







 本文详细探讨了Oracle Hash Join的三种执行模式:Optimal Hash Join、Onepass Hash Join和Multipass Hash Join,包括它们的执行机制、代价模型及优化策略。文章指出,Hash Join的核心在于构建Hash表并通过位图(Bloom Filter)优化过滤。通过对不同执行模式的分析,揭示了Oracle在内存限制下如何处理大表连接,特别是Multipass Hash Join的优化思路,以减少重复I/O。
本文详细探讨了Oracle Hash Join的三种执行模式:Optimal Hash Join、Onepass Hash Join和Multipass Hash Join,包括它们的执行机制、代价模型及优化策略。文章指出,Hash Join的核心在于构建Hash表并通过位图(Bloom Filter)优化过滤。通过对不同执行模式的分析,揭示了Oracle在内存限制下如何处理大表连接,特别是Multipass Hash Join的优化思路,以减少重复I/O。
从整体上看,Oracle的Hash Join的原理和其它主流数据库的Hash Join的原理大致是一样的,只是Oracle对Hash Join进行了更为细粒度的划分,其中最为主要的就是,Oracle根据其内部的hash_area_size、_hash_multiblock_io_count、db_block_size以及需要构建hash的表(也即我们所说的Hash Join的内表)的大小等值将Hash Join分为三种不同的执行方式:最优Hash Join(Optimal Hash Join),一遍Hash Join(Onepass Hash Join),多遍Hash Join(Multipass Hash Join),本文主要讲解Oracle的上述三种Hash Join的具体执行机制以及Oracle选择每种执行方式的条件。
1. Parameters
在讲解Oracle的Hash Join之前,我们首先得了解一下与Oracle Hash Join有关的参数,具体如下:
1) hash_area_size:Oracle服务器进程在内存中为构建Hash表所分配的存储空间。
2) _hash_multiblock_io_count:Oracle在构建Hash表的时候,一次能够从磁盘向内存读取数据的块数,在早期的版本中,该值默认为9,但是,现在可以通过Alter Session语句进行动态设置。
3) db_block_size:Oracle磁盘文件的块大小,默认为8KB。
个人认为与Hash Join有关的核心参数就这三个,当然这三个参数均是在SGA、PGA、UGA等参数的控制之下进行设置的,因此,如果想要详细了解Hash Join的执行的每个细节,建议查阅Oracle的相关资料,熟悉Oracle的这些参数的配置情况,用以在不同的系统环境中进行最为合适的设置,使HashJoin的性能得到最大化的提升。
2. Oracle Inner and Outer
在Oracle的Nest Loop连接中,通常将距离Join较近的表称为Outer表,将距离Join较远的表称为Inner表,但是,在Hash Join的时候,并没有Outer和Inner表之分,只有Build和Probe的说法。
1) Build:也即我们所说的Hash Join中需要构建Hash表的“构建”表,处于Oracle连接计划的外层,距离Join较近。
2) Probe:也即我们所说的需要对Build中的每个值进行“探测”的表,处于Oracle连接计划的内层,距离Join较远。
因此,和其他连接计划不同,在Oracle中,我们将Build表称为Inner表,将Probe表称为Outer表。
3. Hash Join Mechanism
在了解Oracle的具体是如何实现Hash Join之前,我们有必要大致了解一下Hash Join的实现机制。
首先,获取一个数据集,利用一个作用于连接键上的内部Hash函数对数据集中的每一条记录计算Hash键值,让后通过该键值将记录定位存储到Hash表的某个桶中,当数据集遍历完成后,Hash表也就构建完成。
然后,开始获取第二个数据集中的记录,用相同的内部Hash函数作用于该记录的连接键上计算Hash键值,查看在存储器中的Hash表中是否能够定位到一个匹配的记录,如果匹配,在抛出该记录,如果不匹配,这舍弃该记录,继续获取下一条记录,当第二个数据集遍历完成后,也就完成了Hash Join。
因此,可以看出,由于作用于连接键上的散列函数会使得Hash表中的数据随机分布,因此,只有当连接条件为等值连接的时候,Hash Join方可正常执行。
由于需要构造Hash表,因此Hash Join的工作方式与第一个数据集的大小以及Oracle的hash_area_size的值有关,Oracle会根据具体的情况,将Hash Join分为三种执行模式:Optimal Hash Join、Onepass Hash Join、Multipass hash Join,接下来,我们就分别了解一下这三种Join的执行前提条件以及具体的执行机制。
4. Optimal Hash Join
如果,Build表的数据集很小,可以完全存放到hash_area_size中,那么,此时Oracle会执行最优的Hash Join(Optimal Hash Join),如下如所示:
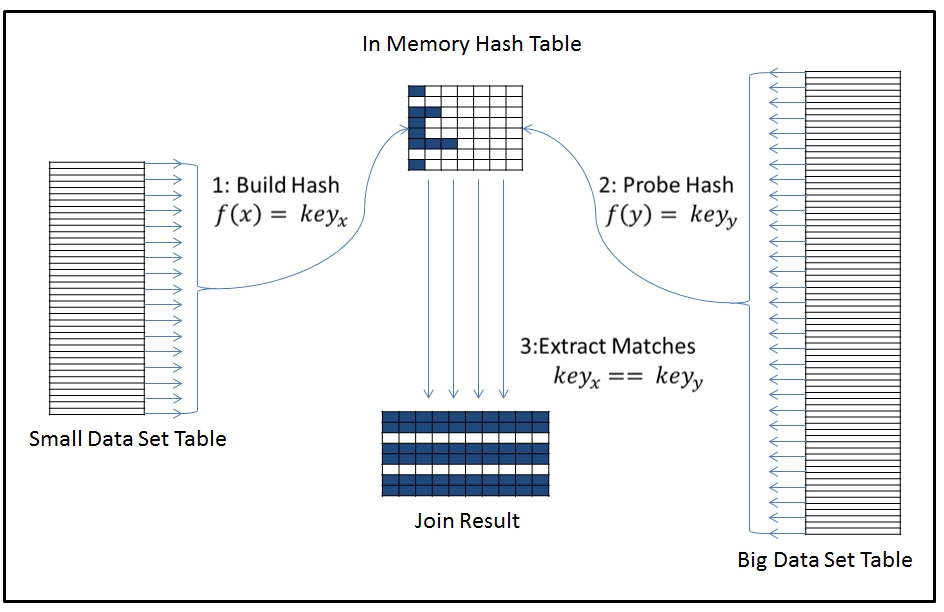
图表 4‑1 Oracle Optimal Hash Join
执行步骤如下:
1) 构建Hash表:Oracle读取第一个数据集(小表数据集),并在内存中建立一个Hash桶(Hash Bucket)数组,数组中的每一个初始元素作为构建表中行的链表的开始位置。Oracle从小表中读取一条记录,通过作于该条记录的连接键上的内部Hash函数计算出一个Hash键值,该键值即为Hash桶数组的下标,然后根据该下标,定位到相应的Hash桶,存放记录,然后读取下一条记录。Hash桶数组的长度一般是2的偶数次幂。Hash桶数组是一个固定数组和链表所组成的复合数据结构,我们可以简单的将其看成一个矩阵,通过内部的Hash函数,使得构建表的数据随机分布于该矩阵之中。
2) 扫描探测表:在内存中构建完Hash表后,Oracle开始读取第二个数据集(大表数据集),针对读取到的每一条记录,用相同的内部Hash函数作用于连接键上计算出一个Hash键值。
3) 探测:根据第二步得到的Hash键值,看能否定位到内存Hash桶数组中,如果该键值不在Hash桶数组所表示的范围之内,则丢弃扫描到的记录,然后读取下一行,如果该键值在Hash桶数组所表示的范围之内,由于作用于不同值的Hash函数可能会产生相同的Hash键值,因此还需要定位到该Hash桶中,在Hash桶的记录链表上进行精确匹配,如果能够匹配上,则抛出该条记录,如果不能够匹配,则丢弃该条记录,并读取下一条记录,直到读取完第二个数据集中的所有数据。
从上面的执行流程中可以看出,如果在所有的桶中最多都只有一条记录,或者所有桶中的记录数很少,那么在进行探测的时候,就会减少大量的精确匹配,连接的效率也就会高很多,因此,一旦Hash Join开始执行,Oracle就会从hash_area_size中申请大量的空间(默认情况下占用hash_area_size的80%)用于创建大量的Hash桶,尽量将每个桶的冲突链减小到最少。
5. Onepass Hash Join
在大多数情况下,Optimal Hash Join太过理想,因为它要求整个Build所建立的Hash桶数组能够被存放于内存中,但是,如果hash_area_size比较小,Build所建立的Hash桶数组只能有一部分存放于内存中,而另一部分必须要存放于磁盘中,这种情况Oracle会如何处理呢?这时候,如果hash_area_size不是特别的小(至于什么情况是特别的小,我们讲解了MultipassHashJoin你就知道了),那么Oracle会选择一种被称为Onepass Hash Join的方式进行Hash连接。Onepass Hash Join的工作机制如下图所示:
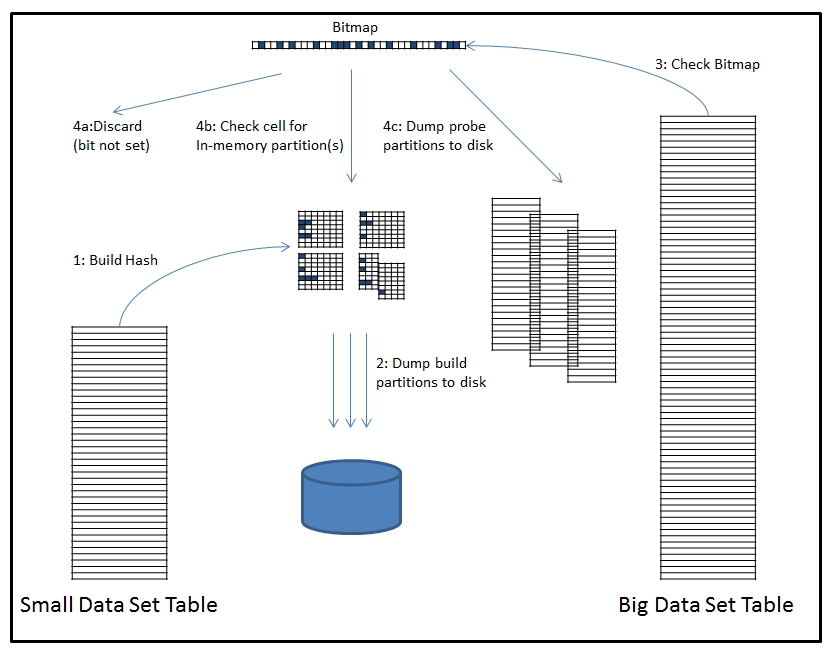
图表 5‑1 Oracle Onepass Hash Join
从上图可以看出,在Onepass Hash Join的模式下,由于Hash桶数组比较大,Oracle不得不将Hash桶数组中的部分Bucket数组转储到磁盘(图中步骤2:Dump build partitionsto disk),然后再重新读入。与此同时,Probe表中某些未匹配上的记录还不能够丢弃,也必须转储到磁盘上(图中步骤4c:Dump probe partitions to disk),然后重新读入,和剩下的Bucket数组进行匹配。
注意对比图表5-1和图表4-1,为了解释最为原始的Hash Join,我们可以看出图表4-1中省略了一个位图(Bitmap),位图的概念是在Oracle后来的版本中引入的,在Oracle中该位图被称为Bloom Filter,该位图中的每一个位表示Hash表中的每一桶。当某个构建行被Hash到某一个特定的桶时,就在位图中设置该桶所对应的位。
所以,不难理解,图表4-1中也应该有个位图,该位图中的相应位是在为Build表构建Hash桶数组的时候被标记的,在执行探测的时候,首先查看该行记录在位图中是否有标记,如果有,再到内存中的Hash桶数组中进行精确匹配,否则直接抛弃该条记录。当然,等到此时才来解释Optimal Hash Join的位图从某种程度看来显得比较晚,但是为了使得展示最为原始的Hash Join的工作机制变得简单,这种做法也就没有什么不妥之处了。
在Onepass Hash Join的过程中,除Bitmap位图占用的空间之外,hash_area_size其余的空间被分解为chunk块(又称为簇或者槽,clusters or slots),这些簇的大小是由db_block_size和参数_hash_multiblock_io_count指定的,其中_hash_multiblock_io_count在早期的Oracle版本中的默认值为9,但是,现在可以在每个查询优化的时候进行动态的设置。簇的大小通过以下公式进行计算:
从上图可以看出,被分解的一部分簇用于创建Hash表,而这些簇所占用的内存又被分为4个独立的分区(partitions)(至于为什么被分成4个独立的分区,而不是8个,或者16个,对于分区数字的选择机制,Oracle没有明确的说明,但就我个人看来,Oracle极有可能会根据统计信息中Build表的大小,以及Build表的Distinct值的数目,以及hash_area_size中能够用于创建Hash表的空间大小来大致估算出一个分区数目,在原则上满足每个分区的数据均匀分布,每个分区所出现的Distinct值大致相同,而且单个分区能够完全存放进hash_area_size用于构建Hash表的空间中,因此,图中的4个分区,仅仅是一个假设值,为了便于理解,在实际应用中,它不一定就是4,有可能是其它值),分区的数目一般是2的幂次数,除了这些分区所占用的空间外,剩下的内存簇主要用于满足向磁盘转储Hash表时预期的I/O要求(比如,图中右下侧的Hash分区显示,该分区中的一个簇即将要转储到磁盘上)。
这里值得一提的是,在上图中,我们将各个分区都划分为块数相同的整齐小方格,目的是为了直观的表示出Hash桶在Hash表中的“逻辑标识”。在任何实际,构成每个分区的内存块数目可能不同。
| 究竟什么是“分区” 有人可能对分区难以理解,在Oracle中,“分区”表示的概念后很多,我们可以这样去理解Oracle Onepass Hash Join中的分区:假设Oracle的内存足够大,因此Build表能够被完全存放于内存中,那么我们就可以为Build表构建一个完整的,没有分区概念(或者说只有一个分区)的Hash桶数组,我们假设这个Hash桶数组就如实的放在了内存里面了,因此,我们就应该知道这个Hash桶数组的长度,每一个桶里面所存储的记录数目以及每个桶中记录所占用的空间,但这只是我们假设的情况,是一个逻辑上的假想,实际上,我们只能够一次将这个Hash桶数组的一部分存放于hash_area_size中用于构建Hash表的空间中,因此,我们就只能够根据其每个桶中所存储的记录占用的空间大小将这个完整的Hash桶数组分成若干区域,区域数通常是2的幂次数,我们将这些区域就称为“分区”,因此,为了满足数据在量上面的均匀分区,每个区域所包含的Hash桶数目可能会不同(比如,整个Hash表有8个桶,每个桶的冲突连长度分别为3、3、3、2、1、0、3、3,而每次只能够向内存中最多存放9条记录,因此,Oracle就可以将整个Hash桶数组分成2个分区,第一个分区拥有Hash桶数组中的前面3个桶所包含的记录,而第二个分区拥有Hash桶数组中后面5个桶所包含的记录,因此第一个分区会占用3个Bucket入口,第二个分区会占用5个Bucked入口,虽然Hash桶数组中的第六个Bucket中并没有任何数据,但它也要占用一个Bucked入口空间),只不过,我们通过这种假象所得到的分区数目,Oracle是通过一定的上下文环境(就像我前面所猜想的,通过统计信息等数据)得到的,那么,现在就应该理解,为什么在实际情况下,构成每个分区的内存块数目可能不同了。 |
Oracle的Onepass Hash Join的执行步骤如下:
1) 获取Build表中的数据集,并将其分布到散列表中,一旦某个桶被使用,则设置该桶在位图中的对应位。
2)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









