






有这样一部网文~火遍大江南北,人物形象饱满,现实世界、网游世界、职业联赛三个世界线并行,且不同世界线之间互动丰富、交叉紧密,还号称网文界的“CP百科全书”~它就是《全职高手》!

当然,情节这么丰富的文自然篇幅不会小~洋洋洒洒500w字,怕不是要让诸多读者望而生畏~我,为了帮助广大读者理清人物关系,决心和大家一起通过先进的技术手段,用文本挖掘的方式提取网文内容,选出优质的网文作品!!~

▼
工具准备:jieba分词
为了提取小说中的关键词,我们需要一个工具——jieba分词。名字很形象哈,结…巴~!来看看怎么用~
i. 导入jieba包,写一句话,作为分词的素材。
1import jieba
2txt = '大夏天的,开着空调,吃着西瓜,刷着微信,敲着代码,别提有多酸爽!'
ii. 直接使用jieba的cut()方法,对句子进行分词处理,返回的是一个生成器。只要是生成器,就可以用遍历来读取。
1txt_cut = jieba.cut(txt)
2print(txt_cut) #这里是一个生成器,可以通过遍历来解析iii. 用斜杠分隔被解析出来的词汇,看看结果如何。
1result = ('/'.join(txt_cut)) #字符串join()方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
2print(result)额…马马虎虎吧,虽然没啥大毛病,但有些不应该被拆的词被拆了,而有些词却应该拆分展示。这怎么办呢?
iv. 人工添加词汇作为词库,提高拆分准确率。方法是jieba.add_word()
1#添加词库,提高分词准确性
2jieba.add_word(word='吃着')
3jieba.add_word(word='刷着')
4jieba.add_word(word='敲着')
5jieba.add_word(word='酸爽')
v. 把这几个词添加入词库,那么它们就不会被拆分了。来看一下效果:
1txt_cut = jieba.cut(txt)
2result2 = ('/'.join(txt_cut))
3print(result2)
4"大/夏天/的/,/开着/空调/,/吃着/西瓜/,/刷着/微信/,/敲着/代码/,/别提/有/多/酸爽/!
比刚才好多了,所有的词都能够准确提炼了。但是,句子中有一些元素,比如标点符号,介词,助词等,分析时候我并不需要,我得把它们给剔除了。
vi. 写一个条件判断删除不需要的词。结果完美!
1#去除停用词
2txt_cut = jieba.cut(txt)
3result3 = [w for w in txt_cut if w not in ['的','有','多','大',',','!']]
4print(result3)
5['夏天', '开着', '空调', '吃着', '西瓜', '刷着', '微信', '敲着', '代码', '别提', '酸爽']
好了,基本用法介绍到这里~我们进行实战操作。
▼
实战操作:分析素材准备
《全职高手》这部网文可是当下最火的”IP”!
i. 作品原文:

去除分析中不必要的字词,我在网上找到这个:
ii. 一份停用词表
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。
停用词表部分内容展示
每部小说都有一些特殊的词汇,为提高分词准确性,我们还需要特殊词库:
iii. 一份小说特殊词库
搜狗细胞词库可以下载小说对应的词库
网址:https://pinyin.sogou.com/dict/

iv. 用词库转换器,把细胞词库转换成txt文本格式,便于处理。
原文、停用词表、特殊词库都准备好了~开始写代码!~
▼
代码编辑:计算关键词频
i. 先导入一些会用到的模块
1import numpy as np
2import pandas as pd
3import jieba
4import wordcloud
5from scipy.misc import imread
6import matplotlib.pyplot as plt
7from pylab import mpl
8import seaborn as sns
9mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
10mpl.rcParams['axes.unicode_minus']
ii. 导入停用词,转换为列表格式。
1stop_list = pd.read_csv('./停用词.txt',engine='python',\
2 encoding='utf-8',names=['t'])['t'].tolist()
iii. 导入小说原文(这里需要运行约30秒,小说字太多有500W)
1f = open('./全职高手.txt',encoding='utf-8').read()
iv.导入词库字典,这里词很多,用load_userdict()方法批量导入,而不用前文jieba介绍中的jieba.add_word()方法
1jieba.load_userdict('dict.txt')
v. 设置一个分词功能的函数,并对小说进行分词
1def txt_cut(f):
2 return [w for w in jieba.cut(f) if w not in stop_list and len(w)>1]
3
4txtcut = txt_cut(f)
vi. 分词完毕,我们对小说的词频取前二十进行简单统计,画出柱状图方便查看
1word_count = pd.Series(txtcut).value_counts().sort_values(ascending=False)[0:20]
2
3fig = plt.figure(figsize=(15,8))
4x = word_count.index.tolist()
5y = word_count.values.tolist()
6sns.barplot(x, y, palette="BuPu_r")
7plt.title('词频Top20')
8plt.ylabel('count')
9sns.despine(bottom=True)
10plt.savefig('./词频统计.png',dpi=400)
11plt.show()
统计结果图&表大致是这样的~
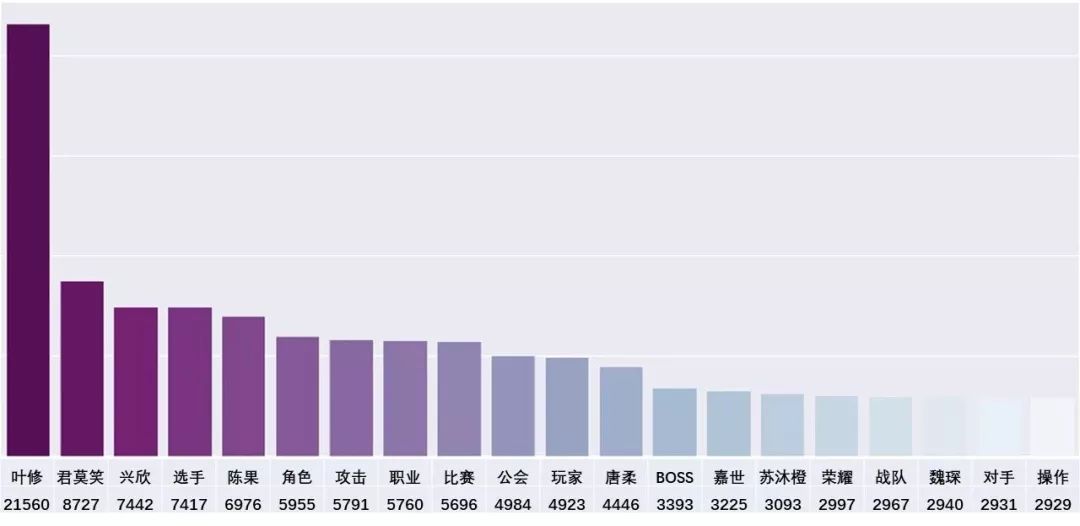
注意到“叶修”这个词,词频高达2W,可以据此推断,他就是本书的男主角;又据说这本书是一部关于游戏的小说,那么词频排名第二的“君莫笑”,应该就是主人公的游戏角色。
作为资深读者的我,看到眼前二十个高频词,就已经可以推断出这部小说的剧情了!~来!我给大家造个句:

▼
可视化展示:词云图
下面,再来玩个有趣的东西:对高频词汇画个词云图。
i. 实例化一个词云类,然后添加分词。
1fig = plt.figure(figsize=(15,5))
2cloud = wordcloud.WordCloud(font_path='./FZSTK.TTF',
3 mask = imread('./background.png'),
4 mode='RGBA',
5 background_color=None
6 ).generate(' '.join(txtcut))
类的属性介绍下:
Font_path: 词云中词的字体,中文词汇必须用中文字体,否则显示会异常。字体文件,大家可以在电脑中字体文件夹中找喜欢的。
Mask: 遮罩,设置词云图案的形状。可以导入图片设置,图片要简单,以面为主,清晰度无所谓,但分辨率一定要调高,否则做出的词云会很不清晰。图片主体不能是纯白色,因为白色被认为是背景,会被忽略识别。
这里我导入一张全职高手的Logo。
Mode: 颜色模式,这里选择RGBA。
Background_color: 背景颜色。

ii. 对词的颜色做点美化
这里用到了scipy和numpy两个库的功能。我们要导入描绘底色的图片,图片尺寸要大于等于遮罩图片的分辨率。计算机会根据底色图的颜色映射到词语图上。所以底色图同样不求清晰,但颜色饱和度要高,对比度要明显!这样效果才好。
1img = imread('./color.png')
2cloud_colors = wordcloud.ImageColorGenerator(np.array(img))
3cloud.recolor(color_func=cloud_colors)
我选了一张全职高手的全家福。

iii. 调用matplotlib接口,做一些基本设置。
1plt.imshow(cloud)
2plt.axis('off')
3plt.savefig('./wordcloud.png',dpi=400)
4plt.show()
绘制完成!见证奇迹吧!

▼
人物关系:CP图
还记得一开始我说《全职高手》是一部CP百科全书吗?我们继续深入挖掘一下文中的人物关系,给他们组一组CP。
挖掘逻辑如下:
遍历文本每一行,再提取每一行中出现的人物,如果两个人物同时出现在同一行,那么他们之间人物关系密切度+1,最后,密切度最高的为最佳CP。
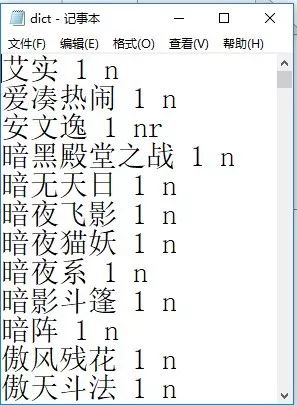
首先需要对词库进行一些完善,筛选出哪些词是人名
字典结构是这样的,一个词占一行,有【词,词频,词性】
词频我们暂时无需关注,写个1代替。词性,我只要甄别出人名,所以,小说中的人名统一设成nr,其余的词,偷个懒,设成n(nr代表人名,n代表名词。其他词性含义可查看词性对照表)
i. 新开一个脚本,导入模块。
1import jieba,codecs
2import jieba.posseg as pseg
3import pandas as pdcodecs库:用来读取文本时,防止文本编码不统一,造成错误;
jieba.posseg:分词后显示词性。
ii. 建立三个容器用于转换数据。
1names = {} #提取的人名,和出现的频数。
2relationships = {} #提取的人物关系。
3lineNames = []#每一行提取的人名,做缓存处理。
iii. 导入词库和文本
遍历文本每一行进行分词。排除词性不为nr,长度大于3小于2的所有词汇(通常人物名字为两个字和三个字)。
iv. 将符合要求的词汇分别添加入容器中
1jieba.load_userdict('dict.txt')
2with codecs.open('全职高手.txt','r','utf8') as f:
3 n = 0
4 for line in f.readlines():
5 n+=1
6 print('正在读取第{}行'.format(n))
7 poss = pseg.cut(line)
8 lineNames.append([])
9 for w in poss:
10 if w.flag != 'nr' or len(w.word) < 2 or len(w.word) > 3:
11 #排除词性不为nr,长度大于3小于2的所有词汇
12 continue
13 lineNames[-1].append(w.word)#以行为组,保存每行所提取的人名
14 if names.get(w.word) is None:
15 names[w.word] = 0
16 relationships[w.word] = {} #把所涉及的人名作为键添加入关系字典
17 names[w.word] += 1#频数+1
v. 遍历lineNames,对每一行出现的人名进行匹配,建立人物关系
1for line in lineNames:
2 for name1 in line:
3 for name2 in line:
4 if name1 == name2:#名称相同,排除
5 continue
6 if relationships[name1].get(name2) is None:
7 relationships[name1][name2]= 1#对于新的人物关系,生成新的键值对。
8 else:
9 relationships[name1][name2] = relationships[name1][name2]+ 1
10 #对于已有的人物关系,密切度+1
我们最终会把人物关系通过Gephi进行模拟。而Gephi构建关系网络,需要特定格式的数据。
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件,,其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。
vi. 这里先构建两个数组,用于归类点数据和边数据
1node = pd.DataFrame(columns=['Id','Label','Weight'])
2edge = pd.DataFrame(columns=['Source','Target','Weight'])
vii. 把清洗好的数据添加进数组中
1for name,times in names.items():
2 node.loc[len(node)] = [name,name,times]
3
4for name,edges in relationships.items():
5 for v, w in edges.items():
6 if w > 3:
7 edge.loc[len(edge)] = [name,v,w]
viii. 导出数据待用
1edge.to_csv('./edge(原).csv',index=0)
2node.to_csv('./node(原).csv',index=0)
脚本编写完毕,运行一下看看。小说一共有206436行,所以,需要计算一段时间:

只分析关系密切的CP,所以我们只取边数据中权重在100以上的数据。按照这个标准,整理点数据和边数据如下::
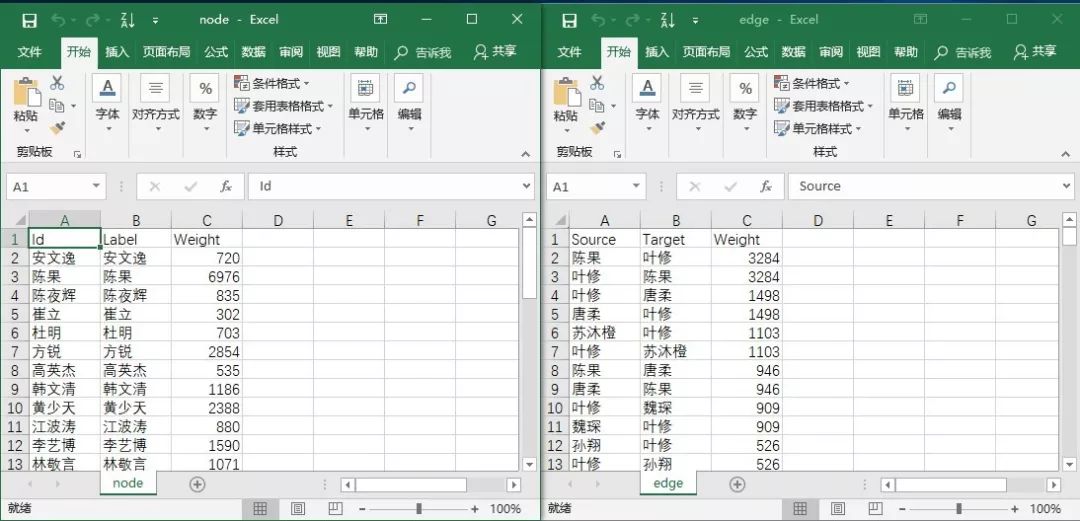
最后,我们把数据导入Gephi。
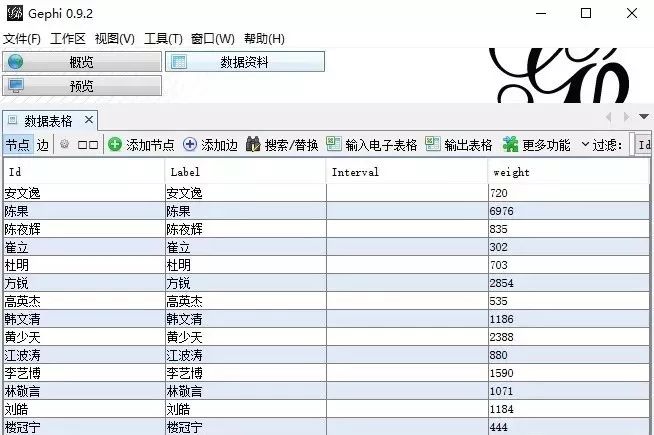
根据对美的认知,调一调颜色和布局。
好了,CP图出现了!

嗯嗯!挺有意思的!人物关系真是复杂得不得了!这里忍不住要剧透了!

叶陈CP:叶修是战队队长,全权负责战队经营。陈果是战队老板娘,霸气侧漏。两人类似于总裁和总经理的关系吧。~~哎,这不是妥妥的霸道总裁爱上我的剧情嘛。
叶唐CP:唐柔是富家千金,才女。不过,不小心让叶修带坏了,迷恋上了打游戏。两人算是师徒和队友关系吧。啧啧~
叶苏CP:这个厉害了!叶修从前认识个兄弟,叫苏沐秋,两人一起打游戏。苏沐秋有个妹妹叫苏沐橙。后来,苏沐秋死了……贵圈真乱啊!
好了,剧透结束。其实,大家有兴趣的话,可以导入更多的数据,然后根据关系网络中簇群的颜色继续研究……
那么,本次分享到此结束!希望大家少看网文,多多学习~!

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼点击下方阅读原文,进入学习Python

















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









