超 1000,现担任 ACL, EMNLP Area Chair,以及 AAAI,EMNLP,Neurips,COLM 等多个会议 Reviewer。

👆扫码报名👆或者点击「阅读原文」报名


















 14
14

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









