







1、入门
为了方便管理我们一般统一软件的安装目录,这里选择安装的目录是 ->
/usr/local/soft
我们通过wget命令从redis官网下载压缩包 -> Redis
当前最新版本下载地址 -> https://download.redis.io/releases/redis-6.2.4.tar.gz
- cd /usr/local/soft
- wget https://download.redis.io/releases/
tar -zxvf redis-6.2.4.tar.gz
Redis是C语言编写,编译需要GCC
Redis6.x.x版本支持了多线程,需要gcc的版本大于4.9,我们需要查看默认GCC版本,如果版本过低则需要升级
gcc -v
我的新安装的虚拟机CentOS显示 ->

证明我的没有安装gcc,安装gcc ->
yum install gcc

再次查看安装后的版本,发现是4.8.5,这个是CentOS默认的版本,我们需要对gcc进行升级 ->
- yum -y install centos-release-scl
- yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
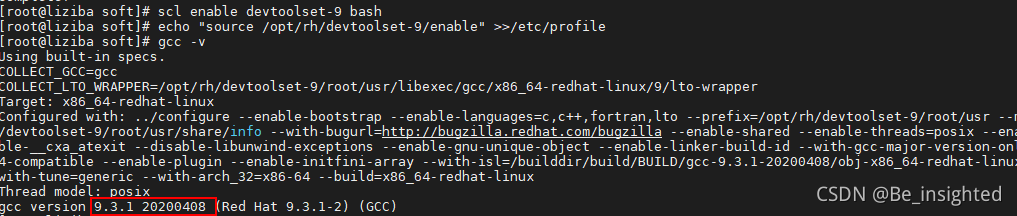
- scl enable devtoolset-9 bash
- echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
查看升级后的版本 ->
- cd redis-6.2.4/src
- make install
编译过程如下 ->

看到如下结果输出则编译成功 ->

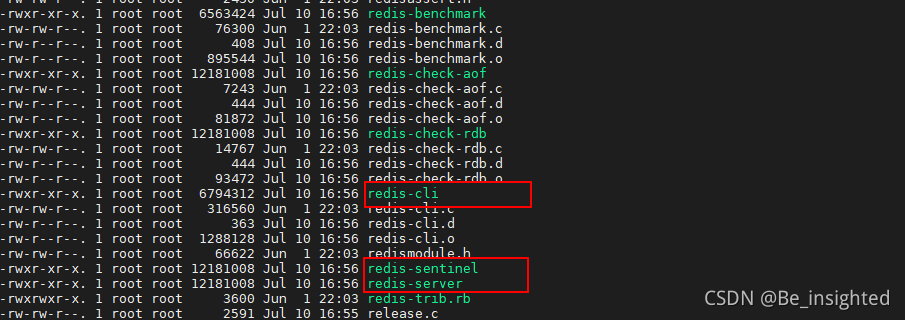
或者在src目录下出现服务端和客户端的脚本 ->
- redis-sentinel
- redis-server
- redis-cli
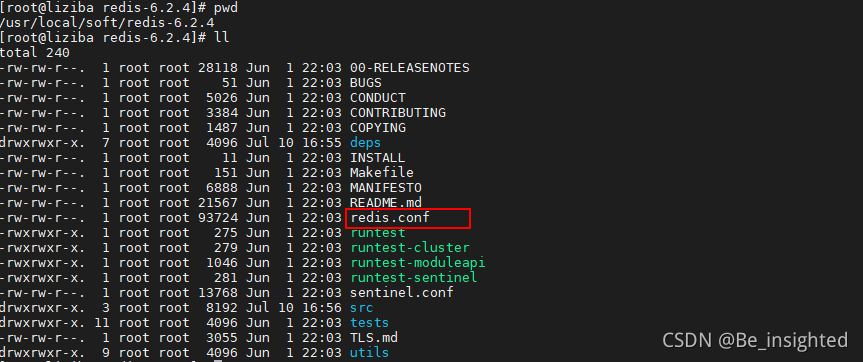
Redis的配置文件在解压目录下的 redis.conf
1.1.6.1 首先设置后台启动,防止窗口一关闭服务就挂掉
默认后台启动参数为 no->
- # By default Redis does not run as a daemon. Use 'yes' if you need it.
- # Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
- # When Redis is supervised by upstart or systemd, this parameter has no impact.
- daemonize no
修改成 yes->
- # By default Redis does not run as a daemon. Use 'yes' if you need it.
- # Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
- # When Redis is supervised by upstart or systemd, this parameter has no impact.
- daemonize yes
1.1.6.2 允许其他主机访问
根据Redis的文档配置注释,我们要运行其他主机访问有多种方式 ->
- 可以选择配置访问主机的IP address
- bind * -::* 相当于允许所有其它主机访问
- bind 0.0.0.0 相当于允许所有其它主机访问
- 直接注释 相当于允许所有其它主机访问
- # bind 192.168.1.100 10.0.0.1 # listens on two specific IPv4 addresses
- # bind 127.0.0.1 ::1 # listens on loopback IPv4 and IPv6
- # bind * -::* # like the default, all available interfaces
我的处理方式,安装文档的注释来配置

1.1.6.3 配置访问密码
如果是要考虑安全性,一定要配置密码,找到requirepass配置处,新增如下配置(阿里云等云服务其外网访问一定要配置,作者被黑过,整台服务器重启都无法重启,损失惨重,但是穷,官方处理需要Money,建议这里一定要谨慎)
requirepass yourpassword
使用redis-server 来启动,启动的方式如下->
/usr/local/soft/redis-6.2.4/src/redis-server /usr/local/soft/redis-6.2.4/redis.conf
或者这个也一样 ->
- cd /src
- redis-server ../redis.conf
查看端口是否启动成功 ->
netstat -an|grep 6379

进入客户端的方式如下 ->
/usr/local/soft/redis-6.2.4/src/redis-cli

停止Redis有两种方式 :
方式一,在客户端中执行SHUTDOWN
SHUTDOWN
![]()
方式二,暴力kill -9
- ps -aux | grep redis
- kill -9 57927

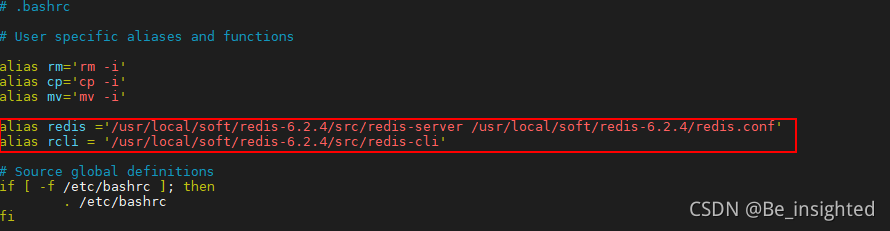
为了方便启动Redis和进入客户端,我们可以通过配置别名来实现
vim ~/.bashrc
添加如下配置,
- 注意''很重要
- redis与rcli后面的=两边不能有空格
- alias redis='/usr/local/soft/redis-6.2.4/src/redis-server /usr/local/soft/redis-6.2.4/redis.conf'
- alias rcli='/usr/local/soft/redis-6.2.4/src/redis-cli'
使配置生效
source ~/.bashrc
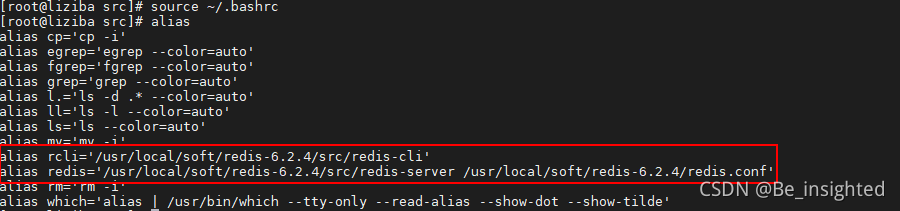
现在我们可以通过redis启动Redis服务,使用rcli进入Redis客户端

Redis中所有的的数据结构都是通过一个唯一的字符串key来获取相应的value数据。
Redis有5种基础数据结构,分别是:
- string(字符串)
- list(列表)
- hash(字典)
- set(集合)
- zset(有序集合)
本小结讲述的是Redis的5种基础数据结构中的string(字符串)
2.1.2.1 string(字符串)的内部结构
string(字符串)是Redis最简单也是使用最广泛的数据结构,它的内部是一个字符数组。如图所示:
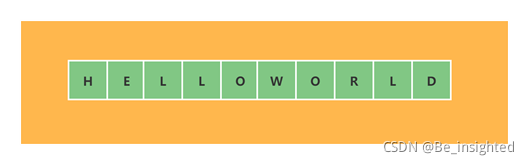
Redis中string(字符串)是动态字符串,允许修改;它在结构上的实现类似于Java中的ArrayList(默认构造一个大小为10的初始数组),这是冗余分配内存的思想,也称为预分配;这种思想可以减少扩容带来的性能消耗。
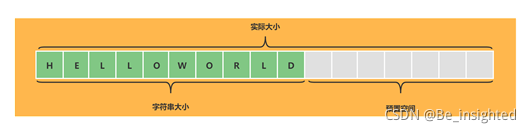
2.1.2.2 string(字符串)的扩容
当string(字符串)的大小达到扩容阈值时,将会对string(字符串)进行扩容,string(字符串)的扩容主要有以下几个点:
- 长度小于1MB,扩容后为原先的两倍; length = length * 2
- 长度大于1MB,扩容后增加1MB; length = length + 1MB
- 字符串的长度最大值为 512MB
2.1.3.1 单个键值对增删改查操作
set -> key 不存在则新增,存在则修改
set key value
get -> 查询,返回对应key的value,不存在返回(nil)
get key
del -> 删除指定的key(key可以是多个)
del key [key …]
示例:
- 127.0.0.1:6379> set name liziba
- OK
- 127.0.0.1:6379> get name
- "liziba"
- 127.0.0.1:6379> set name liziba001
- OK
- 127.0.0.1:6379> get name
- "liziba001"
- 127.0.0.1:6379> del name
- (integer) 1
- 127.0.0.1:6379> get name
- (nil)
2.1.3.2 批量键值对
批量键值读取和写入最大的优势在于节省网络传输开销
mset -> 批量插入
mset key value [key value …]
mget -> 批量获取
mget key [key …]
示例:
- 127.0.0.1:6379> mset name1 liziba1 name2 liziba2 name3 liziba3
- OK
- 127.0.0.1:6379> mget name1 name2 name3
- 1) "liziba1"
- 2) "liziba2"
- 3) "liziba3"
2.1.3.3 过期set命令
过期set是通过设置一个缓存key的过期时间,使得缓存到期后自动删除从而失效的机制。
方式一:
expire key seconds
示例:
- 127.0.0.1:6379> set name liziba
- OK
- 127.0.0.1:6379> get name
- "liziba"
- 127.0.0.1:6379> expire name 10 # 10s 后get name 返回 nil
- (integer) 1
- 127.0.0.1:6379> get name
- (nil)
方式二:
setex key seconds value
示例:
- 127.0.0.1:6379> setex name 10 liziba # 10s 后get name 返回 nil
- OK
- 127.0.0.1:6379> get name
- (nil)
2.1.3.4 不存在创建存在不更新
上面的set操作不存在创建,存在则更新;此时如果需要存在不更新的场景,那么可以使用如下这个指令
setnx -> 不存在创建存在不更新
setnx key value
示例:
- 127.0.0.1:6379> get name
- (nil)
- 127.0.0.1:6379> setnx name liziba
- (integer) 1
- 127.0.0.1:6379> get name
- "liziba"
- 127.0.0.1:6379> setnx name liziba_98 # 已经存在再次设值,失败
- (integer) 0
- 127.0.0.1:6379> get name
- "liziba"
2.1.3.5计数
string(字符串)也可以用来计数,前提是value是一个整数,那么可以对它进行自增的操作。自增的范围必须在signed long的区间访问内,[-9223372036854775808,9223372036854775808]
2.1.3.5.1 incr -> 自增1
incr key
示例:
- 127.0.0.1:6379> set fans 1000
- OK
- 127.0.0.1:6379> incr fans # 自增1
- (integer) 1001
2.1.3.5.2 incrby -> 自定义累加值
incrby key increment
- 127.0.0.1:6379> set fans 1000
- OK
- 127.0.0.1:6379> incr fans
- (integer) 1001
- 127.0.0.1:6379> incrby fans 999
- (integer) 2000
2.1.3.5.3 测试value为整数的自增区间
最大值:
- 127.0.0.1:6379> set fans 9223372036854775808
- OK
- 127.0.0.1:6379> incr fans
- (error) ERR value is not an integer or out of range
最小值:
- 127.0.0.1:6379> set money -9223372036854775808
- OK
- 127.0.0.1:6379> incrby money -1
- (error) ERR increment or decrement would overflow
Redis中所有的的数据结构都是通过一个唯一的字符串key来获取相应的value数据。
Redis有5种基础数据结构,分别是:
- string(字符串)
- list(列表)
- hash(字典)
- set(集合)
- zset(有序集合)
其中list、set、hash、zset这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
- create if not exists:容器不存在则创建
- drop if no elements:如果容器中没有元素,则立即删除容器,释放内存
本小结讲述的是Redis的5种基础数据结构中的list(列表)
2.2.2.1 list(列表)的内部结构
Redis的列表相当于Java语言中的LinkedList,它是一个双向链表数据结构(但是这个结构设计比较巧妙,后面会介绍),支持前后顺序遍历。链表结构插入和删除操作快,时间复杂度O(1),查询慢,时间复杂度O(n)。
2.2.2.2 list(列表)的使用场景
根据Redis双向列表的特性,因此其也被用于异步队列的使用。实际开发中将需要延后处理的任务结构体序列化成字符串,放入Redis的队列中,另一个线程从这个列表中获取数据进行后续处理。其流程类似如下的图:
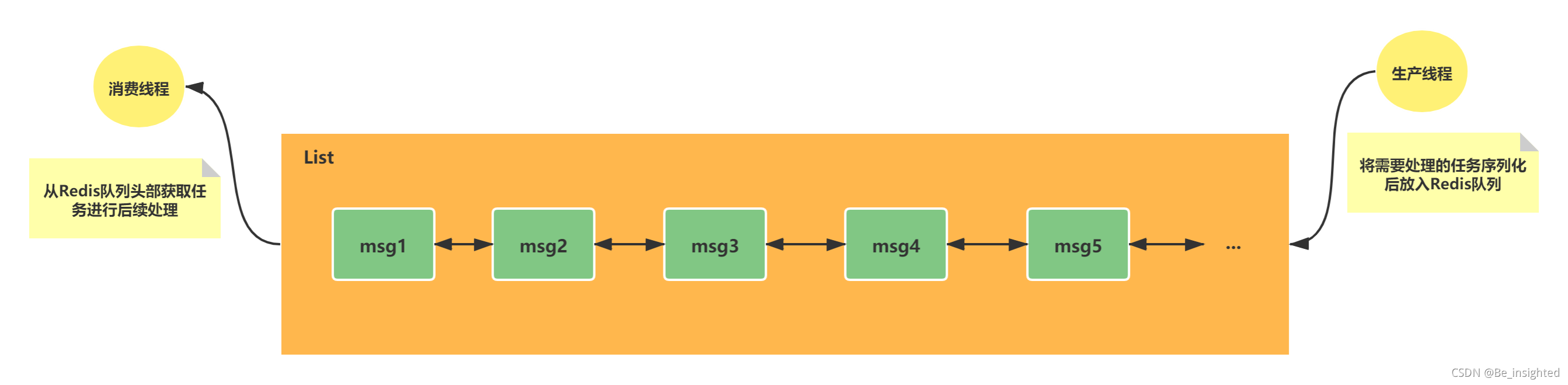
2.2.3.1 右进左出—队列
队列在结构上是先进先出(FIFO)的数据结构(比如排队购票的顺序),常用于消息队列类似的功能,例如消息排队、异步处理等场景。通过它可以确保元素的访问顺序。
lpush -> 从左边边添加元素
lpush key value [value …]
rpush -> 从右边添加元素
rpush key value [value …]
llen -> 获取列表的长度
llen key
lpop -> 从左边弹出元素
lpop key
- 127.0.0.1:6379> rpush code java c python # 向列表中添加元素
- (integer) 3
- 127.0.0.1:6379> llen code # 获取列表长度
- (integer) 3
- 127.0.0.1:6379> lpop code # 弹出最先添加的元素
- "java"
- 127.0.0.1:6379> lpop code
- "c"
- 127.0.0.1:6379> lpop code
- "python"
- 127.0.0.1:6379> llen code
- (integer) 0
- 127.0.0.1:6379> lpop code
- (nil)
2.2.3.2 右进右出——栈
栈在结构上是先进后出(FILO)的数据结构(比如弹夹压入子弹,子弹被射击出去的顺序就是栈),这种数据结构一般用来逆序输出。
lpush -> 从左边边添加元素
lpush key value [value …]
rpush -> 从右边添加元素
rpush key value [value …]
rpop -> 从右边弹出元素
rpop code
- 127.0.0.1:6379> rpush code java c python
- (integer) 3
- 127.0.0.1:6379> rpop code # 弹出最后添加的元素
- "python"
- 127.0.0.1:6379> rpop code
- "c"
- 127.0.0.1:6379> rpop code
- "java"
- 127.0.0.1:6379> rpop code
- (nil)
2.2.3.3 慢操作
列表(list)是个链表数据结构,它的遍历是慢操作,所以涉及到遍历的性能将会遍历区间range的增大而增大。注意list的索引运行为负数,-1代表倒数第一个,-2代表倒数第二个,其它同理。
lindex -> 遍历获取列表指定索引处的值
lindex key ind
lrange -> 获取从索引start到stop处的全部值
lrange key start stop
ltrim -> 截取索引start到stop处的全部值,其它将会被删除
ltrim key start stop
- 127.0.0.1:6379> rpush code java c python
- (integer) 3
- 127.0.0.1:6379> lindex code 0 # 获取索引为0的数据
- "java"
- 127.0.0.1:6379> lindex code 1 # 获取索引为1的数据
- "c"
- 127.0.0.1:6379> lindex code 2 # 获取索引为2的数据
- "python"
- 127.0.0.1:6379> lrange code 0 -1 # 获取全部 0 到倒数第一个数据 == 获取全部数据
- 1) "java"
- 2) "c"
- 3) "python"
- 127.0.0.1:6379> ltrim code 0 -1 # 截取并保理 0 到 -1 的数据 == 保理全部
- OK
- 127.0.0.1:6379> lrange code 0 -1
- 1) "java"
- 2) "c"
- 3) "python"
- 127.0.0.1:6379> ltrim code 1 -1 # 截取并保理 1 到 -1 的数据 == 移除了索引为0的数据 java
- OK
- 127.0.0.1:6379> lrange code 0 -1
- 1) "c"
- 2) "python"
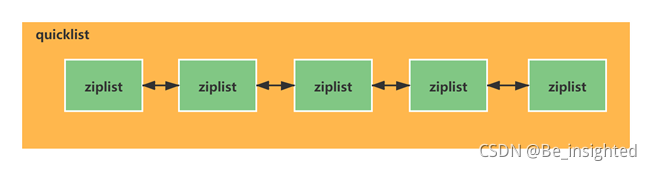
Redis底层存储list(列表)不是一个简单的LinkedList,而是quicklist ——“快速列表”。关于quicklist是什么,下面会简单介绍,具体源码我也还在学习中,后面大家一起探讨。
quicklist是多个ziplist(压缩列表)组成的双向列表;而这个ziplist(压缩列表)又是什么呢?ziplist指的是一块连续的内存存储空间,Redis底层对于list(列表)的存储,当元素个数少的时候,它会使用一块连续的内存空间来存储,这样可以减少每个元素增加prev和next指针带来的内存消耗,最重要的是可以减少内存碎片化问题。
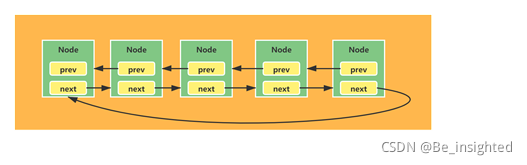
2.2.4.1 常见的链表结构示意图
每个node节点元素,都会持有一个prev->执行前一个node节点和next->指向后一个node节点的指针(引用),这种结构虽然支持前后顺序遍历,但是也带来了不小的内存开销,如果node节点仅仅是一个int类型的值,那么可想而知,引用的内存比例将会更大。
2.2.4.2 ziplist示意图
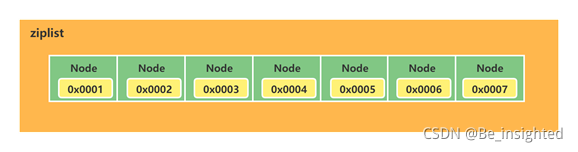
ziplist是一块连续的内存地址,他们之间无需持有prev和next指针,能通过地址顺序寻址访问。
2.2.4.3 quicklist示意图
quicklist是由多个ziplist组成的双向链表。
Redis中所有的的数据结构都是通过一个唯一的字符串key来获取相应的value数据。
Redis有5种基础数据结构,分别是:
- string(字符串)
- list(列表)
- hash(字典)
- set(集合)
- zset(有序集合)
其中list、set、hash、zset这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
- create if not exists:容器不存在则创建
- drop if no elements:如果容器中没有元素,则立即删除容器,释放内存
本小节讲述的是Redis的5种基础数据结构中的hash(字典)
2.3.2.1 hash(字典)的内部结构
Redis的hash(字典)相当于Java语言中的HashMap,它是根据散列值分布的无序字典,内部的元素是通过键值对的方式存储。
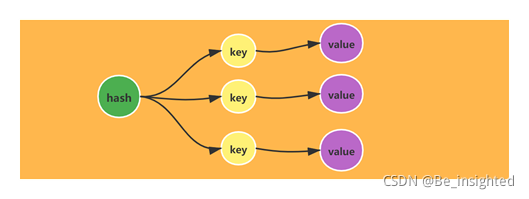
hash(字典)的实现与Java中的HashMap(JDK1.7)的结构也是一致的,它的数据结构也是数组+链表组成的二维结构,节点元素散列在数组上,如果发生hash碰撞则使用链表串联在数组节点上。
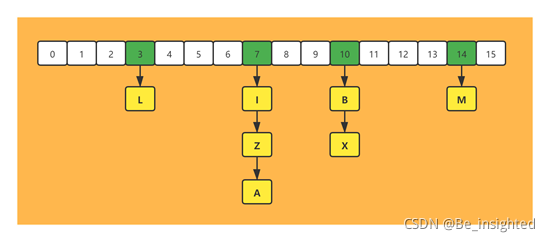
2.3.2.2 hash(字典)扩容
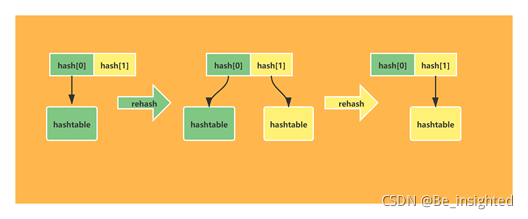
Redis中的hash(字典)存储的value只能是字符串值,此外扩容与Java中的HashMap也不同。Java中的HashMap在扩容的时候是一次性完成的,而Redis考虑到其核心存取是单线程的性能问题,为了追求高性能,因而采取了渐进式rehash策略。
渐进式rehash指的是并非一次性完成,它是多次完成的,因此需要保理旧的hash结构,所以Redis中的hash(字典)会存在新旧两个hash结构,在rehash结束后也就是旧hash的值全部搬迁到新hash之后,新的hash在功能上才会完全替代以前的hash。
2.3.2.3 hash(字典)的相关使用场景
hash(字典)可以用来存储对象的相关信息,一个hash(字典)代表一个对象,hash的一个key代表对象的一个属性,key的值代表属性的值。hash(字典)结构相比字符串来说,它无需将整个对象进行序列化后进行存储。这样在获取的时候可以进行部分获取。所以相比之下hash(字典)具有如下的优缺点:
- 读取可以部分读取,节省网络流量
- 存储消耗的高于单个字符串的存储
2.3.3.1 hash(字典)常用指令
hset -> hash(字典)插入值,字典不存在则创建 key代表字典名称,field 相当于 key,value是key的值
hset key field value
hmset -> 批量设值
hmset key field value [field value …]
示例:
- 7.0.0.1:6379> hset book java "Thinking in Java" # 字符串包含空格需要""包裹
- (integer) 1
- 127.0.0.1:6379> hset book python "Python code"
- (integer) 1
- 127.0.0.1:6379> hset book c "The best of c"
- (integer) 1
- 127.0.0.1:6379> hmset book go "concurrency in go" mysql "high-performance MySQL" # 批量设值
- OK
hget -> 获取字典中的指定key的value
hget key field
hgetall -> 获取字典中所有的key和value,换行输出
hgetall key
示例:
- 127.0.0.1:6379> hget book java
- "Thinking in Java"
- 127.0.0.1:6379> hgetall book
- 1) "java"
- 2) "Thinking in Java"
- 3) "python"
- 4) "Python code"
- 5) "c"
- 6) "The best of c"
hlen -> 获取指定字典的key的个数
hlen key
举例:
- 127.0.0.1:6379> hlen book
- (integer) 5
2.3.3.2 hash(字典)使用小技巧
在string(字符串)中可以使用incr和incrby对value是整数的字符串进行自加操作,在hash(字典)结构中如果单个子key是整数也可以进行自加操作。
hincrby -> 增对hash(字典)中的某个key的整数value进行自加操作
hincrby key field increment
- 127.0.0.1:6379> hset liziba money 10
- (integer) 1
- 127.0.0.1:6379> hincrby liziba money -1
- (integer) 9
- 127.0.0.1:6379> hget liziba money
- "9"
注意如果不是整数会报错。
- 127.0.0.1:6379> hset liziba money 10.1
- (integer) 1
- 127.0.0.1:6379> hincrby liziba money 1
- (error) ERR hash value is not an integer
Redis中所有的的数据结构都是通过一个唯一的字符串key来获取相应的value数据。
Redis有5种基础数据结构,分别是:
- string(字符串)
- list(列表)
- hash(字典)
- set(集合)
- zset(有序集合)
其中list、set、hash、zset这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
- create if not exists:容器不存在则创建
- drop if no elements:如果容器中没有元素,则立即删除容器,释放内存
本文讲述的是Redis的5种基础数据结构中的set(集合)
2.4.2.1 set(集合)的内部结构
Redis的set(集合)相当于Java语言里的HashSet,它内部的键值对是无序的、唯一的。它的内部实现了一个所有value为null的特殊字典。
集合中的最后一个元素被移除之后,数据结构被自动删除,内存被回收。
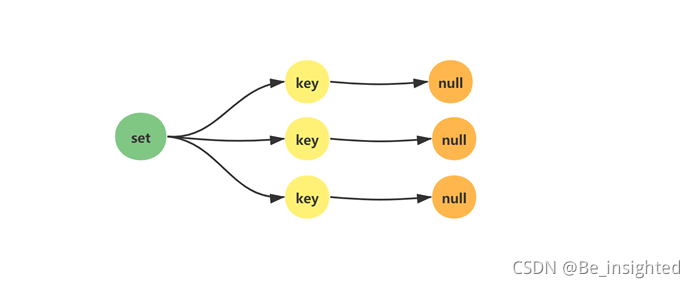
2.4.2.2 set(集合)的使用场景
set(集合)由于其特殊去重复的功能,我们可以用来存储活动中中奖的用户的ID,这样可以保证一个用户不会中奖两次。
sadd -> 添加集合成员,key值集合名称,member值集合元素,元素不能重复
sadd key member [member …]
- 127.0.0.1:6379> sadd name zhangsan
- (integer) 1
- 127.0.0.1:6379> sadd name zhangsan # 不能重复,重复返回0
- (integer) 0
- 127.0.0.1:6379> sadd name lisi wangwu liumazi # 支持一次添加多个元素
- (integer) 3
smembers -> 查看集合中所有的元素,注意是无序的
smembers key
- 127.0.0.1:6379> smembers name # 无序输出集合中所有的元素
- 1) "lisi"
- 2) "wangwu"
- 3) "liumazi"
- 4) "zhangsan"
sismember -> 查询集合中是否包含某个元素
sismember key member
- 127.0.0.1:6379> sismember name lisi # 包含返回1
- (integer) 1
- 127.0.0.1:6379> sismember name tianqi # 不包含返回0
- (integer) 0
scard -> 获取集合的长度
scard key
- 127.0.0.1:6379> scard name
- (integer) 4
spop -> 弹出元素,count指弹出元素的个数
spop key [count]
- 127.0.0.1:6379> spop name # 默认弹出一个
- "wangwu"
- 127.0.0.1:6379> spop name 3
- 1) "lisi"
- 2) "zhangsan"
- 3) "liumazi"
Redis中所有的的数据结构都是通过一个唯一的字符串key来获取相应的value数据。
Redis有5种基础数据结构,分别是:
- string(字符串)
- list(列表)
- hash(字典)
- set(集合)
- zset(有序集合)
其中list、set、hash、zset这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
- create if not exists:容器不存在则创建
- drop if no elements:如果容器中没有元素,则立即删除容器,释放内存
本文讲述的是Redis的5种基础数据结构中的zset(有序列表)
2.5.2.1 zset(有序集合)的内部结构
zset(有序集合)是Redis中最常问的数据结构。它类似于Java语言中的SortedSet和HashMap的结合体,它一方面通过set来保证内部value值的唯一性,另一方面通过value的score(权重)来进行排序。这个排序的功能是通过Skip List(跳跃列表)来实现的。
zset(有序集合)的最后一个元素value被移除后,数据结构被自动删除,内存被回收。
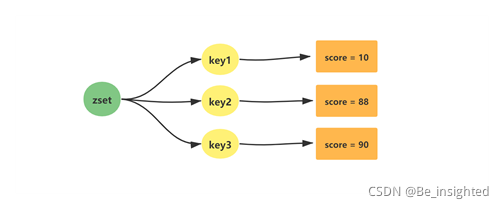
2.5.2.2 zset(有序集合)的相关使用场景
利用zset的去重和有序的效果可以由很多使用场景,举两个例子:
- 存储粉丝列表,value是粉丝的ID,score是关注时间戳,这样可以对粉丝关注进行排序
- 存储学生成绩,value使学生的ID,score是学生的成绩,这样可以对学生的成绩排名
1、zadd -> 向集合中添加元素,集合不存在则新建,key代表zset集合名称,score代表元素的权重,member代表元素
zadd key [NX|XX] [CH] [INCR] score member [score member …]
- 127.0.0.1:6379> zadd name 10 zhangsan
- (integer) 1
- 127.0.0.1:6379> zadd name 10.1 lisi
- (integer) 1
- 127.0.0.1:6379> zadd name 9.9 wangwu
- (integer) 1
2、zrange -> 按照score权重从小到大排序输出集合中的元素,权重相同则按照value的字典顺序排序(lexicographical order )
超出范围的下标并不会引起错误。 比如说,当 start 的值比有序集的最大下标还要大,或是 start > stop 时, zrange 命令只是简单地返回一个空列表。 另一方面,假如 stop 参数的值比有序集的最大下标还要大,那么 Redis 将 stop 当作最大下标来处理。
可以通过使用 WITHSCORES 选项,来让成员和它的 score 值一并返回,返回列表以 value1,score1, …, valueN,scoreN 的格式表示。 客户端库可能会返回一些更复杂的数据类型,比如数组、元组等。
zrange key start stop [WITHSCORES]
- 127.0.0.1:6379> zrange name 0 -1 # 获取所有元素,按照score的升序输出
- 1) "wangwu"
- 2) "zhangsan"
- 3) "lisi"
- 127.0.0.1:6379> zrange name 0 1 # 获取第一个和第二个slot的元素
- 1) "wangwu"
- 2) "zhangsan"
- 127.0.0.1:6379> zadd name 10 tianqi # 在上面的基础上添加score为10的元素
- (integer) 1
- 127.0.0.1:6379> zrange name 0 2 # key相等则按照value字典排序输出
- 1) "wangwu"
- 2) "tianqi"
- 3) "zhangsan"
- 127.0.0.1:6379> zrange name 0 -1 WITHSCORES # WITHSCORES 输出权重
- 1) "wangwu"
- 2) "9.9000000000000004"
- 3) "tianqi"
- 4) "10"
- 5) "zhangsan"
- 6) "10"
- 7) "lisi"
- 8) "10.1"
3、zrevrange -> 按照score权重从大到小输出集合中的元素,权重相同则按照value的字典逆序排序
其中成员的位置按 score 值递减(从大到小)来排列。 具有相同 score 值的成员按字典序的逆序(reverse lexicographical order)排列。除了成员按 score 值递减的次序排列这一点外, ZREVRANGE 命令的其他方面和 ZRANGE key start stop [WITHSCORES] 命令一样。
zrevrange key start stop [WITHSCORES]
- 127.0.0.1:6379> zrevrange name 0 -1 WITHSCORES
- 1) "lisi"
- 2) "10.1"
- 3) "zhangsan"
- 4) "10"
- 5) "tianqi"
- 6) "10"
- 7) "wangwu"
- 8) "9.9000000000000004"
4、zcard -> 当 key 存在且是有序集类型时,返回有序集的基数。 当 key 不存在时,返回 0
zcard key
- 127.0.0.1:6379> zcard name
- (integer) 4
5、zscore -> 返回有序集 key 中,成员 member 的 score 值,如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil
zscore key member z
- 127.0.0.1:6379> zscore name zhangsan
- "10"
- 127.0.0.1:6379> zscore name liziba
- (nil)
6、zrank -> 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。
排名以 0 为底,也就是说, score 值最小的成员排名为 0
zrank key member
- 127.0.0.1:6379> zrange name 0 -1
- 1) "wangwu"
- 2) "tianqi"
- 3) "zhangsan"
- 4) "lisi"
- 127.0.0.1:6379> zrank name wangwu
- (integer) 0
7、zrangebyscore -> 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
min 和 max 可以是 -inf 和 +inf ,这样一来,你就可以在不知道有序集的最低和最高 score 值的情况下,使用 *ZRANGEBYSCORE这类命令。
默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]
- 127.0.0.1:6379> zrange name 0 -1 WITHSCORES # 输出全部元素
- 1) "wangwu"
- 2) "9.9000000000000004"
- 3) "tianqi"
- 4) "10"
- 5) "zhangsan"
- 6) "10"
- 7) "lisi"
- 8) "10.1"
- 127.0.0.1:6379> zrangebyscore name 9 10
- 1) "wangwu"
- 2) "tianqi"
- 3) "zhangsan"
- 127.0.0.1:6379> zrangebyscore name 9 10 WITHSCORES # 输出分数
- 1) "wangwu"
- 2) "9.9000000000000004"
- 3) "tianqi"
- 4) "10"
- 5) "zhangsan"
- 6) "10"
- 127.0.0.1:6379> zrangebyscore name -inf 10 # -inf 从负无穷开始
- 1) "wangwu"
- 2) "tianqi"
- 3) "zhangsan"
- 127.0.0.1:6379> zrangebyscore name -inf +inf # +inf 直到正无穷
- 1) "wangwu"
- 2) "tianqi"
- 3) "zhangsan"
- 4) "lisi"
- 127.0.0.1:6379> zrangebyscore name (10 11 # 10 < score <=11
- 1) "lisi"
- 127.0.0.1:6379> zrangebyscore name (10 (10.1 # 10 < socre < -11
- (empty list or set)
- 127.0.0.1:6379> zrangebyscore name (10 (11
- 1) "lisi"
8、zrem -> 移除有序集 key 中的一个或多个成员,不存在的成员将被忽略
zrem key member [member …]
- 127.0.0.1:6379> zrange name 0 -1
- 1) "wangwu"
- 2) "tianqi"
- 3) "zhangsan"
- 4) "lisi"
- 127.0.0.1:6379> zrem name zhangsan # 移除元素
- (integer) 1
- 127.0.0.1:6379> zrange name 0 -1
- 1) "wangwu"
- 2) "tianqi"
- 3) "lisi"
跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
Skip List(跳跃列表)这种随机的数据结构,可以看做是一个二叉树的变种,它在性能上与红黑树、AVL树很相近;但是Skip List(跳跃列表)的实现相比前两者要简单很多,目前Redis的zset实现采用了Skip List(跳跃列表)(其它还有LevelDB等也使用了跳跃列表)。
RBT红黑树与Skip List(跳跃列表)简单对比:
RBT红黑树
- 插入、查询时间复杂度O(logn)
- 数据天然有序
- 实现复杂,设计变色、左旋右旋平衡等操作
- 需要加锁
Skip List跳跃列表
- 插入、查询时间复杂度O(logn)
- 数据天然有序
- 实现简单,链表结构
- 无需加锁
2.6.2.1 Skip List论文
这里贴出Skip List的论文,需要详细研究的请看论文,下文部分公式、代码、图片出自该论文。
Skip Lists: A Probabilistic Alternative to Balanced Trees
https://www.cl.cam.ac.uk/teaching/2005/Algorithms/skiplists.pdf
2.6.2.2 Skip List动态图
先通过一张动图来了解Skip List的插入节点元素的流程,此图来自维基百科。
2.6.2.3 Skip List算法性能分析
2.6.2.3.1 计算随机层数算法
首先分析的是执行插入操作时计算随机数的过程,这个过程会涉及层数的计算,所以十分重要。对于节点他有如下特性:
- 节点都有第一层的指针
- 节点有第i层指针,那么第i+1层出现的概率为p
- 节点有最大层数限制,MaxLevel
计算随机层数的伪代码:
论文中的示例
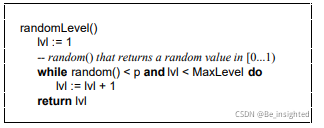
Java版本
- public int randomLevel(){
- int level = 1;
- // random()返回一个[0...1)的随机数
- while (random() < p && level < MaxLevel){
- level += 1;
- }
- return level;
- }
代码中包含两个变量P和MaxLevel,在Redis中这两个参数的值分别是:
- p = 1/4
- MaxLevel = 64
2.3.2 节点包含的平均指针数目
Skip List属于空间换时间的数据结构,这里的空间指的就是每个节点包含的指针数目,这一部分是额外的内内存开销,可以用来度量空间复杂度。random()是个随机数,因此产生越高的节点层数,概率越低(Redis标准源码中的晋升率数据1/4,相对来说Skip List的结构是比较扁平的,层高相对较低)。其定量分析如下:
- level = 1 概率为1-p
- level >=2 概率为p
- level = 2 概率为p(1-p)
- level >= 3 概率为p^2
- level = 3 概率为p^2(1-p)
- level >=4 概率为p^3
- level = 4 概率为p^3(1-p)
- ……
得出节点的平均层数(节点包含的平均指针数目):
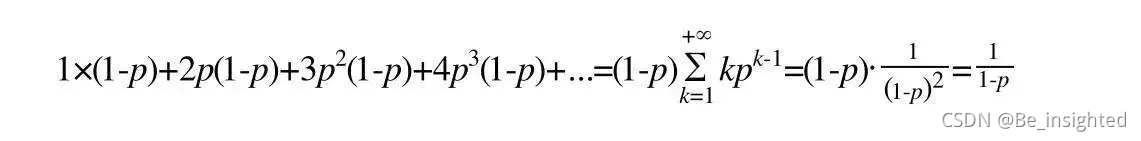
所以Redis中p=1/4计算的平均指针数目为1.33
2.3.3 时间复杂度计算
以下推算来自论文内容
假设p=1/2,在以p=1/2生成的16个元素的跳过列表中,我们可能碰巧具有9个元素,1级3个元素,3个元素3级元素和1个元素14级(这不太可能,但可能会发生)。我们该怎么处理这种情况?如果我们使用标准算法并在第14级开始我们的搜索,我们将会做很多无用的工作。那么我们应该从哪里开始搜索?此时我们假设SkipList中有n个元素,第L层级元素个数的期望是1/p个;每个元素出现在L层的概率是p^(L-1), 那么第L层级元素个数的期望是 n * (p^L-1);得到1 / p =n * (p^L-1)
- 1 / p = n * (p^L-1)
- n = (1/p)^L
- L = log(1/p)^n
所以我们应该选择MaxLevel = log(1/p)^n
定义:MaxLevel = L(n) = log(1/p)^n
推算Skip List的时间复杂度,可以用逆向思维,从层数为i的节点x出发,返回起点的方式来回溯时间复杂度,节点x点存在两种情况:
- 节点x存在(i+1)层指针,那么向上爬一级,概率为p,对应下图situation c.
- 节点x不存在(i+1)层指针,那么向左爬一级,概率为1-p,对应下图situation b.
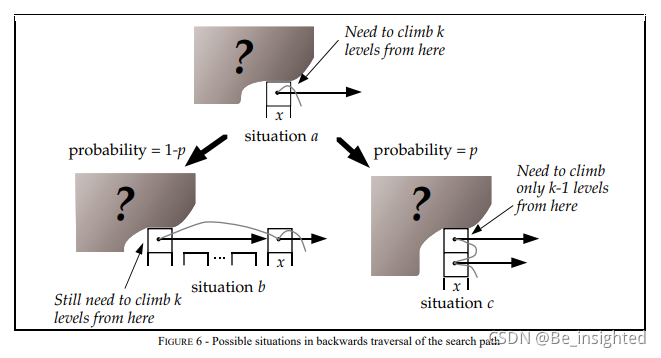
设C(k) = 在无限列表中向上攀升k个level的搜索路径的预期成本(即长度)那么推演如下:
- C(0)=0
- C(k)=(1-p)×(情况b的查找长度) + p×(情况c的查找长度)
- C(k)=(1-p)(C(k)+1) + p(C(k-1)+1)
- C(k)=1/p+C(k-1)
- C(k)=k/p
上面推演的结果可知,爬升k个level的预期长度为k/p,爬升一个level的长度为1/p。
由于MaxLevel = L(n), C(k) = k / p,因此期望值为:(L(n) – 1) / p;将L(n) = log(1/p)^n 代入可得:(log(1/p)^n - 1) / p;将p = 1 / 2 代入可得:2 * log2^n - 2,即O(logn)的时间复杂度。
2.6.3.1 Skip List特性
Skip List跳跃列表通常具有如下这些特性
- Skip List包含多个层,每层称为一个level,level从0开始递增
- Skip List 0层,也就是最底层,应该包含所有的元素
- 每一个level/层都是一个有序的列表
- level小的层包含level大的层的元素,也就是说元素A在X层出现,那么 想X>Z>=0的level/层都应该包含元素A
- 每个节点元素由节点key、节点value和指向当前节点所在level的指针数组组成
2.6.3.2 Skip List查询
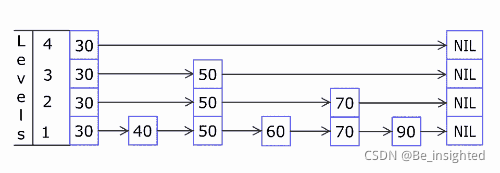
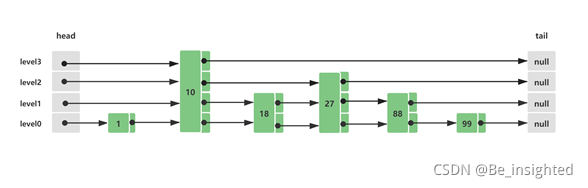
假设初始Skip List跳跃列表中已经存在这些元素,他们分布的结构如下所示:
此时查询节点88,它的查询路线如下所示:
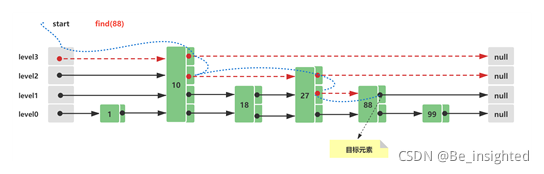
- 从Skip List跳跃列表最顶层level3开始,往后查询到10 < 88 && 后续节点值为null && 存在下层level2
- level2 10往后遍历,27 < 88 && 后续节点值为null && 存在下层level1
- level1 27往后遍历,88 = 88,查询命中
2.6.3.3 Skip List插入
Skip List的初始结构与2.3中的初始结构一致,此时假设插入的新节点元素值为90,插入路线如下所示:
- 查询插入位置,与Skip List查询方式一致,这里需要查询的是第一个比90大的节点位置,插入在这个节点的前面, 88 < 90 < 100
- 构造一个新的节点Node(90),为插入的节点Node(90)计算一个随机level,这里假设计算的是1,这个level时随机计算的,可能时1、2、3、4…均有可能,level越大的可能越小,主要看随机因子x ,层数的概率大致计算为 (1/x)^level ,如果level大于当前的最大level3,需要新增head和tail节点
- 节点构造完毕后,需要将其插入列表中,插入十分简单步骤 -> Node(88).next = Node(90); Node(90).prev = Node(80); Node(90).next = Node(100); Node(100).prev = Node(90);
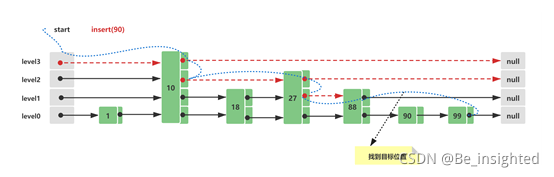
2.6.3.4 Skip List删除
删除的流程就是查询到节点,然后删除,重新将删除节点左右两边的节点以链表的形式组合起来即可,这里不再画图
实现一个Skip List比较简单,主要分为两个步骤:
- 定义Skip List的节点Node,节点之间以链表的形式存储,因此节点持有相邻节点的指针,其中prev与next是同一level的前后节点的指针,down与up是同一节点的多个level的上下节点的指针
- 定义Skip List的实现类,包含节点的插入、删除、查询,其中查询操作分为升序查询和降序查询(往后和往前查询),这里实现的Skip List默认节点之间的元素是升序链表
2.6.4.1 定义Node节点
Node节点类主要包括如下重要属性:
- score -> 节点的权重,这个与Redis中的score相同,用来节点元素的排序作用
- value -> 节点存储的真实数据,只能存储String类型的数据
- prev -> 当前节点的前驱节点,同一level
- next -> 当前节点的后继节点,同一level
- down -> 当前节点的下层节点,同一节点的不同level
- up -> 当前节点的上层节点,同一节点的不同level
- package com.liziba.skiplist;
- /**
- * <p>
- * 跳表节点元素
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/7/5 21:01
- */
- public class Node {
- /** 节点的分数值,根据分数值来排序 */
- public Double score;
- /** 节点存储的真实数据 */
- public String value;
- /** 当前节点的 前、后、下、上节点的引用 */
- public Node prev, next, down, up;
- public Node(Double score) {
- this.score = score;
- prev = next = down = up = null;
- }
- public Node(Double score, String value) {
- this.score = score;
- this.value = value;
- }
- }
2.6.4.2 SkipList节点元素的操作类
SkipList主要包括如下重要属性:
- head -> SkipList中的头节点的最上层头节点(level最大的层的头节点),这个节点不存储元素,是为了构建列表和查询时做查询起始位置的,具体的结构请看2.3中的结构
- tail -> SkipList中的尾节点的最上层尾节点(level最大的层的尾节点),这个节点也不存储元素,是查询某一个level的终止标志
- level -> 总层数
- size -> Skip List中节点元素的个数
- random -> 用于随机计算节点level,如果 random.nextDouble() < 1/2则需要增加当前节点的level,如果当前节点增加的level超过了总的level则需要增加head和tail(总level)
- package com.liziba.skiplist;
- import java.util.Random;
- /**
- * <p>
- * 跳表实现
- * </p>
- *
- * @Author: Liziba
- */
- public class SkipList {
- /** 最上层头节点 */
- public Node head;
- /** 最上层尾节点 */
- public Node tail;
- /** 总层数 */
- public int level;
- /** 元素个数 */
- public int size;
- public Random random;
- public SkipList() {
- level = size = 0;
- head = new Node(null);
- tail = new Node(null);
- head.next = tail;
- tail.prev = head;
- }
- /**
- * 查询插入节点的前驱节点位置
- *
- * @param score
- * @return
- */
- public Node fidePervNode(Double score) {
- Node p = head;
- for(;;) {
- // 当前层(level)往后遍历,比较score,如果小于当前值,则往后遍历
- while (p.next.value == null && p.prev.score <= score)
- p = p.next;
- // 遍历最右节点的下一层(level)
- if (p.down != null)
- p = p.down;
- else
- break;
- }
- return p;
- }
- /**
- * 插入节点,插入位置为fidePervNode(Double score)前面
- *
- * @param score
- * @param value
- */
- public void insert(Double score, String value) {
- // 当前节点的前置节点
- Node preNode = fidePervNode(score);
- // 当前新插入的节点
- Node curNode = new Node(score, value);
- // 分数和值均相等则直接返回
- if (curNode.value != null && preNode.value != null && preNode.value.equals(curNode.value)
- && curNode.score.equals(preNode.score)) {
- return;
- }
- preNode.next = curNode;
- preNode.next.prev = curNode;
- curNode.next = preNode.next;
- curNode.prev = preNode;
- int curLevel = 0;
- while (random.nextDouble() < 1/2) {
- // 插入节点层数(level)大于等于层数(level),则新增一层(level)
- if (curLevel >= level) {
- Node newHead = new Node(null);
- Node newTail = new Node(null);
- newHead.next = newTail;
- newHead.down = head;
- newTail.prev = newHead;
- newTail.down = tail;
- head.up = newHead;
- tail.up = newTail;
- // 头尾节点指针修改为新的,确保head、tail指针一直是最上层的头尾节点
- head = newHead;
- tail = newTail;
- ++level;
- }
- while (preNode.up == null)
- preNode = preNode.prev;
- preNode = preNode.up;
- Node copy = new Node(null);
- copy.prev = preNode;
- copy.next = preNode.next;
- preNode.next.prev = copy;
- preNode.next = copy;
- copy.down = curNode;
- curNode.up = copy;
- curNode = copy;
- ++curLevel;
- }
- ++size;
- }
- /**
- * 查询指定score的节点元素
- * @param score
- * @return
- */
- public Node search(double score) {
- Node p = head;
- for (;;) {
- while (p.next.score != null && p.next.score <= score)
- p = p.next;
- if (p.down != null)
- p = p.down;
- else // 遍历到最底层
- if (p.score.equals(score))
- return p;
- return null;
- }
- }
- /**
- * 升序输出Skip List中的元素 (默认升序存储,因此从列表head往tail遍历)
- */
- public void dumpAllAsc() {
- Node p = head;
- while (p.down != null) {
- p = p.down;
- }
- while (p.next.score != null) {
- System.out.println(p.next.score + "-->" + p.next.value);
- p = p.next;
- }
- }
- /**
- * 降序输出Skip List中的元素
- */
- public void dumpAllDesc() {
- Node p = tail;
- while (p.down != null) {
- p = p.down;
- }
- while (p.prev.score != null) {
- System.out.println(p.prev.score + "-->" + p.prev.value);
- p = p.prev;
- }
- }
- /**
- * 删除Skip List中的节点元素
- * @param score
- */
- public void delete(Double score) {
- Node p = search(score);
- while (p != null) {
- p.prev.next = p.next;
- p.next.prev = p.prev;
- p = p.up;
- }
- }
- }
Bitmaps、HyperLogLog、Geospatial是Redis的三大特殊数据类型,其中Bitmaps严格来说不能算一种数据类型。Bitmaps、HyperLogLog、Geospatial能轻松的解决很多问题,也是大厂面试中经常会考究的知识点。下文详细的讲述了Bitmaps、HyperLogLog、Geospatial的原理、使用等等。有需要的可以一键三连,如果有什么问题欢迎留言交流,看到一定及时回复。
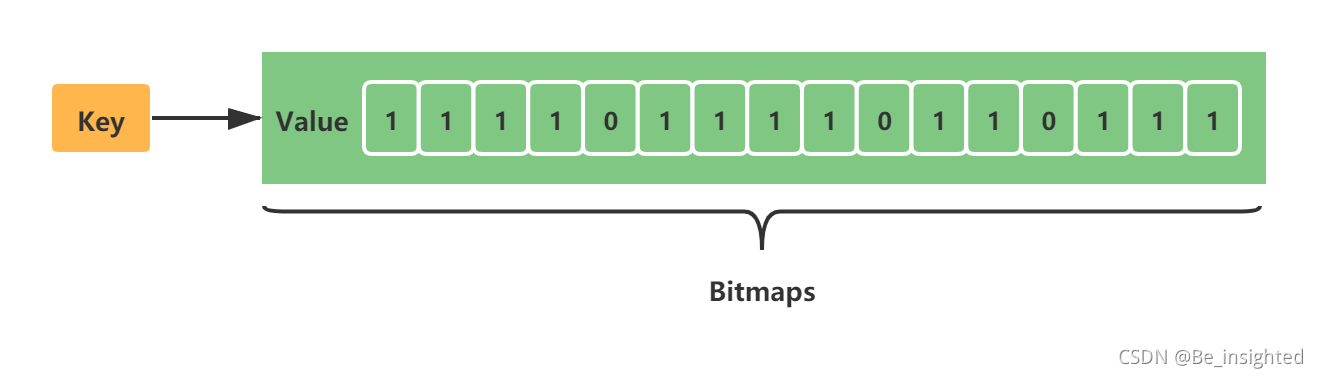
Bitmaps 称为位图,它不是一种数据类型。网上很多视频教程把Bitmaps称为数据类型,应该是不正确的。Bitmaps 是Redis提供给使用者用于操作位的“数据类型”。它主要有如下的基本特性:
- Bitmaps 不是数据类型,底层就是字符串(key-value),byte数组。我们可以使用普通的get/set直接获取和设值位图的内容,也可以通过Redis提供的位图操作getbit/setbit等将byte数组看成“位数组”来处理
- Bitmaps 的“位数组”每个单元格只能存储0和1,数组的下标在Bitmaps中称为偏移量
- Bitmaps设置时key不存在会自动生成一个新的字符串,如果设置的偏移量超出了现有内容的范围,就会自动将位数组进行零扩充。
3.1.2.1 SETBIT key offset value

对key存储的字符串,设置或者清除指定偏移量上的位(bit),位的设置或者清除取决于value参数,0/1;当key不存在时,自动生成一个新的字符串。字符串会进行伸展确保value保存在指定的偏移量上。字符串进行伸展时,空白位置以0填充。
时间复杂度 :
O(1)
offset 范围:
0~2^32
返回值:
指定偏移量原来存储的位
案例:
使用Bitmaps来存储用户是否打卡,打卡记做1,未打卡为0,用户的id作为偏移量
假设存在10个用户,此时用户1、3、5、9、10打了卡,其他人未打卡,Bitmaps的初始化结果如下所示:
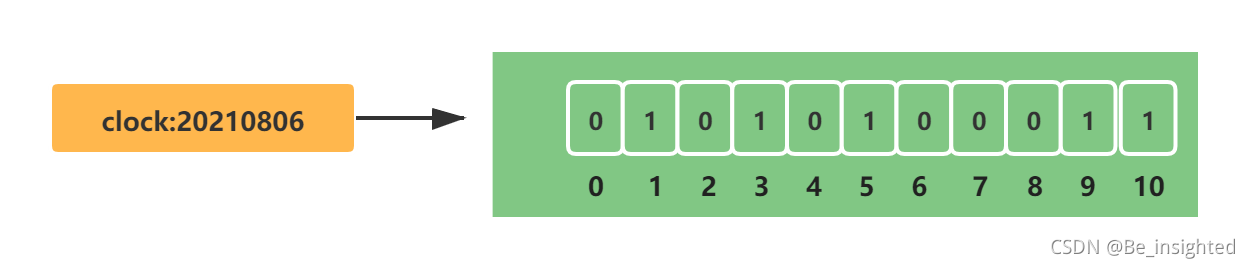
clock:20210806代表2021/08/06的打卡记录
注意事项:
正式系统中,id肯定不会是0、1、2这种,而是以某一个数组开头,比如1000000000000001、1000000000000002这个时候非常容易导致偏移量的浪费,因此我们可以考虑通过计算减去一个合适的值后再设置偏移量,如果设置的Bitmaps偏移量过大,容易造成分配内存时间过长,Redis服务器被阻塞。
3.1.2.2 GETBIT key offset

获取指定偏移量上的位(bit),当offset比字符串长度大,或者key不存在,返回0;
时间复杂度:
O(1)
返回值:
字符串值指定偏移量上的位(bit)
案例:
clock:20210806代表2021/08/06的打卡记录

3.1.2.3 BITCOUNT key [start] [end]
计算给定字符串中,被设置为1的bit位的数量。start和end参数可以指定查询的范围,可以使用负数值。-1代表最后一个字节,-2代表倒是第二个字节。
注意:start和end是字节索引,因此每增加1 代表的是增加一个字符,也就是8位,所以位的查询范围必须是8的倍数。
时间复杂度:
O(N)
返回值:
被设置为1的位的数量
案例:
clock:20210806代表2021/08/06的打卡记录,此时一共11位,前8位置3个1,后3位中2个1
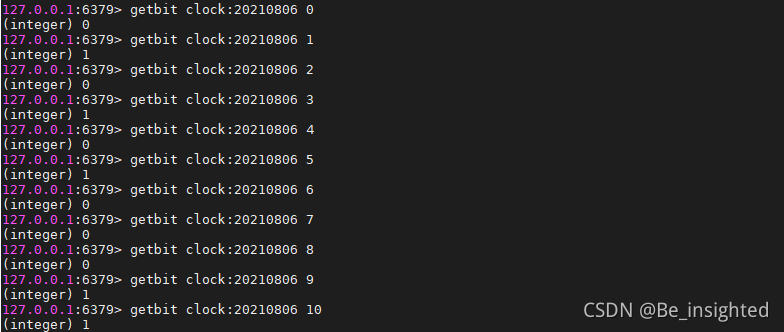
bitcount clock:20210806 0 0 表示第1个字符中1的个数
bitcount clock:20210806 1 1 表示第2个字符中1的个数
bitcount clock:20210806 0 1 表示第1和第2个字符中1的个数

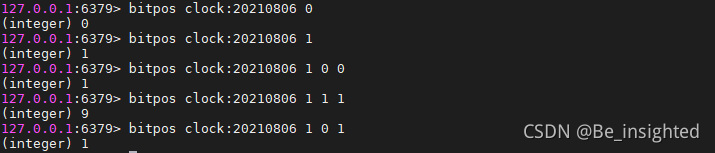
3.1.2.4 BITPOS key bit [start] [end]
返回第一个置为bit的二进制位的位置,默认检测整个Bitmaps,也可以通过start和end参数指定查询范围
注意:start和end是字节索引,因此每增加1 代表的是增加一个字符,也就是8位,所以位的查询范围必须是8的倍数。
时间复杂度:
O(N)
返回值:
整数回复
案例:
bitpos clock:20210806 0 表示第一个0的位置
bitpos clock:20210806 1 表示第一个1的位置
bitpos clock:20210806 1 0 0 表示第一个字符中,第一个1的位置
bitpos clock:20210806 1 1 1 表示第二个字符中,第一个1的位置
bitpos clock:20210806 1 0 1 表示第一个和第二个字符中,第一个1的位置
3.1.2.5 BITOP operation destkey key [key …]
Redis的Bitmaps提供BITOP指令来对一个或多个(除了NOT操作)二进制位的字符串key进行位元操作,操作的结果保存到destkey上,operation是操作类型,有四种分别是:AND、OR、NOT、XOR
- BITOP AND destkey key [key …] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey
- BITOP OR destkey key [key …] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey
- BITOP XOR destkey key [key …] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey
- BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey
当字符串长度不一致是,较短的那个字符串所缺失的部分会被看作0,空的key也会被看作是包含0的字符串序列
时间复杂度:
O(N)
返回值:
位运算的结果(保存到destkey的字符串的长度和输入key中的最长的字符串的长度相等)
案例:
这里使用key1 1001和key2 1011进行上述四种操作

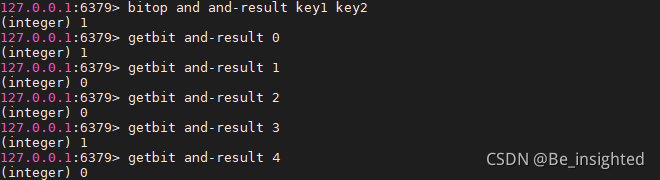
BITOP AND destkey key [key …]
运算规则:0&0=0; 0&1=0; 1&0=0; 1&1=1;
即:两位同时为“1”,结果才为“1”,否则为0
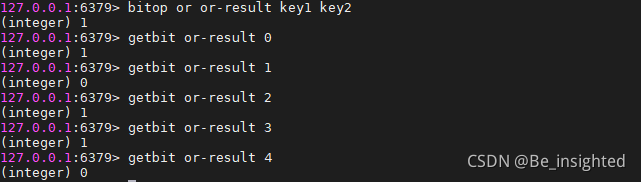
BITOP OR destkey key [key …]
运算规则:0|0=0; 0|1=1; 1|0=1; 1|1=1;
即 :参加运算的两个对象只要有一个为1,其值为1
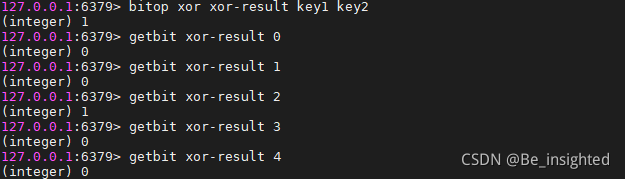
BITOP XOR destkey key [key …]
运算规则:0^0=0; 0^1=1; 1^0=1; 1^1=0;
即:参加运算的两个对象,如果两个相应位为“异”(值不同),则该位结果为1,否则为0
BITOP NOT destkey key
运算规则:取反
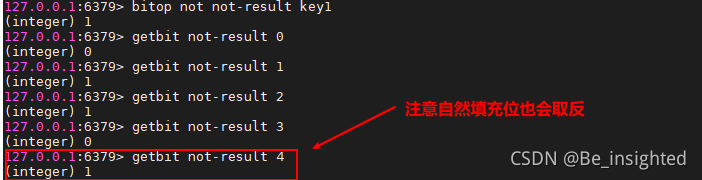
3.1.2.6 BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
2.1和2.2中的setbit和getbit都是对指定key的单个位的操作,如果需要对多个位同时操作,那么可以使用bitfield指令,bitfield有三个子指令,分别是get、set、incrby,它们可以对指定的片段进行读写,但是最多处理64个连续的位,超过64个连续的位,需要使用多个子指令,bitfield可以同时执行多个子指令(无符号整数只能返回63位)。
注意:
- 使用 GET 子命令对超出字符串当前范围的二进制位进行访问(包括键不存在的情况), 超出部分的二进制位的值将被当做是 0 。
- 使用 SET 子命令或者 INCRBY 子命令对超出字符串当前范围的二进制位进行访问将导致字符串被扩大, 被扩大的部分会使用值为 0 的二进制位进行填充。 在对字符串进行扩展时, 命令会根据字符串目前已有的最远端二进制位, 计算出执行操作所需的最小长度。
值操作子指令:
- GET —— 返回指定的二进制位范围
- SET —— 对指定的二进制位范围进行设置,并返回它的旧值
- INCRBY —— 对指定的二进制位范围执行加法操作,并返回它的旧值。用户可以通过向 increment 参数传入负值来实现相应的减法操作
溢出策略子指令:
- WRAP:回绕/折返(wrap around)-默认溢出策略,对于无符号整数来说, 回绕就像使用数值本身与能够被储存的最大无符号整数执行取模计算, 这也是 C 语言的标准行为。 对于有符号整数来说, 上溢将导致数字重新从最小的负数开始计算, 而下溢将导致数字重新从最大的正数开始计算。
- SAT:饱和计算(saturation arithmetic),也可以理解为饱和截断,这种模式下下溢计算的结果为最小的整数值, 而上溢计算的结果为最大的整数值
- FAIL:失败不执行,这种模式会拒绝执行那些导致上溢或者下溢的计算情况,返回nil表示计算未被执行。
需要注意的是, OVERFLOW 子命令只会对紧随着它之后被执行的 INCRBY 命令产生效果, 这一效果将一直持续到与它一同被执行的下一个 OVERFLOW 命令为止。 在默认情况下, INCRBY 命令使用 WRAP 方式来处理溢出计算。
i与u:
i表示有符号整数,u表示无符号整数。u4代表4位长的无符号整数,i8代表8位长的有符号整数。
案例:
测试数字为10100111
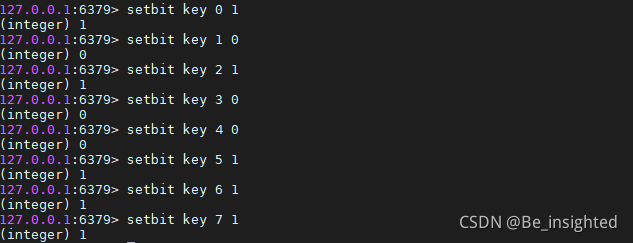
bitfield key get u4 0 从第一个位开始取4个位,得到无符号数1010=10
![]()
bitfield key set u8 0 128 从第0个开始,将接下来的8位用无符号整数128替换,也就是10000000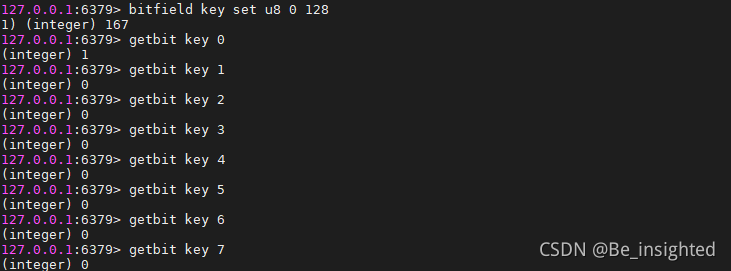
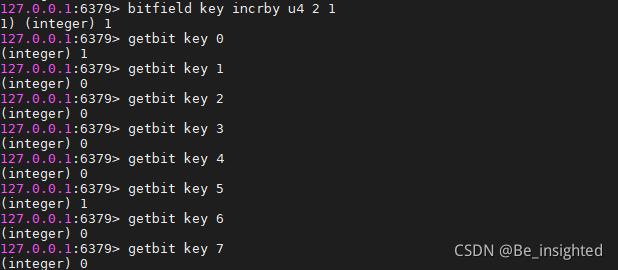
bitfield key incrby u4 2 1 从第2位开始对接下来的4位无符号数+1
bitfield key set u8 0 128 get u4 0 incrby u4 2 1 复合指令,是上面三者的组成,返回值是每个操作的子集,相当于管道操作

首先抛出一个业务问题:
假设产品经理让你设计一个模块,来统计PV(Page View页面的访问量),那么你会怎么做?
我想很多人对于PV(Page View页面的访问量)的统计会很快的想到使用Redis的incr、incrby指令,给每个网页配置一个独立Redis计数器就可以了,把这个技术区的key后缀加上当它的日期,这样一个请求过来,就可以通过执行incr、incrby指令统计所有PV。
此时当你完成这个需求后,产品经理又让你设计一个模块,统计UV(Unique Visitor,独立访客),那么你又会怎么做呢?
UV与PV不一样,UV需要根据用户ID去重,如果用户没有ID我们可能需要考虑使用用户访问的IP或者其他前端穿过了的唯一标志来区分,此时你可能会想到使用如下的方案来统计UV。
- 存储在MySQL数据库表中,使用distinct count计算不重复的个数
- 使用Redis的set、hash、bitmaps等数据结构来存储,比如使用set,我们可以使用用户ID,通过sadd加入set集合即可
但是上面的两张方案都存在两个比较大的问题:
- 随着数据量的增加,存储数据的空间占用越来越大,对于非常大的页面的UV统计,基本不合实际
- 统计的性能比较慢,虽然可以通过异步方式统计,但是性能并不理想
因此针对UV的统计,我们将会考虑使用Redis的新数据类型HyperLogLog.
HyperLogLog是用来做基数统计的算法,它提供不精确的去重计数方案(这个不精确并不是非常不精确),标准误差是0.81%,对于UV这种统计来说这样的误差范围是被允许的。HyperLogLog的优点在于,输入元素的数量或者体积非常大时,基数计算的存储空间是固定的。在Redis中,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同的基数。
但是:HyperLogLog只能统计基数的大小(也就是数据集的大小,集合的个数),他不能存储元素的本身,不能向set集合那样存储元素本身,也就是说无法返回元素。
HyperLogLog指令都是pf(PF)开头,这是因为HyperLogLog的发明人是Philippe Flajolet,pf是他的名字的首字母缩写。
3.3.2.1 PFADD key element [element …]
将任意数量的元素添加到指定的 HyperLogLog 里面,当PFADD key element [element …]指令执行时,如果HyperLogLog的估计近似基数在命令执行之后出现了变化,那么命令返回1,否则返回0,如果HyperLogLog命令执行时给定的键不存在,那么程序将先创建一个空的HyperLogLog结构,再执行命令。
该命令可以只给定key不给element,这种以方式被调用时:
- 如果给定的键存在且已经是一个HyperLogLog,那么这种调用不会产生任何效果
- 如果给定的键不存在,那么命令会闯进一个空的HyperLogLog,并且给客户端返回1
返回值:
如果HyperLogLog数据结构内部存储的数据被修改了,那么返回1,否则返回0
时间复杂度:
O(1)
使用示例:
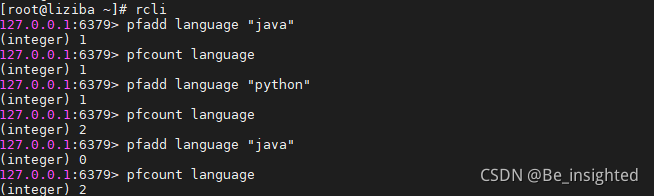
3.3.2.2 PFCOUNT key [key …]
PFCOUNT 指令后面可以跟多个key,当PFCOUNT key [key …]命令作用于单个键时,返回存储在给定键的HyperLogLog的近似基数,如果键不存在,则返回0;当PFCOUNT key [key …]命令作用于多个键时,返回所给定HyperLogLog的并集的近似基数,这个近似基数是通过将索引给定HyperLogLog合并至一个临时HyperLogLog来计算得出的。
返回值:
返回给定HyperLogLog包含的唯一元素的近似数量的整数值
时间复杂度:
当命令作用于单个HyperLogLog时,时间复杂度为O(1),并且具有非常低的平均常数时间。当命令作用于N个HyperLogLog时,时间复杂度为O(N),常数时间会比单个HyperLogLog要大的多。
使用示例:

3.3.2.3 PFMERGE destkey sourcekey [sourcekey …]
将多个HyperLogLog合并到一个HyperLogLog中,合并后HyperLogLog的基数接近于所有输入HyperLogLog的可见集合的并集,合并后得到的HyperLogLog会被存储在destkey键里面,如果该键不存在,那么命令在执行之前,会先为该键创建一个空的HyperLogLog。
返回值:
字符串回复,返回OK
时间复杂度:
O(N),其中N为被合并的HyperLogLog的数量,不过这个命令的常数复杂度比较高
使用示例:

3.3.3.1 伯努利试验
HyperLogLog的算法设计能使用12k的内存来近似的统计2^64个数据,这个和伯努利试验有很大的关系,因此在探究HyperLogLog原理之前,需要先了解一下伯努利试验。
以下是百度百科关于伯努利试验的介绍:
伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验,或称为伯努利概型。单个伯努利试验是没有多大意义的,然而,当我们反复进行伯努利试验,去观察这些试验有多少是成功的,多少是失败的,事情就变得有意义了,这些累计记录包含了很多潜在的非常有用的信息。
伯努利试验是数据概率论中的一部分,它的典故源于“抛硬币”。
一个硬币只有正面和反面,每次抛硬币出现正反面的概率都是50%,我们一直抛硬币直到出现第一次正面为止,记录抛硬币的次数,这个就被称为一次伯努利试验。伯努利试验需要做非常多的次数,数据才会变得有意义。
对于n次伯努利试验,出现正面的次数为n,假设每次伯努利试验抛掷的次数为k(也就是每次出现正面抛掷的次数),第一次伯努利试验抛掷次数为k1,第n次伯努利试验抛掷次数为kn,在这n次伯努利试验中,抛掷次数最大值为kmax。
上述的伯努利试验,结合极大似然估算方法(极大似然估计),得出n和kmax之间的估算关系:n=2^kmax。很显然这个估算关系是不准确的,例如如下案例:
第一次试验:抛掷1次出现正面,此时k=1,n=1;
第二次实验:抛掷3次出现正面,此时k=3,n=2;
第三次实验:抛掷6次出现正面,此时k=6,n=3;
第n次试验:抛掷10次出现正面,此时k=10,n=n,通过估算关系计算,n=2^10
上述案例可以看出,假设n=3,此时通过估算关系n=2^kmax,2^6 ≠3,而且偏差很大。因此得出结论,这种估算方法误差很大。
3.3.3.2 估值优化
关于上述估值偏差较大的问题,可以采用如下方式结合来缩小误差:
- 增加测试的轮数,取平均值。假设三次伯努利试验为1轮测试,我们取出这一轮试验中最大的的kmax作为本轮测试的数据,同时我们将测试的轮数定位100轮,这样我们在100轮实验中,将会得到100个kmax,此时平均数就是(k_max_1 + … + k_max_m)/m,这里m为试验的轮数,此处为100.
- 增加修正因子,修正因子是一个不固定的值,会根据实际情况来进行值的调整。
上述这种增加试验轮数,去kmax的平均值的方法,是LogLog算法的实现。因此LogLog它的估算公式如下:
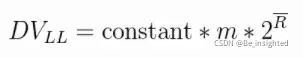
HyperLogLog与LogLog的区别在于HyperLogLog使用的是调和平均数,并非平均数。调和平均数指的是倒数的平均数(调和平均数)。调和平均数相比平均数能降低最大值对平均值的影响,这个就好比我和马爸爸两个人一起算平均工资,如果用平均值这么一下来我也是年薪数十亿,这样肯定是不合理的。
使用平均数和调和平均数计算方式如下:
假设我的工资20000,马云1000000000
使用平均数的计算方式:(20000 + 1000000000) / 2 = 500010000
调和平均数的计算方式:2/(1/20000 + 1/1000000000) ≈ 40000
很明显,平均工资月薪40000更加符合实际平均值,5个亿不现实。
调和平均数的基本计算公式如下:
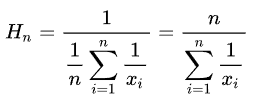
3.3.3.3 HyperLogLog的实现
根据3.1和3.2大致可以知道HyperLogLog的实现原理了,它的主要精髓在于通过记录下低位连续零位的最大长度K(也就是上面我们说的kmax),来估算随机数的数量n。
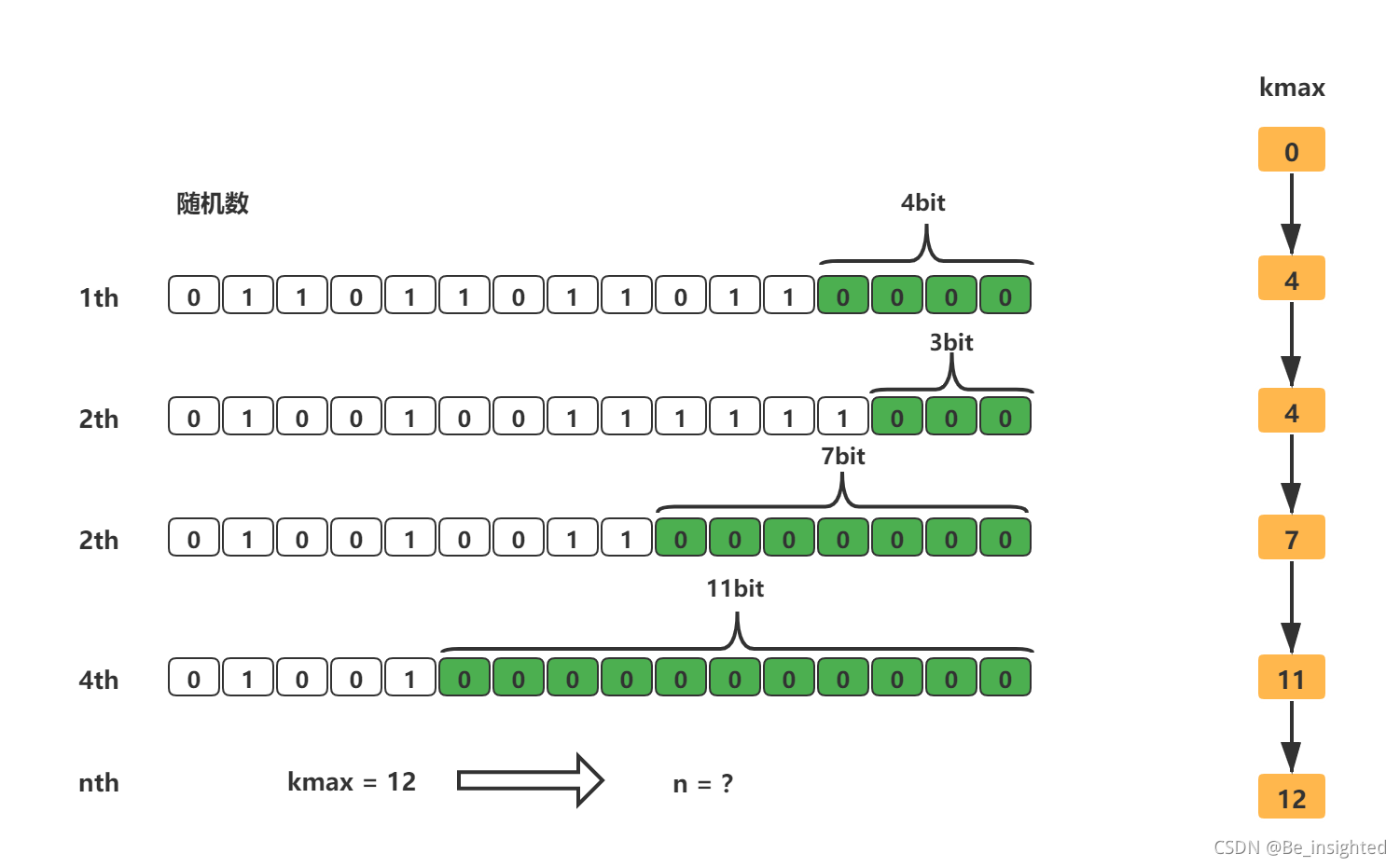
任何值在计算机中我们都可以将其转换为比特串,也就是0和1组成的bit数组,我们从这个bit串的低位开始计算,直到出现第一个1为止,这就好比上面的伯努利试验抛硬币,一直抛硬币直到出现第一个正面为止(只是这里是数字0和1,伯努利试验中使用的硬币的正与反,并没有区别)。而HyperLogLog估算的随机数的数量,比如我们统计的UV,就好比伯努利试验中试验的次数。
综上所述,HyperLogLog的实现主要分为三步:
第一步:转为比特串
通过hash函数,将输入的数据装换为比特串,比特串中的0和1可以类比为硬币的正与反,这是实现估值统计的第一步
第二步:分桶
分桶就是上面3.2估值优化中的分多轮,这样做的的好处可以使估值更加准确。在计算机中,分桶通过一个单位是bit,长度为L的大数组S,将数组S平均分为m组,m的值就是多少轮,每组所占有的比特个数是相同的,设为 P。得出如下关系:
- L = S.length
- L = m * p
- 数组S的内存 = L / 8 / 1024 (KB)
在HyperLogLog中,我们都知道它需要12KB的内存来做基数统计,原因就是HyperLogLog中m=16834,p=6,L=16834 * 6,因此内存为=16834 * 6 / 8 / 1024 = 12 (KB),这里为何是6位来存储kmax,因为6位可以存储的最大值为64,现在计算机都是64位或32位操作系统,因此6位最节省内存,又能满足需求。
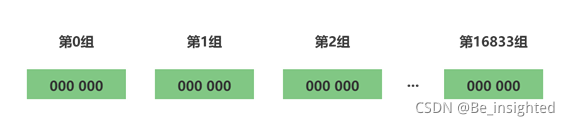
第三步:桶分配
最后就是不同的数据该如何分配桶,我们通过计算hash的方式得到比特串,只要hash函数足够好,就很难产生hash碰撞,我们假设不同的数值计算得到不同的hash值,相同的数值得到相同的hash值(这也是HyperLogLog能用来统计UV的一个关键点),此时我们需要计算值应该放到那个桶中,可以计算的方式很多,比如取值的低16位作为桶索引值,或者采用值取模的方式等等。
3.3.3.4 代码实现-BernoulliExperiment(伯努利试验)
首先来写一个3.1中伯努利试验n=2^kmax的估算值验证,这个估算值相对偏差会比较大,在试验轮次增加时估算值的偏差会有一定幅度的减小,其代码示例如下:
- package com.lizba.pf;
- import java.util.concurrent.ThreadLocalRandom;
- /**
- * <p>
- * 伯努利试验 中基数n与kmax之间的关系 n = 2^kmax
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/8/17 23:16
- */
- public class BernoulliExperimentTest {
- static class BitKeeper {
- /** 记录最大的低位0的长度 */
- private int kmax;
- public void random() {
- // 生成随机数
- long value = ThreadLocalRandom.current().nextLong(2L << 32);
- int len = this.lowZerosMaxLength(value);
- if (len > kmax) {
- kmax = len;
- }
- }
- /**
- * 计算低位0的长度
- * 这里如果不理解看下我的注释
- * value >> i 表示将value右移i, 1<= i <32 , 低位会被移出
- * value << i 表示将value左移i, 1<= i <32 , 低位补0
- * 看似一左一右相互抵消,但是如果value低位是0右移被移出后,左移又补回来,这样是不会变的,但是如果移除的是1,补回的是0,那么value的值就会发生改变
- * 综合上面的方法,就能比较巧妙的计算低位0的最大长度
- *
- * @param value
- * @return
- */
- private int lowZerosMaxLength(long value) {
- int i = 1;
- for (; i < 32; i++) {
- if (value >> i << i != value) {
- break;
- }
- }
- return i - 1;
- }
- }
- static class Experiment {
- /** 测试次数n */
- private int n;
- private BitKeeper bitKeeper;
- public Experiment(int n) {
- this.n = n;
- this.bitKeeper = new BitKeeper();
- }
- public void work() {
- for(int i = 0; i < n; i++) {
- this.bitKeeper.random();
- }
- }
- /**
- * 输出每一轮测试次数n
- * 输出 logn / log2 = k 得 2^k = n,这里的k即我们估计的kmax
- * 输出 kmax,低位最大0位长度值
- */
- public void debug() {
- System.out.printf("%d %.2f %d\n", this.n, Math.log(this.n) / Math.log(2), this.bitKeeper.kmax);
- }
- }
- public static void main(String[] args) {
- for (int i = 0; i < 100000; i++) {
- Experiment experiment = new Experiment(i);
- experiment.work();
- experiment.debug();
- }
- }
- }
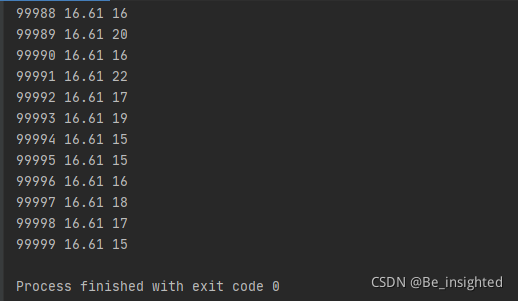
我们可以通过修改main函数中,测试的轮次,再根据输出的结果来观察,n=2^kmax这样的结果还是比较吻合的。
3.3.3.5 代码实现-HyperLogLog
接下来根据HyperLogLog中采用调和平均数+分桶的方式来做代码优化,模拟简单版本的HyperLogLog算法的实现,其代码如下:
- package com.lizba.pf;
- import java.util.concurrent.ThreadLocalRandom;
- /**
- * <p>
- * HyperLogLog 简单实现
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/8/18 10:40
- */
- public class HyperLogLogTest {
- static class BitKeeper {
- /** 记录最大的低位0的长度 */
- private int kmax;
- /**
- * 计算低位0的长度,并且保存最大值kmax
- *
- * @param value
- */
- public void random(long value) {
- int len = this.lowZerosMaxLength(value);
- if (len > kmax) {
- kmax = len;
- }
- }
- /**
- * 计算低位0的长度
- * 这里如果不理解看下我的注释
- * value >> i 表示将value右移i, 1<= i <32 , 低位会被移出
- * value << i 表示将value左移i, 1<= i <32 , 低位补0
- * 看似一左一右相互抵消,但是如果value低位是0右移被移出后,左移又补回来,这样是不会变的,但是如果移除的是1,补回的是0,那么value的值就会发生改变
- * 综合上面的方法,就能比较巧妙的计算低位0的最大长度
- *
- * @param value
- * @return
- */
- private int lowZerosMaxLength(long value) {
- int i = 1;
- for (; i < 32; i++) {
- if (value >> i << i != value) {
- break;
- }
- }
- return i - 1;
- }
- }
- static class Experiment {
- private int n;
- private int k;
- /** 分桶,默认1024,HyperLogLog中是16384个桶,并不适合我这里粗糙的算法 */
- private BitKeeper[] keepers;
- public Experiment(int n) {
- this(n, 1024);
- }
- public Experiment(int n, int k) {
- this.n = n;
- this.k = k;
- this.keepers = new BitKeeper[k];
- for (int i = 0; i < k; i++) {
- this.keepers[i] = new BitKeeper();
- }
- }
- /**
- * (int) (((m & 0xfff0000) >> 16) % keepers.length) -> 计算当前m在keepers数组中的索引下标
- * 0xfff0000 是一个二进制低16位全为0的16进制数,它的二进制数为 -> 1111111111110000000000000000
- * m & 0xfff0000 可以保理m高16位, (m & 0xfff0000) >> 16 然后右移16位,这样可以去除低16位,使用高16位代替高16位
- * ((m & 0xfff0000) >> 16) % keepers.length 最后取模keepers.length,就可以得到m在keepers数组中的索引
- */
- public void work() {
- for (int i = 0; i < this.n; i++) {
- long m = ThreadLocalRandom.current().nextLong(1L << 32);
- BitKeeper keeper = keepers[(int) (((m & 0xfff0000) >> 16) % keepers.length)];
- keeper.random(m);
- }
- }
- /**
- * 估算 ,求倒数的平均数,调和平均数
- *
- * @return
- */
- public double estimate() {
- double sumBitsInverse = 0.0;
- // 求调和平均数
- for (BitKeeper keeper : keepers) {
- sumBitsInverse += 1.0 / (float) keeper.kmax;
- }
- double avgBits = (float) keepers.length / sumBitsInverse;
- return Math.pow(2, avgBits) * this.k;
- }
- }
- /**
- * 测试
- *
- * @param args
- */
- public static void main(String[] args) {
- for (int i = 100000; i < 1000000; i+=100000) {
- Experiment experiment = new Experiment(i);
- experiment.work();
- double estimate = experiment.estimate();
- // i 测试数据
- // estimate 估算数据
- // Math.abs(estimate - i) / i 偏差百分比
- System.out.printf("%d %.2f %.2f\n", i, estimate, Math.abs(estimate - i) / i);
- }
- }
- }
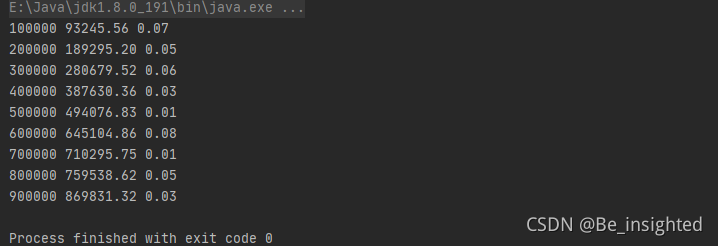
测试结果如下,误差基本控制在0.08以下,还是很高的误差,所以说算法很粗糙
Geospatial是Redis在3.2版本以后增加的地理位置GEO模块,这个模块可以用来实现微信附近的人,在线点餐“附近的餐馆”等位置功能。
3.4.2.1 GEOADD
命令简介:
GEOADD key longitude latitude member [longitude latitude member …]
![]()
将给定的空间元素(维度、经度、名字)添加到指定的键里面,数据以有序集合的形式被存放在键中。GEOADD接收的参数必须先输入经度,然后输入维度。
GEOADD经纬度的输入范围如下(对两极不支持):
- 有效经度介于-180°~180°之间
- 有效维度介于-85.05112878°至85.05112878°之间
当用户尝试输入一个超出范围的经度或者纬度时, GEOADD 命令将返回一个错误。
代码示例:
可以依次添加单个,也可以同时添加多个地理位置的元素。
- 127.0.0.1:6379> geoadd city 116.405289 39.904987 beijing
- (integer) 1
- 127.0.0.1:6379> geoadd city 117.190186 39.125595 tianjin
- (integer) 1
- 127.0.0.1:6379> geoadd city 121.472641 31.231707 shanghai
- (integer) 1
- 127.0.0.1:6379> geoadd city 112.982277 28.19409 changsha 113.28064 23.125177 guangzhou
- (integer) 2

错误示例:
- 127.0.0.1:6379> geoadd city 190 18 buzhidao
- (error) ERR invalid longitude,latitude pair 190.000000,18.000000
![]()
3.4.2.2 GEOPOS
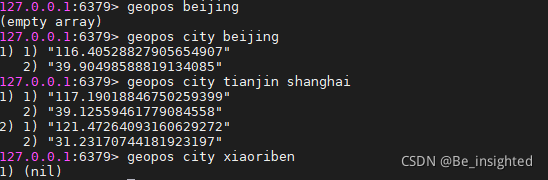
命令简介:
GEOPOS key member [member …]
根据键(key)获取给定位置元素的位置(经度和纬度),GEOPOS 可以接收一个member,也可以接收多个member,如果member不存在则返回nil
代码示例:
- 127.0.0.1:6379> geopos beijing
- (empty array)
- 127.0.0.1:6379> geopos city beijing
- 1) 1) "116.40528827905654907"
- 2) "39.90498588819134085"
- 127.0.0.1:6379> geopos city tianjin shanghai
- 1) 1) "117.19018846750259399"
- 2) "39.12559461779084558"
- 2) 1) "121.47264093160629272"
- 2) "31.23170744181923197"
- 127.0.0.1:6379> geopos city xiaoriben
- 1) (nil)
3.4.2.3 GEODIST
命令简介:
GEODIST key member1 member2 [unit]
返回两个给定位置之间的距离,以双精度浮点数的形式被返回。如果给定的位置其中一个不存在(两个都不存在也是一样,下面有示例),将会返回空值(nil)。
unit单位描述:
- m -> 米
- km -> 千米
- mi -> 英里
- ft -> 英尺
默认单位:
如果用户未给定指定单位unit,则默认为米(m)
误差范围:
GEODIST 计算的算法会将地球考虑为一个完全球体,在极限情况下,存在最大0.5%的误差
代码示例:
- 127.0.0.1:6379> geodist city beijing shanghai m
- "1067597.0432"
- 127.0.0.1:6379> geodist city beijing shanghai km
- "1067.5970"
- 127.0.0.1:6379> geodist city beijing xiaoriben
- (nil)
- 127.0.0.1:6379> geodist city meiguoguizi xiaoriben
- (nil)

3.4.2.4 GEORADIUS
命令简介:
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
m|km|ft|mi选项:
- m -> 米
- km -> 千米
- mi -> 英里
- ft -> 英尺
[WITHCOORD] [WITHDIST] [WITHHASH]选项:
- [WITHCOORD]:将位置元素的经度和纬度也一并返回。
- [WITHDIST] :在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
- [WITHHASH]: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
[ASC|DESC] 选项:
- ASC:根据给定的中心位置,从近到远返回位置元素
- DESC:根据给定的中心位置,从远到近返回位置元素
[COUNT count] 参数:
GEORADIUS 默认会返回符合条件的全部位置元素。但是用户可以通过[COUNT count] 参数去指定获取前N个匹配元素。这个参数可以减少需要返回的元素数量,一定程度上可以减少带宽压力。
返回值:
GEORADIUS 的返回值是一个数组,但是数组的内容会根据是否存在上述参数而改变
- 未给定任何WITH参数,则返回普通线性列表
- 给定[WITHCOORD] [WITHDIST] [WITHHASH]等参数后返回一个二层嵌套数组
具体返回值请查看后续示例,建议还是自己多搞几次就清楚了
代码示例:
未给定任何WITH参数
- 127.0.0.1:6379> georadius city 116.405289 39.904987 1000 km
- 1) "tianjin"
- 2) "beijing"
给定[WITHCOORD] [WITHDIST] [WITHHASH]等参数,返回的时二层嵌套数组
- 127.0.0.1:6379> georadius city 116.405289 39.904987 1000 km withcoord
- 1) 1) "tianjin"
- 2) 1) "117.19018846750259399"
- 2) "39.12559461779084558"
- 2) 1) "beijing"
- 2) 1) "116.40528827905654907"
- 2) "39.90498588819134085"
- 127.0.0.1:6379> georadius city 116.405289 39.904987 1000 km withdist
- 1) 1) "tianjin"
- 2) "109.7754"
- 2) 1) "beijing"
- 2) "0.0001"
3.4.2.5 GEORADIUSBYMEMBER
命令简介:
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
GEORADIUSBYMEMBER与GEORADIUS的区别在于,GEORADIUSBYMEMBER无需给定经纬度,只需要给定成员的key就行,具体使用与GEORADIUS一致
代码示例:
- 127.0.0.1:6379> georadiusbymember city beijing 1000 km
- 1) "tianjin"
- 2) "beijing"
- 127.0.0.1:6379> georadiusbymember city beijing 1000 km withcoord
- 1) 1) "tianjin"
- 2) 1) "117.19018846750259399"
- 2) "39.12559461779084558"
- 2) 1) "beijing"
- 2) 1) "116.40528827905654907"
- 2) "39.90498588819134085"
3.4.2.6 GEOHASH
命令名称:
GEOHASH key member [member …]
返回一个或多个位置元素的GeoHash表示,可以给顶多个key中的member,因此返回的是一个数组。
代码示例:
- 127.0.0.1:6379> geohash city beijing shanghai changsha
- 1) "wx4g0b7xru0"
- 2) "wtw3sjt9vs0"
- 3) "wt026ux4mz0"
为了便于各位大佬们学习Geospatial的学习,我整理了全国省会城市的经纬度在这,有需要的可以自取。
| 名称 | 经度 | 维度 |
| 北京市 | 116.405289 | 39.904987 |
| 天津市 | 117.190186 | 39.125595 |
| 呼和浩特市 | 111.751990 | 40.841490 |
| 银川市 | 106.232480 | 38.486440 |
| 石家庄市 | 114.502464 | 38.045475 |
| 济南市 | 117.000923 | 36.675808 |
| 郑州市 | 113.665413 | 34.757977 |
| 西安市 | 108.948021 | 34.263161 |
| 武汉市 | 114.298569 | 30.584354 |
| 南京市 | 118.76741 | 32.041546 |
| 合肥市 | 117.283043 | 31.861191 |
| 上海市 | 121.472641 | 31.231707 |
| 长沙市 | 112.982277 | 28.19409 |
| 南昌市 | 115.892151 | 28.676493 |
| 杭州市 | 120.15358 | 30.287458 |
| 福州市 | 119.306236 | 26.075302 |
| 广州市 | 113.28064 | 23.125177 |
| 台北市 | 121.5200760 | 25.0307240 |
| 海口市 | 110.199890 | 20.044220 |
| 南宁市 | 108.320007 | 22.82402 |
| 重庆市 | 106.504959 | 29.533155 |
| 昆明市 | 102.71225 | 25.040609 |
| 贵阳市 | 106.713478 | 26.578342 |
| 成都市 | 104.065735 | 30.659462 |
| 兰州市 | 103.834170 | 36.061380 |
| 西宁市 | 101.777820 | 36.617290 |
| 拉萨市 | 91.11450 | 29.644150 |
| 乌鲁木齐市 | 87.616880 | 43.826630 |
| 沈阳市 | 123.429092 | 41.796768 |
| 长春市 | 125.324501 | 43.886841 |
| 哈尔滨市 | 126.642464 | 45.756966 |
| 香港 | 114.165460 | 22.275340 |
| 澳门 | 113.549130 | 22.198750 |
Redis类似大多数成熟的数据库系统一样,提供了事务机制。Redis的事务机制非常简单,它没有严格的事务模型,无法像关系型数据库一样保证操作的原子性。
Redis事务最大的作用是保证多个指令的串行执行,它可以借助于Redis单线程读写的特性,保证Redis事务中的指令不会被事务外的指令打搅,不过要注意它不是原子性的。
完整事务案例:

multi开启一个事务之后,所有指令都不执行,而是缓存到事务队列中,直到服务器接收到exec指令,才开始执行整个事务中的指令。事务全部指令执行完毕后,一次性返回全部的结果。
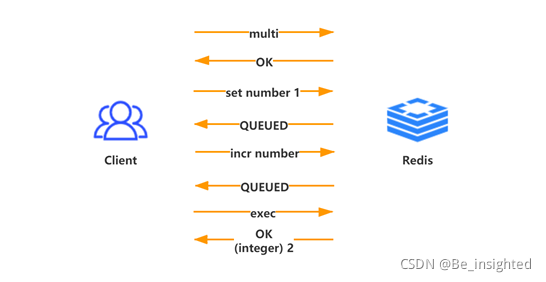
使用Redis事务,一个最需要注意的问题是,指令多,网络开销高;因此我们一定要结合管道pipeline一起使用,这样可以将多次网络io操作压缩成单次。
4.1.2.1 简介
Redis事务相关的指令有五个,分别是MULTI、EXEC、DISCARD、WATCH、UNWATCH
| 指令 | 指令作用 | 返回值 |
| MULTI | 标记一个事务块的开始 | 总是返回 OK |
| EXEC | 执行所有事务块内的命令 | 事务块内所有命令的返回值,按命令执行的先后顺序排列。当操作被打断时,返回空值 nil |
| DISCARD | 取消事务,放弃执行事务块内的所有命令,如果正在使用 WATCH 命令监视某个(或某些) key,那么取消所有监视,等同于执行命令 UNWATCH | 总是返回 OK |
| WATCH | 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断 | 总是返回 OK |
| UNWATCH | 取消 WATCH 命令对所有 key 的监视。如果在执行WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。因为 EXEC 命令会执行事务,因此 WATCH 命令的效果已经产生了;而 DISCARD 命令在取消事务的同时也会取消所有对 key 的监视,因此这两个命令执行之后,就没有必要执行 UNWATCH 了 | 总是返回 OK |
4.1.2.2 MULTI(开启事务)
MULTI用于标记一个事务的开始,事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性(atomic)地执行。MULTI指令总是返回OK。

4.1.2.3 EXEC(执行事务)
EXEC用于执行所有事务块内的命令,假如某个(或某些) key 正处于 WATCH 命令的监视之下,且事务块中有和这个(或这些) key 相关的命令,那么 EXEC 命令只在这个(或这些) key 没有被其他命令所改动的情况下执行并生效,否则该事务被打断(abort)。

4.1.2.4 DISCARD(取消事务)
DISCARD用于取消事务,放弃执行事务块内的所有命令。如果正在使用 WATCH 命令监视某个(或某些) key,那么取消所有监视,等同于执行命令 UNWATCH 。DISCARD指令总是返回OK。

4.1.2.5 WATCH(监视)
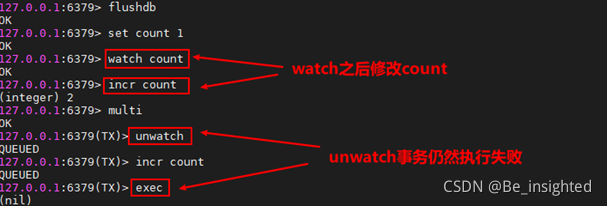
WATCH用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。这个实现方式也很简单,WATCH是在事务之间发送的指令,Redis服务在接收到指令时,会记录下该key对应的值,当Redis服务接收到EXEC指令,需要执行事务时,Redis服务首先会检查WATCH的key的值,从WATCH之后是否发生改变即可。

注意禁止在MULTI和EXEC之间执行WATCH指令,这会导致Redis服务响应异常

4.1.2.6 UNWATCH
UNWATCH用于取消WATCH命令对所有key的监视。如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。因为 EXEC 命令会执行事务,因此 WATCH 命令的效果已经产生了;而 DISCARD 命令在取消事务的同时也会取消所有对 key 的监视,因此这两个命令执行之后,就没有必要执行 UNWATCH 了。
通过模拟一个简单的余额增加的例子,使用Jedis客户端来使用Redis的事务。
- package com.lizba.redis.tx;
- import redis.clients.jedis.Jedis;
- import redis.clients.jedis.Transaction;
- import java.math.BigDecimal;
- import java.util.List;
- /**
- * <p>
- * Redis事务demo
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/9 23:53
- */
- public class TransactionDemo {
- private Jedis client;
- public TransactionDemo(Jedis client) {
- this.client = client;
- }
- /**
- * 添加余额
- *
- * @param userId 用户id
- * @param amt 添加余额
- * @return
- */
- public BigDecimal addBalance(String userId, BigDecimal amt) {
- String key = this.keyFormat(userId);
- // 初始用户余额为0
- client.setnx(key, "0");
- while (true) {
- client.watch(key);
- BigDecimal balance = new BigDecimal(client.get(key)).setScale(2, BigDecimal.ROUND_HALF_UP);
- BigDecimal amount = balance.add(amt);
- Transaction tx = client.multi();
- tx.set(key, amount.toPlainString());
- List<Object> exec = tx.exec();
- // 返回值不为空则证明Redis事务成功
- if (exec != null) {
- break;
- }
- }
- return new BigDecimal(client.get(key)).setScale(2, BigDecimal.ROUND_HALF_UP);
- }
- /**
- * 获取总金额
- *
- * @param userId 用户id
- * @return
- */
- public BigDecimal getAmount(String userId) {
- String amt = client.get(keyFormat(userId));
- return new BigDecimal(amt);
- }
- /**
- * Redis key
- * @param userId 用户id
- * @return
- */
- private String keyFormat(String userId) {
- return String.format("balance:%s",userId);
- }
- }
测试代码:
- package com.lizba.redis.tx;
- import redis.clients.jedis.Jedis;
- import java.math.BigDecimal;
- import java.util.concurrent.CountDownLatch;
- /**
- * <p>
- * 测试Redis事务
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/10 0:03
- */
- public class TestTransactionDemo {
- private static CountDownLatch count = new CountDownLatch(100);
- public static void main(String[] args) throws InterruptedException {
- for (int i = 0; i < 100; i++) {
- new Thread(() -> {
- Jedis client = new Jedis("192.168.211.109", 6379);
- TransactionDemo demo = new TransactionDemo(client);
- demo.addBalance("liziba", BigDecimal.TEN);
- client.close();
- count.countDown();
- }).start();
- }
- count.await();
- Jedis client = new Jedis("192.168.211.109", 6379);
- BigDecimal amt = new TransactionDemo(client).getAmount("liziba");
- System.out.println(amt.toPlainString());
- }
- }
测试结果:
预期1000,结果1000

李子捌把话说在前头,如果你是面试或者为了了解知识来学习这一知识点,我觉得是有必要的;但是如果你是作为公司的技术负责人或者项目技术选型来使用Redis的Pub/Sub做消息的发布订阅,如果你不是走投无路了,那么你可能值得斟酌一下。Redis的Pub/Sub发布订阅,是Redis一步步完善消息队列功能的一个进步点,虽然现在没人用Pub/Sub做消息队列,但是它的思想和功能也是值得玩一下的,这个就是我写这篇文章的主要原因。同步执行的
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
- pub -> publisher
- sub -> subscriber
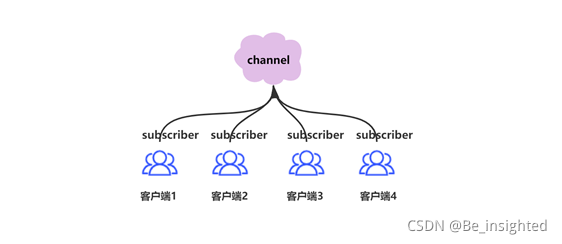
Redis客户端订阅一个频道非常简单,它可以订阅任意数量的频道。
如下图,Redis客户端订阅(subscriber)频道(channel)
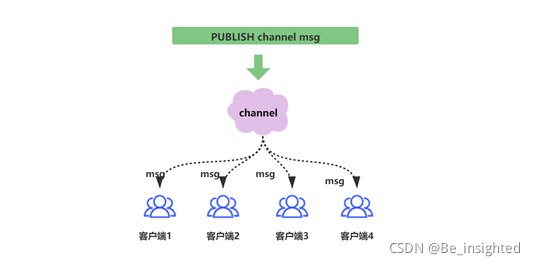
如下图,当消息发送到客户端订阅的频道(channel)时,这个消息就会被订阅的所有未故障的客户端接接收到
演示Redis的发布订阅,我们需要开启多个客户端,订阅频道(channel)。
4.2.2.1 普通订阅
如下我会启动4个客户端,第一个客户端用来发布消息,其他的用来订阅频道,接收消息。
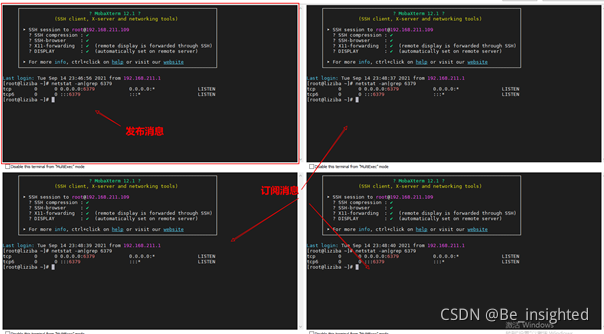
客户端2、客户端3、客户端4同时订阅news和weather频道(channel)
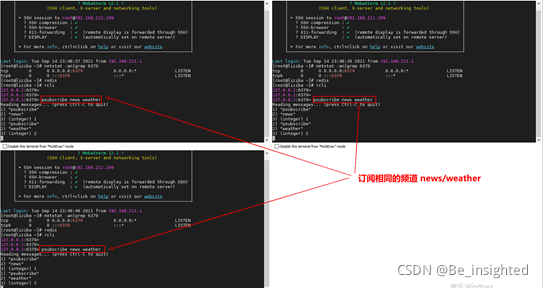
客户端1向频道news/weather发布消息
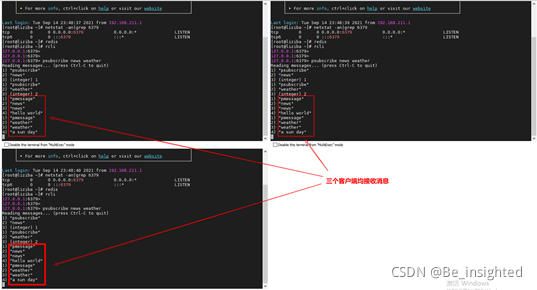
此时可以看到三个客户端均接收客户端1向频道news/weather发布的消息
4.2.2.2 模式订阅
Redis为了方便同时订阅多个模式的频道,也有类似市面上常见的MQ中模式订阅功能(如Rabbit MQ中的topic),这个功能可以匹配符的方式进行订阅。
比如我需要订阅以fund.开头,任意字符结尾的频道,就可以使用如下的订阅方式
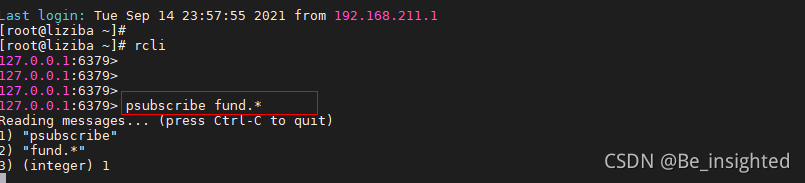
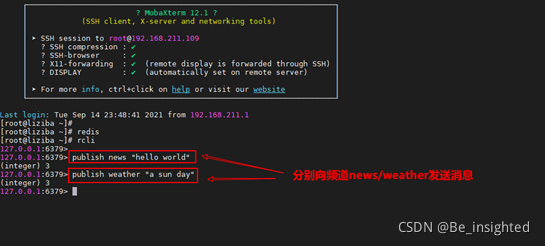
尝试向fund.nuoan发布消息
![]()
订阅了fund.*的客户端,成功接收到消息

关于Redis的Pub/Sub为什么被抛弃,最主要的原因是它无法持久化,没有实现持久化机制的Pub/Sub,无法做到消息的不丢失,在客户端宕机或者Redis服务宕机的情况下,都会导致消息丢失。
- 客户端宕机,客户端无法接收消息
- Redis服务宕机,没有客户端能连接上,肯定也无法接收到消息
大部分情况下,我们都不会用到Redis去做消息中间件,市面上成熟且好用的消息中间件非常多,如果真的需要使用Redis来做消息中间件,可以考虑Redis 5.0的新数据结构Stream,这个功能在Pub/Sub的基础上,实现了持久化机制,并且大力借鉴了kafka的设计原理,完善了Redis用于实现消息队列的不足之处。
Stream弥补了Redis作为MQ(message queue)技术选型上的不足之处;Redis 5.0发布的Stream相比Pub/Sub模块,Stream支持消息持久化,结合sentinel或cluster使其成为了一个比较可靠的消息队列。尽管我认为它很难成为公司MQ的技术选型产品,但是关于Stream的使用和特性(消费组),仍值得一探究竟。
Stream对标消息队列,因此几乎具备了MQ所有的特性,以下列出Stream所具有的部分特性:
- 消息顺序存储
- 消息ID序列化规则生成
- 消息的遍历
- 消息阻塞/非阻塞式获取
- 客户端分组消费消息
- 消息确认机制
- 消息异常机制
- 消息队列监控
在文中也会说到Stream的这些特性。
4.3.2.1 Stream 结构
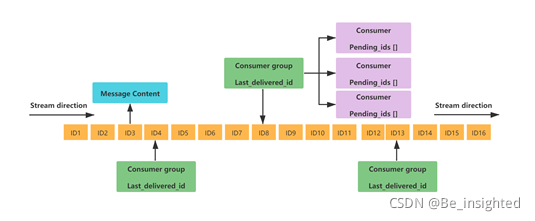
在探索Stream的内部结构之前,先看一张清晰的Stream结构图:
如下是关于上图的名词解析:
- Message Content:消息内容
- Consumer group:消费组,通过XGROUP CREATE 命令创建,一个消费组可以有多个消费者
- Last_delivered_id:游标,每个消费组有一个游标,任意消费者读取消息后,游标都会向前移动
- Consumer:消费者,消费组中的消费者
- Pending_ids:状态变量,每个消费者会有一个状态变量,用于记录被当前消费者读取,但是并未ack的消息id
4.3.2.2 四个唯一
Stream内部维护了一个消息链表,以此使得消息能够具有队列的特性。在Stream中有四个唯一需要了解:
- 每个Stream都具有唯一的名称
- 每个消息(Message)都具有一个由系统分配或者客户端指定唯一ID
- 每个Stream中的消费组(Consumer_Group)具有唯一名称
- 每个消费组(Consumer_Group)中的消费者(Consumer)具有唯一名称
4.3.2.3 消息ID
Stream的消息ID可以由服务端自动生成,也可以由客户端传入,如下图是自动生成的结构:
![]()
系统自动生成的规则
<millisecondsTime>-<sequenceNumber
millisecondsTime指的是Redis节点服务器的本地时间,如果存在当前的毫秒时间戳比以前已经存在的数据的时间戳小的话(本地时间钟后跳),那么系统将会采用以前相同的毫秒创建新的ID。
sequenceNumber指的是序列号,在相同的millisecondsTime毫秒下,序列号从0开始递增,序列号是64位长度,理论上在统一毫秒内生成的数据量无法到达这个级别,因此不用担心sequenceNumber会不够用。
客户端显示传入规则
Redis对于ID有强制要求,格式必须是-,最小ID为0-1,并且后续ID不能小于前一个ID
4.3.2.4 消息内容
Stream的消息内容,也就是图中的Message Content它的结构类似Hash结构,以key-value的形式存在。
4.3.3.1 指令汇总
Stream的指令根据可以分为两类,分别是消息队列相关指令,消费组相关指令。
消息队列相关指令:
| 指令名称 | 指令作用 |
| XADD | 添加消息到队列末尾 |
| XTRIM | 限制Stream的长度,如果已经超长会进行截取 |
| XDEL | 删除消息 |
| XLEN | 获取Stream中的消息长度 |
| XRANGE | 获取消息列表(可以指定范围),忽略删除的消息 |
| XREVRANGE | 和XRANGE相比区别在于反向获取,ID从大到小 |
| XREAD | 获取消息(阻塞/非阻塞),返回大于指定ID的消息 |
消费组相关指令:
| 指令名称 | 指令作用 |
| XGROUP CREATE | 创建消费者组 |
| XREADGROUP GROUP | 读取消费者组中的消息 |
| XACK | ack消息,消息被标记为“已处理” |
| XGROUP SETID | 设置消费者组最后递送消息的ID |
| XGROUP DELCONSUMER | 删除消费者组 |
| XPENDING | 打印待处理消息的详细信息 |
| XCLAIM | 转移消息的归属权(长期未被处理/无法处理的消息,转交给其他消费者组进行处理) |
| XINFO | 打印Stream\Consumer\Group的详细信息 |
| XINFO GROUPS | 打印消费者组的详细信息 |
| XINFO STREAM | 打印Stream的详细信息 |
4.3.3.2 XADD
XADD 用于向Stream 队列中添加消息,如果指定的Stream 队列不存在,则该命令执行时会新建一个Stream 队列。
XADD的指令语法:
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value …]
如下通过XADD展示了定义ID的两种方式,具体可以看2.3。

4.3.3.3 XTRIM
XTRIM 用于对Stream的长度进行限定。
XTRIM 的指令语法:
XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]
- MAXLEN 允许的最大长度,如果长度超出则会抛弃队列前面的消息
- MINID 允许的最小id,从某个id值开始保留,其余的将会被抛弃

4.3.3.4 XDEL
XDEL 用于删除消息。
XDEL 的指令语法:
XDEL key ID [ID …]

4.3.3.5 XLEN
XLEN 用于获取Stream 队列的消息的长度。
XLEN 的指令语法:
XLEN key

4.3.3.6 XRANGE
XRANGE 用于获取消息列表(可以指定范围),忽略删除的消息。
XRANGE 的指令语法:
XRANGE key start end [COUNT count]
- start 表示开始值,-代表最小值
- end 表示结束值,+代表最大值
- count 表示最多获取多少个值
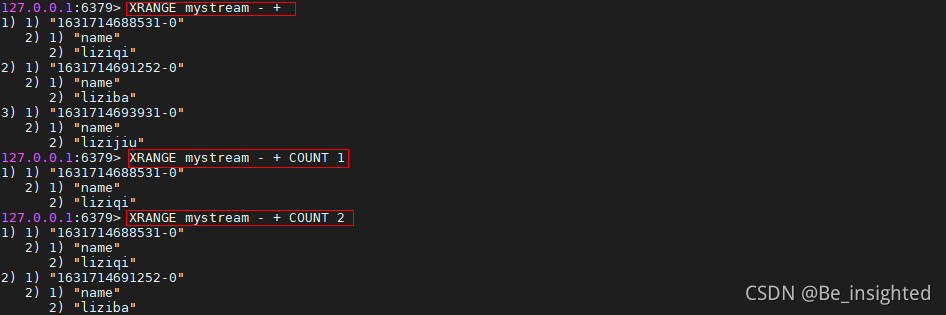
4.3.3.7 XREVRANGE
XREVRANGE 用于获取消息列表(可以指定范围),忽略删除的消息。与XRANGE 的区别在于,获取消息列表元素的方向是相反的,end在前,start在后。
XREVRANGE 的指令语法:
XREVRANGE key end start [COUNT count]

4.3.3.8 XREAD
XREAD 用于获取消息(阻塞/非阻塞),只会返回大于指定ID的消息。
XREAD 的指令语法:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
- COUNT 最多读取多少条消息
- BLOCK 是否已阻塞的方式读取消息,默认不阻塞,如果milliseconds设置为0,表示永远阻塞
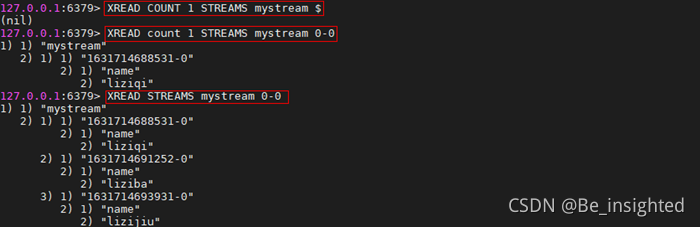
$代表特殊ID,表示以当前Stream已经存储的最大的ID作为最后一个ID,当前Stream中不存在大于当前最大ID的消息,因此此时返回nil。
0-0代表从最小的ID开始获取Stream中的消息,当不指定count,将会返回Stream中的所有消息,注意也可以使用0(00/000也都是可以的……)。
阻塞方式获取Stream中的指令,这里演示阻塞获取一条消息
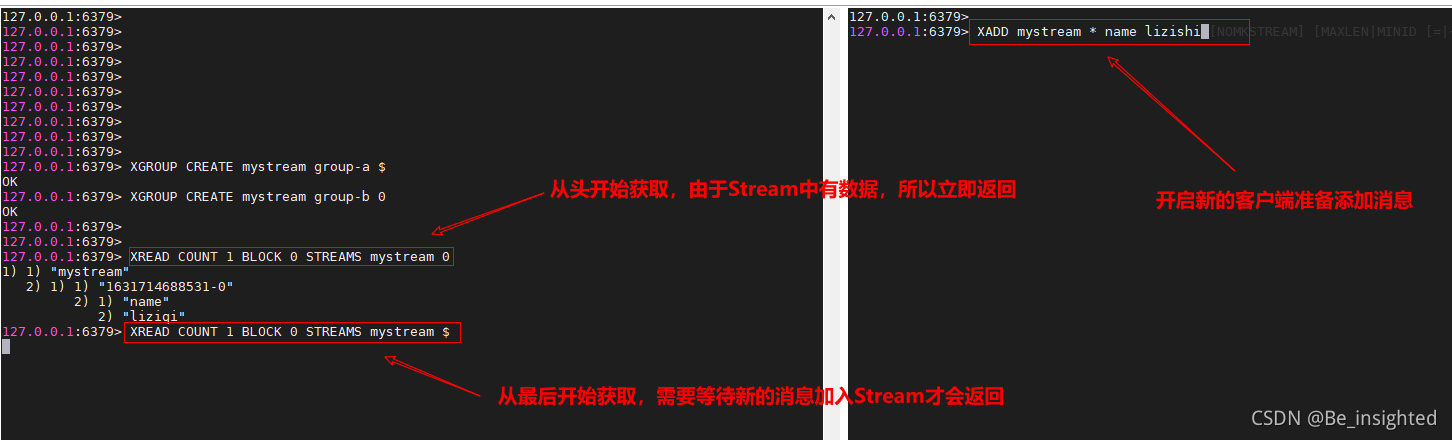
4.3.3.9 XGROUP CREATE
XGROUP CREATE 用于创建消费者组。
XGROUP CREATE 的指令语法:
XGROUP [CREATE key groupname ID|$ [MKSTREAM]] [SETID key groupname ID|$] [DESTROY key groupname] [CREATECONSUMER key groupname consumername] [DELCONSUMER key groupname consumername]
XGROUP CREATE中的指令没什么复杂的,第一个中括号中的几个参数最为重要,如下图两种方式:
- $表示从Stream尾部开始消费,会忽略Stream中目前已有的数据
- 0表示从Stream头部开始消费

如果Stream不存在,XGROUP CREATE 语法将会报错,因此可以得出不允许在不存在的Stream上创建消费者组

4.3.3.10 XREADGROUP GROUP
XREADGROUP GROUP 用于读取消费者组中的消息。
XREADGROUP GROUP 的指令语法:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key …] ID [ID …]
注意,这里有一个比较重要的知识点,刚开始的时候可能容易搞错:
>这个特殊符号表示消息到目前为止,从未传递给其他消费者的消息
0表示指定消息ID,因为ID均大于0-0(0代指0-0),因此代表从Stream 的队列头部开始获取消息
在如下截图中,为何第一次 mystream 0 获取消息返回empty,在执行完 mystream > 之后,第二 mystream 0 却成功的获取到了消息,但是很明显mystream中刚添加了两条消息,第一次不应该失败才对呀?
这是因为,当指定ID进行消息获取时,命令将会让我们访问我们的历史待处理消息(曾被获取,但是未ack)。即传递给这个指定消费者(由提供的名称标识)的消息集,并且到目前为止从未使用XACK进行确认。
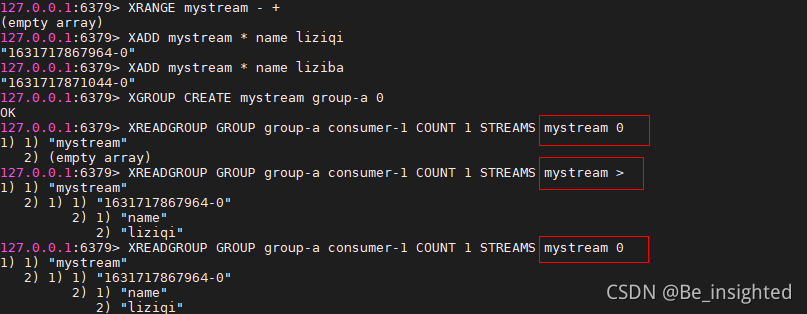
XREADGROUP GROUP 也可以像XREAD 一样使用阻塞的方式获取消息

当向mystream中添加消息后,阻塞读返回

4.3.3.11 XACK
XACK 用于标记为“已处理”。
XACK 的指令语法:
XACK key group ID [ID …]
结合**XREADGROUP GROUP **中指定ID的方式只能获取未ack的未处理消息的特性,测试XACK指令。从如下的测试示例中可以得出两个结论:
- 消息首次ack成功,返回1,ack失败返回0
- 3.9中的结论是正确的
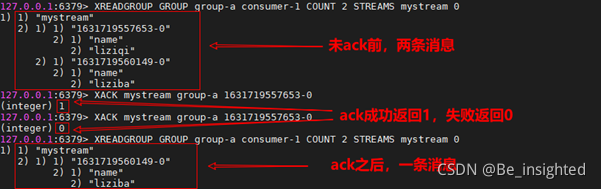
4.3.3.12 XPENDING
XPENDING 用于打印待处理消息的详细信息。
XPENDING 指令是非常有用的,因为它可以打印待处理消息的信息。如果在一个消费者组中存在多个消费者,如果存在部分消费者永久的故障,无法再处理消息了,我们就可以通过XPENDING 指令来查看指定消费者组中的消费者未ack的消息,然后转移给其他消费者进行处理。
XPENDING 的指令语法:
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
XPENDING 返回值解析:
- 第一个参数表示当前消费者中待处理消息的总数
- 第二个参数表示待处理消息的最小ID
- 第三个参数表示待处理消息的最大ID
- 第四个参数表示消费者列表和未处理的消息数量

4.3.3.13 XCLAIM
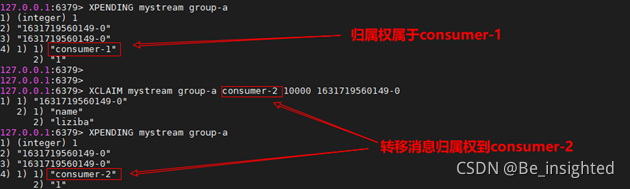
XCLAIM 用于转移消息的归属权。
XCLAIM 的指令语法:
XCLAIM key group consumer min-idle-time ID [ID …] [IDLE ms] [TIME ms-unix-time] [RET
指令参数解析:
- key 表示Stream的名称
- group 表示需要转移消息的归属权的消费者组名称
- consumer 表示接收消息的消费者名称
- min-idle-time 表示最小空闲时间,只有后续指定ID的消息空闲时间大于指定的空闲时间,消息归属权转移指令才会生效
- ID [] 需要转移归属权的消息ID,数组,可以是多个
示例中,将consumer-1中ID为1631719560149-0的未处理的消息的归属权转移到consumer-2下:
4.3.3.14 XINFO
XINFO 用于打印Stream\Consumer\Group的详细信息。
XINFO 的指令语法:
XINFO [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP]
示例打印指定STREAM的详细消息

使用Stream有两个点需要注意,如果使用不当都会导致内存消耗增大。
- 待处理消息过多,消息未及时ack
- Stream消息持续持久化,使用XDEL删除消息
关于第一点,待处理消息过多,消息未及时ack,其导致内存增加的原因是,Stream会为每个消费者维护一个PEL列表,PEL列表用于存储处理完但未及时ack的消息ID。我们在实际使用过程中,处理完的消息一定要及时ack,也有定时检查是否有消费者不可用导致消息堆积的情况。
XPENDING能查询出消费者中待处理的消息,就是因为有PEL的存在。

关于第二点,使用XDEL删除Stream中不在需要的消息,其导致内存增加的原因是,Stream的XDEL删除消息的指令,并不会从内存上删除消息,它只是给消息打上标记位,下次通过XRANGE指令忽略这些消息而已。因此我们可以设置Stream的最大长度,来解决这个问题,在XADD中使用MAXLEN指定Stream队列的长度,当消息超出长度就会将队列头消息清除掉。(不过这种处理方式一定要做到及时处理消息,避免消息的丢失。)
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value …]
Redis是一种基于客户端-服务端模型以及请求/响应的TCP服务。一次Redis客户端发起的请求,经过服务端的响应后,大致会经历如下的步骤:
- 客户端发起一个(查询/插入)请求,并监听socket返回,通常情况都是阻塞模式等待Redis服务器的响应
- 服务端处理命令,并且返回处理结果给客户端
- 客户端接收到服务的返回结果,程序从阻塞代码处返回
Redis客户端和服务端之间通过网络连接进行数据传输,这个连接可以很快(loopback接口)或很慢(建立了一个多次跳转的网络连接)。无论网络延如何延时,数据包总是能从客户端到达服务器,并从服务器返回数据回复客户端,这个时间被称之为RTT(Round Trip Time - 往返时间)。我们可以很容易就意识到,Redis在连续请求服务端时,即使Redis每秒能处理100k请求,但也会因为网络传输花费大量时间,导致整体性能的下降。
因此如果遇到大量的批处理,我们可以考虑使用Redis的pipeline(管道)。值得注意的是,管道技术并不是Redis特有的技术,管道技术往往需要客户端-服务器的共同配合,大部分工作任务其实是在客户端完成,很显然Redis支持管道技术,按照官网的意思,Redis的最低版本就考虑了管道技术的支持性设计。
如下图,多个连续的incr指令,使用pipeline(管道)后,多个连续的incr指令只会花费一次网络来回开销,这个开销会随着n数值的增大,大幅减少网络io开销,从而提升整体服务的性能。
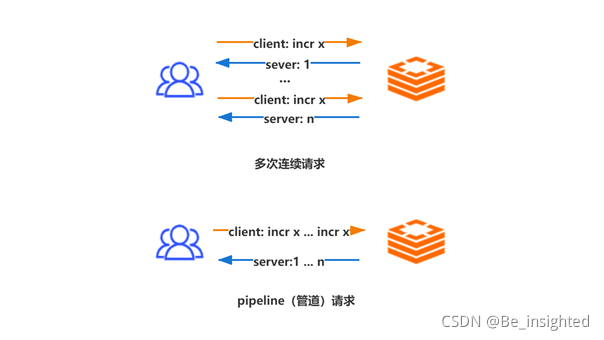
在上述简介中,提到了管道技术优化的是网络传输的耗时时间,这里通过Redis客户端-服务端的一次完整的网络请求来回,深入探索pipeline的本质。
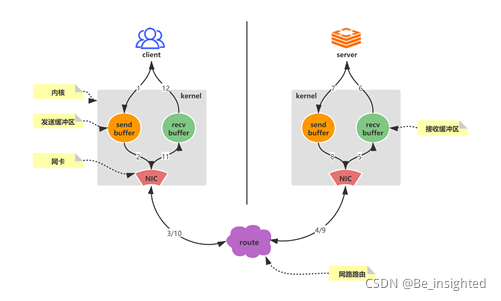
- 客户端调用write将数据写入操作系统内核(kernel)为socket连接分配的发送缓冲区(send buffer)
- 客户端操作系统内核将发送缓冲区(send buffer)的数据发送到网卡(NIC)
- 网卡(NIC)将数据通过路由(route)将数据送到Redis服务器机器网卡(NIC)
- 服务器操作系统内核(kernel)将网卡(NIC)接收的数据,写入内核为socket分配的接收缓冲区(recv buffer)
- 服务器进程从接收缓冲区调用read读取数据,并进行数据逻辑处理
- 数据处理完成之后,服务器进程调用write将响应数据写入操作系统内核为socket分配的发送缓冲区
- 操作系统内核将发送缓冲区的数据发送到服务器网卡
- 服务器网卡将响应数据通过路由发送到客户端网卡
- 客户端网卡接收响应数据
- 客户端操作系统内核读取网卡接收到的服务器响应数据,并写入操作系统为socket连接分配的介绍缓冲区
- 客户端进程调用read从接收缓冲区中读取服务器响应数据
- 一次完整网络请求来回过程结束
对于pipeline技术而言,就是将n * 12个步骤,合并成1 * 12,这样服务请求响应的总体时间将会大大的减少。
有个值得注意的点:
在上述网络请求来回中,可能出现我们经常说到的io阻塞:
- 当write操作发生,并且发送缓冲区(send buffer)满时,就会导致write操作阻塞
- 当read操作发生,并且接收缓冲区(recv buffer)满时,就会导致read操作阻塞
上述的这两个阻塞如果出现,将会导致整个请求时间变长,因此我们操作大批量指令的时候,比如10k个指令,我们可以合理的对指令分多次批量发送,这样可以减少出现阻塞的情况,也可以避免服务器响应一个过大的答复包,导致客户端内存负载过重。
使用Redis提供的benchmark对Redis进行性能测试,
如过你是Windows下的Redis,在安装目录下有个redis-benchmark.exe,进入cmd命令模式测试即可。
如果你是在Linux下的redis,在安装目录的src目录下有个redis-benchmark

redis-benchmark的全部指令参数如下所示,我们这里测试pipeline,需要使用-P
| 指令名称 | 描述 | 默认值 |
| -h | 指定Redis服务器hostname | 127.0.0.1 |
| -p | 指定Redis服务器端口 | 6379 |
| -s | 指定Redis服务器Server Socket | |
| -a | 指定Redis服务器密码 | |
| -c | 指定客户端并发数 | 50 |
| -n | 指定总请求数 | 100000 |
| -dbnum | 指定Redis数据库 | 0 |
| -k | 1=keep alive 0=reconnect | 1 |
| -r | 使用随机key,value 对相关指令进行压测 | |
| -P | 使用管道(pipeline) | 1(no pipeline) |
| -q | 强制退出Redis,仅展示query/sec | |
| --csv | 使用CSV格式输出 | |
| -l | 循环运行测试 | |
| -t | 运行逗号分隔的测试列表 | |
| -I | Idle模式,仅打开N个idle连接并等待 |
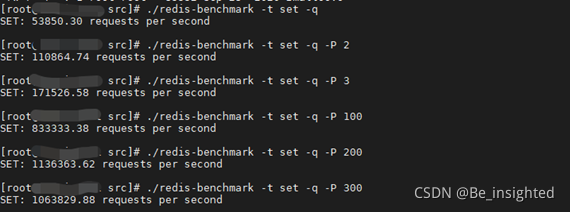
通过普通方式测试set指令和pipeline方式测试set指令,可以看到Redis服务不同的QPS:
- 普通set方式,Redis QPS 大概在5.3万左右
- 当使用pipeline set时,随着管道内并行请求数量的增加,Redis QPS可以达到100万以上
4.4.4 Jedis使用pipeline
测试代码
- package com.liziba.redis;
- import redis.clients.jedis.Jedis;
- import redis.clients.jedis.Pipeline;
- import java.io.IOException;
- /**
- * <p>
- * 测试pipeline
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/14 22:43
- */
- public class PipelineTest {
- public static void main(String[] args) throws IOException {
- Jedis client = new Jedis("127.0.0.1", 6379);
- long startPipe = System.currentTimeMillis();
- Pipeline pipe = client.pipelined();
- pipe.multi();
- for (int i = 0; i < 100000; i++) {
- pipe.set("pipe" + i, i + "" );
- }
- pipe.exec();
- pipe.close();
- long endPipe = System.currentTimeMillis();
- System.out.println("pipeline set cost time : " + (endPipe - startPipe) + "ms");
- for (int i = 0; i < 100000; i++) {
- client.set("normal" + i, i + "");
- }
- System.out.println("normal set cost time : " + (System.currentTimeMillis() - endPipe)+ "ms");
- }
- }
测试结果

Redis的非常快,很大一部分原因是因为Redis的数据存储在内存中,既然在内存中,那么当服务器宕机或者断电的时候,数据就会全部丢失了,所以Redis提供了两种机制来保证Redis数据不会因为故障而全部丢失,这种机制称为Redis的持久化机制。
Redis的持久化机制有两种:
- RDB(Redis Data Base) 内存快照
- AOF(Append Only File) 增量日志
**RDB(Redis DataBase) **指的是在指定的时间间隔内将内存中的数据集快照写入磁盘,RDB是内存快照(内存数据的二进制序列化形式)的方式持久化,每次都是从Redis中生成一个快照进行数据的全量备份。
优点:
- 存储紧凑,节省内存空间
- 恢复速度非常快
- 适合全量备份、全量复制的场景,经常用于灾难恢复(对数据的完整性和一致性要求相对较低的场合)
缺点:
- 容易丢失数据,容易丢失两次快照之间Redis服务器中变化的数据。
- RDB通过fork子进程对内存快照进行全量备份,是一个重量级操作,频繁执行成本高。
- fork子进程,虽然共享内存,但是如果备份时内存被修改,最大可能膨胀到2倍大小。
AOF(Append Only File)是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行AOF文件中的Redis命令来恢复数据。AOF能够解决数据持久化实时性问题,是现在Redis持久化机制中主流的持久化方案(后续会谈到4.0以后的混合持久化)。
优点:
- 数据的备份更加完整,丢失数据的概率更低,适合对数据完整性要求高的场景
- 日志文件可读,AOF可操作性更强,可通过操作日志文件进行修复
缺点:
- AOF日志记录在长期运行中逐渐庞大,恢复起来非常耗时,需要定期对AOF日志进行瘦身处理(后续详述)
- 恢复备份速度比较慢
- 同步写操作频繁会带来性能压力
官网地址
RDB持久化方案进行备份时,Redis会单独fork一个子进程来进行持久化,会将数据写入一个临时文件中,持久化完成后替换旧的RDB文件。在整个持久化过程中,主进程(为客户端提供服务的进程)不参与IO操作,这样能确保Redis服务的高性能,RDB持久化机制适合对数据完整性要求不高但追求高效恢复的使用场景。
下面展示RDB持久化流程:
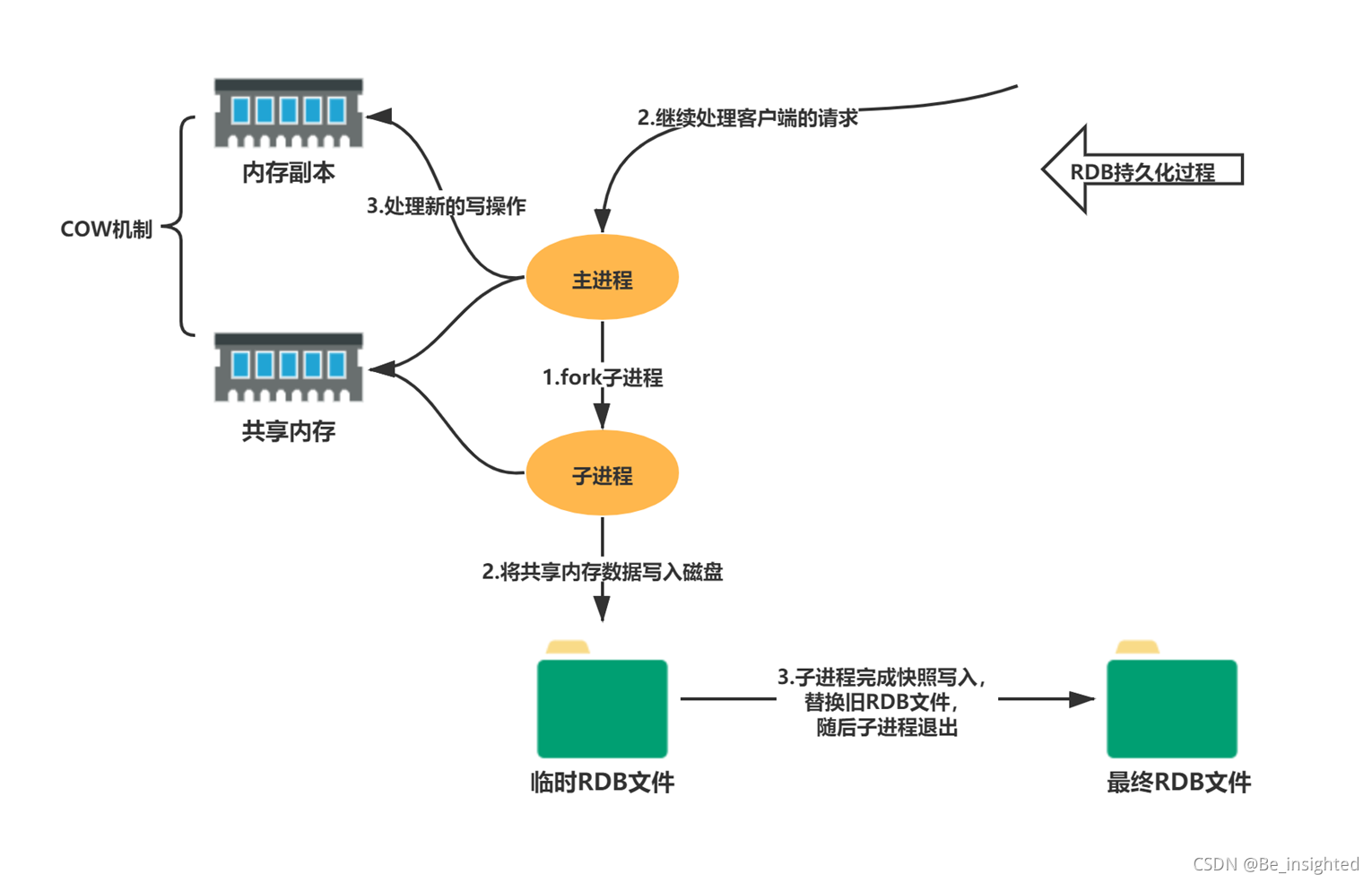
上面说到了RDB持久化过程中,主进程会fork一个子进程来负责RDB的备份,这里简单介绍一下fork
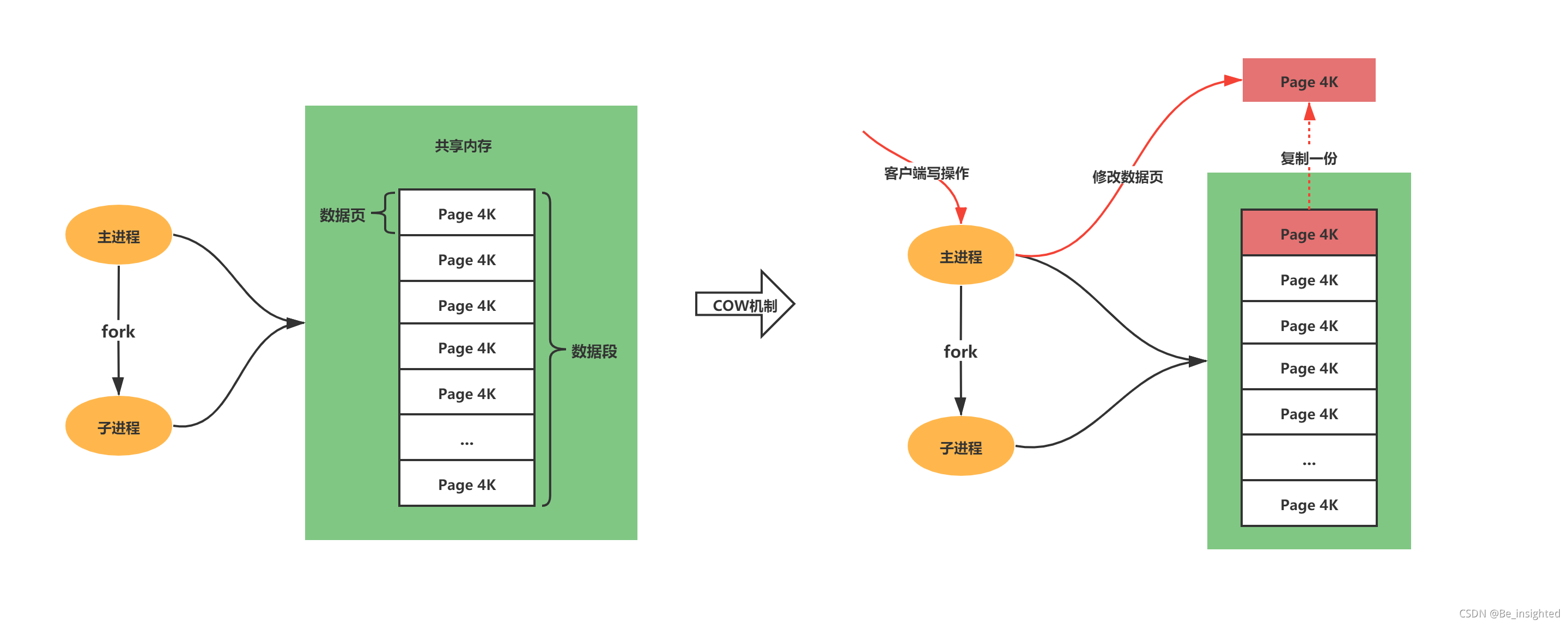
- Linux操作系统中的程序,fork会产生一个和父进程完全相同的子进程。子进程与父进程所有的数据均一致,但是子进程是一个全新的进程,与原进程是父子进程关系
- 出于效率考虑,Linux操作系统中使用COW(Copy On Write)写时复制机制,fork子进程一般情况下与父进程共同使用一段物理内存,只有在进程空间中的内存发生修改时,内存空间才会复制一份出来。
在Redis中,RDB持久化就是充分的利用了这项技术,Redis在持久化时调用glibc函数fork一个子进程,全权负责持久化工作,这样父进程仍然能继续给客户端提供服务。fork的子进程初始时与父进程(Redis的主进程)共享同一块内存;当持久化过程中,客户端的请求对内存中的数据进行修改,此时就会通过COW机制对数据段页面进行分离,也就是复制一块内存出来给主进程去修改。
RDB触发的规则分为两大类,分别是手动触发和自动触发:
自动触发:
- 配置触发规则
- shutdown触发
- flushall触发
手动触发:
- save
- bgsave
以下介绍Redis的RDB持久化机制中的自动触发机制中的配置触发规则来触发RDB,涉及到RDB规则的配置、文件存储路径配置、文件名配置、文件压缩配置、文件完整性校验配置。
5.2.3.1 配置规则触发
- 在Redis安装目录下的redis.conf配置文件中搜索 /snapshot即可快速定位,配置文件默认注释了下面三行数据,通过配置规则来触发RDB的持久化,需要开启或者根据自己的需求按照规则来配置。

下面对配置规则进行解释,实际使用过程中可以根据需求进行合理的配置
save 3600 1 -> 3600秒内有1个key被修改,触发RDB
save 300 100 -> 300 秒内有100个key被修改,触发RDB
save 60 10000 -> 60 秒内有10000个key被修改,触发RDB
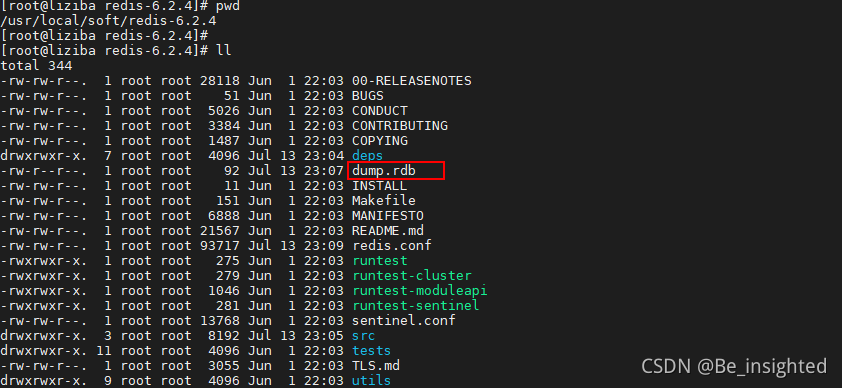
- 配置RDB文件的存储路径

我们可以在Redis的安装目录下看到dump.rdb文件,如果没看到,连接到客户端执行一次shutdown,这个是后面
shutdown自动触发规则,后续会讲述
- 配置RDB文件的名称

- 配置RDB文件压缩
Redis默认会使用LZF算法对Redis的RDB文件进行压缩,这会消耗一定的CPU计算资源,但是会带来空间上的节省

- 配置RDB文件完整性校验
Redis 默认使用CRC64的算法,对RDB文件完整性进行校验,以此来保证RDB文件的完整

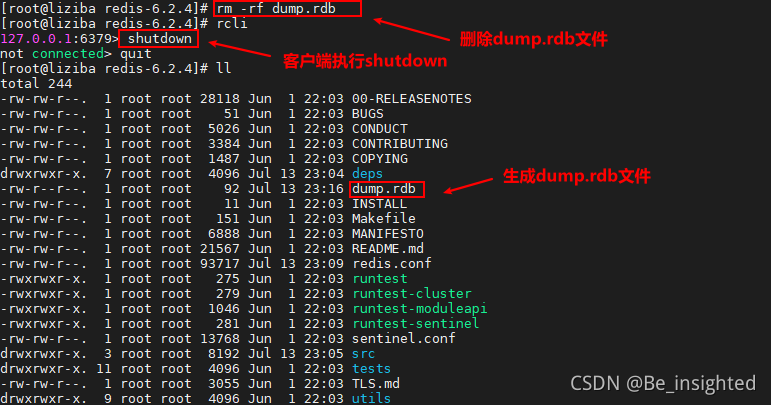
5.2.3.2 shutdown触发
shutdown触发Redis的RDB持久化机制非常简单,我们在客户端执行shutdown即可。
5.2.3.3 flushall触发
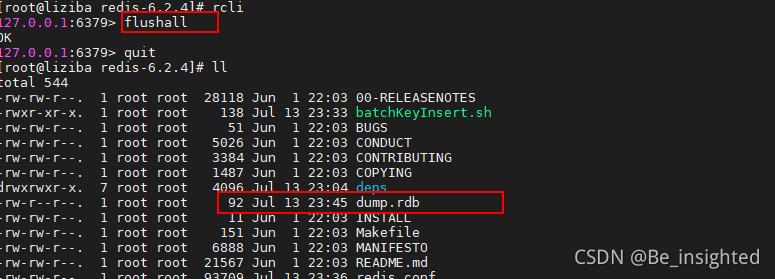
首先这里一定要特别注意,flushall是删库跑路,它是清空dump.rdb文件,千万千万不要看了博主的文章,跑到公司备份的时候顺手来个flushall,然后到时候来问候我……,这个flushall是为了清空Redis数据的同时清空dump.rdb文件,要不然重启Redis的时候,数据又会恢复到上一次备份的时候的数据,与flushall的执行指令含义就冲突了。
为了证明这个文件不会保留数据,我特地特地的写个脚本测试一下:
编写一个批量插入的脚本文件
vi batchKeyInsert.sh
- #!/bin/bash
- for((i=0;i<100000;i++))
- do
- echo -en "Hello Redis." | redis-cli -h 192.168.211.108 -p 6379 -c -x set name$i >>redis.log
- done
文件赋权
chmod +x batchKeyInsert.sh
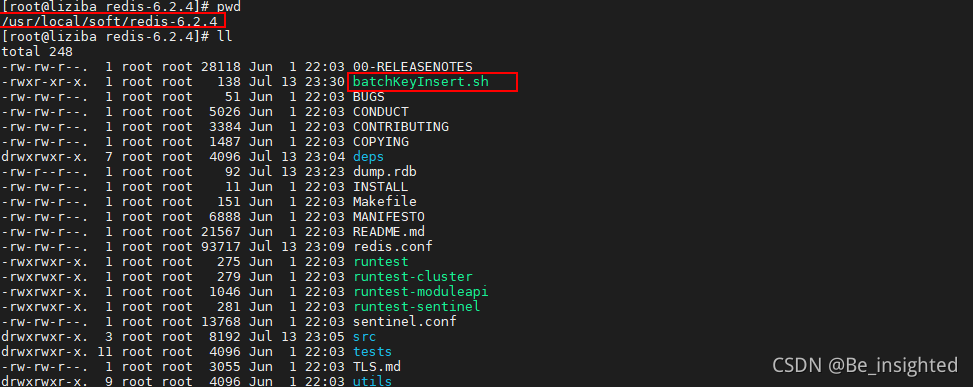
./batchKeyInsert.sh

此时查看dump.rdb
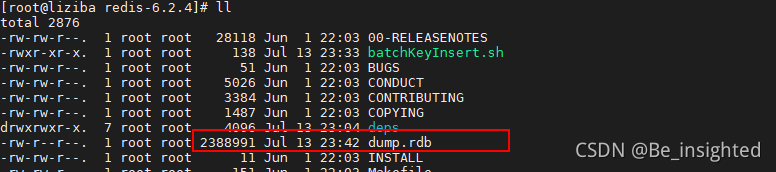
执行flushall,后再次查看,rbd文件被清空
手动触发RDB持久化的方式可以使用save命令和bgsave命令,这两个命令的区别如下。
save:执行save指令,阻塞Redis的其他操作,会导致Redis无法响应客户端请求,不建议使用。
bgsave:执行bgsave指令,Redis后台异步进行快照的保存操作,此时Redis仍然能响应客户端的请求。
在实际的生产环境中,我们一般不会使用主节点Master来进行持久化备份,我们会通过在Redis的多个从服务器上进行RDB持久化备份,这样是为了对Redis数据的多次备份,防止出现网络分区或者部分节点宕机甚至是硬件损坏的情况发生。
作为运维或者架构师,李子捌觉得应该要定时定期的通过脚本对Redis持久化文件进行转移备份,这样双重保险,更加可靠,万一遇到突发情况,也是多一手解决方案。
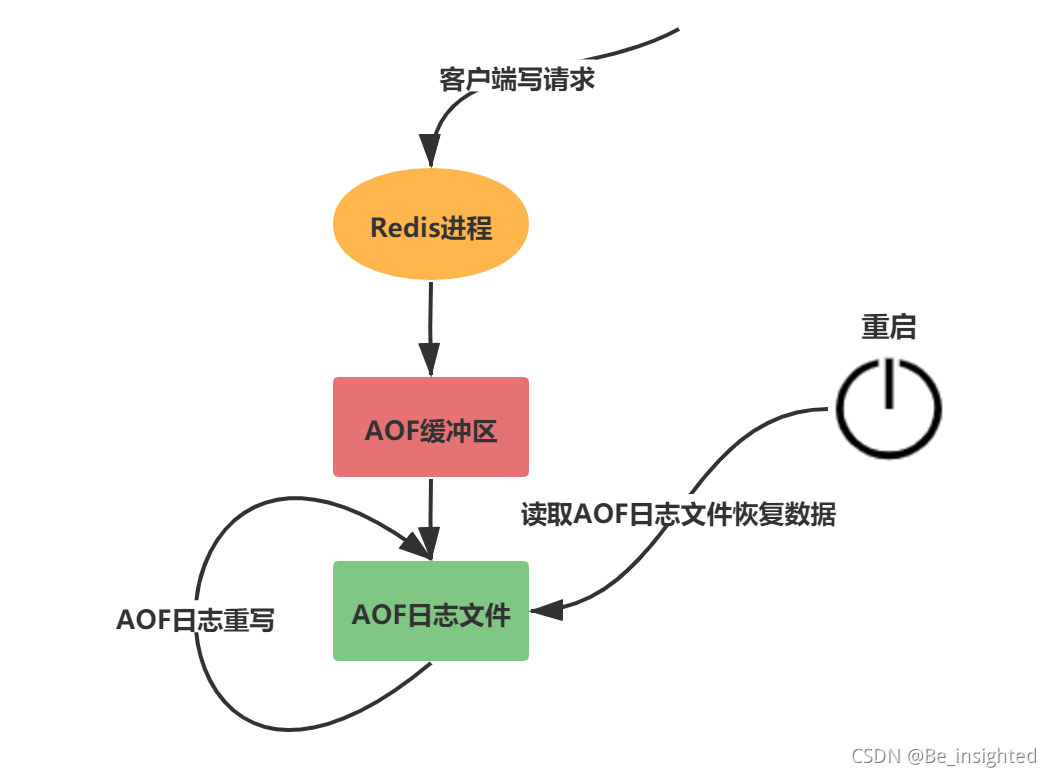
Redis配置文件中开启,AOF持久化方案进行备份时,客户端所有请求的写命令都会被追加到AOF缓冲区中,缓冲区中的数据会根据Redis配置文件中配置的同步策略来同步到磁盘上的AOF文件中,同时当AOF的文件达到重写策略配置的阈值时,Redis会对AOF日志文件进行重写,给AOF日志文件瘦身。Redis服务重启的时候,通过加载AOF日志文件来恢复数据。
5.3.2.1 基本配置
AOF默认不开启,默认为appendonly no,开启则需要修改为appendonly yes

AOF配置文件的名称默认为appendonly.aof

配置文件的地址可以通过在redis客户端执行config get dir获取,其保存路径与RDB一致

5.3.2.2 同步频率配置
AOF日志是以文件的形式存在的,当程序对AOF日志文件进行写操作时,实际上将内容写到了内核为文件描述符分配的一个内存缓冲区中,随后内核会异步的将缓冲区中的数据刷新到磁盘中。如果缓冲区中的数据没来得及刷回磁盘时,服务器宕机了,这些数据就会丢失。
因此Redis通过调用Linux操作系统的glibc提供的fsync(int fid)来将指定文件的内容强制从内核缓冲区刷回磁盘,以此来保证缓冲区中的数据不会丢失。不过这是一个IO操作,相比Redis的性能来说它是非常慢的,所以不能频繁的执行。
Redis配置文件中有三种刷新缓冲区的配置:
appendfsync always
每次Redis写操作,都写入AOF日志,这种配置理论上Linux操作系统扛不住,因为Redis的并发远远超过了Linux操作系统提供的最大刷新频率,就算Redis写操作比较少的情况,这种配置也是非常耗性能的,因为涉及到IO操作,所以这个配置基本上不会用
appendfsync everysec
每秒刷新一次缓冲区中的数据到AOF文件,这个Redis配置文件中默认的策略,兼容了性能和数据完整性的折中方案,这种配置,理论上丢失的数据在一秒钟左右。
appendfsync no
Redis进程不会主动的去刷新缓冲区中的数据到AOF文件中,而是直接交给操作系统去判断,这种操作也是不推荐的,丢失数据的可能性非常大。

注意要刷新缓冲区的数据到磁盘需要将如下配置,配置为no,不是yes
no-appendfsync-on-rewrite no
5.3.2.3 AOF修复功能
AOF持久化机制正常恢复与RDB持久化机制的恢复是一样的,都只需要将备份文件放置到Redis的工作目录下,Redis启动时就会自动的加载。AOF持久化机制提供了AOF文件异常时恢复的功能,这个功能在AOF文件损坏的场景中经常被使用到。
测试,清空Redis服务中的数据

写入数据

AOF日志文件每秒会被刷新一次数据,此时数据已经写入了appendonly.aof文件

打开文件我们可以非常清除的阅读AOF的文件内容,看到Redis的指令序列

此时人为的进行数据破坏

再次启动发现无法启动(我配置的别名启动)

执行redis-check-aof --fix ../appendonly.aof 对AOF日志文件进行修复

修复过程中会有部分数据丢失

连接客户端查看数据

5.3.2.4 AOF重写
前面提到AOF的缺点时,说过AOF属于日志追加的形式来存储Redis的写指令,这会导致大量冗余的指令存储,从而使得AOF日志文件非常庞大,比如同一个key被写了10000次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此Redis提供重写机制来解决这个问题。Redis的AOF持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof
Redis4.0后的重写使用的是RDB快照和AOF指令拼接的方式,在AOF文件的头部是RDB快照的二进制形式的数据,尾部是快照产生后发生的写入操作的指令。
由于重写AOF文件时,会对Redis的性能带来一定的影响,因此也不能随便的进行自动重写,Redis提供两个配置用于自动进行AOF重写的指标,只有这两个指标同时满足的时候才会发生重写:
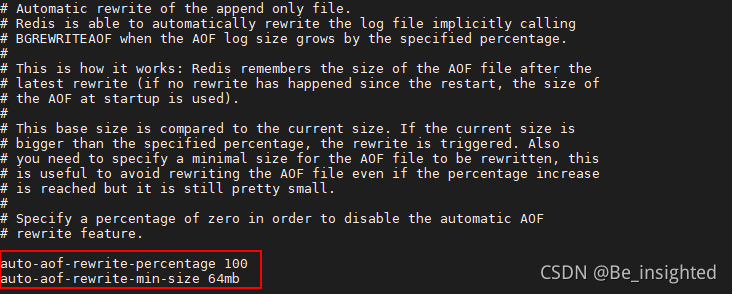
auto-aof-rewrite-percentage 100:指的是当文件的内存达到原先内存的两倍
auto-aof-rewrite-min-size 64mb:指的是文件重写的最小内存大小
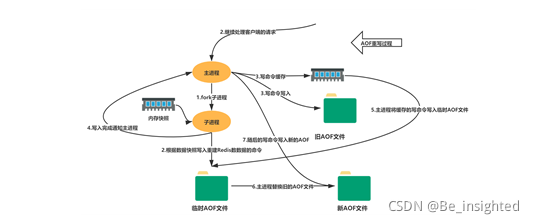
AOF重写流程如下:
- bgrewriteaof触发重写,判断是否存在bgsave或者bgrewriteaof正在执行,存在则等待其执行结束再执行
- 主进程fork子进程,防止主进程阻塞无法提供服务,类似RDB
- 子进程遍历Redis内存快照中数据写入临时AOF文件,同时会将新的写指令写入aof_buf和aof_rewrite_buf两个重写缓冲区,前者是为了写会旧的AOF文件,后者是为了后续刷新到临时AOF文件中,防止快照内存遍历时新的写入操作丢失
- 子进程结束临时AOF文件写入后,通知主进程
- 主进程会将上面3中的aof_rewirte_buf缓冲区中的数据写入到子进程生成的临时AOF文件中
- 主进程使用临时AOF文件替换旧AOF文件,完成整个重写过程
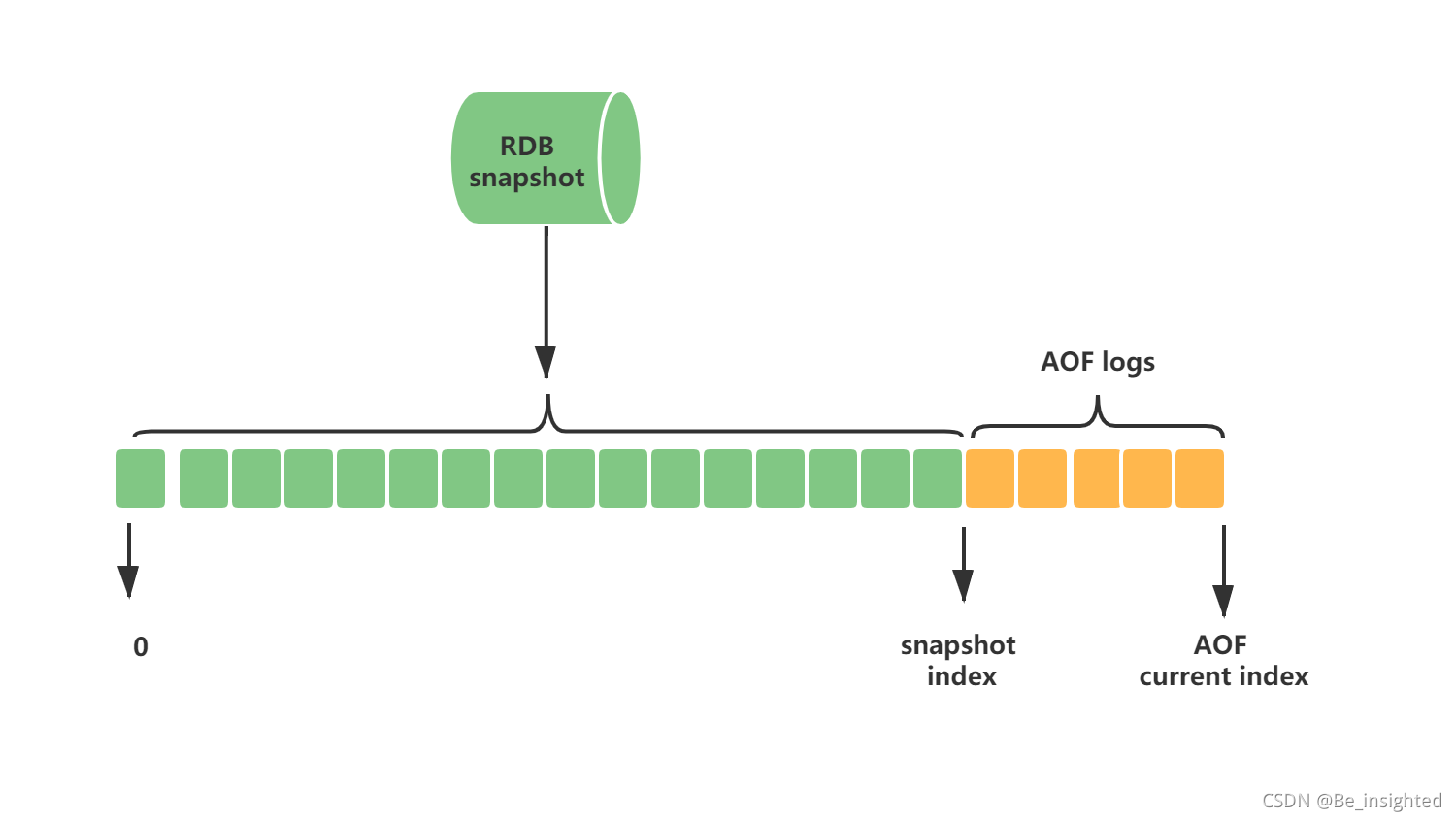
Redis4.0后大部分的使用场景都不会单独使用RDB或者AOF来做持久化机制,而是兼顾二者的优势混合使用。其原因是RDB虽然快,但是会丢失比较多的数据,不能保证数据完整性;AOF虽然能尽可能保证数据完整性,但是性能确实是一个诟病,比如重放恢复数据。
其日志文件结构如下:
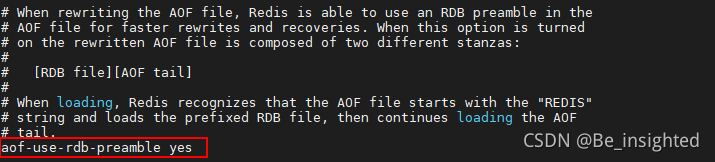
混合持久化通过aof-use-rdb-preamble yes开启,Redis 4.0以上版本默认开启
测试,我们先插入一些key,然后执行BGREWRITEAOF触发AOF持久化后,再插入一些key
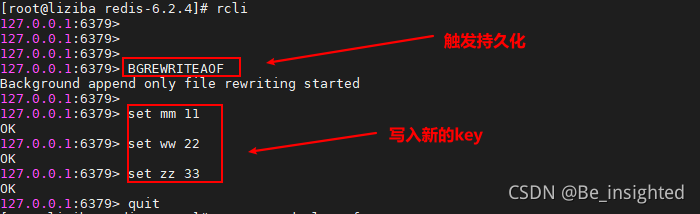
此时将会看到如下的效果,验证了混合持久化的方式
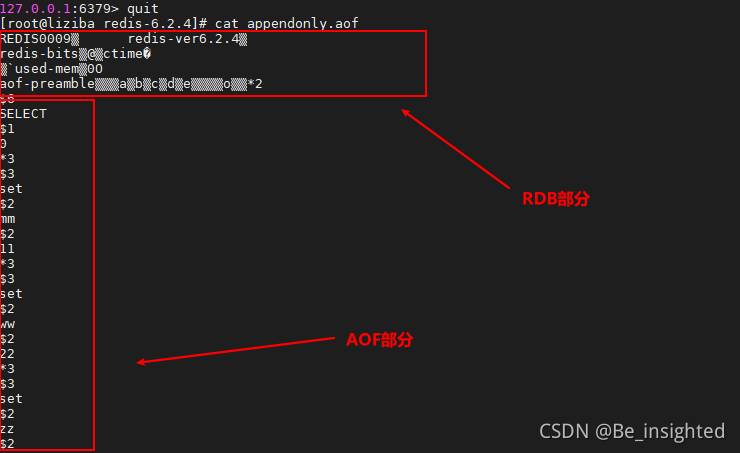
最后来总结这两者,到底用哪个更好呢?
- 推荐是两者均开启
- 如果对数据不敏感,可以选单独用RDB
- 不建议单独用AOF,因为可能会出现Bug
- 如果只是做纯内存缓存,可以都不用
Redis中文网的介绍:
-
如何选择使用哪种持久化方式?
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也Note: 因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。 (这是一个长期计划。) 接下来的几个小节将介绍 RDB 和 AOF 的更多细节。要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
Redis官网关于持久化的介绍
Redis中文网关于持久化的介绍
REDIS persistence -- Redis中国用户组(CRUG)
6.1 Redis安装布隆(Bloom Filter)过滤器
- 推荐版本6.x,最低4.x版本,可以通过如下命令查看版本:
redis-server -v
![]()
- 插件安装,网上大部分推荐v1.1.1,文章写的时候v2.2.6已经是release版本了,用户自己选择,地址全在下面(2.2.6官网介绍说是1.0版本的维护版本,如果不想使用新的功能,无需升级!)
v1.1.1
https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
v2.2.6
https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
以下安装全部在指定目录下完成,可以选择一个合适的统一目录进行软件安装和管理。
6.1.2.1 下载插件压缩包
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
6.1.2.2 解压
tar -zxvf v2.2.6.tar.gz
6.1.2.3 编译插件
- cd RedisBloom-2.2.6/
- make
编译成功后看到redisbloom.so文件即可
6.1.3.1 Redis配置文件修改
- 在redis.conf配置文件中加入如RedisBloom的redisbloom.so文件的地址
- 如果是集群则每个配置文件中都需要加入redisbloom.so文件的地址
- 添加完成后需要重启redis
loadmodule /usr/local/soft/RedisBloom-2.2.6/redisbloom.so
redis.conf配置文件中预置了loadmodule的配置项,我们可以直接在这里修改,后续修改会更加方便。

保存退出后一定要记得重启Redis!
保存退出后一定要记得重启Redis!
保存退出后一定要记得重启Redis!
6.1.3.2 测试是否成功
Redis集成布隆过滤器的主要指令如下:
- bf.add 添加一个元素
- bf.exists 判断一个元素是否存在
- bf.madd 添加多个元素
- bf.mexists 判断多个元素是否存在
连接客户端进行测试,如果指令有效则证明集成成功

如果出现如下情况(error) ERR unknown command ,可以通过如下方法检查:
- SHUTDOWN Redis实例,再重启实例,再次测试
- 检查配置文件是否配置redisbloom.so文件地址正确
- 检查Redis的版本是否过低
![]()
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
上面这句介绍比较全面的描述了什么是布隆过滤器,如果还是不太好理解的话,就可以把布隆过滤器理解为一个set集合,我们可以通过add往里面添加元素,通过contains来判断是否包含某个元素。由于本文讲述布隆过滤器时会结合Redis来讲解,因此类比为Redis中的Set数据结构会比较好理解,而且Redis中的布隆过滤器使用的指令与Set集合非常类似(后续会讲到)。
学习布隆过滤器之前有必要先聊下它的优缺点,因为好的东西我们才想要嘛!
布隆过滤器的优点:
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
布隆过滤器可以告诉我们** “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判,后续会讲),**利用这个判断是否存在的特点可以做很多有趣的事情。
- 解决Redis缓存穿透问题(面试重点)
- 邮件过滤,使用布隆过滤器来做邮件黑名单过滤
- 对爬虫网址进行过滤,爬过的不再爬
- 解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)
- HBase\RocksDB\LevelDB等数据库内置布隆过滤器,用于判断数据是否存在,可以减少数据库的IO请求
6.2.3.1 数据结构
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):
多个无偏hash函数:
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。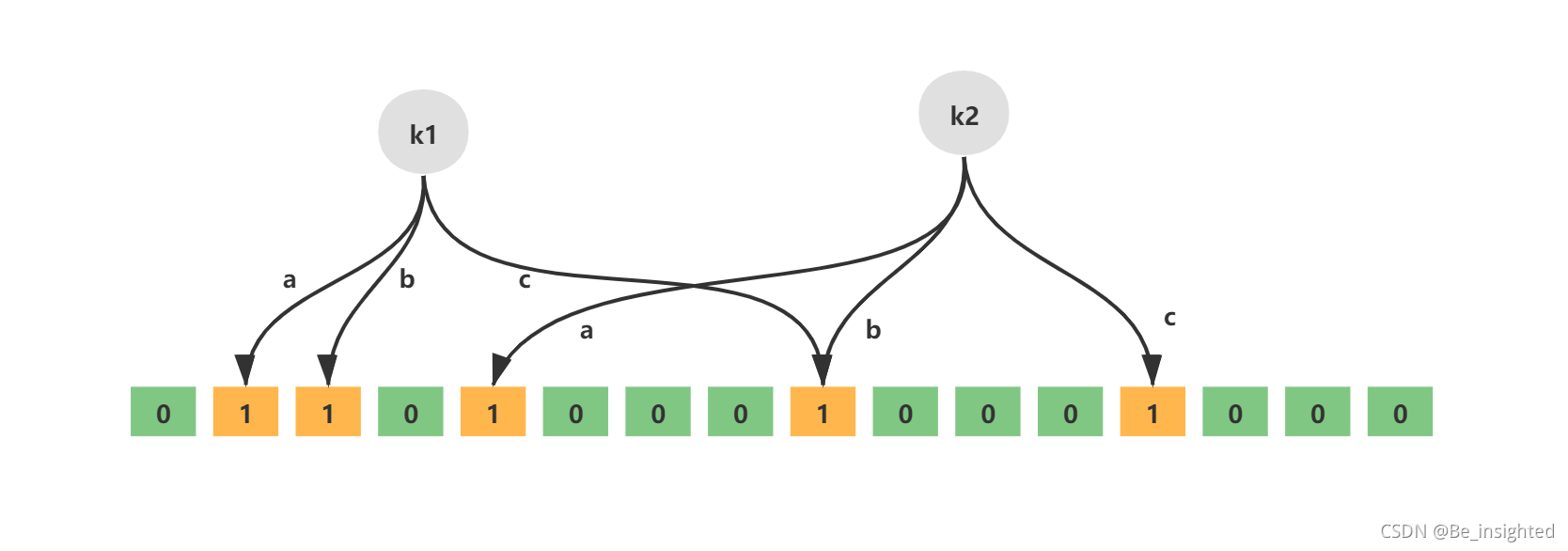
6.2.3.2 空间计算
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
它们之间的关系比较简单:
- 错误率越低,位数组越长,控件占用较大
- 错误率越低,无偏hash函数越多,计算耗时较长
如下地址是一个免费的在线布隆过滤器在线计算的网址:
Bloom Filter Calculator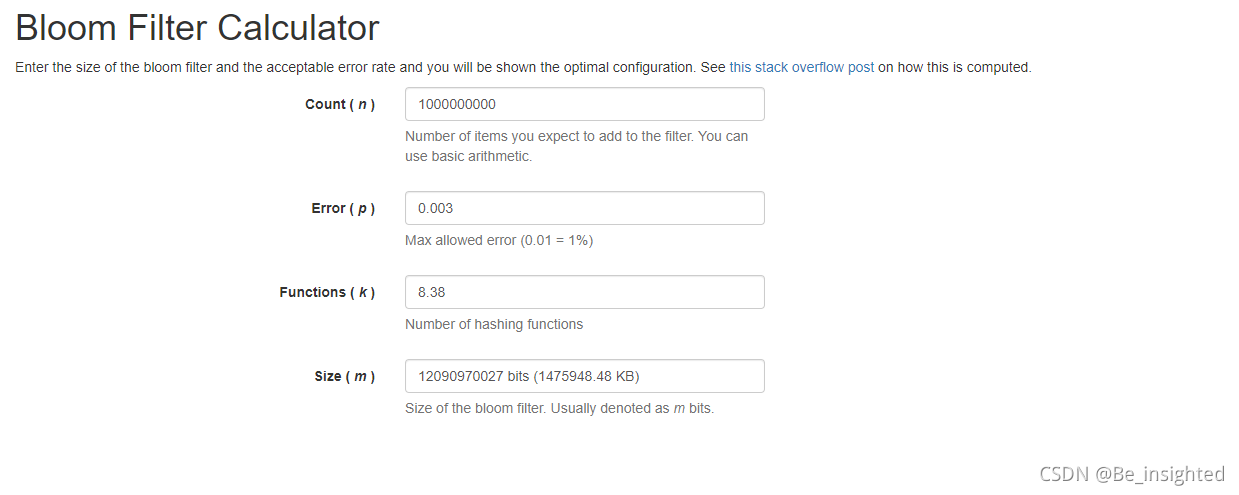 Bloom Filter Calculator
Bloom Filter Calculator
6.2.3.3 增加元素
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 将计算得到的数组索引下标位置数据修改为1
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.
如图所示: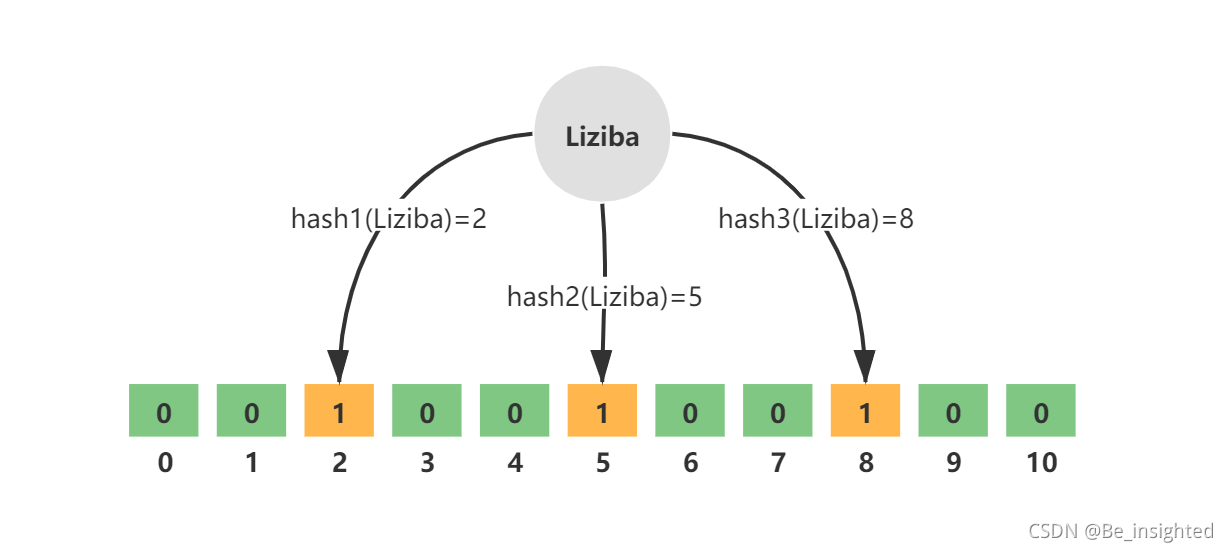
6.2.3.4 查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
关于误判,其实非常好理解,hash函数在怎么好,也无法完全避免hash冲突,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。例如李子捌和李子柒的hash值取模后得到的数组索引都是1,但其实这里只有李子捌,如果此时判断李子柒在不在这里,误判就出现啦!因此布隆过滤器最大的缺点误判只要知道其判断元素是否存在的原理就很容易明白了!
6.2.3.5 修改元素
无
6.2.3.6 删除元素
布隆过滤器对元素的删除不太支持,目前有一些变形的特定布隆过滤器支持元素的删除!关于为什么对删除不太支持,其实也非常好理解,hash冲突必然存在,删除肯定是很苦难的!
6.2.4.1 版本要求
- 推荐版本6.x,最低4.x版本,可以通过如下命令查看版本:
redis-server -v
![]()
- 插件安装,网上大部分推荐v1.1.1,文章写的时候v2.2.6已经是release版本了,用户自己选择,地址全在下面(2.2.6官网介绍说是1.0版本的维护版本,如果不想使用新的功能,无需升级!)
v1.1.1
https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
v2.2.6
https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
6.2.4.2 安装&编译
以下安装全部在指定目录下完成,可以选择一个合适的统一目录进行软件安装和管理。
6.2.4.2.1 下载插件压缩包
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
6.2.4.2.2 解压
tar -zxvf v2.2.6.tar.gz
6.2.4.2.3 编译插件
- cd RedisBloom-2.2.6/
- make
编译成功后看到redisbloom.so文件即可
6.2.4.3 Redis集成
6.2.4.3.1 Redis配置文件修改
- 在redis.conf配置文件中加入如RedisBloom的redisbloom.so文件的地址
- 如果是集群则每个配置文件中都需要加入redisbloom.so文件的地址
- 添加完成后需要重启redis
loadmodule /usr/local/soft/RedisBloom-2.2.6/redisbloom.so
redis.conf配置文件中预置了loadmodule的配置项,我们可以直接在这里修改,后续修改会更加方便。

保存退出后一定要记得重启Redis!
保存退出后一定要记得重启Redis!
保存退出后一定要记得重启Redis!
6.2.4.3.2 测试是否成功
Redis集成布隆过滤器的主要指令如下:
- bf.add 添加一个元素
- bf.exists 判断一个元素是否存在
- bf.madd 添加多个元素
- bf.mexists 判断多个元素是否存在
连接客户端进行测试,如果指令有效则证明集成成功

如果出现如下情况(error) ERR unknown command ,可以通过如下方法检查:
- SHUTDOWN Redis实例,再重启实例,再次测试
- 检查配置文件是否配置redisbloom.so文件地址正确
- 检查Redis的版本是否过低

6.2.5.1 bf.add
bf.add表示添加单个元素,添加成功返回1
- 127.0.0.1:6379> bf.add name liziba
- (integer) 1
![]()
6.2.5.2 bf.madd
bf.madd表示添加多个元素
- 127.0.0.1:6379> bf.madd name liziqi lizijiu lizishi
- 1) (integer) 1
- 2) (integer) 1
- 3) (integer) 1

6.2.5.3 bf.exists
bf.exists表示判断元素是否存在,存在则返回1,不存在返回0
- 127.0.0.1:6379> bf.mexists name liziba
- 1) (integer) 1
![]()
6.2.5.3 bf.mexists
bf.mexists表示判断多个元素是否存在,存在的返回1,不存在的返回0
- 127.0.0.1:6379> bf.mexists name liziqi lizijiu liziliu
- 1) (integer) 1
- 2) (integer) 1
- 3) (integer) 0

使用布隆过滤器的方式有很多,还有很多大佬自己手写的,我这里使用的是谷歌guava包中实现的布隆过滤器,这种方式的布隆过滤器是在本地内存中实现。
6.2.6.1 引入pom依赖
- <dependency>
- <groupId>com.google.guava</groupId>
- <artifactId>guava</artifactId>
- <version>29.0-jre</version>
- </dependency>
6.2.6.2 编写测试代码
- package com.lizba.bf;
- import com.google.common.hash.BloomFilter;
- import com.google.common.hash.Funnels;
- /**
- * <p>
- * 布隆过滤器测试代码
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/8/29 14:51
- */
- public class BloomFilterTest {
- /** 预计插入的数据 */
- private static Integer expectedInsertions = 10000000;
- /** 误判率 */
- private static Double fpp = 0.01;
- /** 布隆过滤器 */
- private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
- public static void main(String[] args) {
- // 插入 1千万数据
- for (int i = 0; i < expectedInsertions; i++) {
- bloomFilter.put(i);
- }
- // 用1千万数据测试误判率
- int count = 0;
- for (int i = expectedInsertions; i < expectedInsertions *2; i++) {
- if (bloomFilter.mightContain(i)) {
- count++;
- }
- }
- System.out.println("一共误判了:" + count);
- }
- }
6.2.6.3 测试结果
误判了100075次,大概是expectedInsertions(1千万)的0.01,这与我们设置的 fpp = 0.01非常接近。
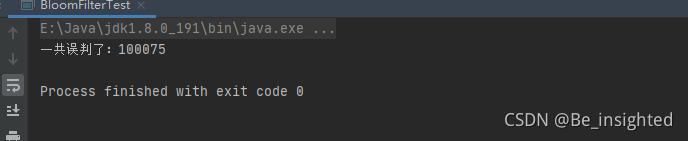
6.2.6.4 参数说明
在guava包中的BloomFilter源码中,构造一个BloomFilter对象有四个参数:
- Funnel funnel:数据类型,由Funnels类指定即可
- long expectedInsertions:预期插入的值的数量
- fpp:错误率
- BloomFilter.Strategy:hash算法
6.2.6.5 fpp&expectedInsertions
- 当expectedInsertions=10000000&&fpp=0.01时,位数组的大小numBits=95850583,hash函数的个数numHashFunctions=7
- 当expectedInsertions=10000000&&fpp=0.03时,位数组的大小numBits=72984408,hash函数的个数numHashFunctions=5
- 当expectedInsertions=100000&&fpp=0.03时,位数组的大小numBits=729844,hash函数的个数numHashFunctions=5
综上三次测试可以得出如下结论:
- 当预计插入的值的数量不变时,偏差值fpp越小,位数组越大,hash函数的个数越多
- 当偏差值不变时,预计插入的中的数量越大,位数组越大,hash函数并没有变化(注意这个结论只是在guava实现的布隆过滤器中的算法符合,并不是说所有的算法都是这个结论,我做了多次测试,确实numHashFunctions在fpp相同时,是不变的!)
Redis经常会被问道缓存击穿问题,比较优秀的解决办法是使用布隆过滤器,也有使用空对象解决的,但是最好的办法肯定是布隆过滤器,我们可以通过布隆过滤器来判断元素是否存在,避免缓存和数据库都不存在的数据进行查询访问!在如下的代码中只要通过bloomFilter.contains(xxx)即可,我这里演示的还是误判率!
6.2.7.1 引入pom依赖
- <dependency>
- <groupId>org.redisson</groupId>
- <artifactId>redisson-spring-boot-starter</artifactId>
- <version>3.16.0</version>
- </dependency>
6.2.7.2 编写测试代码
- package com.lizba.bf;
- import org.redisson.Redisson;
- import org.redisson.api.RBloomFilter;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.Config;
- /**
- * <p>
- * Java集成Redis使用布隆过滤器防止缓存穿透方案
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/8/29 16:13
- */
- public class RedisBloomFilterTest {
- /** 预计插入的数据 */
- private static Integer expectedInsertions = 10000;
- /** 误判率 */
- private static Double fpp = 0.01;
- public static void main(String[] args) {
- // Redis连接配置,无密码
- Config config = new Config();
- config.useSingleServer().setAddress("redis://192.168.211.108:6379");
- // config.useSingleServer().setPassword("123456");
- // 初始化布隆过滤器
- RedissonClient client = Redisson.create(config);
- RBloomFilter<Object> bloomFilter = client.getBloomFilter("user");
- bloomFilter.tryInit(expectedInsertions, fpp);
- // 布隆过滤器增加元素
- for (Integer i = 0; i < expectedInsertions; i++) {
- bloomFilter.add(i);
- }
- // 统计元素
- int count = 0;
- for (int i = expectedInsertions; i < expectedInsertions*2; i++) {
- if (bloomFilter.contains(i)) {
- count++;
- }
- }
- System.out.println("误判次数" + count);
- }
- }
6.2.7.3 测试结果

Redis的数据结构均可以通过EXPIRE key seconds 的方式设置key的过期时间(TTL)。我们也习惯的认为Redis的key过期时间到了,就会自动删除,显然这种想法并不正确。Redis的设计考虑到性能/内存等综合因素,设计了一套过期策略。
Redis key过期删除有两种方式
- 主动删除
- 被动删除
当key被访问的时候,先校验key是否过期,如果过期了则主动删除。
Redis服务器定时随机的测试key的过期时间,如果过期了则被动删除。被动删除的存在必不可少,因为存在一些过期且永久不在访问的key,如果都依赖主动删除,那么它们将会永久占用内存。
Redis为了保证提供高性能服务,被动删除过期的key,采用了贪心策略/概率算法,默认每隔10秒扫描一次,具体策略如下:
- 从过期字典(设置了过期时间的key的集合)中随机选择20个key,检查其是否过期
- 删除其中已经过期的key
- 如果删除的过期key数量大于25%,则重复步骤1
开发在设计Redis缓存架构时,一定要注意要尽可能的避免(禁止)将大量的key设置为同一过期时间,因为结合2.2被动删除可知,Redis被动删除过期key时,会导致服务短暂的不可用;如果存在大量key同时过期,这会导致被动删除key的三个步骤循环多次,从而导致Redis服务出现卡顿情况,这种情况在大型流量项目是无法接收的。
因此为了避免这种情况出现,一定要将一些允许过期时间不需要非常精确的key,设置较为随机的过期时间,这样就可以将卡顿时间缩小。
在主从模式下,Redis是AP架构,它具有高可用性,但是无法保证主从节点的强一致性。在Redis主从架构中,从节点不会直接发生数据的写入,过期key删除也不会在从节点直接发生,它只能被动地依靠主从同步来完成这一步骤。
当主节点中key到期时,会在AOF文件中增加DEL指令,在这个指令未同步到从节点这段时间内,从节点中的key仍然是未删除的。只有当指令同步过来之后,从节点才会删除这个key。通常情况下,这并不带来什么太大的问题,但是确实存在主从数据不一致的情况。
Redis是基于内存存储的key-value数据库,我们知道内存虽然快但空间小,当物理内存达到上限时,系统就会跑的很慢,这是因为swap机制会将部分内存的数据转移到swap分区中,通过与swap的交换保证系统继续运行;但是swap属于硬盘存储,速度远远比不上内存,尤其是对于Redis这种QPS非常高的服务,发生这种情况是无法接收的。(注意如果swap分区内存也满了,系统就会发生错误!)
Linux操作系统可以通过free -m查看swap大小:

因此如何防止Redis发生这种情况非常重要(面试官问到Redis几乎没有不问这个知识点的)。
Redis针对上述问题提供了maxmemory配置,这个配置可以指定Redis存储器的最大数据集,通常情况都是在redis.conf文件中进行配置,也可以运行时使用CONFIG SET命令进行一次性配置。
redis.conf文件中的配置项示意图:
默认情况maxmemory配置项并未启用,Redis官方介绍64位操作系统默认无内存限制,32位操作系统默认3GB隐式内存配置,如果maxmemory 为0,代表内存不受限。
因此我们在做缓存架构时,要根据硬件资源+业务需求做合适的maxmemory配置。
很显然配置了最大内存,当maxmemory达到了最大上限之后Redis不可能不干活了,那么Redis是怎么来处理这个问题的呢?这就是本文的重点,Redis 提供了maxmemory-policy淘汰策略(本文只讲述LRU不涉及LFU,LFU在下一篇文章讲述),对满足条件的key进行删除,辞旧迎新。
maxmemory-policy淘汰策略:
- noeviction:当达到内存限制并且客户端尝试执行可能导致使用更多内存的命令时返回错误,简单来说读操作仍然允许,但是不准写入新的数据,del(删除)请求可以。
- allkeys-lru:从全体key中,通过lru(Least Recently Used - 最近最少使用)算法进行淘汰
- allkeys-random:从全体key中,随机进行淘汰
- volatile-lru:从设置了过期时间的全部key中,通过lru(Least Recently Used - 最近最少使用)算法进行淘汰,这样可以保证未设置过期时间需要被持久化的数据,不会被选中淘汰
- volatile-random:从设置了过期时间的全部key中,随机进行淘汰
- volatile-ttl:从设置了过期时间的全部key中,通过比较key的剩余过期时间TTL的值,TTL越小越先被淘汰
还有volatile-lfu/allkeys-lfu这个留到下文一起探讨,两个算法不一样!
random随机淘汰只需要随机取一些key进行删除,释放内存空间即可;ttl过期时间小先淘汰也可以通过比较ttl的大小,将ttl值小的key进行删除,释放内存空间即可。
那么LRU是怎么实现的呢?Redis又是如何知道哪个key最近被使用了,哪个key最近没有被使用呢?
我们先用Java的容器实现一个简单的LRU算法,我们使用ConcurrentHashMap做key-value结果存储元素的映射关系,使用ConcurrentLinkedDeque来维持key的访问顺序。
LRU实现代码:
- package com.lizba.redis.lru;
- import java.util.Arrays;
- import java.util.List;
- import java.util.concurrent.ConcurrentHashMap;
- import java.util.concurrent.ConcurrentLinkedDeque;
- /**
- * <p>
- * LRU简单实现
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/17 23:47
- */
- public class SimpleLru {
- /** 数据缓存 */
- private ConcurrentHashMap<String, Object> cacheData;
- /** 访问顺序记录 */
- private ConcurrentLinkedDeque<String> sequence;
- /** 缓存容量 */
- private int capacity;
- public SimpleLru(int capacity) {
- this.capacity = capacity;
- cacheData = new ConcurrentHashMap(capacity);
- sequence = new ConcurrentLinkedDeque();
- }
- /**
- * 设置值
- *
- * @param key
- * @param value
- * @return
- */
- public Object setValue(String key, Object value) {
- // 判断是否需要进行LRU淘汰
- this.maxMemoryHandle();
- // 包含则移除元素,新访问的元素一直保存在队列最前面
- if (sequence.contains(key)) {
- sequence.remove();
- }
- sequence.addFirst(key);
- cacheData.put(key, value);
- return value;
- }
- /**
- * 达到最大内存,淘汰最近最少使用的key
- */
- private void maxMemoryHandle() {
- while (sequence.size() >= capacity) {
- String lruKey = sequence.removeLast();
- cacheData.remove(lruKey);
- System.out.println("key: " + lruKey + "被淘汰!");
- }
- }
- /**
- * 获取访问LRU顺序
- *
- * @return
- */
- public List<String> getAll() {
- return Arrays.asList(sequence.toArray(new String[] {}));
- }
- }
测试代码:
- package com.lizba.redis.lru;
- /**
- * <p>
- * 测试最近最少使用
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/18 0:00
- */
- public class TestSimpleLru {
- public static void main(String[] args) {
- SimpleLru lru = new SimpleLru(8);
- for (int i = 0; i < 10; i++) {
- lru.setValue(i+"", i);
- }
- System.out.println(lru.getAll());
- }
- }
测试结果:

从上数的测试结果可以看出,先加入的key0,key1被淘汰了,最后加入的key也是最新的key保存在sequence的队头。
通过这种方案,可以很简单的实现LRU算法;但缺点也十分明显,方案需要使用额外的数据结构来保存key的访问顺序,这样会使Redis内存消耗增加,本身用来优化内存的方案,却要消耗不少内存,显然是不行的。
针对这种情况,Redis使用了近似LRU算法,并不是完完全全准确的淘汰掉最近最不经常使用的key,但是总体的准确度也可以得到保证。
近似LRU算法非常简单,在Redis的key对象中,增加24bit用于存储最近一次访问的系统时间戳,当客户端对Redis服务端发送key的写入相关请求时,发现内存达到maxmemory,此时触发惰性删除;Redis服务通过随机采样,选择5个满足条件的key(注意这个随机采样allkeys-lru是从所有的key中随机采样,volatile-lru是从设置了过期时间的所有key中随机采样),通过key对象中记录的最近访问时间戳进行比较,淘汰掉这5个key中最旧的key;如果内存仍然不够,就继续重复这个步骤。
注意,5是Redis默认的随机采样数值大小,它可以通过redis.conf中的maxmemory_samples进行配置:

针对上述的随机LRU算法,Redis官方给出了一张测试准确性的数据图:
- 最上层浅灰色表示被淘汰的key,图一是标准的LRU算法淘汰的示意图
- 中间深灰色层表示未被淘汰的旧key
- 最下层浅绿色表示最近被访问的key

在Redis 3.0 maxmemory_samples设置为10的时候,Redis的近似LRU算法已经非常的接近真实LRU算法了,但是显然maxmemory_samples设置为10比maxmemory_samples 设置为5要更加消耗CPU计算时间,因为每次采样的样本数据增大,计算时间也会增加。
Redis3.0的LRU比Redis2.8的LRU算法更加准确,是因为Redis3.0增加了一个与maxmemory_samples相同大小的淘汰池,每次淘汰key的时候,先与淘汰池中等待被淘汰的key进行比较,最后淘汰掉最老旧的key,其实就是被选中淘汰的key放到一起再比较一下,淘汰其中最旧的。
LRU算法看似比较好用,但是也存在不合理的地方,比如A和B两个key,在发生淘汰时的前一个小时前同一时刻添加到Redis,A在前49分钟被访问了1000次,但是后11分钟没有被访问;B在这一个小时内仅仅第59分钟被访问了1次;此时如果使用LRU算法,如果A、B均被Redis采样选中,A将会被淘汰很显然这个是不合理的。
针对这种情况Redis 4.0添加了LFU算法,(Least frequently used) 最不经常使用,这种算法比LRU更加合理,下文将会一起学习中淘汰算法,如有需要请关注我的专栏。
 https://liziba.blog.csdn.net/article/details/120445829
https://liziba.blog.csdn.net/article/details/1204458298.2 LFU(Least Frequently Used)
LRU有一个明显的缺点,它无法正确的表示一个Key的热度,如果一个key从未被访问过,仅仅发生内存淘汰的前一会儿被用户访问了一下,在LRU算法中这会被认为是一个热key。
例如如下图,keyA与keyB同时被set到Redis中,在内存淘汰发生之前,keyA被频繁的访问,而keyB只被访问了一次,但是这次访问的时间比keyA的任意一次访问时间都更接近内存淘汰触发的时间,如果keyA与keyB均被Redis选中进行淘汰,keyA将被优先淘汰。我想大家都不太希望keyA被淘汰吧,那么有没有更好的的内存淘汰机制呢?当然有,那就是LFU。
LFU(Least Frequently Used)是Redis 4.0 引入的淘汰算法,它通过key的访问频率比较来淘汰key,重点突出的是Frequently Used。
LRU与LFU的区别:
- LRU -> Recently Used,根据最近一次访问的时间比较
- LFU -> Frequently Used,根据key的访问频率比较
Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式(LRU请看我上一篇文章):
- volatile-lfu:对有过期时间的key采用LFU淘汰算法
- allkeys-lfu:对全部key采用LFU淘汰算法
Redis分配一个字符串的最小空间占用是19字节,16字节(对象头)+3字节(SDS基本字段)。Redis的内存淘汰算法LRU/LFU均依靠其中的对象头中的lru来实现。
Redis对象头的内存结构:
- typedef struct redisObject {
- unsigned type:4; // 4 bits 对象的类型(zset、set、hash等)
- unsigned encoding:4; // 4 bits 对象的存储方式(ziplist、intset等)
- unsigned lru:24; // 24bits 记录对象的访问信息
- int refcount; // 4 bytes 引用计数
- void *ptr; // 8 bytes (64位操作系统),指向对象具体的存储地址/对象body
- }
Redis对象头中的lru字段,在LRU模式下和LFU模式下使用方式并不相同。
8.2.2.1 LRU实现方式
在LRU模式,lru字段存储的是key被访问时Redis的时钟server.lrulock(Redis为了保证核心单线程服务性能,缓存了Unix操作系统时钟,默认每毫秒更新一次,缓存的值是Unix时间戳取模2^24)。当key被访问的时候,Redis会更新这个key的对象头中lru字段的值。
因此在LRU模式下,Redis可以根据对象头中的lru字段记录的值,来比较最后一次key的访问时间。
用Java代码演示一个简单的Redis-LRU算法:
- Redis对象头
- package com.lizba.redis.lru;
- /**
- * <p>
- * Redis对象头
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/22 22:40
- */
- public class RedisHead {
- /** 时间 */
- private Long lru;
- /** 具体数据 */
- private Object body;
- public RedisHead setLru(Long lru) {
- this.lru = lru;
- return this;
- }
- public RedisHead setBody(Object body) {
- this.body = body;
- return this;
- }
- public Long getLru() {
- return lru;
- }
- public Object getBody() {
- return body;
- }
- }
- Redis LRU实现代码
- package com.lizba.redis.lru;
- import java.util.Comparator;
- import java.util.List;
- import java.util.concurrent.ConcurrentHashMap;
- import java.util.stream.Collectors;
- /**
- * <p>
- * Redis中LRU算法的实现demo
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/22 22:36
- */
- public class RedisLruDemo {
- /**
- * 缓存容器
- */
- private ConcurrentHashMap<String, RedisHead> cache;
- /**
- * 初始化大小
- */
- private int initialCapacity;
- public RedisLruDemo(int initialCapacity) {
- this.initialCapacity = initialCapacity;
- this.cache = new ConcurrentHashMap<>(initialCapacity);
- ;
- }
- /**
- * 设置key/value 设置的时候更新LRU
- *
- * @param key
- * @param body
- */
- public void set(String key, Object body) {
- // 触发LRU淘汰
- synchronized (RedisLruDemo.class) {
- if (!cache.containsKey(key) && cache.size() >= initialCapacity) {
- this.flushLruKey();
- }
- }
- RedisHead obj = this.getRedisHead().setBody(body).setLru(System.currentTimeMillis());
- cache.put(key, obj);
- }
- /**
- * 获取key,存在则更新LRU
- *
- * @param key
- * @return
- */
- public Object get(String key) {
- RedisHead result = null;
- if (cache.containsKey(key)) {
- result = cache.get(key);
- result.setLru(System.currentTimeMillis());
- }
- return result;
- }
- /**
- * 清除LRU key
- */
- private void flushLruKey() {
- List<String> sortData = cache.keySet()
- .stream()
- .sorted(Comparator.comparing(key -> cache.get(key).getLru()))
- .collect(Collectors.toList());
- String removeKey = sortData.get(0);
- System.out.println( "淘汰 -> " + "lru : " + cache.get(removeKey).getLru() + " body : " + cache.get(removeKey).getBody());
- cache.remove(removeKey);
- if (cache.size() >= initialCapacity) {
- this.flushLruKey();
- }
- return;
- }
- /**
- * 获取所有数据测试用
- *
- * @return
- */
- public List<RedisHead> getAll() {
- return cache.keySet().stream().map(key -> cache.get(key)).collect(Collectors.toList());
- }
- private RedisHead getRedisHead() {
- return new RedisHead();
- }
- }
- 测试代码
- package com.lizba.redis.lru;
- import java.util.Random;
- import java.util.concurrent.TimeUnit;
- /**
- * <p>
- * 测试LRU
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/22 22:51
- */
- public class TestRedisLruDemo {
- public static void main(String[] args) throws InterruptedException {
- RedisLruDemo demo = new RedisLruDemo(10);
- // 先加入10个key,此时cache达到容量,下次加入会淘汰key
- for (int i = 0; i < 10; i++) {
- demo.set(i + "", i);
- }
- // 随机访问前十个key,这样可以保证下次加入时随机淘汰
- for (int i = 0; i < 20; i++) {
- int nextInt = new Random().nextInt(10);
- TimeUnit.SECONDS.sleep(1);
- demo.get(nextInt + "");
- }
- // 再次添加5个key,此时每次添加都会触发淘汰
- for (int i = 10; i < 15; i++) {
- demo.set(i + "", i);
- }
- System.out.println("-------------------------------------------");
- demo.getAll().forEach( redisHead -> System.out.println("剩余 -> " + "lru : " + redisHead.getLru() + " body : " + redisHead.getBody()));
- }
- }
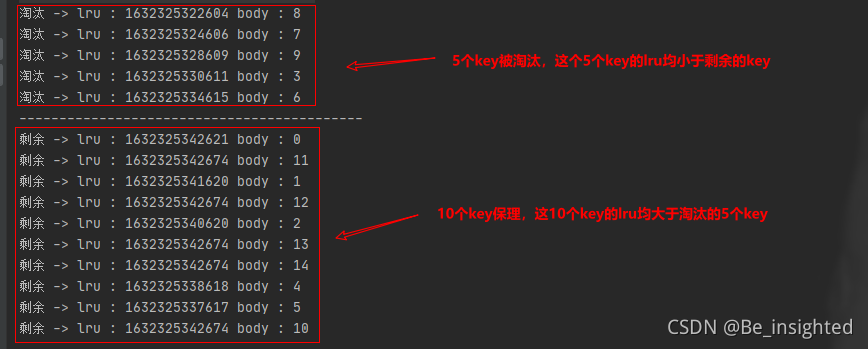
8.2.2.2 LFU实现方式
在LFU模式下,Redis对象头的24bit lru字段被分成两段来存储,高16bit存储ldt(Last Decrement Time),低8bit存储logc(Logistic Counter)。
**8.2.2.2.1 ldt(Last Decrement Time) **
高16bit用来记录最近一次计数器降低的时间,由于只有8bit,存储的是Unix分钟时间戳取模2^16,16bit能表示的最大值为65535(65535/24/60≈45.5),大概45.5天会折返(折返指的是取模后的值重新从0开始)。
Last Decrement Time计算的算法源码:
- /* Return the current time in minutes, just taking the least significant
- * 16 bits. The returned time is suitable to be stored as LDT (last decrement
- * time) for the LFU implementation. */
- // server.unixtime是Redis缓存的Unix时间戳
- // 可以看出使用的Unix的分钟时间戳,取模2^16
- unsigned long LFUGetTimeInMinutes(void) {
- return (server.unixtime/60) & 65535;
- }
- /* Given an object last access time, compute the minimum number of minutes
- * that elapsed since the last access. Handle overflow (ldt greater than
- * the current 16 bits minutes time) considering the time as wrapping
- * exactly once. */
- unsigned long LFUTimeElapsed(unsigned long ldt) {
- // 获取系统当前的LFU time
- unsigned long now = LFUGetTimeInMinutes();
- // 如果now >= ldt 直接取差值
- if (now >= ldt) return now-ldt;
- // 如果now < ldt 增加上65535
- // 注意Redis 认为折返就只有一次折返,多次折返也是一次,我思考了很久感觉这个应该是可以接受的,本身Redis的淘汰算法就带有随机性
- return 65535-ldt+now;
- }
8.2.2.2.2 logc(Logistic Counter)
低8位用来记录访问频次,8bit能表示的最大值为255,logc肯定无法记录真实的Rediskey的访问次数,其实从名字可以看出存储的是访问次数的对数值,每个新加入的key的logc初始值为5(LFU_INITI_VAL),这样可以保证新加入的值不会被首先选中淘汰;logc每次key被访问时都会更新;此外,logc会随着时间衰减。
8.2.2.2.3 logc 算法调整
redis.conf 提供了两个配置项,用于调整LFU的算法从而控制Logistic Counter的增长和衰减。
- lfu-log-factor 用于调整Logistic Counter的增长速度,lfu-log-factor值越大,Logistic Counter增长越慢。
Redis Logistic Counter增长的源代码:
- /* Logarithmically increment a counter. The greater is the current counter value
- * the less likely is that it gets really implemented. Saturate it at 255. */
- uint8_t LFULogIncr(uint8_t counter) {
- // Logistic Counter最大值为255
- if (counter == 255) return 255;
- // 取一个0~1的随机数r
- double r = (double)rand()/RAND_MAX;
- // counter减去LFU_INIT_VAL (LFU_INIT_VAL为每个key的Logistic Counter初始值,默认为5)
- double baseval = counter - LFU_INIT_VAL;
- // 如果衰减之后已经小于5了,那么baseval < 0取0
- if (baseval < 0) baseval = 0;
- // lfu-log-factor在这里被使用
- // 可以看出如果lfu_log_factor的值越大,p越小
- // r < p的概率就越小,Logistic Counter增加的概率就越小(因此lfu_log_factor越大增长越缓慢)
- double p = 1.0/(baseval*server.lfu_log_factor+1);
- if (r < p) counter++;
- return counter;
- }
如下是官网提供lfu-log-factor在不同值下,key随着访问次数的增加的Logistic Counter变化情况的数据:
- lfu-decay-time 用于调整Logistic Counter的衰减速度,它是一个以分钟为单位的数值,默认值为1,;lfu-decay-time值越大,衰减越慢。
Redis Logistic Counter衰减的源代码:
- /* If the object decrement time is reached decrement the LFU counter but
- * do not update LFU fields of the object, we update the access time
- * and counter in an explicit way when the object is really accessed.
- * And we will times halve the counter according to the times of
- * elapsed time than server.lfu_decay_time.
- * Return the object frequency counter.
- *
- * This function is used in order to scan the dataset for the best object
- * to fit: as we check for the candidate, we incrementally decrement the
- * counter of the scanned objects if needed. */
- unsigned long LFUDecrAndReturn(robj *o) {
- // 获取lru的高16位,也就是ldt
- unsigned long ldt = o->lru >> 8;
- // 获取lru的低8位,也就是logc
- unsigned long counter = o->lru & 255;
- // 根据配置的lfu-decay-time计算Logistic Counter需要衰减的值
- unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
- if (num_periods)
- counter = (num_periods > counter) ? 0 : counter - num_periods;
- return counter;
- }
8.2.2.2.4 LFU 优化
LFU 与 LRU 有一个共同点,当内存达到max_memory时,选择key是随机抓取的,因此Redis为了使这种随机性更加准确,设计了一个淘汰池,这个淘汰池对于LFU和LRU算的都适应,只是淘汰池的排序算法有区别而已。
Redis 3.0就对这一块进行了优化(来自redis.io):

8.2.3.1 配置文件开启LFU淘汰算法
修改redis.conf配置文件,设置maxmemory-policy volatile-lfu/allkeys-lfu
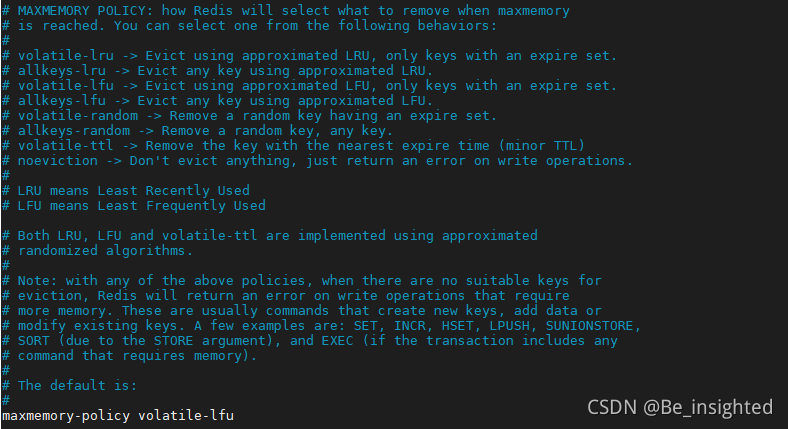
重启Redis,连接客户端通过info指令查看maxmemory_policy的配置信息
![]()
通过object freq key 获取对象的LFU的Logistic Counter值
限定用户的某个行为在指定时间T内,只允许发生N次。假设T为1秒钟,N为1000次。
程序员设计了一个在每分钟内只允许访问1000次的限流方案,如下图01:00s-02:00s之间只允许访问1000次,这种设计最大的问题在于,请求可能在01:59s-02:00s之间被请求1000次,02:00s-02:01s之间被请求了1000次,这种情况下01:59s-02:01s间隔0.02s之间被请求2000次,很显然这种设计是错误的。
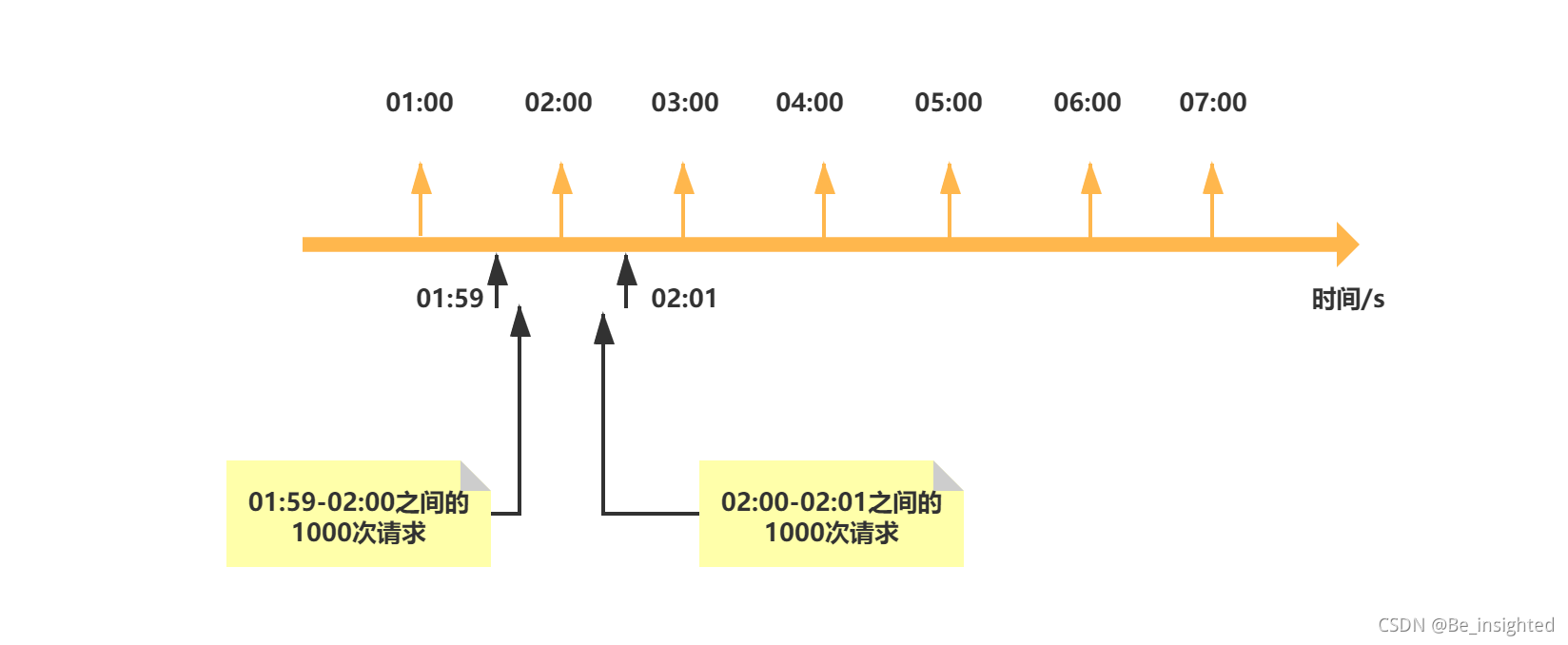
9.1.3.1 解决方案
指定时间T内,只允许发生N次。我们可以将这个指定时间T,看成一个滑动时间窗口(定宽)。我们采用Redis的zset基本数据类型的score来圈出这个滑动时间窗口。在实际操作zset的过程中,我们只需要保留在这个滑动时间窗口以内的数据,其他的数据不处理即可。
- 每个用户的行为采用一个zset存储,score为毫秒时间戳,value也使用毫秒时间戳(比UUID更加节省内存)
- 只保留滑动窗口时间内的行为记录,如果zset为空,则移除zset,不再占用内存(节省内存)
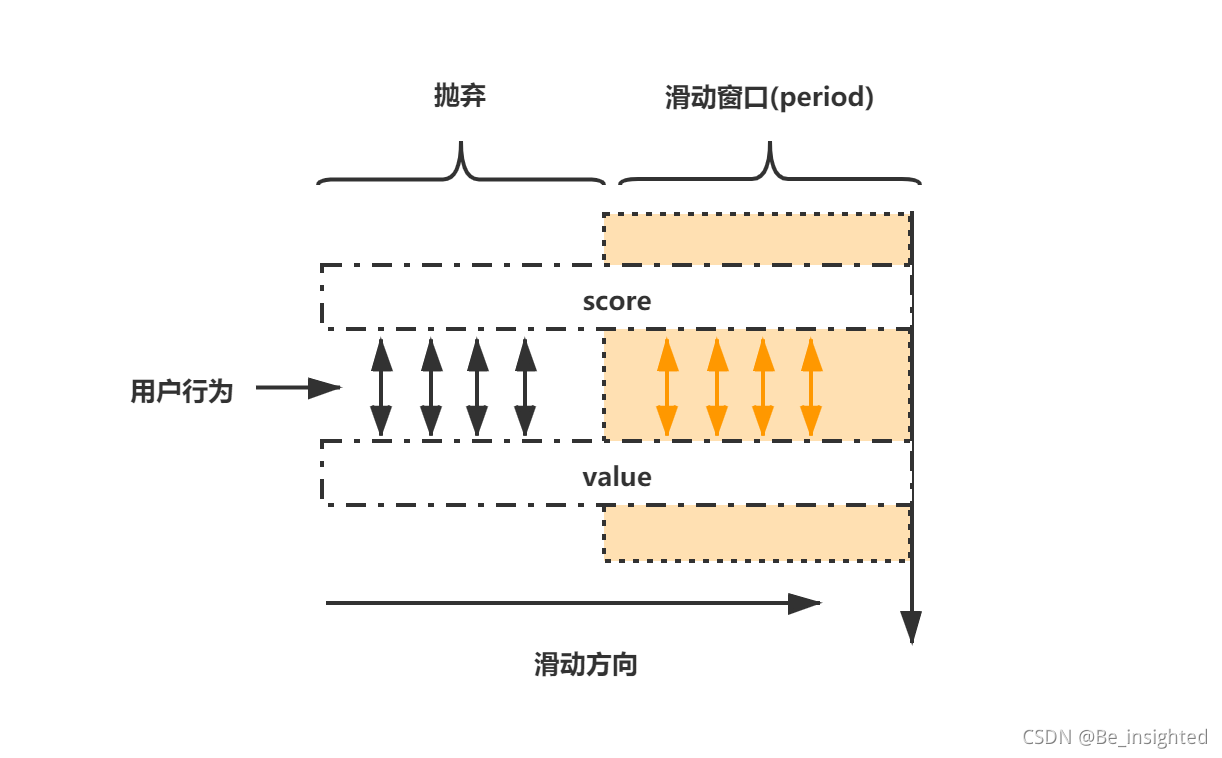
9.1.3.2 pipeline代码实现
代码的实现的逻辑是统计滑动窗口内zset中的行为数量,并且与阈值maxCount直接进行比较就可以判断当前行为是否被允许。这里涉及多个redis操作,因此使用pipeline可以大大提升效率
- package com.lizba.redis.limit;
- import redis.clients.jedis.Jedis;
- import redis.clients.jedis.Pipeline;
- import redis.clients.jedis.Response;
- /**
- * <p>
- * 通过zset实现滑动窗口算法限流
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/6 18:11
- */
- public class SimpleSlidingWindowByZSet {
- private Jedis jedis;
- public SimpleSlidingWindowByZSet(Jedis jedis) {
- this.jedis = jedis;
- }
- /**
- * 判断行为是否被允许
- *
- * @param userId 用户id
- * @param actionKey 行为key
- * @param period 限流周期
- * @param maxCount 最大请求次数(滑动窗口大小)
- * @return
- */
- public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
- String key = this.key(userId, actionKey);
- long ts = System.currentTimeMillis();
- Pipeline pipe = jedis.pipelined();
- pipe.multi();
- pipe.zadd(key, ts, String.valueOf(ts));
- // 移除滑动窗口之外的数据
- pipe.zremrangeByScore(key, 0, ts - (period * 1000));
- Response<Long> count = pipe.zcard(key);
- // 设置行为的过期时间,如果数据为冷数据,zset将会删除以此节省内存空间
- pipe.expire(key, period);
- pipe.exec();
- pipe.close();
- return count.get() <= maxCount;
- }
- /**
- * 限流key
- *
- * @param userId
- * @param actionKey
- * @return
- */
- public String key(String userId, String actionKey) {
- return String.format("limit:%s:%s", userId, actionKey);
- }
- }
测试代码:
- package com.lizba.redis.limit;
- import redis.clients.jedis.Jedis;
- /**
- *
- * @Author: Liziba
- * @Date: 2021/9/6 20:10
- */
- public class TestSimpleSlidingWindowByZSet {
- public static void main(String[] args) {
- Jedis jedis = new Jedis("192.168.211.108", 6379);
- SimpleSlidingWindowByZSet slidingWindow = new SimpleSlidingWindowByZSet(jedis);
- for (int i = 1; i <= 15; i++) {
- boolean actionAllowed = slidingWindow.isActionAllowed("liziba", "view", 60, 5);
- System.out.println("第" + i +"次操作" + (actionAllowed ? "成功" : "失败"));
- }
- jedis.close();
- }
- }
测试效果:
从测试输出的数据可以看出,起到了限流的效果,从第11次以后的请求操作都是失败的,但是这个和我们允许的5次误差还是比较大的。这个问题的原因是我们测试System.currentTimeMillis()的毫秒可能相同,而且此时value也是System.currentTimeMillis()也相同,会导致zset中元素覆盖!
修改代码测试:
在循环中睡眠1毫秒即可,测试结果符合预期!
TimeUnit.MILLISECONDS.sleep(1);

9.1.3.3 lua代码实现
我们在项目中使用原子性的lua脚步来实现限流的使用会更多,因此这里也提供一个基于操作zset的lua版本
- package com.lizba.redis.limit;
- import com.google.common.collect.ImmutableList;
- import redis.clients.jedis.Jedis;
- import redis.clients.jedis.Pipeline;
- import redis.clients.jedis.Response;
- /**
- * <p>
- * 通过zset实现滑动窗口算法限流
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/6 18:11
- */
- public class SimpleSlidingWindowByZSet {
- private Jedis jedis;
- public SimpleSlidingWindowByZSet(Jedis jedis) {
- this.jedis = jedis;
- }
- /**
- * lua脚本限流
- *
- * @param userId
- * @param actionKey
- * @param period
- * @param maxCount
- * @return
- */
- public boolean isActionAllowedByLua(String userId, String actionKey, int period, int maxCount) {
- String luaScript = this.buildLuaScript();
- String key = key(userId, actionKey);
- long ts = System.currentTimeMillis();
- System.out.println(ts);
- ImmutableList<String> keys = ImmutableList.of(key);
- ImmutableList<String> args = ImmutableList.of(String.valueOf(ts),String.valueOf((ts - period * 1000)), String.valueOf(period));
- Number count = (Number) jedis.eval(luaScript, keys, args);
- return count != null && count.intValue() <= maxCount;
- }
- /**
- * 限流key
- *
- * @param userId
- * @param actionKey
- * @return
- */
- private String key(String userId, String actionKey) {
- return String.format("limit:%s:%s", userId, actionKey);
- }
- /**
- * 针对某个key使用lua脚本限流
- *
- * @return
- */
- private String buildLuaScript() {
- return "redis.call('ZADD', KEYS[1], tonumber(ARGV[1]), ARGV[1])" +
- "\nlocal c" +
- "\nc = redis.call('ZCARD', KEYS[1])" +
- "\nredis.call('ZREMRANGEBYSCORE', KEYS[1], 0, tonumber(ARGV[2]))" +
- "\nredis.call('EXPIRE', KEYS[1], tonumber(ARGV[3]))" +
- "\nreturn c;";
- }
- }
测试代码不变,大家可以自行测试,记得还是要考虑我们测试的时候System.currentTimeMillis()相等的问题,不信你输出System.currentTimeMillis()就知道了!多思考问题,技术其实都在心里!
限定用户的某个行为在指定时间T内,只允许发生N次。假设T为1秒钟,N为1000次。
程序员设计了一个在每分钟内只允许访问1000次的限流方案,如下图01:00s-02:00s之间只允许访问1000次,这种设计最大的问题在于,请求可能在01:59s-02:00s之间被请求1000次,02:00s-02:01s之间被请求了1000次,这种情况下01:59s-02:01s间隔0.02s之间被请求2000次,很显然这种设计是错误的。
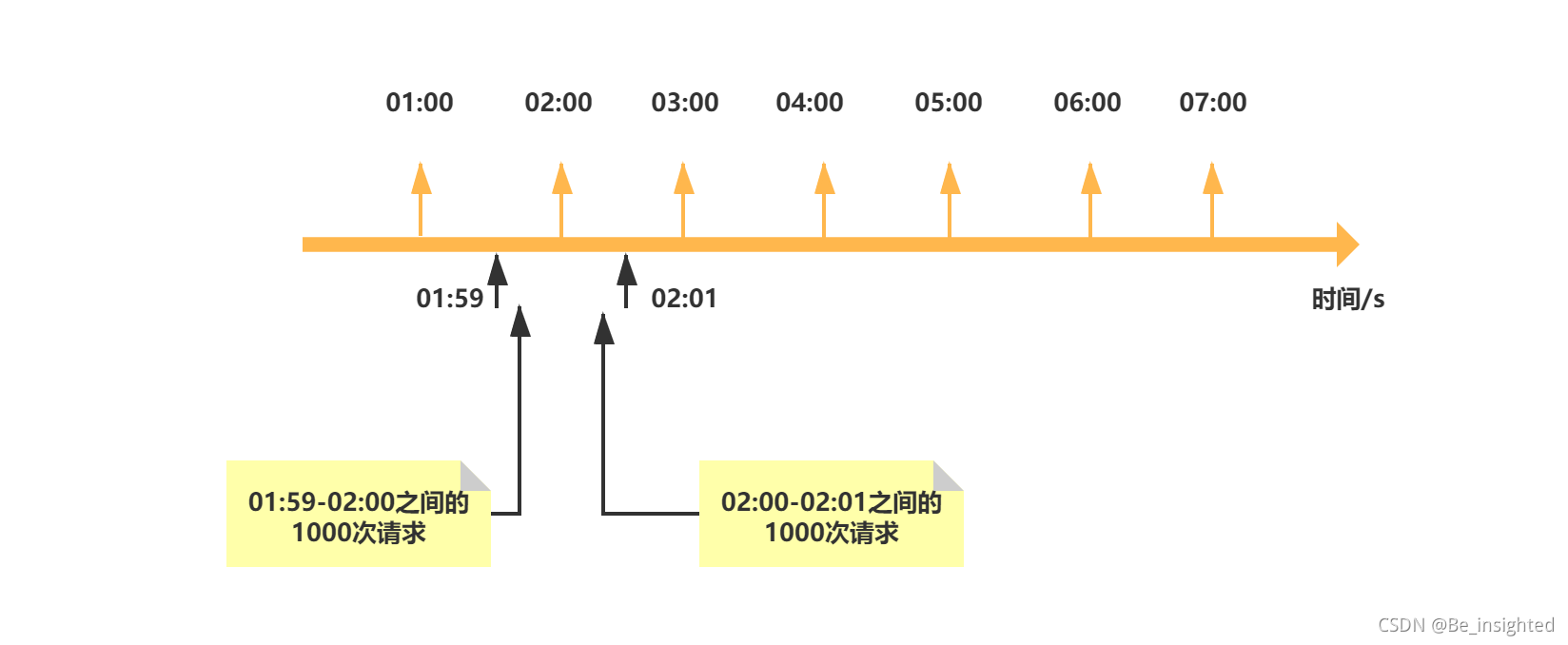
9.2.3.1 解决方案
漏斗容量有限,当流水的的速度小于灌水的速度,漏斗就会水满溢出,利用这个原理我们可以设计限流代码!漏斗的剩余的空间就代表着当前行为(请求)可以持续进行的数量,漏斗的流水速率代表系统允许行为(请求)发生的最大频率,通常安装系统的处理能力权衡后进行设值。
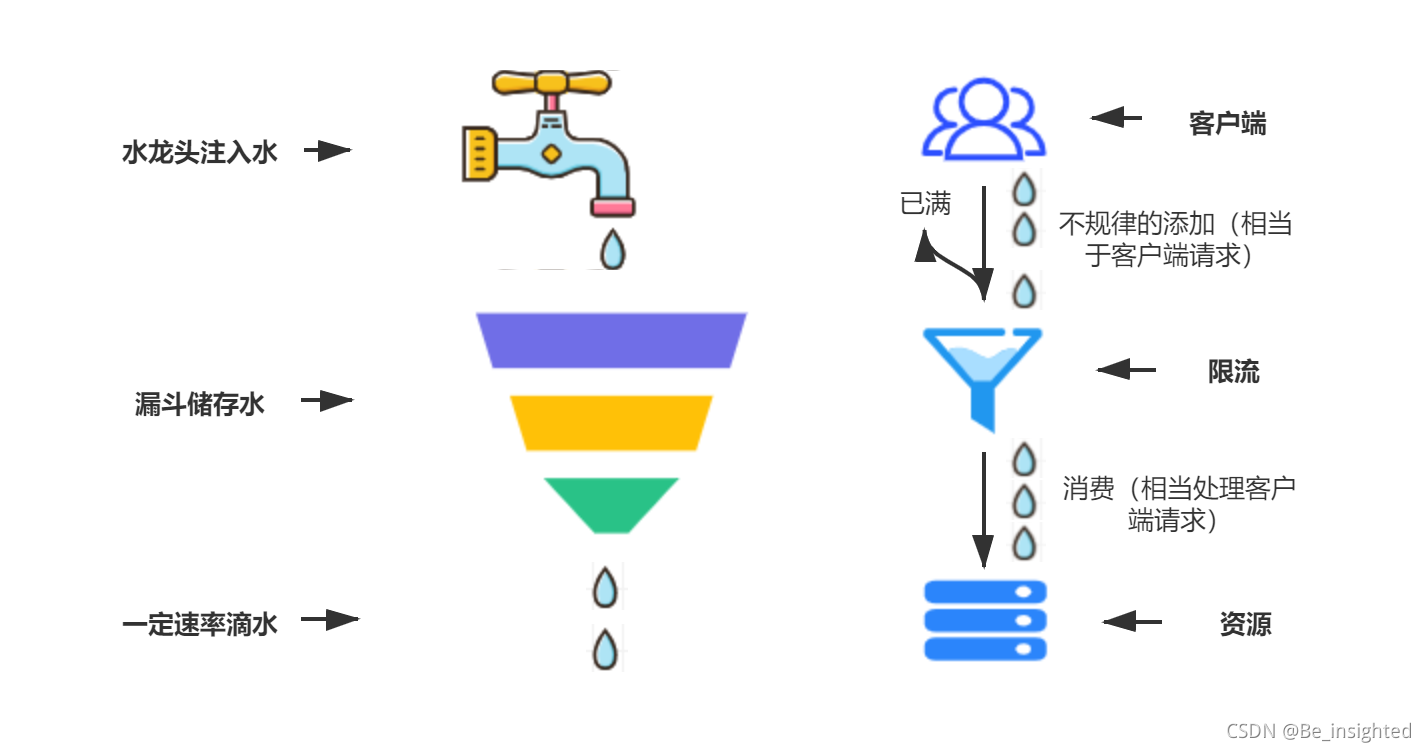
9.2.3.2 Java代码实现
- package com.lizba.redis.limit;
- import java.util.Map;
- import java.util.concurrent.ConcurrentHashMap;
- /**
- * <p>
- * 漏斗限流
- * </p>
- *
- * @Author: Liziba
- */
- public class FunnelRateLimiter {
- /** map用于存储多个漏斗 */
- private Map<String, Funnel> funnels = new ConcurrentHashMap<>();
- /**
- * 请求(行为)是否被允许
- *
- * @param userId 用户id
- * @param actionKey 行为key
- * @param capacity 漏斗容量
- * @param leakingRate 剩余容量
- * @param quota 请求次数
- * @return
- */
- public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate, int quota) {
- String key = String.format("%s:%s", userId, actionKey);
- Funnel funnel = funnels.get(key);
- if (funnel == null) {
- funnel = new Funnel(capacity, leakingRate);
- funnels.put(key, funnel);
- }
- return funnel.waterLeaking(quota);
- }
- /**
- * 漏斗类
- */
- class Funnel {
- /** 漏斗容量 */
- int capacity;
- /** 漏斗流速,每毫秒允许的流速(请求) */
- float leakingRate;
- /** 漏斗剩余空间 */
- int leftCapacity;
- /** 上次漏水时间 */
- long leakingTs;
- public Funnel(int capacity, float leakingRate) {
- this.capacity = this.leftCapacity = capacity;
- this.leakingRate = leakingRate;
- leakingTs = System.currentTimeMillis();
- }
- /**
- * 计算剩余空间
- */
- void makeSpace() {
- long nowTs = System.currentTimeMillis();
- long intervalTs = nowTs - leakingTs;
- int intervalCapacity = (int) (intervalTs * leakingRate);
- // int 溢出
- if (intervalCapacity < 0) {
- this.leftCapacity = this.capacity;
- this.leakingTs = nowTs;
- return;
- }
- // 腾出空间 >= 1
- if (intervalCapacity < 1) {
- return;
- }
- // 增加漏斗剩余容量
- this.leftCapacity += intervalCapacity;
- this.leakingTs = nowTs;
- // 容量不允许超出漏斗容量
- if (this.leftCapacity > this.capacity) {
- this.leftCapacity = this.capacity;
- }
- }
- /**
- * 漏斗流水
- *
- * @param quota 流水量
- * @return
- */
- boolean waterLeaking(int quota) {
- // 触发漏斗流水
- this.makeSpace();
- if (this.leftCapacity >= quota) {
- leftCapacity -= quota;
- return true;
- }
- return false;
- }
- }
- }
测试代码:
计算机运行如下的代码速度会非常的块,我通过TimeUnit.SECONDS.sleep(2);模拟客户端过一段时间后再请求。
设置漏斗容量为10,每毫秒允许0.002次请求(2 次/秒),每次请求数量为1;
- package com.lizba.redis.limit;
- import java.util.concurrent.TimeUnit;
- /**
- * @Author: Liziba
- */
- public class TestFunnelRateLimit {
- public static void main(String[] args) throws InterruptedException {
- FunnelRateLimiter limiter = new FunnelRateLimiter();
- for (int i = 1; i <= 20; i++) {
- if (i == 15) {
- TimeUnit.SECONDS.sleep(2);
- }
- // 设置漏斗容量为10,每毫秒允许0.002次请求(2 次/秒),每次请求数量为1
- boolean success = limiter.isActionAllowed("Liziba", "commit", 10, 0.002f, 1);
- System.out.println("第" + i + "请求" + (success ? "成功" : "失败"));
- }
- }
- }
测试结果:
- 01-10次请求成功,初始漏斗大小为10,因此前10次请求成功
- 11-14次请求失败,由于漏斗已满,并且漏斗的流速在这四次请求之间未能释放1
- 15-18次请求成功,因为i == 15时主线程睡眠2秒,2秒时间漏斗流出 0.00210002 = 4,因此这四次请求成功
- 19-20次请求失败,与11-14次请求失败的原因一致
9.2.3.3 结合Redis实现
我们采用hash结构,将Funnel的属性字段,放入hash中,并且在代码中进行运算即可
- package com.lizba.redis.limit;
- import redis.clients.jedis.Jedis;
- import java.util.HashMap;
- import java.util.Map;
- /**
- * <p>
- * redis hash 漏斗限流
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/7 23:46
- */
- public class FunnelRateLimiterByHash {
- private Jedis client;
- public FunnelRateLimiterByHash(Jedis client) {
- this.client = client;
- }
- /**
- * 请求是否成功
- *
- * @param userId
- * @param actionKey
- * @param capacity
- * @param leakingRate
- * @param quota
- * @return
- */
- public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate, int quota) {
- String key = this.key(userId, actionKey);
- long nowTs = System.currentTimeMillis();
- Map<String, String> funnelMap = client.hgetAll(key);
- if (funnelMap == null || funnelMap.isEmpty()) {
- return initFunnel(key, nowTs, capacity, quota);
- }
- long intervalTs = nowTs - Long.parseLong(funnelMap.get("leakingTs"));
- int intervalCapacity = (int) (intervalTs * leakingRate);
- // 时间过长, int可能溢出
- if (intervalCapacity < 0) {
- intervalCapacity = 0;
- initFunnel(key, nowTs, capacity, quota);
- }
- // 腾出空间必须 >= 1
- if (intervalCapacity < 1) {
- intervalCapacity = 0;
- }
- int leftCapacity = Integer.parseInt(funnelMap.get("leftCapacity")) + intervalCapacity;
- if (leftCapacity > capacity) {
- leftCapacity = capacity;
- }
- return initFunnel(key, nowTs, leftCapacity, quota);
- }
- /**
- * 存入redis,初始funnel
- *
- * @param key
- * @param nowTs
- * @param capacity
- * @param quota
- * @return
- */
- private boolean initFunnel(String key,long nowTs, int capacity, int quota) {
- Map<String, String> funnelMap = new HashMap<>();
- funnelMap.put("leftCapacity", String.valueOf((capacity > quota) ? (capacity - quota) : 0));
- funnelMap.put("leakingTs", String.valueOf(nowTs));
- client.hset(key, funnelMap);
- return capacity >= quota;
- }
- /**
- * 限流key
- *
- * @param userId
- * @param actionKey
- * @return
- */
- private String key(String userId, String actionKey) {
- return String.format("limit:%s:%s", userId, actionKey);
- }
- }
测试代码:
- package com.lizba.redis.limit;
- import redis.clients.jedis.Jedis;
- import java.util.concurrent.TimeUnit;
- /**
- * @Author: Liziba
- */
- public class TestFunnelRateLimiterByHash {
- public static void main(String[] args) throws InterruptedException {
- Jedis jedis = new Jedis("192.168.211.108", 6379);
- FunnelRateLimiterByHash limiter = new FunnelRateLimiterByHash(jedis);
- for (int i = 1; i <= 20; i++) {
- if (i == 15) {
- TimeUnit.SECONDS.sleep(2);
- }
- boolean success = limiter.isActionAllowed("liziba", "view", 10, 0.002f, 1);
- System.out.println("第" + i + "请求" + (success ? "成功" : "失败"));
- }
- jedis.close();
- }
- }
测试结果:
与上面的java代码结构一致
上述说了两种实现漏斗限流的方式,其实思想都是一样的,但是这两者都无法在分布式环境中使用,即便是在单机环境中也是不准确的,存在线程安全问题/原子性问题,因此我们一般使用Redis提供的限流模块Redis-Cell来限流,Redis-Cell提供了原子的限流指令cl.throttle,这个留到后续在详细说吧,我要睡觉去了!
令牌桶算法比较简单,它就好比摇号买房,拿到号的人才有资格买,没拿到号的就只能等下次了(还好小编不需摇号,因为买不起!)。
在实际的开发中,系统会维护一个容器用于存放令牌(token),并且系统以一个固定速率往容器中添加令牌(token),这个速率通常更加系统的处理能力来权衡。当客户端的请求打过来时,需要从令牌桶中获取到令牌(token)之后,这个请求才会被处理,否则直接拒绝服务。
令牌桶限流的关键在于发放令牌的速率和令牌桶的容量。
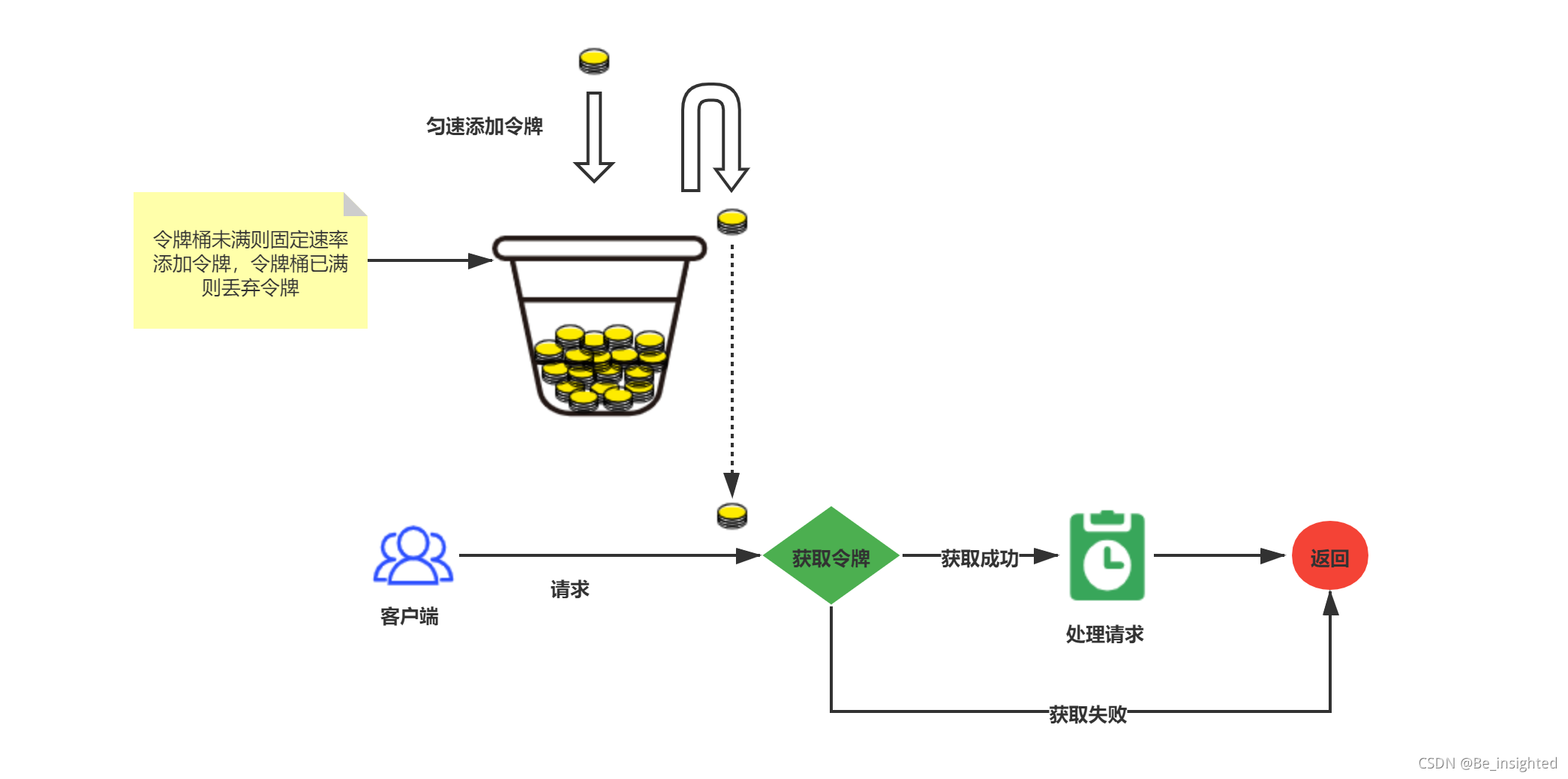
实现令牌桶限流的方式有很多种,本文讲述的是基于Redis的Redis-Cell限流模块,这是Redis提供的适用于分布式系统、高效、准确的限流方式,使用十分广泛,而且非常简单!
Redis默认是没有集成Redis-Cell这个限流模块的,就好比Redis使用布隆过滤器一样,我们也需要对该模块进行安装与集成。
9.3.2.1 GitHub源码&安装包
Redis-Cell的GitHub地址:
Redis-Cell基于Rust语言开发,如果不想花费精力去搞Rust环境,那么可以直接下载与你的操作系统对应的安装包(这个很关键,我就安装了挺多次的,如果安装的问题比较多的话,也建议降低一个release版本!)
下载对应的安装包:
如果不清楚自己的服务器(Linux)版本的,可以事先查看后再下载安装包:
- # Linux 查看当前操作系统的内核信息
- uname -a
- # 查看当前操作系统系统的版本信息
- cat /proc/version

9.3.2.2 安装&异常处理
- 在Redis的安装目录的同级目录下,新建文件夹Redis-Cell,将压缩包上传后解压
tar -zxvf redis-cell-v0.2.5-powerpc64-unknown-linux-gnu.tar.gz
- 解压后出现如下文件,复制libredis_cell.so文件的路径
- (pwd查看当前路径))

- 修改Redis配置文件,redis.conf,添加完成后记得保存后再退出

- 重启Redis,如果启动正常,进入redis客户端,通过module list查看挂载的模块是否有Redis-Cell

- 测试指令,出现如下情况说明集成Redis-Cell成功

- 如果重启Redis后,客户端无法连接成功,说明Redis启动失败,这个时候我们需要查看Redis的启动日志,如果已经配置日志文件的可以直接查看日志定位问题,如果还未配置日志文件的需要先配置日志文件,redis.conf添加日志文件路径地址,再次重启,查看日志文件输出的错误日志
- 错误可能千奇百怪,问题不大搞技术就不要心急,一个个解决,我这里记录下我最后遇到的问题,/lib64/libc.so.6: version 'GLIBC_2.18' not found
- 43767:M 08 Sep 2021 21:39:39.643 # Module /usr/local/soft/Redis-Cell-0.3.0/libredis_cell.so failed to load: /lib64/libc.so.6: version `GLIBC_2.18' not found (required by /usr/local/soft/Redis-Cell-0.3.0/libredis_cell.so)
- 43767:M 08 Sep 2021 21:39:39.643 # Can't load module from /usr/local/soft/Redis-Cell-0.3.0/libredis_cell.so: server aborting
- 缺失GLIBC_2.18,那就安装它(最后两个编译的过程时间比较长,耐心等待几分钟)
- yum install gcc
- wget http://ftp.gnu.org/gnu/glibc/glibc-2.18.tar.gz
- tar zxf glibc-2.18.tar.gz
- cd glibc-2.18/
- mkdir build
- cd build/
- ../configure --prefix=/usr
- make -j4
- make install
- 安装完成后,重启Redis,测试是否安装成功,循环上面的过程,通过日志分析错误即可
指令CL.THROTTLE参数含义
- CL.THROTTLE liziba 10 5 60 1
- ▲ ▲ ▲ ▲ ▲
- | | | | └───── apply 1 token (default if omitted) (本次申请一个token)
- | | └──┴─────── 5 tokens / 60 seconds (60秒添加5个token到令牌桶中)
- | └───────────── 10 max_burst (最大的突发请求,不是令牌桶的最大容量)
- └─────────────────── key "liziba" (限流key)
输出参数值含义
- 127.0.0.1:6379> cl.throttle liziba 10 5 60 1
- 1) (integer) 0 # 当前请求是否被允许,0表示允许,1表示不允许
- 2) (integer) 11 # 令牌桶的最大容量,令牌桶中令牌数的最大值
- 3) (integer) 10 # 令牌桶中当前的令牌数
- 4) (integer) -1 # 如果被拒绝,需要多长时间后在重试,如果当前被允许则为-1
- 5) (integer) 12 # 多长时间后令牌桶中的令牌会满
这里唯一有歧义的可能是max_burst,这个并不是令牌桶的最大容量,从作者的README.md中的解释也可以看出来
The total limit of the key (max_burst + 1). This is equivalent to the common X-RateLimit-Limit HTTP header.

9.3.4.1 导入依赖
- <dependency>
- <groupId>io.lettuce</groupId>
- <artifactId>lettuce-core</artifactId>
- <version>5.3.4.RELEASE</version>
- <!--排除 netty 包冲突-->
- <exclusions>
- <exclusion>
- <groupId>io.netty</groupId>
- <artifactId>netty-buffer</artifactId>
- </exclusion>
- <exclusion>
- <groupId>io.netty</groupId>
- <artifactId>netty-common</artifactId>
- </exclusion>
- <exclusion>
- <groupId>io.netty</groupId>
- <artifactId>netty-codec</artifactId>
- </exclusion>
- <exclusion>
- <groupId>io.netty</groupId>
- <artifactId>netty-transport</artifactId>
- </exclusion>
- </exclusions>
- </dependency>
9.3.4.2 实现代码
Redis命令接口定义:
- package com.lizba.redis.limit.tokenbucket;
- import io.lettuce.core.dynamic.Commands;
- import io.lettuce.core.dynamic.annotation.Command;
- import java.util.List;
- /**
- * <p>
- * Redis命令接口定义
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/8 23:50
- */
- public interface IRedisCommand extends Commands {
- /**
- * 定义限流方法
- *
- * @param key 限流key
- * @param maxBurst 最大的突发请求,桶容量等于maxBurst + 1
- * @param tokens tokens 与 seconds 是组合参数,表示seconds秒内添加个tokens
- * @param seconds tokens 与 seconds 是组合参数,表示seconds秒内添加个tokens
- * @param apply 当前申请的token数
- * @return
- */
- @Command("CL.THROTTLE ?0 ?1 ?2 ?3 ?4")
- List<Object> throttle(String key, long maxBurst, long tokens, long seconds, long apply);
- }
Redis-Cell令牌桶限流类定义:
- package com.lizba.redis.limit.tokenbucket;
- import io.lettuce.core.RedisClient;
- import io.lettuce.core.api.StatefulRedisConnection;
- import io.lettuce.core.dynamic.RedisCommandFactory;
- import java.util.List;
- /**
- * <p>
- * Redis-Cell令牌桶限流
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/8 23:47
- */
- public class TokenBucketRateLimiter {
- private static final String SUCCESS = "0";
- private RedisClient client;
- private StatefulRedisConnection<String, String> connection;
- private IRedisCommand command;
- public TokenBucketRateLimiter(RedisClient client) {
- this.client = client;
- this.connection = client.connect();
- this.command = new RedisCommandFactory(connection).getCommands(IRedisCommand.class);
- }
- /**
- * 请是否被允许
- *
- * @param key
- * @param maxBurst
- * @param tokens
- * @param seconds
- * @param apply
- * @return
- */
- public boolean isActionAllowed(String key, long maxBurst, long tokens, long seconds, long apply) {
- List<Object> result = command.throttle(key, maxBurst, tokens, seconds, apply);
- if (result != null && result.size() > 0) {
- return SUCCESS.equals(result.get(0).toString());
- }
- return false;
- }
- }
测试代码:
- package com.lizba.redis.limit.tokenbucket;
- import io.lettuce.core.RedisClient;
- /**
- * <p>
- * 测试令牌桶限流
- * 测试参数 cl.throttle liziba 10 5 60 1
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/9/9 0:02
- */
- public class TestTokenBucketRateLimiter {
- public static void main(String[] args) {
- RedisClient client = RedisClient.create("redis://192.168.211.108:6379");
- TokenBucketRateLimiter limiter = new TokenBucketRateLimiter(client);
- // cl.throttle liziba 10 5 60 1
- for (int i = 1; i <= 15; i++) {
- boolean success = limiter.isActionAllowed("liziba", 10, 5, 60, 1);
- System.out.println("第" + i + "次请求" + (success ? "成功" : "失败"));
- }
- }
- }
测试结果(这里也说明了令牌桶的容量是max_burst + 1):
- 第0次请求成功
- 第1次请求成功
- 第2次请求成功
- 第3次请求成功
- 第4次请求成功
- 第5次请求成功
- 第6次请求成功
- 第7次请求成功
- 第8次请求成功
- 第9次请求成功
- 第10次请求成功
- 第11次请求成功
- 第14次请求失败
- 第15次请求失败
- 第14次请求失败
- 第15次请求失败
Redis提供了info指令,它会返回关于Redis服务器的各种信息和统计数值。在使用Redis时,时常会遇到一些疑难杂症需要我们去排查,这个时候我们可以通过info指令来获取Redis的运行状态,然后进行问题的排查。
通过给定可选的参数 section ,可以让命令只返回某一部分的信息:
- server: Redis服务器的一般信息
- clients: 客户端的连接部分
- memory: 内存消耗相关信息
- persistence: RDB和AOF相关信息
- stats: 一般统计
- replication: 主/从复制信息
- cpu: 统计CPU的消耗
- commandstats: Redis命令统计
- cluster: Redis集群信息
- keyspace: 数据库的相关统计
它也可以采取以下值:
- all: 返回所有信息
- default: 值返回默认设置的信息
如果没有使用任何参数时,默认为default,返回所有的信息。
返回Redis服务所有的信息
- # Server
- redis_version:6.2.4
- redis_git_sha1:00000000
- redis_git_dirty:0
- redis_build_id:fa652e749408dcfd
- redis_mode:standalone
- os:Linux 3.10.0-327.el7.x86_64 x86_64
- arch_bits:64
- multiplexing_api:epoll
- atomicvar_api:c11-builtin
- gcc_version:9.3.1
- process_id:4617
- process_supervised:no
- run_id:9662797d01b55345cd6cabad38d102e27db19e66
- tcp_port:6379
- server_time_usec:1632494557942546
- uptime_in_seconds:4
- uptime_in_days:0
- hz:10
- configured_hz:10
- lru_clock:5104605
- executable:/usr/local/soft/redis-6.2.4/src/redis-server
- config_file:/usr/local/soft/redis-6.2.4/redis.conf
- io_threads_active:0
- # Clients
- connected_clients:1
- cluster_connections:0
- maxclients:10000
- client_recent_max_input_buffer:16
- client_recent_max_output_buffer:0
- blocked_clients:0
- tracking_clients:0
- clients_in_timeout_table:0
- # Memory
- used_memory:874728
- used_memory_human:854.23K
- used_memory_rss:10207232
- used_memory_rss_human:9.73M
- used_memory_peak:932800
- used_memory_peak_human:910.94K
- used_memory_peak_perc:93.77%
- used_memory_overhead:830808
- used_memory_startup:810168
- used_memory_dataset:43920
- used_memory_dataset_perc:68.03%
- allocator_allocated:1036080
- allocator_active:1380352
- allocator_resident:3932160
- total_system_memory:1913507840
- total_system_memory_human:1.78G
- used_memory_lua:37888
- used_memory_lua_human:37.00K
- used_memory_scripts:0
- used_memory_scripts_human:0B
- number_of_cached_scripts:0
- maxmemory:104857600
- maxmemory_human:100.00M
- maxmemory_policy:volatile-lfu
- allocator_frag_ratio:1.33
- allocator_frag_bytes:344272
- allocator_rss_ratio:2.85
- allocator_rss_bytes:2551808
- rss_overhead_ratio:2.60
- rss_overhead_bytes:6275072
- mem_fragmentation_ratio:12.27
- mem_fragmentation_bytes:9375272
- mem_not_counted_for_evict:0
- mem_replication_backlog:0
- mem_clients_slaves:0
- mem_clients_normal:20496
- mem_aof_buffer:0
- mem_allocator:jemalloc-5.1.0
- active_defrag_running:0
- lazyfree_pending_objects:0
- lazyfreed_objects:0
- # Persistence
- loading:0
- current_cow_size:0
- current_cow_size_age:0
- current_fork_perc:0.00
- current_save_keys_processed:0
- current_save_keys_total:0
- rdb_changes_since_last_save:0
- rdb_bgsave_in_progress:0
- rdb_last_save_time:1632494553
- rdb_last_bgsave_status:ok
- rdb_last_bgsave_time_sec:-1
- rdb_current_bgsave_time_sec:-1
- rdb_last_cow_size:0
- aof_enabled:0
- aof_rewrite_in_progress:0
- aof_rewrite_scheduled:0
- aof_last_rewrite_time_sec:-1
- aof_current_rewrite_time_sec:-1
- aof_last_bgrewrite_status:ok
- aof_last_write_status:ok
- aof_last_cow_size:0
- module_fork_in_progress:0
- module_fork_last_cow_size:0
- # Stats
- total_connections_received:1
- total_commands_processed:1
- instantaneous_ops_per_sec:0
- total_net_input_bytes:31
- total_net_output_bytes:20324
- instantaneous_input_kbps:0.00
- instantaneous_output_kbps:0.00
- rejected_connections:0
- sync_full:0
- sync_partial_ok:0
- sync_partial_err:0
- expired_keys:0
- expired_stale_perc:0.00
- expired_time_cap_reached_count:0
- expire_cycle_cpu_milliseconds:0
- evicted_keys:0
- keyspace_hits:0
- keyspace_misses:0
- pubsub_channels:0
- pubsub_patterns:0
- latest_fork_usec:0
- total_forks:0
- migrate_cached_sockets:0
- slave_expires_tracked_keys:0
- active_defrag_hits:0
- active_defrag_misses:0
- active_defrag_key_hits:0
- active_defrag_key_misses:0
- tracking_total_keys:0
- tracking_total_items:0
- tracking_total_prefixes:0
- unexpected_error_replies:0
- total_error_replies:0
- dump_payload_sanitizations:0
- total_reads_processed:2
- total_writes_processed:1
- io_threaded_reads_processed:0
- io_threaded_writes_processed:0
- # Replication
- role:master
- connected_slaves:0
- master_failover_state:no-failover
- master_replid:5b43385d46f4a601c025cb2c4ce5706b0b77db86
- master_replid2:0000000000000000000000000000000000000000
- master_repl_offset:0
- second_repl_offset:-1
- repl_backlog_active:0
- repl_backlog_size:1048576
- repl_backlog_first_byte_offset:0
- repl_backlog_histlen:0
- # CPU
- used_cpu_sys:0.030666
- used_cpu_user:0.000000
- used_cpu_sys_children:0.000000
- used_cpu_user_children:0.000000
- used_cpu_sys_main_thread:0.030570
- used_cpu_user_main_thread:0.000000
- # Modules
- # Errorstats
- # Cluster
- cluster_enabled:0
- # Keyspace
- db0:keys=2,expires=0,avg_ttl=0
下面是所有 server 相关的信息
| 参数名 | 含义 |
| redis_version | Redis 服务器版本 |
| redis_git_sha1 | Git SHA1 |
| redis_git_dirty | Git dirty flag |
| redis_build_id | 构建ID |
| redis_mode | 服务器模式(standalone,sentinel或者cluster) |
| os | Redis 服务器的宿主操作系统 |
| arch_bits | 架构(32 或 64 位) |
| multiplexing_api | Redis 所使用的事件处理机制 |
| atomicvar_api | Redis使用的Atomicvar API |
| gcc_version | 编译 Redis 时所使用的 GCC 版本 |
| process_id | 服务器进程的 PID |
| run_id | Redis 服务器的随机标识符(用于 Sentinel 和集群) |
| tcp_port | TCP/IP 监听端口 |
| uptime_in_seconds | 自 Redis 服务器启动以来,经过的秒数 |
| uptime_in_days | 自 Redis 服务器启动以来,经过的天数 |
| hz | 服务器的频率设置 |
| lru_clock | 以分钟为单位进行自增的时钟,用于 LRU 管理 |
| executable | 服务器的可执行文件路径 |
| config_file | 配置文件路径 |
下面是所有 clients 相关的信息
| 参数名 | 含义 |
| connected_clients | 已连接客户端的数量(不包括通过从属服务器连接的客户端) |
| client_longest_output_list | 当前连接的客户端当中,最长的输出列表 |
| client_biggest_input_buf | 当前连接的客户端当中,最大输入缓存 |
| blocked_clients | 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量 |

下面是所有 memory 相关的信息
| 参数名 | 含义 |
| used_memory | 由 Redis 分配器分配的内存总量,以字节(byte)为单位 |
| used_memory_human | 以人类可读的格式返回 Redis 分配的内存总量 |
| used_memory_rss | 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。 |
| used_memory_peak | Redis 的内存消耗峰值(以字节为单位) |
| used_memory_peak_human | 以人类可读的格式返回 Redis 的内存消耗峰值 |
| used_memory_peak_perc | 使用内存占峰值内存的百分比 |
| used_memory_overhead | 服务器为管理其内部数据结构而分配的所有开销的总和(以字节为单位) |
| used_memory_startup | Redis在启动时消耗的初始内存大小(以字节为单位) |
| used_memory_dataset | 以字节为单位的数据集大小(used_memory减去used_memory_overhead) |
| used_memory_dataset_perc | used_memory_dataset占净内存使用量的百分比(used_memory减去used_memory_startup) |
| total_system_memory | Redis主机具有的内存总量 |
| total_system_memory_human | 以人类可读的格式返回 Redis主机具有的内存总量 |
| used_memory_lua | Lua 引擎所使用的内存大小(以字节为单位) |
| used_memory_lua_human | 以人类可读的格式返回 Lua 引擎所使用的内存大小 |
| maxmemory | maxmemory配置指令的值 |
| maxmemory_human | 以人类可读的格式返回 maxmemory配置指令的值 |
| maxmemory_policy | maxmemory-policy配置指令的值 |
| mem_fragmentation_ratio | used_memory_rss 和 used_memory 之间的比率 |
| mem_allocator | 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc |
| active_defrag_running | 指示活动碎片整理是否处于活动状态的标志 |
| lazyfree_pending_objects | 等待释放的对象数(由于使用ASYNC选项调用UNLINK或FLUSHDB和FLUSHALL) |
在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过mem_fragmentation_ratio 的值看出。当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。由于Redis无法控制其分配的内存如何映射到内存页,因此常住内存(used_memory_rss)很高通常是内存使用量激增的结果。当 Redis 释放内存时,内存将返回给分配器,分配器可能会,也可能不会,将内存返还给操作系统。如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致。查看 used_memory_peak 的值可以验证这种情况是否发生。
下面是所有 persistence 相关的信息:
| 参数名 | 含义 |
| loading | 指示转储文件(dump)的加载是否正在进行的标志 |
| rdb_changes_since_last_save | 自上次转储以来的更改次数 |
| rdb_bgsave_in_progress | 指示RDB文件是否正在保存的标志 |
| rdb_last_save_time | 上次成功保存RDB的基于纪年的时间戳 |
| rdb_last_bgsave_status | 上次RDB保存操作的状态 |
| rdb_last_bgsave_time_sec | 上次RDB保存操作的持续时间(以秒为单位) |
| rdb_current_bgsave_time_sec | 正在进行的RDB保存操作的持续时间(如果有) |
| rdb_last_cow_size | 上次RDB保存操作期间copy-on-write分配的字节大小 |
| aof_enabled | 表示AOF记录已激活的标志 |
| aof_rewrite_in_progress | 表示AOF重写操作正在进行的标志 |
| aof_rewrite_scheduled | 表示一旦进行中的RDB保存操作完成,就会安排进行AOF重写操作的标志 |
| aof_last_rewrite_time_sec | 上次AOF重写操作的持续时间,以秒为单位 |
| aof_current_rewrite_time_sec | 正在进行的AOF重写操作的持续时间(如果有) |
| aof_last_bgrewrite_status | 上次AOF重写操作的状态 |
| aof_last_write_status | 上一次AOF写入操作的状态 |
| aof_last_cow_size | 上次AOF重写操作期间copy-on-write分配的字节大小 |
changes_since_last_save指的是从上次调用SAVE或者BGSAVE以来,在数据集中产生某种变化的操作的数量。
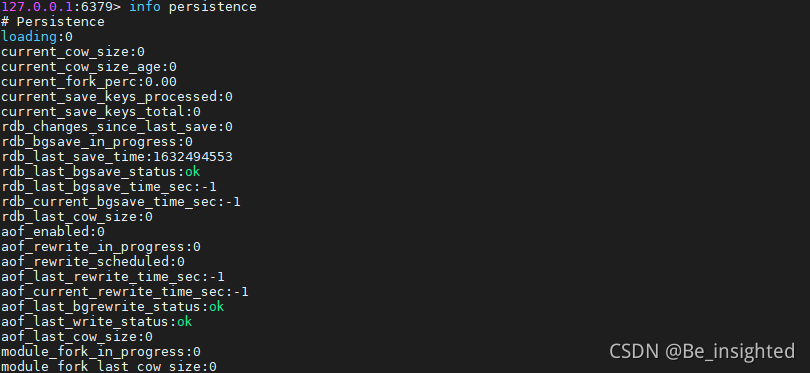
如果启用了AOF,则会添加以下这些额外的字段:
| 参数名 | 含义 |
| aof_current_size | 当前的AOF文件大小 |
| aof_base_size | 上次启动或重写时的AOF文件大小 |
| aof_pending_rewrite | 指示AOF重写操作是否会在当前RDB保存操作完成后立即执行的标志。 |
| aof_buffer_length | AOF缓冲区大小 |
| aof_rewrite_buffer_length | AOF重写缓冲区大小 |
| aof_pending_bio_fsync | 在后台IO队列中等待fsync处理的任务数 |
| aof_delayed_fsync | 延迟fsync计数器 |
如果正在执行加载操作,将会添加这些额外的字段:
| 参数名 | 含义 |
| loading_start_time | 加载操作的开始时间(基于纪元的时间戳) |
| loading_total_bytes | 文件总大小 |
| loading_loaded_bytes | 已经加载的字节数 |
| loading_loaded_perc | 已经加载的百分比 |
| loading_eta_seconds | 预计加载完成所需的剩余秒数 |
下面是所有 stats 相关的信息:
| 参数名 | 含义 |
| total_connections_received | 服务器接受的连接总数 |
| total_commands_processed | 服务器处理的命令总数 |
| instantaneous_ops_per_sec | 每秒处理的命令数 |
| rejected_connections | 由于maxclients限制而拒绝的连接数 |
| expired_keys | key到期事件的总数 |
| evicted_keys | 由于maxmemory限制而导致被驱逐的key的数量 |
| keyspace_hits | 在主字典中成功查找到key的次数 |
| keyspace_misses | 在主字典中查找key失败的次数 |
| pubsub_channels | 拥有客户端订阅的全局pub/sub通道数 |
| pubsub_patterns | 拥有客户端订阅的全局pub/sub模式数 |
| latest_fork_usec | 最新fork操作的持续时间,以微秒为单位 |
下面是所有 replication 相关的信息:
| 参数名 | 含义 |
| role | 如果实例不是任何节点的从节点,则值是”master”,如果实例从某个节点同步数据,则是”slave”。 请注意,一个从节点可以是另一个从节点的主节点(菊花链) |
如果实例是从节点,则会提供以下这些额外字段:
| 参数名 | 含义 |
| master_host | 主节点的Host名称或IP地址 |
| master_port | 主节点监听的TCP端口 |
| master_link_status | 连接状态(up或者down) |
| master_last_io_seconds_ago | 自上次与主节点交互以来,经过的秒数 |
| master_sync_in_progress | 指示主节点正在与从节点同步 |
如果SYNC操作正在进行,则会提供以下这些字段:
| 参数名 | 含义 |
| master_sync_left_bytes | 同步完成前剩余的字节数 |
| master_sync_last_io_seconds_ago | 在SYNC操作期间自上次传输IO以来的秒数 |
如果主从节点之间的连接断开了,则会提供一个额外的字段:
| 参数名 | 含义 |
| master_link_down_since_seconds | 自连接断开以来,经过的秒数 |
以下字段将始终提供:
| 参数名 | 含义 |
| connected_slaves | 已连接的从节点数 |
对每个从节点,将会添加以下行:
slaveXXX id,地址,端口号,状态
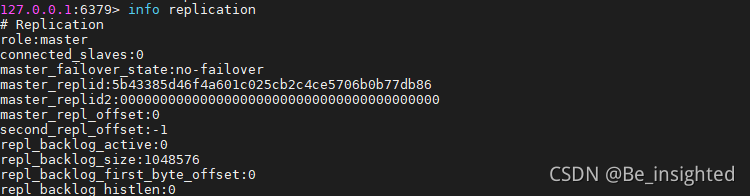
下面是所有 cpu 相关的信息:
| 参数名 | 含义 |
| used_cpu_sys | 由Redis服务器消耗的系统CPU |
| used_cpu_user | 由Redis服务器消耗的用户CPU |
| used_cpu_sys_children | 由后台进程消耗的系统CPU |
| used_cpu_user_children | 由后台进程消耗的用户CPU |

cluster部分当前只包含一个唯一的字段:
| 参数名 | 含义 |
| cluster_enabled | 表示已启用Redis集群 |
![]()
keyspace部分提供有关每个数据库的主字典的统计,统计信息是key的总数和过期的key的总数,对于每个数据库,提供以下行:
| 参数名 | 含义 |
| keyspace | dbXXX keys=XXX,expires=XXX |
![]()
Redis一主二从Sentinel监控配置如下:
- 3个Sentinel实例(奇数个,选择Leader)
- Redis服务(一主二)。
服务器资源有限的朋友们,可以通过VMware启动虚拟机的方式来构建环境,关于如何使用VMware安装虚拟机,网络配置、克隆、单实例Redis的安装在我的博文中都有保姆级教程,需要的请自取。
资源清单:
| IP地址 | 节点角色 | 端口 |
| 192.168.211.104 | Redis Master/ Sentinel | 6379/26379 |
| 192.168.211.105 | Redis Slave/ Sentinel | 6379/26379 |
| 192.168.211.106 | Redis Slave/ Sentinel | 6379/26379 |
关闭防火墙:
由于是自己学习使用,我们不针对专门的端口最策略(在公司这一块有专门的运维同时来做),这里我们直接关闭服务器的防火墙(三台都需要关闭)
- systemctl status firewalld.service # 查看防火墙状态
- systemctl stop firewalld.service # 停止防火墙(重启后会失效)
- systemctl disable firewalld.service # 禁止开机启动
效果图,不会的朋友可以参考一下
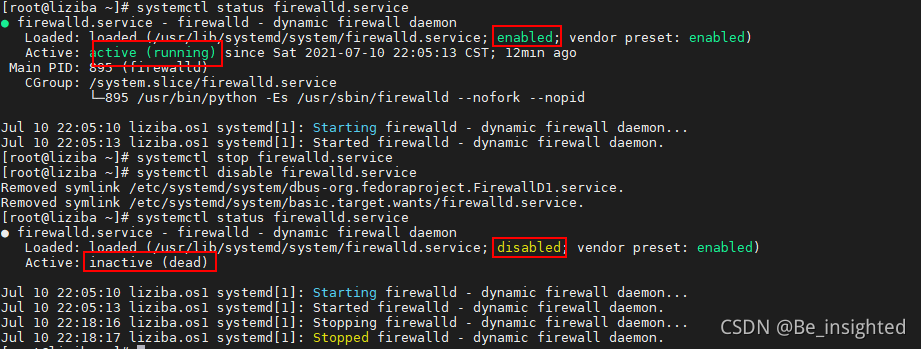
整体架构简图
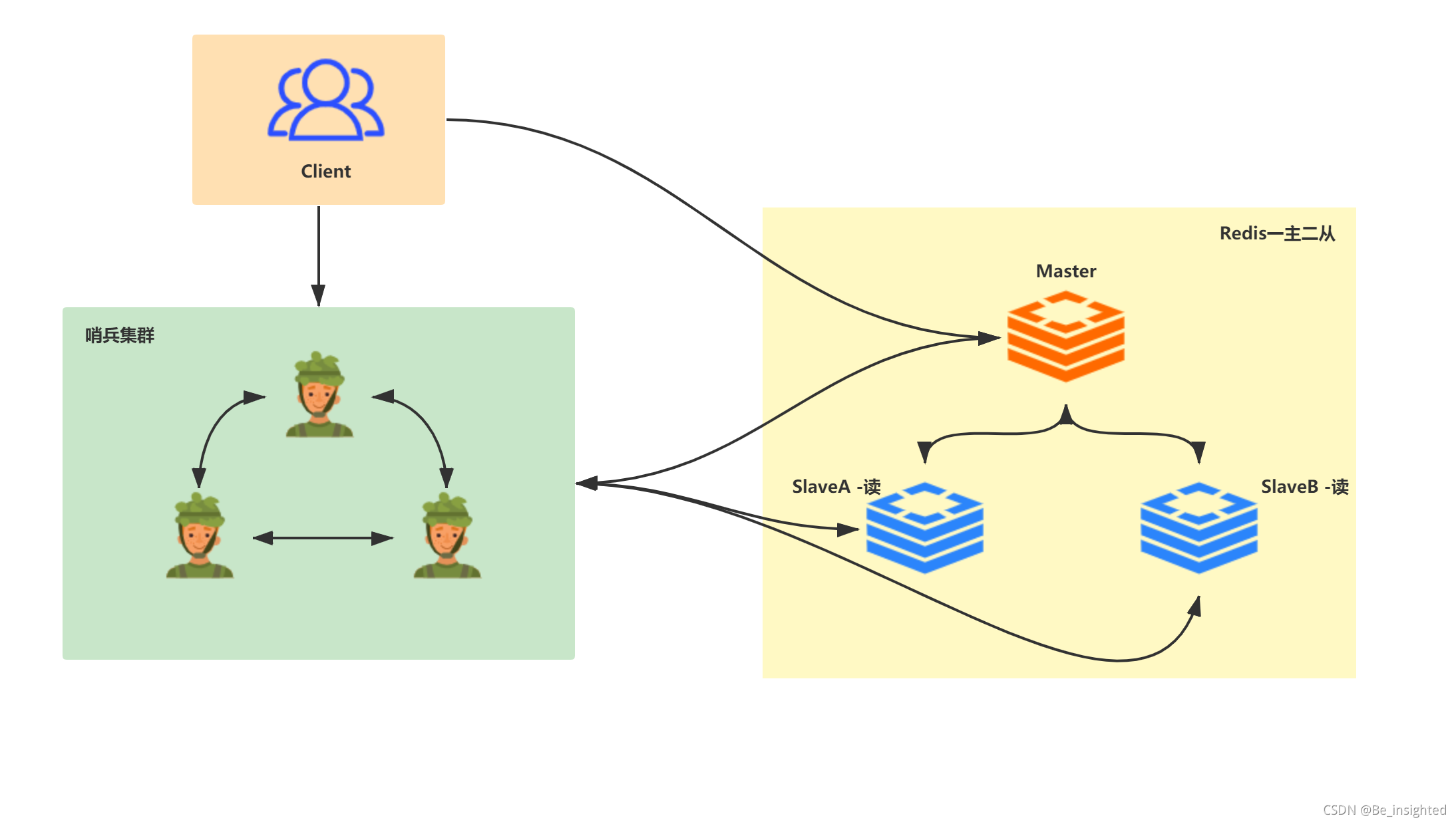
这里的Redis的主节点是192.168.211.104,所以我们在192.168.211.105和192.168.211.106的Redis配置文件中,配置replicaof指向的Master IP +port。
配置文件在Redis的安装目录:
编辑redis.conf配置文件:
vim redis.conf
redis.conf配置文件中默认注释:
# replicaof
取消注销,配置为Master的IP + port:
replicaof 192.168.211.104 6379
单机节点实例下,Redis的安装目录默认有sentinel.conf配置文件,先对文件进行备份,备份文件名为sentinel.conf.copy(自定义):
cp sentinel.conf sentinel.conf.copy
创建日志等相关文件:
cd /usr/local/soft/redis-6.2.4/
mkdir logs
mkdir rdbs
mkdir sentinel-tmp # sentinel的工作目录,下面有说明
三台机器分别修改sentinel.conf的配置文件内容如下(内容都相同):
**daemonize yes **
**port 26379 **
protected-mode no
dir "/usr/local/soft/redis-6.2.4/sentinel-tmp"
sentinel monitor redis-master 192.168.211.104 6379 2
sentinel down-after-milliseconds redis-master 30000
sentinel failover-timeout redis-master 180000
sentinel parallel-syncs redis-master 1
上述配置详细解读:
| 配置项 | 作用 |
| **daemonize ** | 后台启动,与Redis一致,yes表示后台启动 |
| **port ** | 端口 **26379 ** |
| protected-mode | 开启外网访问保护模式,no表示关闭,这样外网可以访问 |
| **dir ** | Sentinel工作目录 |
| sentinel monitor | Sentinel 监控的Redis主节点 |
| sentinel failover-timeout | 1、同一个sentinel对同一个master两次failover之间的间隔时间
2、当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时
3、当想要取消一个正在进行的failover所需要的时间。
4、当进行failover时,配置所有slaves指向新的master所需的最大时间 |
| sentinel parallel-syncs | 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 |
上述就已经完成了Redis一主二从集群和3个Sentinel实例的监控的配置,接下来就是启动Redis和Sentinel
10.2.4.1 启动redis
进入Redis安装目录下的src目录:
cd /usr/local/soft/redis-6.2.4/src
启动Redis服务(也可以配置别名启动,需要的请看我的Redis单机实例安装教程):
./redis-server ../redis.conf
10.2.4.2 启动Sentinel
启动目录与Redis启动目录相同,在Redis安装目录下的src目录
方式一:
./redis-sentinel ../sentinel.conf
方式二:
./redis-server ../sentinel.conf --sentinel
10.2.4.3 查看集群状态
进入Redis客户端,通过info replication查看集群状态:
info replication
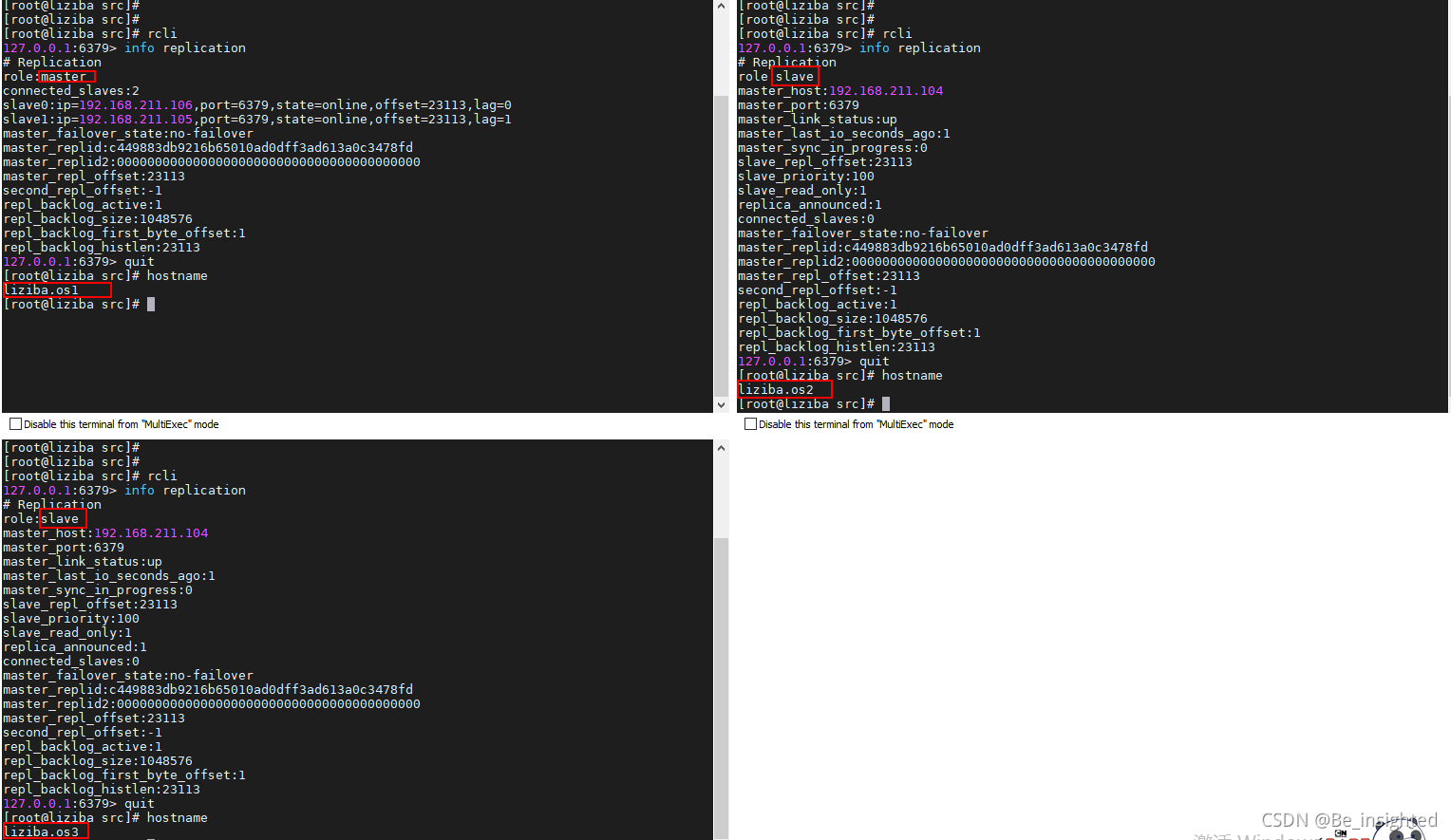
rcli是我配置的别名启动,不懂的请看我的单节点实例部署的博文,或者给我留言我会及时回复的,如上图我们可以看到集群没什么问题,接下来还需要测试Sentinel
通过宕机的方式来测试Sentinel是否有效,我们在主节点192.168.211.104上,连接Redis执行shutdown:
shutdown

此时我们的192.168.211.105 slave节点被选举成为新的,master,证明sentinel部署成功:
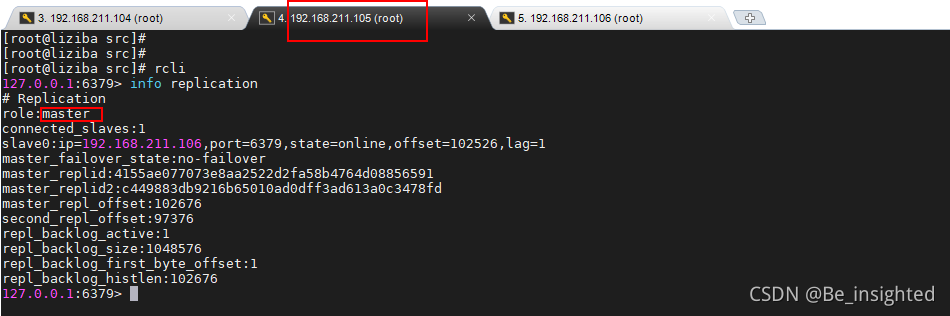
最后我们将shutdown的192.168.211.104节点重新启动,再次查看Redis的集群情况
我们发现192.168.211.104重启后,成为了一个新的slave节点,此时的master节点仍然时192.168.211.105.
10.3 CentOS 7单机安装Redis Cluster(3主3从伪集群)
首先安装单机版Redis
安装配置:
| 服务IP | Redis安装目录 |
| 192.168.211.107 | /usr/local/soft/redis-6.2.4/ |
创建不同的数据目录
- cd /usr/local/soft/redis-6.2.4/
- mkdir redis-cluster
- cd redis-cluster/
- mkdir 6319 6329 6339 6349 6359 6369

拷贝Redis配置文件redis.conf到创建的第一个文件夹下
cp /usr/local/soft/redis-6.2.4/redis.conf /usr/local/soft/redis-6.2.4/redis-cluster/6319
修改配置文件
- cd /usr/local/soft/redis-6.2.4/redis-cluster/6319
- vim redis.conf
如下配置文件配置项如有不懂的,可以去我的单机版安装Redis实例中查看,这里搜索这些配置可以退出编辑模式 使用/xxx(斜杆+部分字符) 来搜索,或者直接从服务器拿下来修改
- port 6319
- protected-mode no
- daemonize yes
- dir "/usr/local/soft/redis-6.2.4/redis-cluster/6319/"
- cluster-enabled yes
- cluster-config-file nodes-6319.conf
- cluster-node-timeout 15000
- appendonly yes
- pidfile "/var/run/redis_6319.pid"
外网集群需要增加如下配置
- # 各节点网卡分配的IP(公网IP)
- cluster-announce-ip xx.xx.xx.xx
- # 节点映射端口
- cluster-announce-port ${PORT}
- # 节点总线端口
- cluster-announce-bus-port ${PORT}
拷贝配置文件到其余5个创建的目录
- cd /usr/local/soft/redis-6.2.4/redis-cluster/6319/
- cp redis.conf ../6329/
- cp redis.conf ../6339/
- cp redis.conf ../6349/
- cp redis.conf ../6359/
- cp redis.conf ../6369/

**批量替换配置文件内容 **sed -i 's/原字符串/新字符串/' /xxx/xx.xx
- cd /usr/local/soft/redis-6.2.4/redis-cluster/
- sed -i 's/6319/6329/g' 6329/redis.conf
- sed -i 's/6319/6339/g' 6339/redis.conf
- sed -i 's/6319/6349/g' 6349/redis.conf
- sed -i 's/6319/6359/g' 6359/redis.conf
- sed -i 's/6319/6369/g' 6369/redis.conf

启动6个Redis节点
- ./src/redis-server redis-cluster/6319/redis.conf
- ./src/redis-server redis-cluster/6329/redis.conf
- ./src/redis-server redis-cluster/6339/redis.conf
- ./src/redis-server redis-cluster/6349/redis.conf
- ./src/redis-server redis-cluster/6359/redis.conf
- ./src/redis-server redis-cluster/6369/redis.conf
- ps -ef|grep redis
使用绝对IP地址启动集群
- cd /usr/local/soft/redis-6.2.4/src/
- redis-cli --cluster create 192.168.211.107:6319 192.168.211.107:6329 192.168.211.107:6339 192.168.211.107:6349 192.168.211.107:6359 192.168.211.107:6369 --cluster-replicas 1
Redis对6个节点分配3主3从,我们直接yes确认
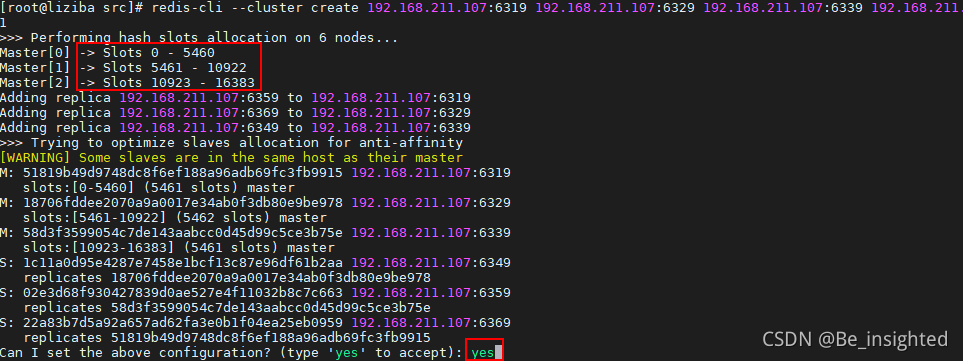
slot分配图,这里记录下来,后续测试有用
| 节点 | IP | 槽范围 |
| Master[0] | 192.168.211.107:6319 | Slots 0 - 5460 |
| Master[1] | 192.168.211.107:6329 | Slots 5461 - 10922 |
| Master[2] | 192.168.211.107:6339 | Slots 10923 - 16383 |
集群创建完成
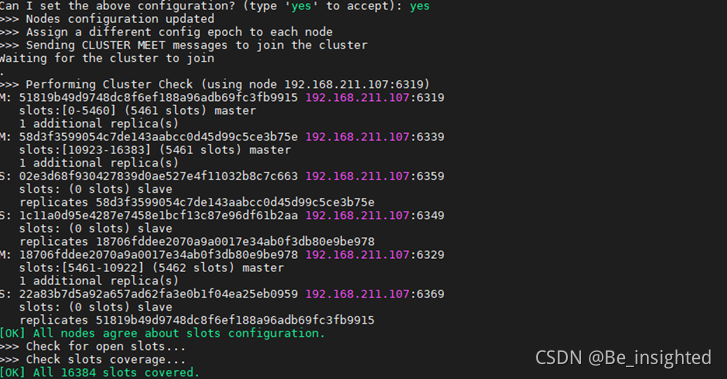
通过脚本批量插入key,来根据key的分布测试集群节点是否正常
创建脚本
- cd /usr/local/soft/redis-6.2.4/redis-cluster/
- vim batchKeyInsert.sh
*脚本内容是循环十万次往Redis中插入key
redis-cli -h {host} -p {port} {command} 是一种客户端连接执行命令方式
redis-cli -h 192.168.211.107 -p 6319 -c -x set name$i >>redis.log
-c
连接集群结点时使用,此选项可防止moved和ask异常
-x
代表从标准输入读取数据作为该命令的最后一个参数
- #!/bin/bash
- for((i=0;i<100000;i++))
- do
- echo -en "Come on, i love java" | redis-cli -h 192.168.211.107 -p 6319 -c -x set name$i >>redis.log
- done
文件赋予权限
chmod +x batchKeyInsert.sh
执行脚本(需要一点时间)
./batchKeyInsert.sh
进入三个主节点,连接客户端,查看节点的数据分布情况
- cd /usr/local/soft/redis-6.2.4/src
- redis-cli -p 6319
- dbsize
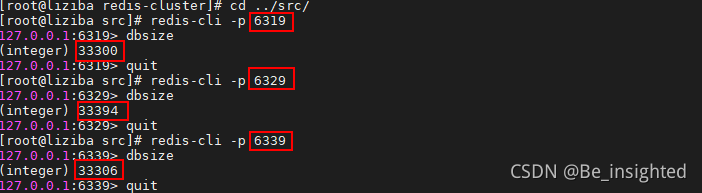
从上面看出节点数据分布较为均匀,集群部署成功!
主从复制是Redis分布式的基石,也是Redis高可用的保障。在Redis中,被复制的服务器称为主服务器(Master),对主服务器进行复制的服务器称为从服务器(Slave)。
主从复制的配置非常简单,有三种方式(其中IP-主服务器IP地址/PORT-主服务器Redis服务端口):
- 配置文件——redis.conf文件中,配置slaveof ip port
- 命令——进入Redis客户端执行slaveof ip port
- 启动参数—— ./redis-server --slaveof ip port
Redis的主从复制机制,并不是一开始就像6.x版本一样完善,而是一个版本一个版本迭代而来的。它大体上经过三个版本的迭代:
- 2.8以前
- 2.8~4.0
- 4.0以后
随着版本的增长,Redis主从复制机制逐渐完善;但是他们的本质都是围绕同步(sync)和命令传播(command propagate)两个操作展开:
- 同步(sync):指的是将从服务器的数据状态更新至主服务器当前的数据状态,主要发生在初始化或后续的全量同步。
- 命令传播(command propagate):当主服务器的数据状态被修改(写/删除等),主从之间的数据状态不一致时,主服务将发生数据改变的命令传播给从服务器,让主从服务器之间的状态重回一致。
10.4.2.1 版本2.8以前
10.4.2.1.1 同步
2.8以前的版本,从服务器对主服务器的同步需要从服务器向主服务器发生sync命令来完成:
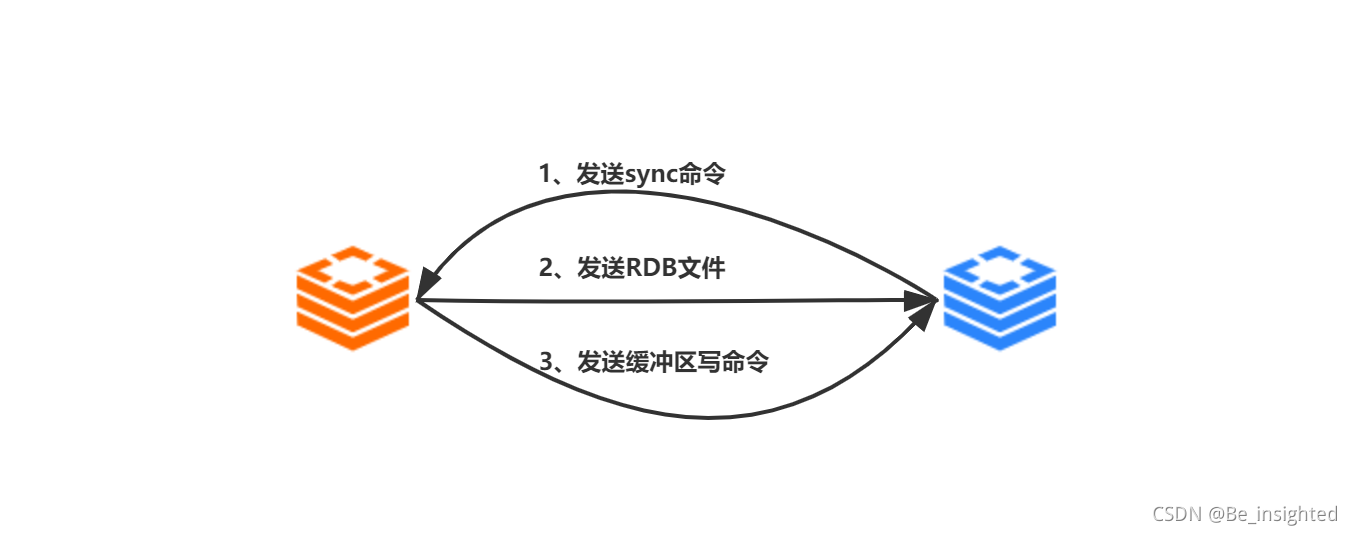
- 从服务器接收到客户端发送的slaveof ip prot命令,从服务器根据ip:port向主服务器创建套接字连接
- 套接字成功连接到主服务器后,从服务器会为这个套接字连接关联一个专门用于处理复制工作的文件事件处理器,处理后续的主服务器发送的RDB文件和传播的命令
- 开始进行复制,从服务器向主服务器发送sync命令
- 主服务器接收到sync命令后,执行bgsave命令,主服务器主进程fork的子进程会生成一个RDB文件,同时将RDB快照产生后的所有写操作记录在缓冲区中
- bgsave命令执行完成后,主服务器将生成的RDB文件发送给从服务器,从服务器接收到RDB文件后,首先会清除本身的全部数据,然后载入RDB文件,将自己的数据状态更新成主服务器的RDB文件的数据状态
- 主服务器将缓冲区的写命令发送给从服务器,从服务器接收命令,并执行。
- 主从复制同步步骤完成
10.4.2.1.2 命令传播
当同步工作完成之后,主从之间需要通过命令传播来维持数据状态的一致性。
如下图,当前主从服务器之间完成同步工作之后,主服务接收客户端的DEL K6指令后删除了K6,此时从服务器仍然存在K6,主从数据状态并不一致。为了维持主从服务器状态一致,主服务器会将导致自己数据状态发生改变的命令传播到从服务器执行,当从服务器也执行了相同的命令之后,主从服务器之间的数据状态将会保持一致。
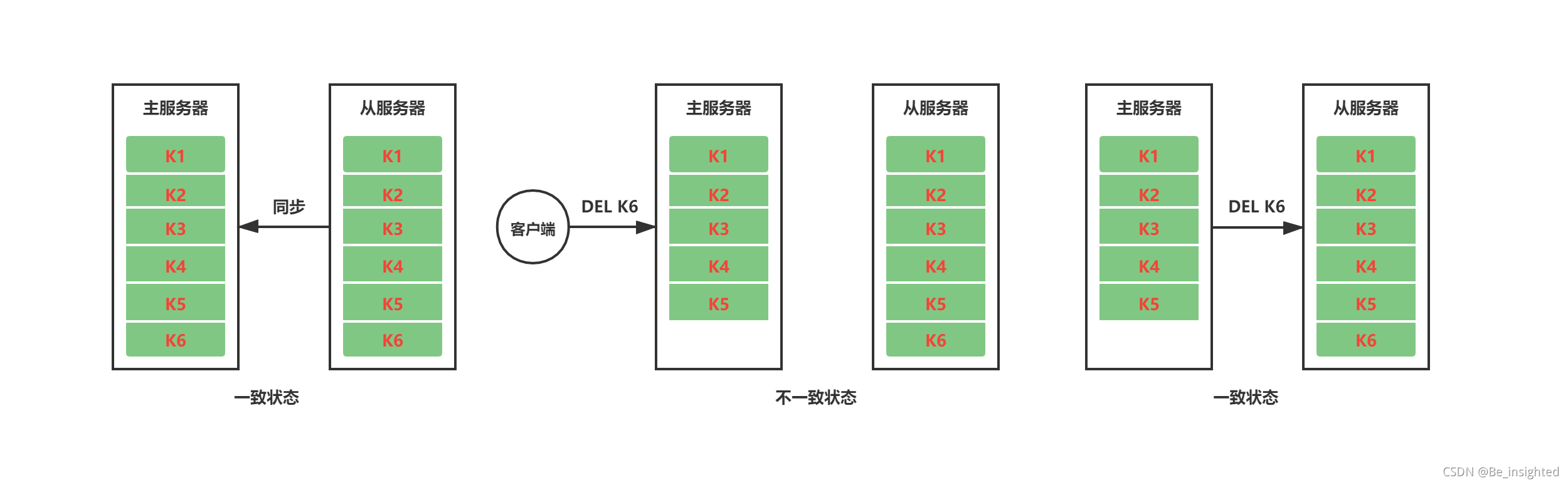
10.4.2.1.3 缺陷
从上面看不出2.8以前版本的主从复制有什么缺陷,这是因为我们还没有考虑网络波动的情况。了解分布式的兄弟们肯定听说过CAP理论,CAP理论是分布式存储系统的基石,在CAP理论中P(partition网络分区)必然存在,Redis主从复制也不例外。当主从服务器之间出现网络故障,导致一段时间内从服务器与主服务器之间无法通信,当从服务器重新连接上主服务器时,如果主服务器在这段时间内数据状态发生了改变,那么主从服务器之间将出现数据状态不一致。
在Redis 2.8以前的主从复制版本中,解决这种数据状态不一致的方式是通过重新发送sync命令来实现。虽然sync能保证主从服务器数据状态一致,但是很明显sync是一个非常消耗资源的操作。
sync命令执行,主从服务器需要占用的资源:
- 主服务器执行BGSAVE生成RDB文件,会占用大量CPU、磁盘I/O和内存资源
- 主服务器将生成的RDB文件发送给从服务器,会占用大量网络带宽,
- 从服务器接收RDB文件并载入,会导致从服务器阻塞,无法提供服务
从上面三点可以看出,sync命令不仅会导致主服务器的响应能力下降,也会导致从服务器在此期间拒绝对外提供服务。
10.4.2.2 版本2.8-4.0
10.4.2.2.1 改进点
针对2.8以前的版本,Redis在2.8之后对从服务器重连后的数据状态同步进行了改进。改进的方向是减少全量同步(full resynchronizaztion)的发生,尽可能使用增量同步(partial resynchronization)。在2.8版本之后使用psync命令代替了sync命令来执行同步操作,psync命令同时具备全量同步和增量同步的功能:
- 全量同步与上一版本(sync)一致
- 增量同步中对于断线重连后的复制,会根据情况采取不同措施;如果条件允许,仍然只发送从服务缺失的部分数据。
10.4.2.2.2 psync如何实现
Redis为了实现从服务器断线重连后的增量同步,增加了三个辅助参数:
- 复制偏移量(replication offset)
- 积压缓冲区(replication backlog)
- 服务器运行id(run id)
10.4.2.2.2.1 复制偏移量
在主服务器和从服务器内都会维护一个复制偏移量
- 主服务器向从服务发送数据,传播N个字节的数据,主服务的复制偏移量增加N
- 从服务器接收主服务器发送的数据,接收N个字节的数据,从服务器的复制偏移量增加N
正常同步的情况如下:
通过对比主从服务器之间的复制偏移量是否相等,能够得知主从服务器之间的数据状态是否保持一致。
假设此时A/B正常传播,C从服务器断线,那么将出现如下情况:
很明显有了复制偏移量之后,从服务器C断线重连后,主服务器只需要发送从服务器缺少的100字节数据即可。但是主服务器又是如何知道从服务器缺少的是那些数据呢?
10.4.2.2.2.2 复制积压缓冲区
复制积压缓冲区是一个固定长度的队列,默认为1MB大小。当主服务器数据状态发生改变,主服务器将数据同步给从服务器的同时会另存一份到复制积压缓冲区中。
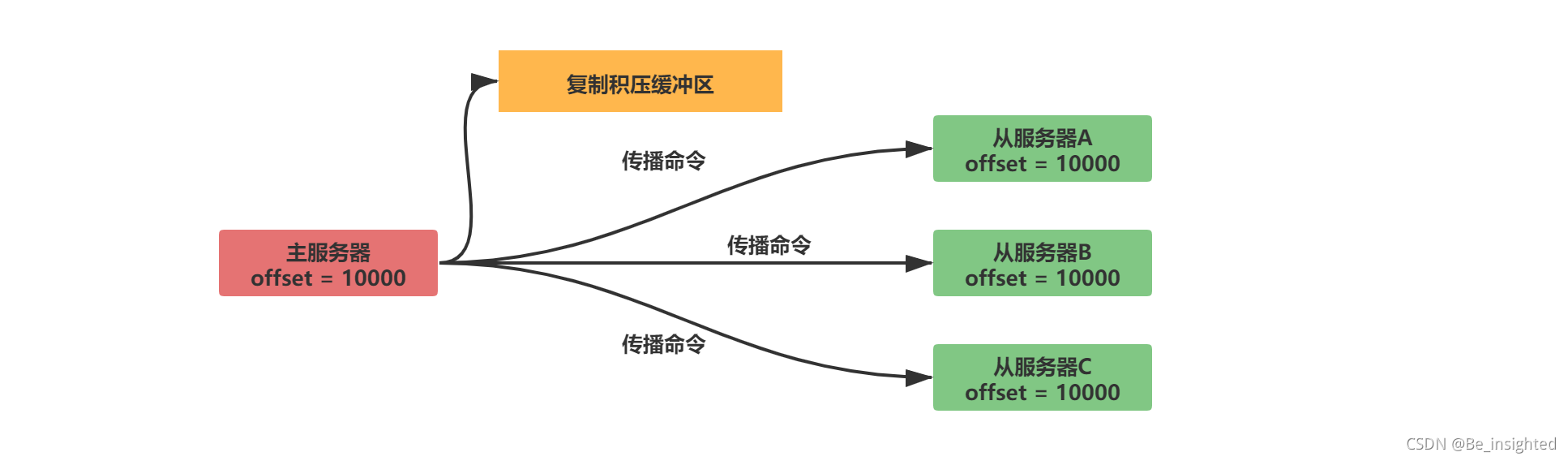
复制积压缓冲区为了能和偏移量进行匹配,它不仅存储了数据内容,还记录了每个字节对应的偏移量:

当从服务器断线重连后,从服务器通过psync命令将自己的复制偏移量(offset)发送给主服务器,主服务器便可通过这个偏移量来判断进行增量传播还是全量同步。
- 如果偏移量offset+1的数据仍然在复制积压缓冲区中,那么进行增量同步操作
- 反之进行全量同步操作,与sync一致
Redis的复制积压缓冲区的大小默认为1MB,如果需要自定义应该如何设置呢?
很明显,我们希望能尽可能的使用增量同步,但是又不希望缓冲区占用过多的内存空间。那么我们可以通过预估Redis从服务断线后重连的时间T,Redis主服务器每秒接收的写命令的内存大小M,来设置复制积压缓冲区的大小S。
**S = 2 * M * T **
注意这里扩大2倍是为了留有一定的余地,保证绝大部分的断线重连都能采用增量同步。
10.4.2.2.2.3 服务器运行 ID
看到这里是不是再想上面已经可以实现断线重连的增量同步了,还要运行ID干嘛?其实还有一种情况没考虑,就是当主服务器宕机后,某台从服务器被选举成为新的主服务器,这种情况我们就通过比较运行ID来区分。
- 运行ID(run id)是服务器启动时自动生成的40个随机的十六进制字符串,主服务和从服务器均会生成运行ID
- 当从服务器首次同步主服务器的数据时,主服务器会发送自己的运行ID给从服务器,从服务器会保存在RDB文件中
- 当从服务器断线重连后,从服务器会向主服务器发送之前保存的主服务器运行ID,如果服务器运行ID匹配,则证明主服务器未发生更改,可以尝试进行增量同步
- 如果服务器运行ID不匹配,则进行全量同步
10.4.2.2.3 完整的psync
完整的psync过程非常的复杂,在2.8-4.0的主从复制版本中已经做到了非常完善。psync命令发送的参数如下:
**psync**
当从服务器没有复制过任何主服务器(并不是主从第一次复制,因为主服务器可能会变化,而是从服务器第一次全量同步),从服务器将会发送:
psync ? -1
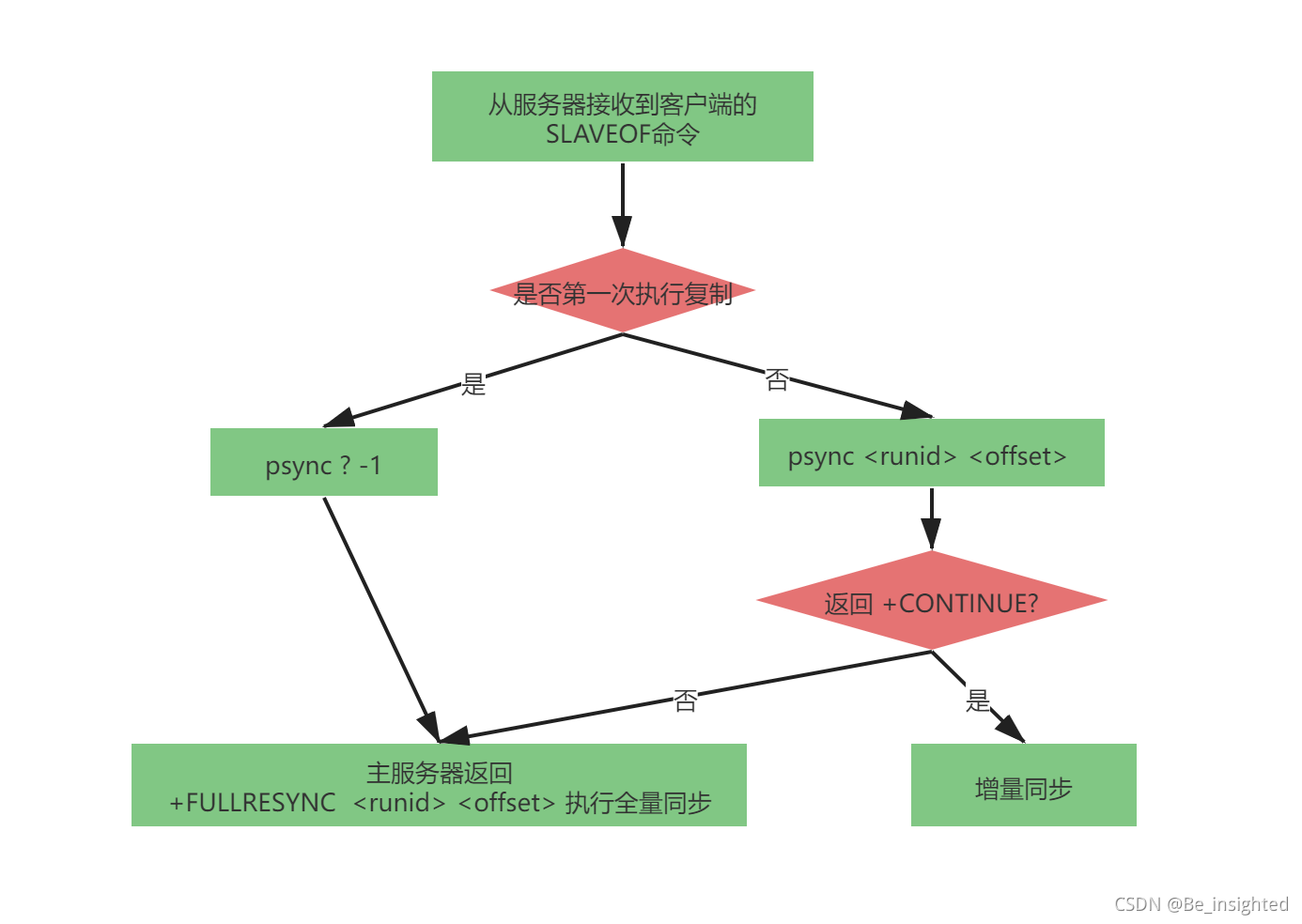
一起完整的psync流程如下图:
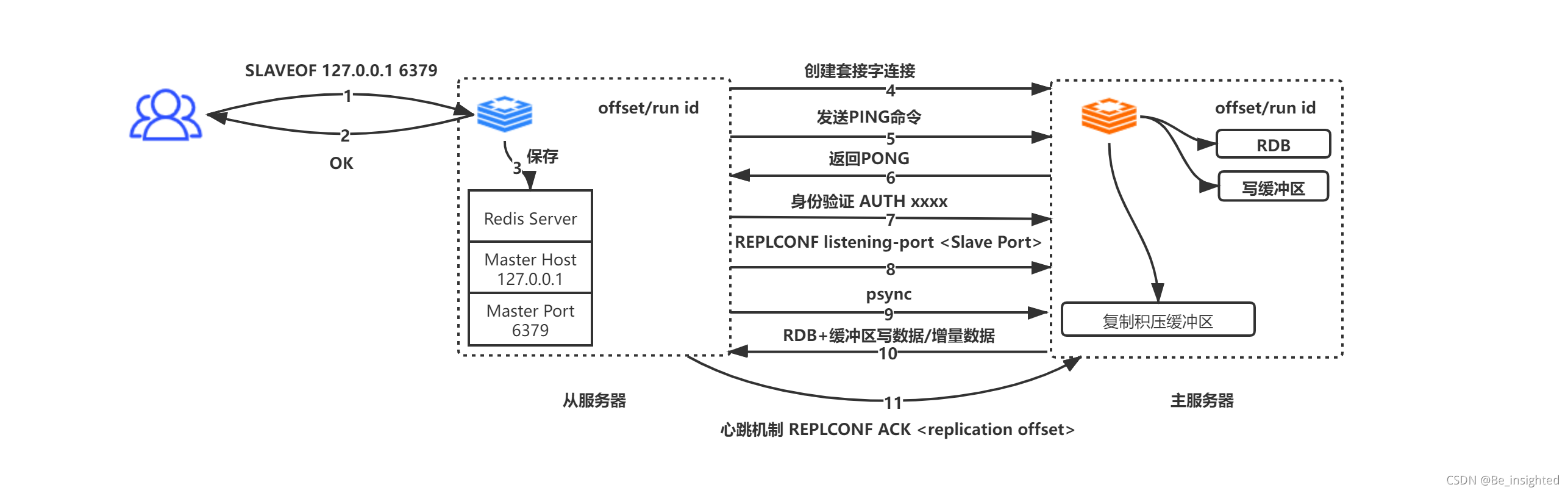
- 从服务器接收到SLAVEOF 127.0.0.1 6379命令
- 从服务器返回OK给命令发起方(这里是异步操作,先返回OK,再保存地址和端口信息)
- 从服务器将IP地址和端口信息保存到Master Host和Master Port中
- 从服务器根据Master Host和Master Port主动向主服务器发起套接字连接,同时从服务将会未这个套接字连接关联一个专门用于文件复制工作的文件事件处理器,用于后续的RDB文件复制等工作
- 主服务器接收到从服务器的套接字连接请求,为该请求创建对应的套接字连接之后,并将从服务器看着一个客户端(在主从复制中,主服务器和从服务器之间其实互为客户端和服务端)
- 套接字连接建立完成,从服务器主动向主服务发送PING命令,如果在指定的超时时间内主服务器返回PONG,则证明套接字连接可用,否则断开重连
- 如果主服务器设置了密码(masterauth),那么从服务器向主服务器发送AUTH masterauth命令,进行身份验证。注意,如果从服务器发送了密码,主服务并未设置密码,此时主服务会发送no password is set错误;如果主服务器需要密码,而从服务器未发送密码,此时主服务器会发送NOAUTH错误;如果密码不匹配,主服务器会发送invalid password错误。
- 从服务器向主服务器发送REPLCONF listening-port xxxx(xxxx表示从服务器的端口)。主服务器接收到该命令后会将数据保存起来,当客户端使用INFO replication查询主从信息时能够返回数据
- 从服务器发送psync命令,此步骤请查看上图psync的两种情况
- 主服务器与从服务器之间互为客户端,进行数据的请求/响应
- 主服务器与从服务器之间通过心跳包机制,判断连接是否断开。从服务器每个1秒向主服务器发送命令,REPLCONF ACL offset(从服务器的复制偏移量),该机制可以保证主从之间数据的正确同步,如果偏移量不相等,主服务器将会采取增量/全量同步措施来保证主从之间数据状态一致(增量/全量的选择取决于,offset+1的数据是否仍在复制积压缓冲区中)
10.4.2.3 版本4.0
Redis 2.8-4.0版本仍然有一些改进的空间,当主服务器切换时,是否也能进行增量同步呢?因此Redis 4.0版本针对这个问题做了优化处理,psync升级为psync2.0。
psync2.0 抛弃了服务器运行ID,采用了replid和replid2来代替,其中replid存储的是当前主服务器的运行ID,replid2保存的是上一个主服务器运行ID。
- 复制偏移量(replication offset)
- 积压缓冲区(replication backlog)
- 主服务器运行id(replid)
- 上个主服务器运行id(replid2)
通过replid和replid2我们可以解决主服务器切换时,增量同步的问题:
- 如果replid等于当前主服务器的运行id,那么判断同步方式增量/全量同步
- 如果replid不相等,则判断replid2是否相等(是否同属于上一个主服务器的从服务器),如果相等,仍然可以选择增量/全量同步,如果不相等则只能进行全量同步。
主从复制奠定了Redis分布式的基础,但是普通的主从复制并不能达到高可用的状态。在普通的主从复制模式下,如果主服务器宕机,就只能通过运维人员手动切换主服务器,很显然这种方案并不可取。
针对上述情况,Redis官方推出了可抵抗节点故障的高可用方案——Redis Sentinel(哨兵)。Redis Sentinel(哨兵):由一个或多个Sentinel实例组成的Sentinel系统,它可以监视任意多个主从服务器,当监视的主服务器宕机时,自动下线主服务器,并且择优选取从服务器升级为新的主服务器。
如下示例:当旧Master下线时长超过用户设定的下线时长上限,Sentinel系统就会对旧Master执行故障转移操作,故障转移操作包含三个步骤:
- 在Slave中选择数据最新的作为新的Master
- 向其他Slave发送新的复制指令,让其他从服务器成为新的Master的Slave
- 继续监视旧Master,如果其上线则将旧Master设置为新Master的Slave
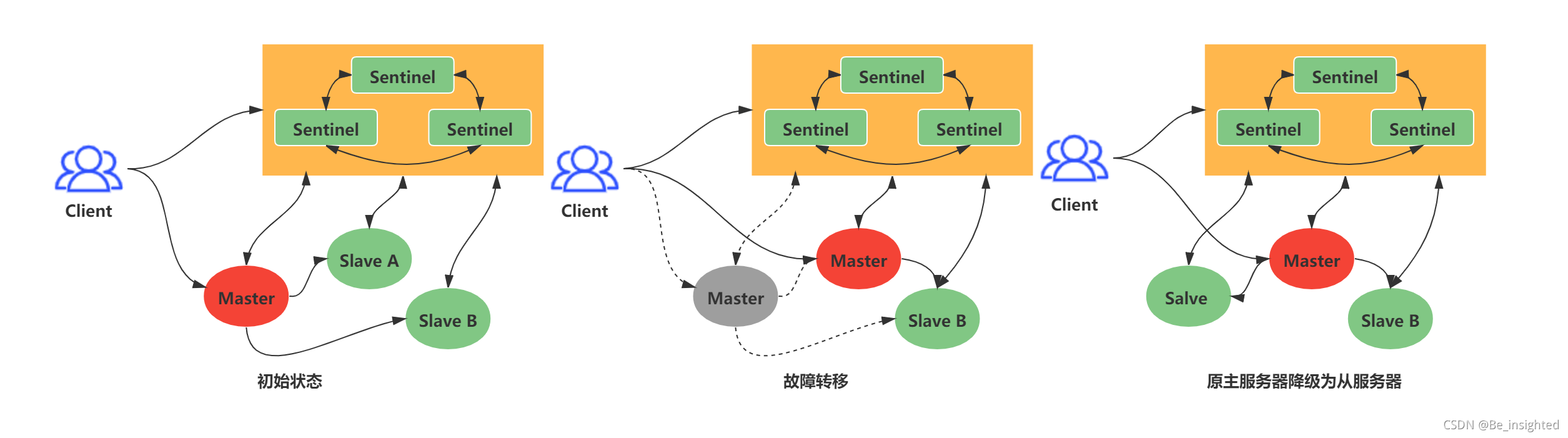
本文基于如下资源清单进行开展:
| IP地址 | 节点角色 | 端口 |
| 192.168.211.104 | Redis Master/ Sentinel | 6379/26379 |
| 192.168.211.105 | Redis Slave/ Sentinel | 6379/26379 |
| 192.168.211.106 | Redis Slave/ Sentinel | 6379/26379 |
Sentinel并没有什么特别神奇的地方,它就是一个更加简单的Redis服务器,在Sentinel启动的时候它会加载不同的命令表和配置文件,因此从本质上来讲Sentinel就是一个拥有较少命令和部分特殊功能的Redis服务。当一个Sentinel启动时它需要经历如下步骤:
- 初始化Sentinel服务器
- 替换普通Redis代码为Sentinel的专用代码
- 初始化Sentinel状态
- 根据用户给定的Sentinel配置文件,初始化Sentinel监视的主服务器列表
- 创建连接主服务器的网络连接
- 根据主服务获取从服务器信息,创建连接从服务器的网络连接
- 根据发布/订阅获取Sentinel信息,创建Sentinel之间的网络连接
10.5.2.1 初始化Sentinel服务器
Sentinel本质上就是一个Redis服务器,因此启动Sentinel需要启动一个Redis服务器,但是Sentinel并不需要读取RDB/AOF文件来还原数据状态。
10.5.2.2 替换普通Redis代码为Sentinel的专用代码
Sentinel用于较少的Redis命令,大部分命令在Sentinel客户端都不支持,并且Sentinel拥有一些特殊的功能,这些需要Sentinel在启动时将Redis服务器使用的代码替换为Sentinel的专用代码。在此期间Sentinel会载入与普通Redis服务器不同的命令表。
Sentinel不支持SET、DBSIZE等命令;保留支持PING、PSUBSCRIBE、SUBSCRIBE、UNSUBSCRIBE、INFO等指令;这些指令在Sentinel工作中提供了保障。
10.5.2.3 初始化Sentinel状态
装载Sentinel的特有代码之后,Sentinel会初始化sentinelState结构,该结构用于存储Sentinel相关的状态信息,其中最重要的就是masters字典。
- struct sentinelState {
- //当前纪元,故障转移使用
- uint64_t current_epoch;
- // Sentinel监视的主服务器信息
- // key -> 主服务器名称
- // value -> 指向sentinelRedisInstance指针
- dict *masters;
- // ...
- } sentinel;
10.5.2.4 初始化Sentinel监视的主服务器列表
Sentinel监视的主服务器列表保存在sentinelState的masters字典中,当sentinelState创建之后,开始对Sentinel监视的主服务器列表进行初始化。
- masters的key是主服务的名字
- masters的value是一个指向sentinelRedisInstance指针
主服务器的名字由我们sentinel.conf配置文件指定,如下主服务器名字为redis-master(我这里是一主二从的配置):
- daemonize yes
- port 26379
- protected-mode no
- dir "/usr/local/soft/redis-6.2.4/sentinel-tmp"
- sentinel monitor redis-master 192.168.211.104 6379 2
- sentinel down-after-milliseconds redis-master 30000
- sentinel failover-timeout redis-master 180000
- sentinel parallel-syncs redis-master 1
sentinelRedisInstance实例保存了Redis服务器的信息(主服务器、从服务器、Sentinel信息都保存在这个实例中)。
- typedef struct sentinelRedisInstance {
- // 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
- int flags;
- // 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
- char *name;
- // 服务器运行ID
- char *runid;
- //配置纪元,故障转移使用
- uint64_t config_epoch;
- // 实例地址
- sentinelAddr *addr;
- // 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
- mstime_t down_after_period;
- // 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
- int quorum;
- // 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
- int parallel-syncs;
- // 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
- mstime_t failover_timeout;
- // ...
- } sentinelRedisInstance;
根据上面的一主二从配置将会得到如下实例结构:
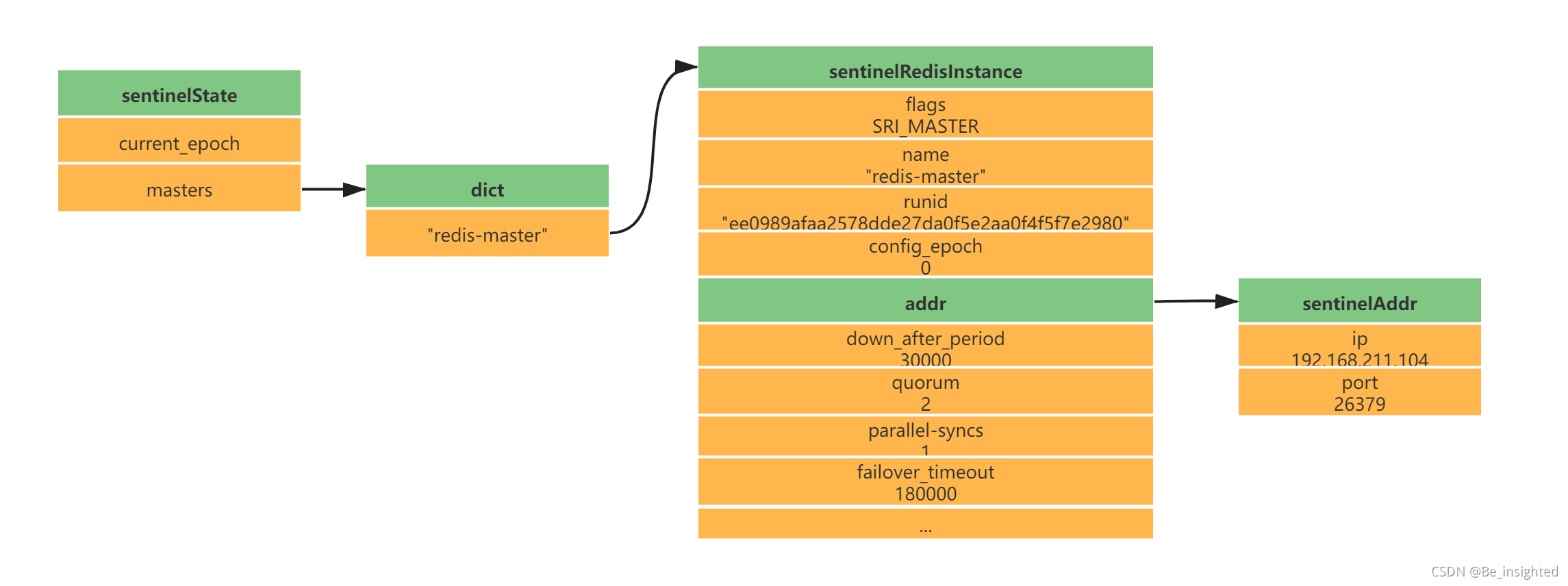
10.5.2.5 创建连接主服务器的网络连接
当实例结构初始化完成之后,Sentinel将会开始创建连接Master的网络连接,这一步Sentinel将成为Master的客户端。
Sentinel和Master之间会创建一个命令连接和一个订阅连接:
- 命令连接用于获取主从信息
- 订阅连接用于Sentinel之间进行信息广播,每个Sentinel和自己监视的主从服务器之间会订阅sentinel:hello频道(注意Sentinel之间不会创建订阅连接,它们通过订阅sentinel:hello频道来获取其他Sentinel的初始信息)
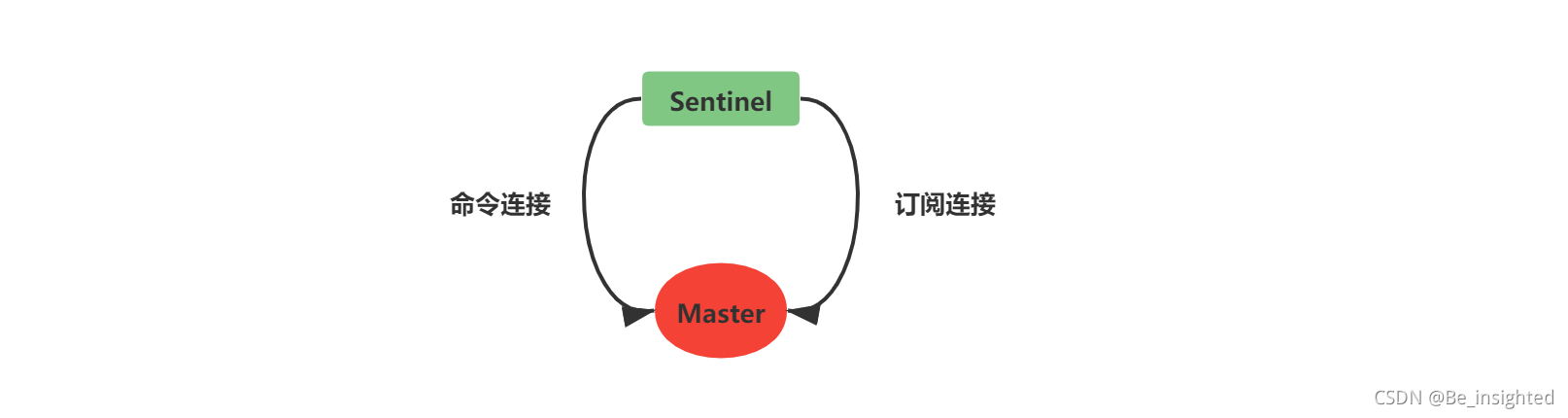
Sentinel在创建命令连接完成之后,每隔10秒钟向Master发送一次INFO指令,通过Master的回复信息可以获得两方面的知识:
- Master本身的信息
- Master下的Slave信息
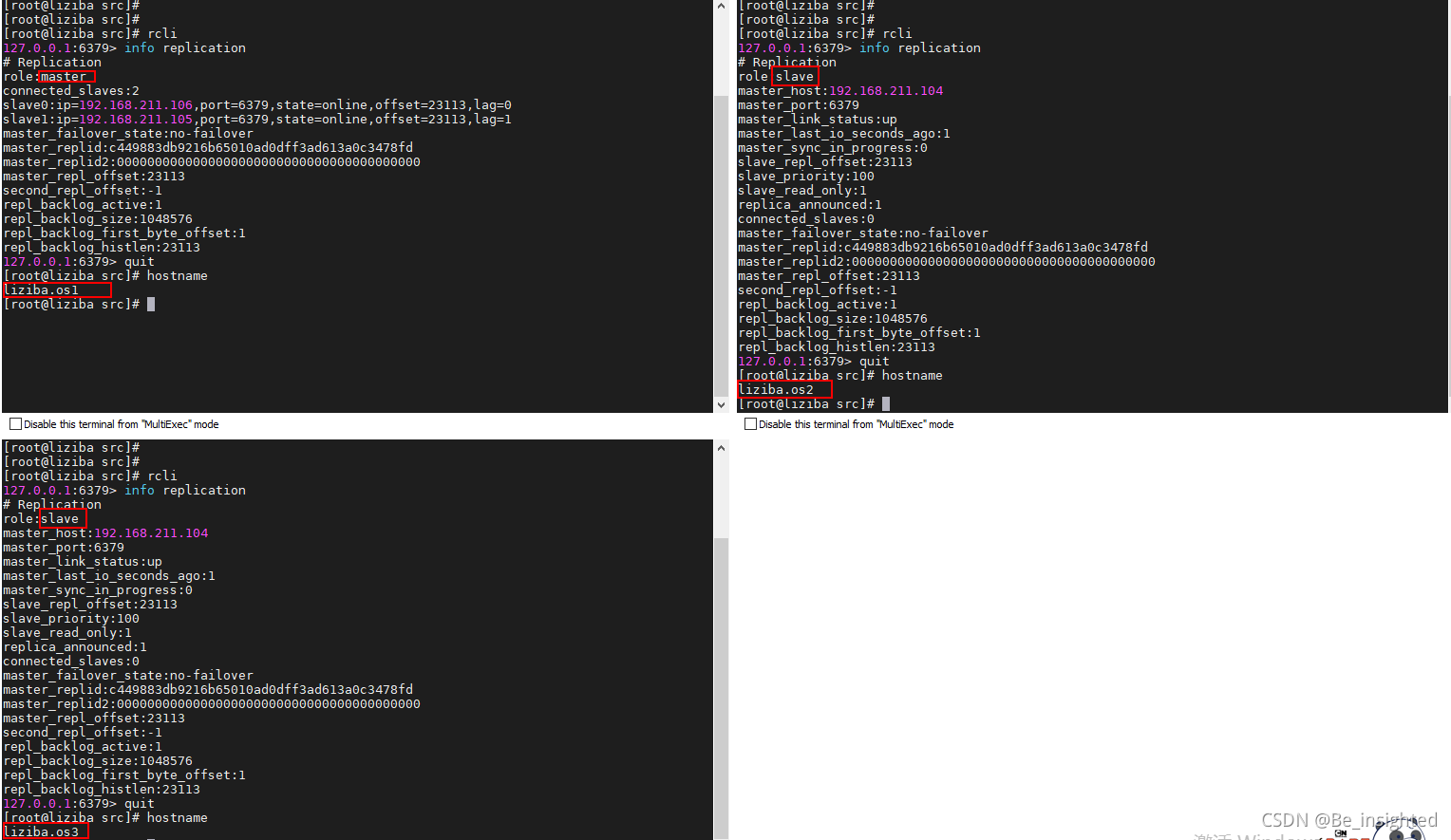
10.5.2.6 创建连接从服务器的网络连接
根据主服务获取从服务器信息,Sentinel可以创建到Slave的网络连接,Sentinel和Slave之间也会创建命令连接和订阅连接。
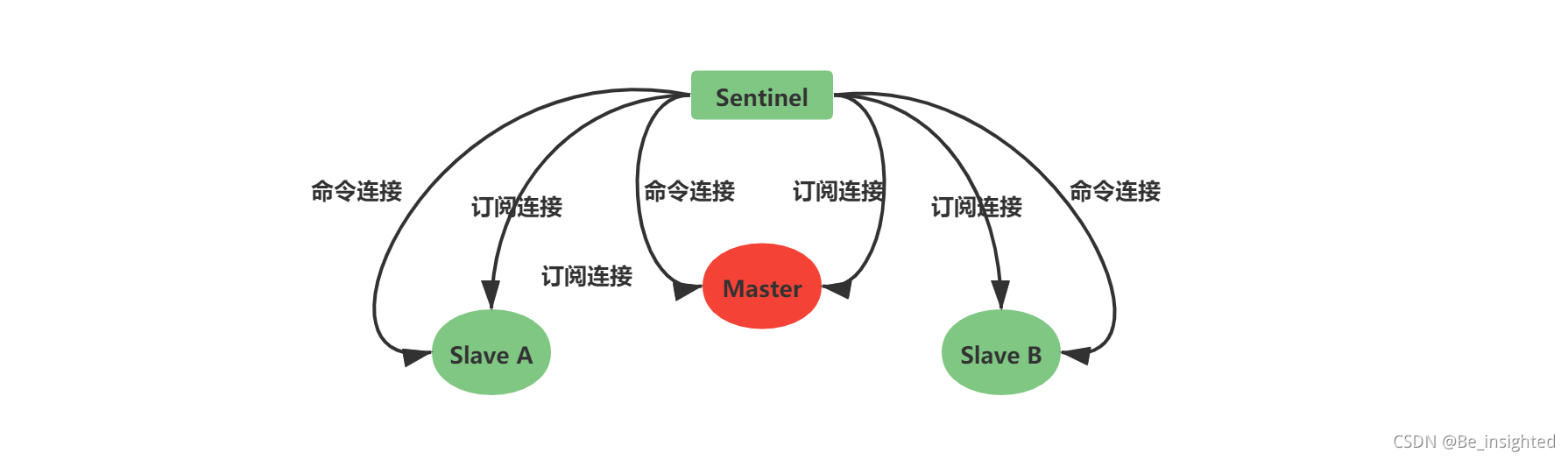
当Sentinel和Slave之间创建网络连接之后,Sentinel成为了Slave的客户端,Sentinel也会每隔10秒钟通过INFO指令请求Slave获取服务器信息。
到这一步Sentinel获取到了Master和Slave的相关服务器数据。这其中比较重要的信息如下:
- 服务器ip和port
- 服务器运行id run id
- 服务器角色role
- 服务器连接状态mater_link_status
- Slave复制偏移量slave_repl_offset(故障转移中选举新的Master需要使用)
- Slave优先级slave_priority
此时实例结构信息如下所示:
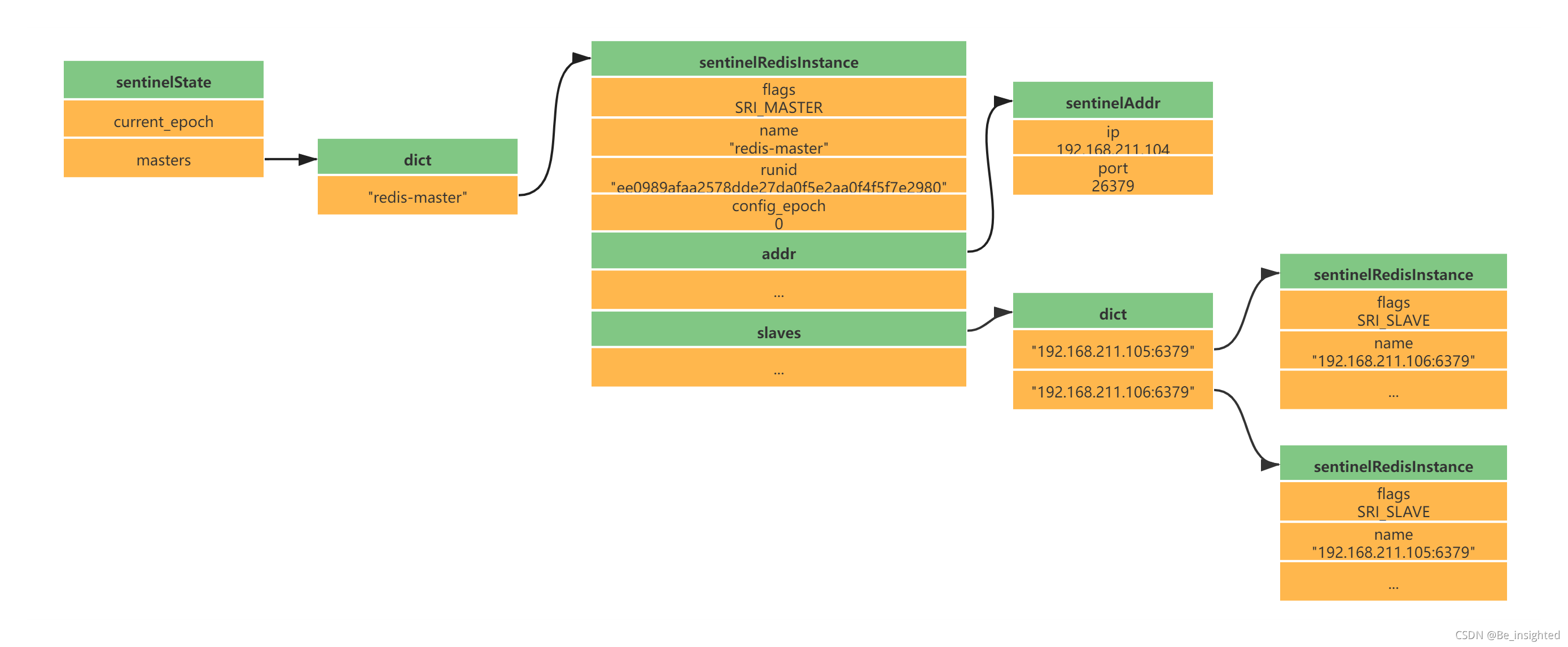
10.5.2.7 创建Sentinel之间的网络连接
此时是不是还有疑问,Sentinel之间是怎么互相发现对方并且相互通信的,这个就和上面Sentinel与自己监视的主从之间订阅sentinel:hello频道有关了。
Sentinel会与自己监视的所有Master和Slave之间订阅sentinel:hello频道,并且Sentinel每隔2秒钟向sentinel:hello频道发送一条消息,消息内容如下:
PUBLISH sentinel:hello ",,,,,,,"
其中s代码Sentinel,m代表Master;ip表示IP地址,port表示端口、runid表示运行id、epoch表示配置纪元。
多个Sentinel在配置文件中会配置相同的主服务器ip和端口信息,因此多个Sentinel均会订阅sentinel:hello频道,通过频道接收到的信息就可获取到其他Sentinel的ip和port,其中有如下两点需要注意:
- 如果获取到的runid与Sentinel自己的runid相同,说明消息是自己发布的,直接丢弃
- 如果不相同,则说明接收到的消息是其他Sentinel发布的,此时需要根据ip和port去更新或新增Sentinel实例数据
Sentinel之间不会创建订阅连接,它们只会创建命令连接:

此时实例结构信息如下所示:
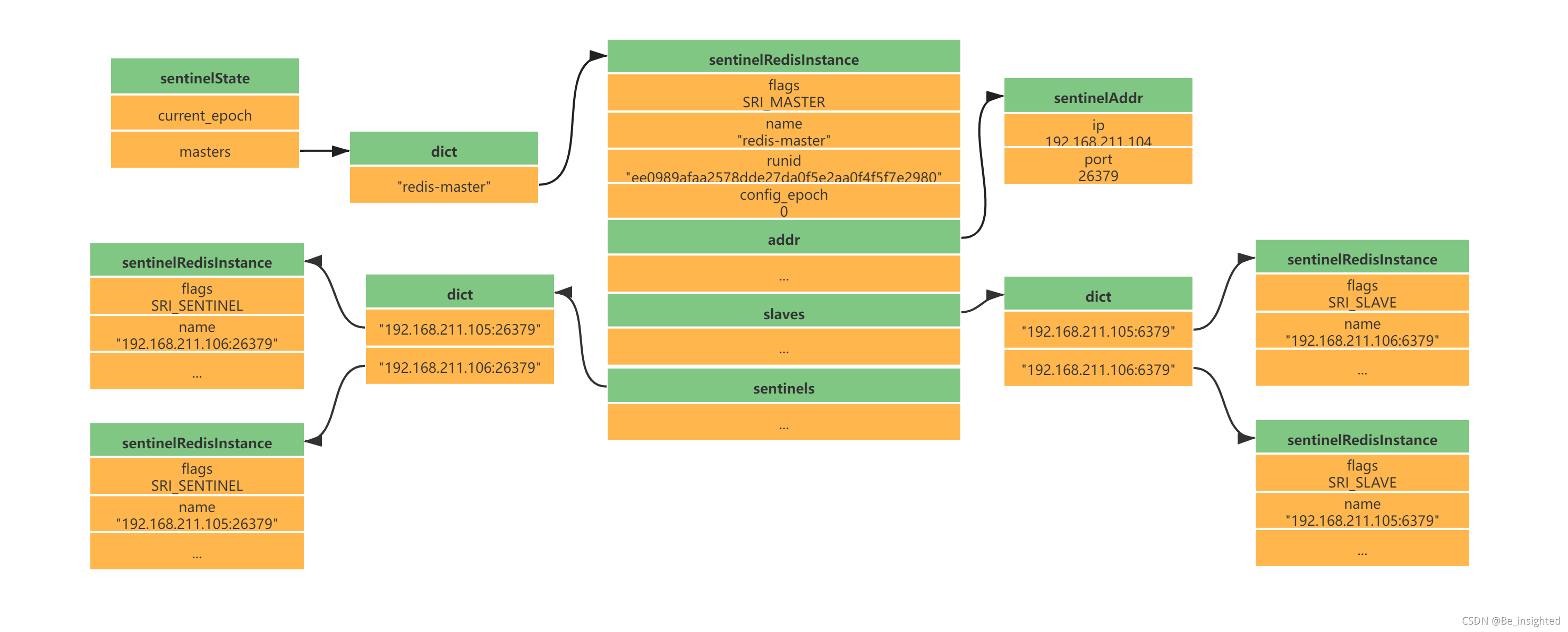
Sentinel最主要的工作就是监视Redis服务器,当Master实例超出预设的时限后切换新的Master实例。这其中有很多细节工作,大致分为检测Master是否主观下线、检测Master是否客观下线、选举领头Sentinel、故障转移四个步骤。
10.5.3.1 检测Master是否主观下线
Sentinel每隔1秒钟,向sentinelRedisInstance实例中的所有Master、Slave、Sentinel发送PING命令,通过其他服务器的回复来判断其是否仍然在线。
sentinel down-after-milliseconds redis-master 30000
在Sentinel的配置文件中,当Sentinel PING的实例在连续down-after-milliseconds配置的时间内返回无效命令,则当前Sentinel认为其主观下线。Sentinel的配置文件中配置的down-after-milliseconds将会对其sentinelRedisInstance实例中的所有Master、Slave、Sentinel都适应。
无效指令指的是+PONG、-LOADING、-MASTERDOWN之外的其他指令,包括无响应
如果当前Sentinel检测到Master处于主观下线状态,那么它将会修改其sentinelRedisInstance的flags为SRI_S_DOWN

10.5.3.2 检测Master是否客观下线
当前Sentinel认为其下线只能处于主观下线状态,要想判断当前Master是否客观下线,还需要询问其他Sentinel,并且所有认为Master主观下线或者客观下线的总和需要达到quorum配置的值,当前Sentinel才会将Master标志为客观下线。

当前Sentinel向sentinelRedisInstance实例中的其他Sentinel发送如下命令:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
- ip:被判断为主观下线的Master的IP地址
- port:被判断为主观下线的Master的端口
- current_epoch:当前sentinel的配置纪元
- runid:当前sentinel的运行id,runid
current_epoch和runid均用于Sentinel的选举,Master下线之后,需要选举一个领头Sentinel来选举一个新的Master,current_epoch和runid在其中发挥着重要作用,这个后续讲解。
接收到命令的Sentinel,会根据命令中的参数检查主服务器是否下线,检查完成后会返回如下三个参数:
- down_state:检查结果1代表已下线、0代表未下线
- leader_runid:返回*代表判断是否下线,返回runid代表选举领头Sentinel
- leader_epoch:当leader_runid返回runid时,配置纪元会有值,否则一直返回0
- 当Sentinel检测到Master处于主观下线时,询问其他Sentinel时会发送current_epoch和runid,此时current_epoch=0,runid=*
- 接收到命令的Sentinel返回其判断Master是否下线时down_state = 1/0,leader_runid = *,leader_epoch=0
10.5.3.3 选举领头Sentinel
down_state返回1,证明接收is-master-down-by-addr命令的Sentinel认为该Master也主观下线了,如果down_state返回1的数量(包括本身)大于等于quorum(配置文件中配置的值),那么Master正式被当前Sentinel标记为客观下线。
此时,Sentinel会再次发送如下指令:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
此时的runid将不再是0,而是Sentinel自己的运行id(runid)的值,表示当前Sentinel希望接收到is-master-down-by-addr命令的其他Sentinel将其设置为领头Sentinel。这个设置是先到先得的,Sentinel先接收到谁的设置请求,就将谁设置为领头Sentinel。
发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。
10.5.3.4 故障转移
故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情:
- 从原先master的slave中,选择最佳的slave作为新的master
- 让其他slave成为新的master的slave
- 继续监听旧master,如果其上线,则将其设置为新的master的slave
这其中最难的一步是如果选择最佳的新Master,领头Sentinel会做如下清洗和排序工作:
- 判断slave是否有下线的,如果有从slave列表中移除
- 删除5秒内未响应sentinel的INFO命令的slave
- 删除与下线主服务器断线时间超过down_after_milliseconds * 10 的所有从服务器
- 根据slave优先级slave_priority,选择优先级最高的slave作为新master
- 如果优先级相同,根据slave复制偏移量slave_repl_offset,选择偏移量最大的slave作为新master
- 如果偏移量相同,根据slave服务器运行id run id排序,选择run id最小的slave作为新master
新的Master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新Master)发送SLAVEOF ip port命令,使其成为新master的slave。
到这里Sentinel的的工作流程就算是结束了,如果新master下线,则循环流程即可!
Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)进行数据共享,Redis集群主要实现了以下目标:
- 在1000个节点的时候仍能表现得很好并且可扩展性是线性的。
- 没有合并操作(多个节点不存在相同的键),这样在 Redis 的数据模型中最典型的大数据值中也能有很好的表现。
- 写入安全,那些与大多数节点相连的客户端所做的写入操作,系统尝试全部都保存下来。但是Redis无法保证数据完全不丢失,异步同步的主从复制无论如何都会存在数据丢失的情况。
- 可用性,主节点不可用,从节点能替换主节点工作。
关于Redis集群的学习,如果没有任何经验的弟兄们建议先看下这三篇文章(中文系列):
Redis集群教程
REDIS cluster-tutorial -- Redis中文资料站 -- Redis中国用户组(CRUG)
Redis集群规范
REDIS cluster-spec -- Redis中文资料站 -- Redis中国用户组(CRUG)
Redis3主3从伪集群部署
CentOS 7单机安装Redis Cluster(3主3从伪集群),仅需简单五步_李子捌的博客-CSDN博客
下文内容依赖下图三主三从结构开展:
资源清单:
| 节点 | IP | 槽(slot)范围 |
| Master[0] | 192.168.211.107:6319 | Slots 0 - 5460 |
| Master[1] | 192.168.211.107:6329 | Slots 5461 - 10922 |
| Master[2] | 192.168.211.107:6339 | Slots 10923 - 16383 |
| Slave[0] | 192.168.211.107:6369 | |
| Slave[1] | 192.168.211.107:6349 | |
| Slave[2] | 192.168.211.107:6359 |
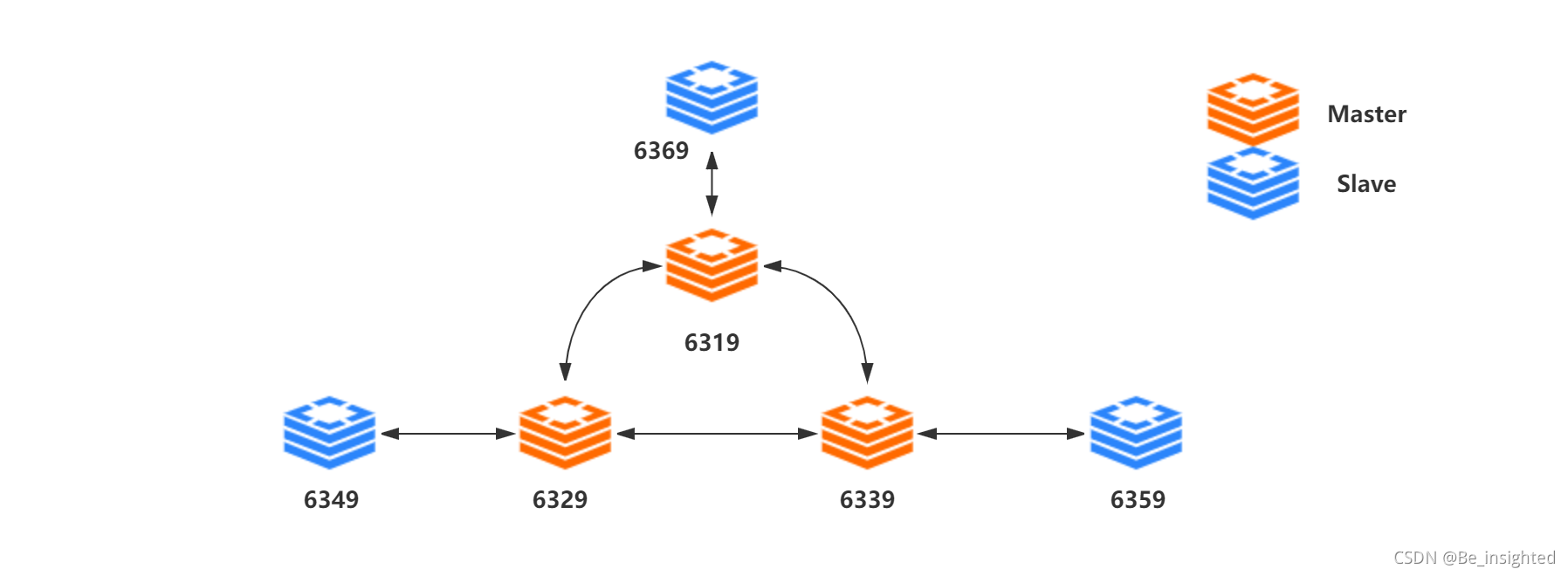
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,这种结构很容易添加或者删除节点。集群的每个节点负责一部分hash槽,比如上面资源清单的集群有3个节点,其槽分配如下所示:
- 节点 Master[0] 包含 0 到 5460 号哈希槽
- 节点 Master[1] 包含5461 到 10922 号哈希槽
- 节点 Master[2] 包含10923到 16383 号哈希槽
深入学习Redis集群之前,需要了解集群中Redis实例的内部结构。当某个Redis服务节点通过cluster_enabled配置为yes开启集群模式之后,Redis服务节点不仅会继续使用单机模式下的服务器组件,还会增加custerState、clusterNode、custerLink等结构用于存储集群模式下的特殊数据。
如下三个数据承载对象一定要认真看,尤其是结构中的注释,看完之后集群大体上怎么工作的,心里就有数了,嘿嘿嘿;
10.6.2.1 clsuterNode
clsuterNode用于存储节点信息,比如节点的名字、IP地址、端口信息和配置纪元等等,以下代码列出部分非常重要的属性:
- typedef struct clsuterNode {
- // 创建时间
- mstime_t ctime;
- // 节点名字,由40位随机16进制的字符组成(与sentinel中讲的服务器运行id相同)
- char name[REDIS_CLUSTER_NAMELEN];
- // 节点标识,可以标识节点的角色和状态
- // 角色 -> 主节点或从节点 例如:REDIS_NODE_MASTER(主节点) REDIS_NODE_SLAVE(从节点)
- // 状态 -> 在线或下线 例如:REDIS_NODE_PFAIL(疑似下线) REDIS_NODE_FAIL(下线)
- int flags;
- // 节点配置纪元,用于故障转移,与sentinel中用法类似
- // clusterState中的代表集群的配置纪元
- unit64_t configEpoch;
- // 节点IP地址
- char ip[REDIS_IP_STR_LEN];
- // 节点端口
- int port;
- // 连接节点的信息
- clusterLink *link;
- // 一个2048字节的二进制位数组
- // 位数组索引值可能为0或1
- // 数组索引i位置值为0,代表节点不负责处理槽i
- // 数组索引i位置值为1,代表节点负责处理槽i
- unsigned char slots[16384/8];
- // 记录当前节点处理槽的数量总和
- int numslots;
- // 如果当前节点是从节点
- // 指向当前从节点的主节点
- struct clusterNode *slaveof;
- // 如果当前节点是主节点
- // 正在复制当前主节点的从节点数量
- int numslaves;
- // 数组——记录正在复制当前主节点的所有从节点
- struct clusterNode **slaves;
- } clsuterNode;
上述代码中可能不太好理解的是slots[16384/8],其实可以简单的理解为一个16384大小的数组,数组索引下标处如果为1表示当前槽属于当前clusterNode处理,如果为0表示不属于当前clusterNode处理。clusterNode能够通过slots来识别,当前节点处理负责处理哪些槽。
初始clsuterNode或者未分配槽的集群中的clsuterNode的slots如下所示:
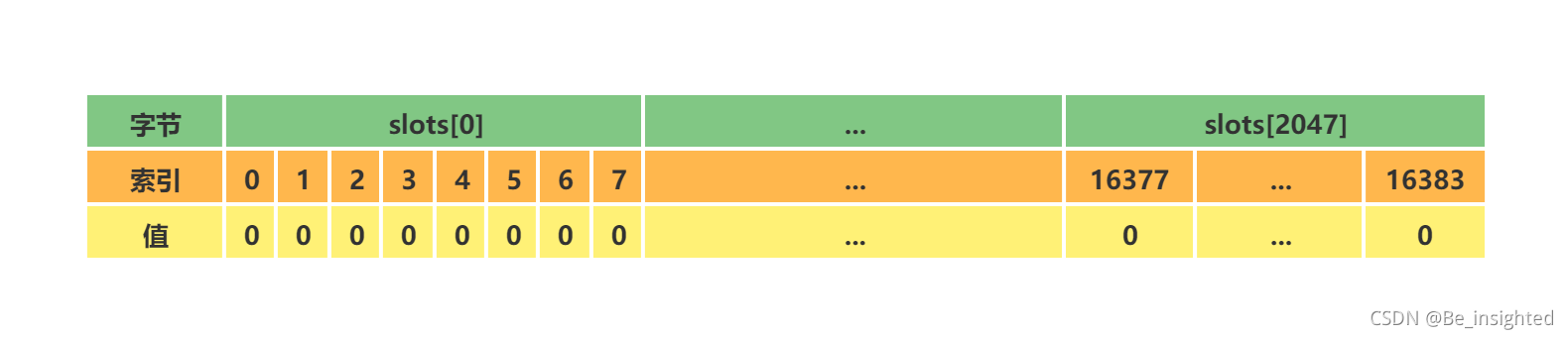
假设集群如上面我给出的资源清单,此时代表Master[0]的clusterNode的slots如下所示:

10.6.2.2 clusterLink
clusterLink是clsuterNode中的一个属性,用于存储连接节点所需的相关信息,比如套接字描述符、输入输出缓冲区等待,以下代码列出部分非常重要的属性:
- typedef struct clusterState {
- // 连接创建时间
- mstime_t ctime;
- // TCP 套接字描述符
- int fd;
- // 输出缓冲区,需要发送给其他节点的消息缓存在这里
- sds sndbuf;
- // 输入缓冲区,接收打其他节点的消息缓存在这里
- sds rcvbuf;
- // 与当前clsuterNode节点代表的节点建立连接的其他节点保存在这里
- struct clusterNode *node;
- } clusterState;
10.6.2.3 custerState
每个节点都会有一个custerState结构,这个结构中存储了当前集群的全部数据,比如集群状态、集群中的所有节点信息(主节点、从节点)等等,以下代码列出部分非常重要的属性:
- typedef struct clusterState {
- // 当前节点指针,指向一个clusterNode
- clusterNode *myself;
- // 集群当前配置纪元,用于故障转移,与sentinel中用法类似
- unit64_t currentEpoch;
- // 集群状态 在线/下线
- int state;
- // 集群中处理着槽的节点数量总和
- int size;
- // 集群节点字典,所有clusterNode包括自己
- dict *node;
- // 集群中所有槽的指派信息
- clsuterNode *slots[16384];
- // 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
- clusterNode *importing_slots_from[16384];
- // 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
- clusterNode *migrating_slots_to[16384];
- // ...
- } clusterState;
在custerState有三个结构需要认真了解的,第一个是slots数组,clusterState中的slots数组与clsuterNode中的slots数组是不一样的,在clusterNode中slots数组记录的是当前clusterNode所负责的槽,而clusterState中的slots数组记录的是整个集群的每个槽由哪个clsuterNode负责,因此集群正常工作的时候clusterState的slots数组每个索引指向负责该槽的clusterNode,集群槽未分配之前指向null。
如图展示资源清单中的集群clusterState中的slots数组与clsuterNode中的slots数组:
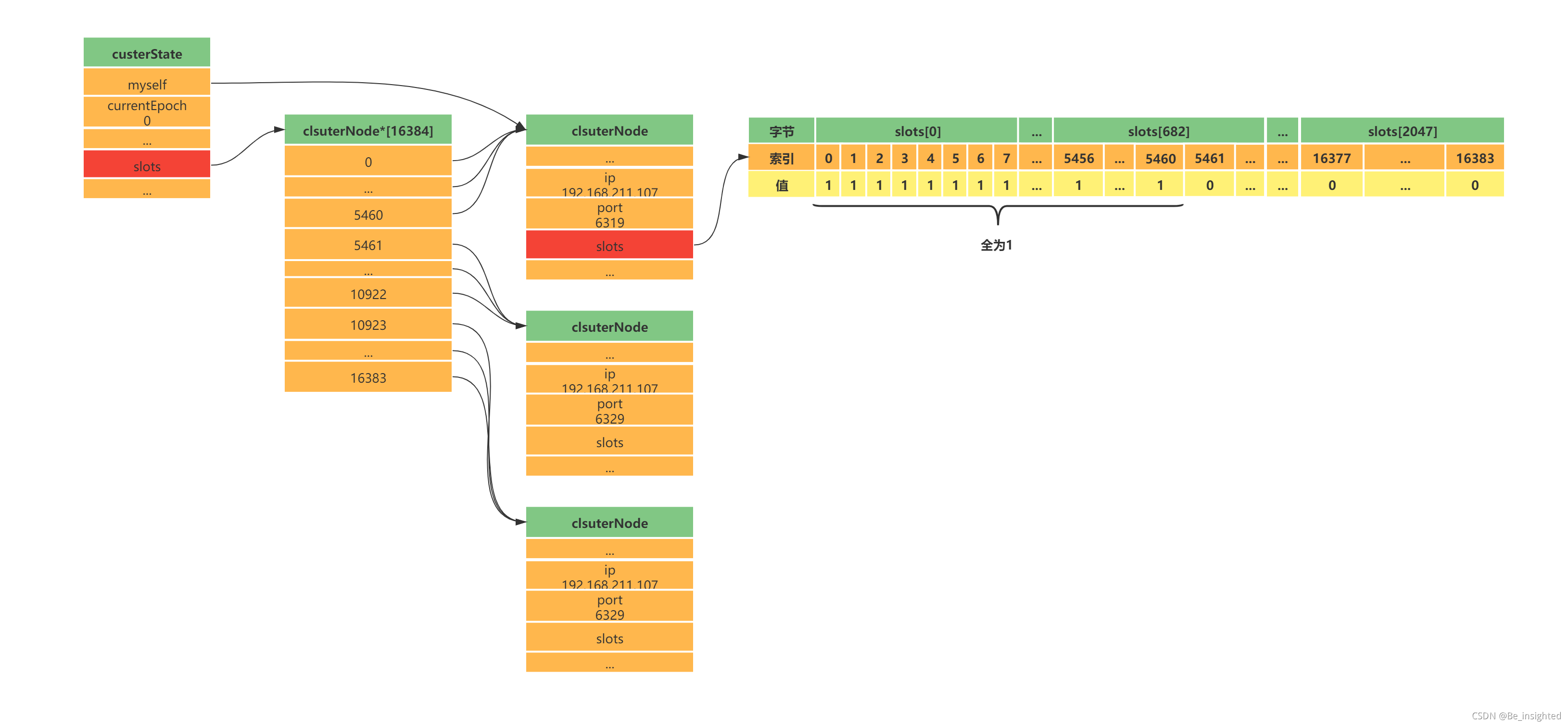
Redis集群中使用两个slots数组的原因是出于性能的考虑:
- 当我们需要获取整个集群中clusterNode分别负责什么槽时,只需要查询clusterState中的slots数组即可。如果没有clusterState的slots数组,则需要遍历所有的clusterNode结构,这样显然要慢一些
- 此外clusterNode中的slots数组也有存在的必要,因为集群中任意一个节点之间需要知道彼此负责的槽,此时节点之间只需要互相传输clusterNode中的slots数组结构就行。
第二个需要认真了解的结构是node字典,该结构虽然简单,但是node字典中存储了所有的clusterNode,这也是Redis集群中的单个节点获取其他主节点、从节点信息的主要位置,因此我们也需要注意一下。
第三个需要认真了解的结构是importing_slots_from[16384]数组和migrating_slots_to[16384],这两个数组在集群重新分片时需要使用,需要重点了解,后面再说吧,这里说的话顺序不太对。
10.6.3.1 槽(slot)如何指派?
Redis集群一共16384个槽,如上资源清单我们在三主三从的集群中,每个主节点负责自己相应的槽,而在上面的三主三从部署的过程中并未看到我指定槽给对应的主节点,这是因为Redis集群自己内部给我们划分了槽,但是如果我们想自己指派槽该如何整呢?
我们可以向节点发送如下命令,将一个或多个槽指派给当前节点负责:
CLUSTER ADDSLOTS
比如我们想把0和1槽指派给Master[0],我们只需要想Master[0]节点发送如下命令即可:
CLUSTER ADDSLOTS 0 1
当节点被指派了槽后,会将clusterNode的slots数组更新,节点会将自己负责处理的槽也就是slots数组通过消息发送给集群中的其他节点,其他节点在接收当消息后会更新对应clusterNode的slots数组以及clusterState的solts数组。
10.6.3.2 ADDSLOTS 在Redis集群内部是如何实现的呢?
这个其实也比较简单,当我们向Redis集群中的某个节点发送CLUSTER ADDSLOTS命令时,当前节点首先会通过clusterState中的slots数组来确认指派给当前节点的槽是否没有指派给其他节点,如果已经指派了,那么会直接抛出异常,返回错误给指派的客户端。如果指派给当前节点的所有槽都未指派给其他节点,那么当前节点会将这些槽指派给自己。
指派主要有三个步骤:
- 更新clusterState的slots数组,将指定槽slots[i]指向当前clusterNode
- 更新clusterNode的slots数组,将指定槽slots[i]处的值更新为1
- 向集群中的其他节点发送消息,将clusterNode的slots数组发送给其他节点,其他节点接收到消息后也更新对应的clusterState的slots数组和clusterNode的slots数组
10.6.3.3 集群这么多节点,客户端怎么知道请求哪个节点?
在了解这个问题之前先要知道一个点,Redis集群是怎么计算当前这个键属于哪个槽的呢?根据官网的介绍,Redis其实并未使用一致性hash算法,而是将每个请求的key通过CRC16校验后对16384取模来决定放置到哪个槽中。
HASH_SLOT = CRC16(key) mod 16384
此时,当客户端连接向某个节点发送请求时,当前接收到命令的节点首先会通过算法计算出当前key所属的槽i,计算完后当前节点会判断clusterState的槽i是否由自己负责,如果恰好由自己负责那么当前节点就会之间响应客户端的请求,如果不由当前节点负责,则会经历如下步骤:
- 节点向客户端返回MOVED重定向错误,MOVED重定向错误中会将计算好的正确处理该key的clusterNode的ip和port返回给客户端
- 客户端接收到节点返回的MOVED重定向错误时,会根据ip和port将命令转发给正确的节点,整个处理过程对程序员来说透明,由Redis集群的服务端和客户端共同负责完成。
10.6.3.4 如果我想将已经分配给A节点的槽重新分配给B节点,怎么整?
这个问题其实涵括了很多问题,比如移除Redis集群中的某些节点,增加节点等都可以概括为把哈希槽从一个节点移动到另外一个节点。并且Redis集群非常牛逼的一点也在这里,它支持在线(不停机)的分配,也就是官方说集群在线重配置(live reconfiguration )。
在将实现之前先来看下CLUSTER的指令,指令会了操作就会了:
- CLUSTER ADDSLOTS slot1 [slot2] … [slotN]
- CLUSTER DELSLOTS slot1 [slot2] … [slotN]
- CLUSTER SETSLOT slot NODE node
- CLUSTER SETSLOT slot MIGRATING node
- CLUSTER SETSLOT slot IMPORTING node
CLUSTER 用于槽分配的指令主要有如上这些,ADDSLOTS 和DELSLOTS主要用于槽的快速指派和快速删除,通常我们在集群刚刚建立的时候进行快速分配的时候才使用。CLUSTER SETSLOT slot NODE node也用于直接给指定的节点指派槽。如果集群已经建立我们通常使用最后两个来重分配,其代表的含义如下所示:
- 当一个槽被设置为 MIGRATING,原来持有该哈希槽的节点仍会接受所有跟这个哈希槽有关的请求,但只有当查询的键还存在原节点时,原节点会处理该请求,否则这个查询会通过一个 -ASK 重定向(-ASK redirection)转发到迁移的目标节点。
- 当一个槽被设置为 IMPORTING,只有在接受到 ASKING 命令之后节点才会接受所有查询这个哈希槽的请求。如果客户端一直没有发送 ASKING 命令,那么查询都会通过 -MOVED 重定向错误转发到真正处理这个哈希槽的节点那里。
上面这两句话是不是感觉不太看的懂,这是官方的描述,不太懂的话我来给你通俗的描述,整个流程大致如下步骤:
- redis-trib(集群管理软件redis-trib会负责Redis集群的槽分配工作),向目标节点(槽导入节点)发送CLUSTER SETSLOT slot IMPORTING node命令,目标节点会做好从源节点(槽导出节点)导入槽的准备工作。
- redis-trib随即向源节点发送CLUSTER SETSLOT slot MIGRATING node命令,源节点会做好槽导出准备工作
- redis-trib随即向源节点发送CLUSTER GETKEYSINSLOT slot count命令,源节点接收命令后会返回属于槽slot的键,最多返回count个键
- redis-trib会根据源节点返回的键向源节点依次发送MIGRATE ip port key 0 timeout命令,如果key在源节点中,将会迁移至目标节点。
- 迁移完成之后,redis-trib会向集群中的某个节点发送CLUSTER SETSLOT slot NODE node命令,节点接收到命令后会更新clusterNode和clusterState结构,然后节点通过消息传播槽的指派信息,至此集群槽迁移工作完成,且集群中的其他节点也更新了新的槽分配信息。
10.6.3.5 如果客户端访问的key所属的槽正在迁移怎么办?
优秀的你总会想到这种并发情况,牛皮呀!大佬们!
这个问题官方也考虑了,还记得我们在聊clusterState结构的时候么?importing_slots_from和migrating_slots_to就是用来处理这个问题的。
- typedef struct clusterState {
- // ...
- // 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
- clusterNode *importing_slots_from[16384];
- // 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
- clusterNode *migrating_slots_to[16384];
- // ...
- } clusterState;
- 当节点正在导出某个槽,则会在clusterState中的migrating_slots_to数组对应的下标处设置其指向对应的clusterNode,这个clusterNode会指向导入的节点。
- 当节点正在导入某个槽,则会在clusterState中的importing_slots_from数组对应的下标处设置其指向对应的clusterNode,这个clusterNode会指向导出的节点。
有了上述两个相互数组,就能判断当前槽是否在迁移了,而且从哪里迁移来,要迁移到哪里去?搞笑不就是这么简单……
此时,回到问题中,如果客户端请求的key刚好属于正在迁移的槽。那么接收到命令的节点首先会尝试在自己的数据库中查找键key,如果这个槽还没迁移完成,且当前key刚好也还没迁移完成,那就直接响应客户端的请求就行。如果该key已经不在了,此时节点会去查询migrating_slots_to数组对应的索引槽,如果索引处的值不为null,而是指向了某个clusterNode结构,那说明这个key已经被迁移到这个clusterNode了。这个时候节点不会继续在处理指令,而是返回ASKING命令,这个命令也会携带导入槽clusterNode对应的ip和port。客户端在接收到ASKING命令之后就需要将请求转向正确的节点了,不过这里有一点需要注意的地方。
前面说了,当节点发现当前槽不属于自己处理时会返回MOVED指令,那么在迁移中的槽时怎么处理的呢?这个Redis集群是这个玩的。
节点发现槽正在迁移则向客户端返回ASKING命令,客户端会接收到ASKING命令,其中包含了槽迁入的clusterNode的节点ip和port。那么客户端首先会向迁入的clusterNode发送一条ASKING命令,这个命令必须要发目的是告诉当前节点,你要破例处理这次请求,因为这个槽已经迁移到你这里了,你不能直接拒绝我(因此如果Redis未接收到ASKING命令,会直接查询节点的clusterState,而正在迁移中的槽还没有更新到clusterState中,那么只能直接返回MOVED,这样不就会一直循环很多次……),接收到ASKING命令的节点会强制执行一次这个请求(只执行一次,下次再来需要重新提前发送ASKING命令)。
Redis集群故障比较简单,这个和sentinel中主节点宕机或者在指定最长时间内未响应,重新在从节点中选举新的主节点的方式其实差不多。当然前提是Redis集群中的每个主节点,我们提前设置了从节点,要不就嘿嘿嘿……没戏。其大致步骤如下:
- 正常工作的集群,每个节点之间会定期向其他节点发送PING命令,如果接收命令的节点未在规定时间内返回PONG消息 ,当前节点会将接收命令的节点的clusterNode的flags设置为REDIS_NODE_PFAIL,PFAIL并不是下线,而是疑似下线。
- 集群节点会通过发送消息的方式来告知其他节点,集群中各个节点的状态信息
- 如果集群中半数以上负责处理槽的主节点都将某个主节点设置为疑似下线,那么这个节点将会被标记位下线状态,节点会将接收命令的节点的clusterNode的flags设置为REDIS_NODE_FAIL,FAIL表示已下线
- 集群节点通过发送消息的方式来告知其他节点,集群中各个节点的状态信息,此时下线节点的从节点在发现自己的主节点已经被标记为下线状态了,那么是时候挺身而出了
- 下线主节点的从节点,会选举出一个从节点作为最新的主节点,执行被选中的节点指向SLAVEOF no one成为新的主节点
- 新的主节点会撤销掉原主节点的槽指派,并将这些槽指派修改为自己,也就是修改clusterNode结构和clusterState结构
- 新的主节点向集群广播一条PONG指令,其他节点将会知道有新的主节点产生,并更新clusterNode结构和clusterState结构
- 新的主节点如果会向原主节点剩余的从节点发送新的SLAVEOF指令,使其成为自己的从节点
- 最后新的主节点将会负责原主节点的槽的响应工作
这里我写得非常模糊,如果需要细致挖掘的一定要看这篇文章:
REDIS cluster-spec -- Redis中文资料站 -- Redis中国用户组(CRUG)
或者可以看下黄健宏老师的《Redis设计与实现》这本书写得挺好,我也参考了很多内容。
CAP定理是分布式存储系统的基石,分布式系统(distributed system)指的是建立在网络上的软件系统,它是多个计算机节点通过协调工作的方式,共同完成任务的系统。分布式系统解决了单个计算机无法完成的计算和存储任务。但是分布式系统的设计十分复杂,设计者必定面临诸多挑战,比如节点故障、网络分区、异地网络等等问题。
上面有说到分布式系统,分布式和水平扩展等概念经常会一起出现,文中也通过阅读资料和自己的理解总结一下计算机系统超负荷时,常用的两种扩展解决手段。
垂直扩展(纵向扩展、向上扩展、Scale up):
指的是增加现有系统部件的内存、CPU等资源来提升系统的负荷能力。
水平扩展(横向扩展、向外扩展、Scale Out):
指的是在现有系统部件的基础上新增新的机器来提升系统的符合能力。
优缺点:
垂直扩展实现简单,但是机器的增加硬件资源仍然容易达到性能瓶颈,需要继续扩展。
水平扩展实现复杂,但是相比之下能带来系统的高可用、高吞吐量等优势。
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
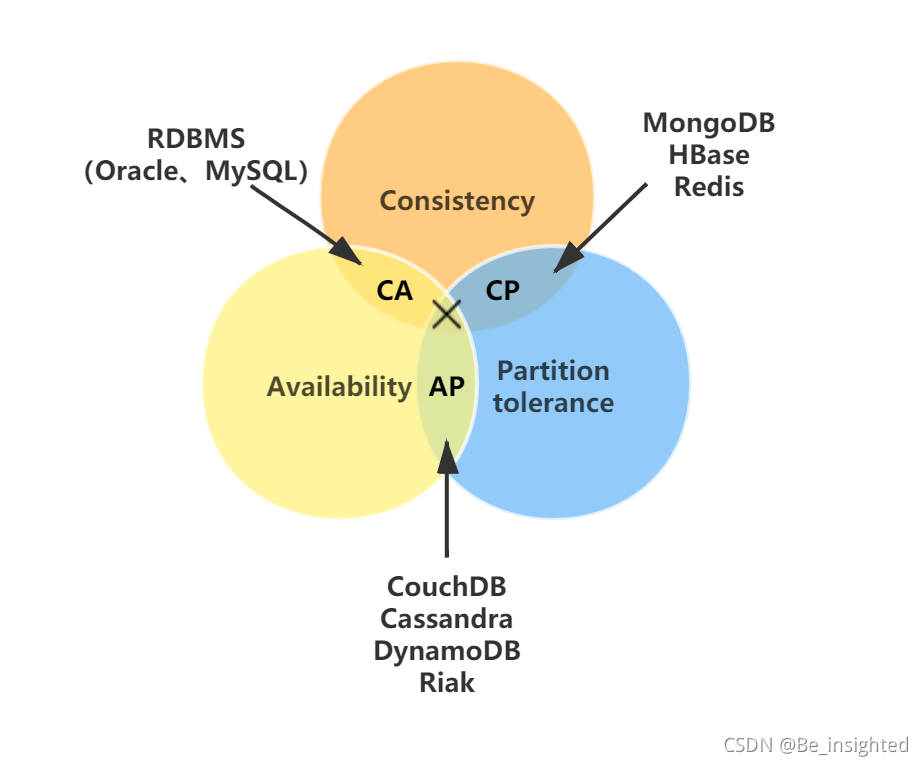
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):保证每个请求不管成功或者失败都有响应。
分区容错性(P):系统中任意信息的丢失或失败不会影响系统的继续运作。
上面有说到分布式系统建立在网络上,需要依靠网络来进行节点之间的通信,由于网络的不稳定性是必然存在的,这可能会导致节点网络断开,专业术语叫“网络分区”。
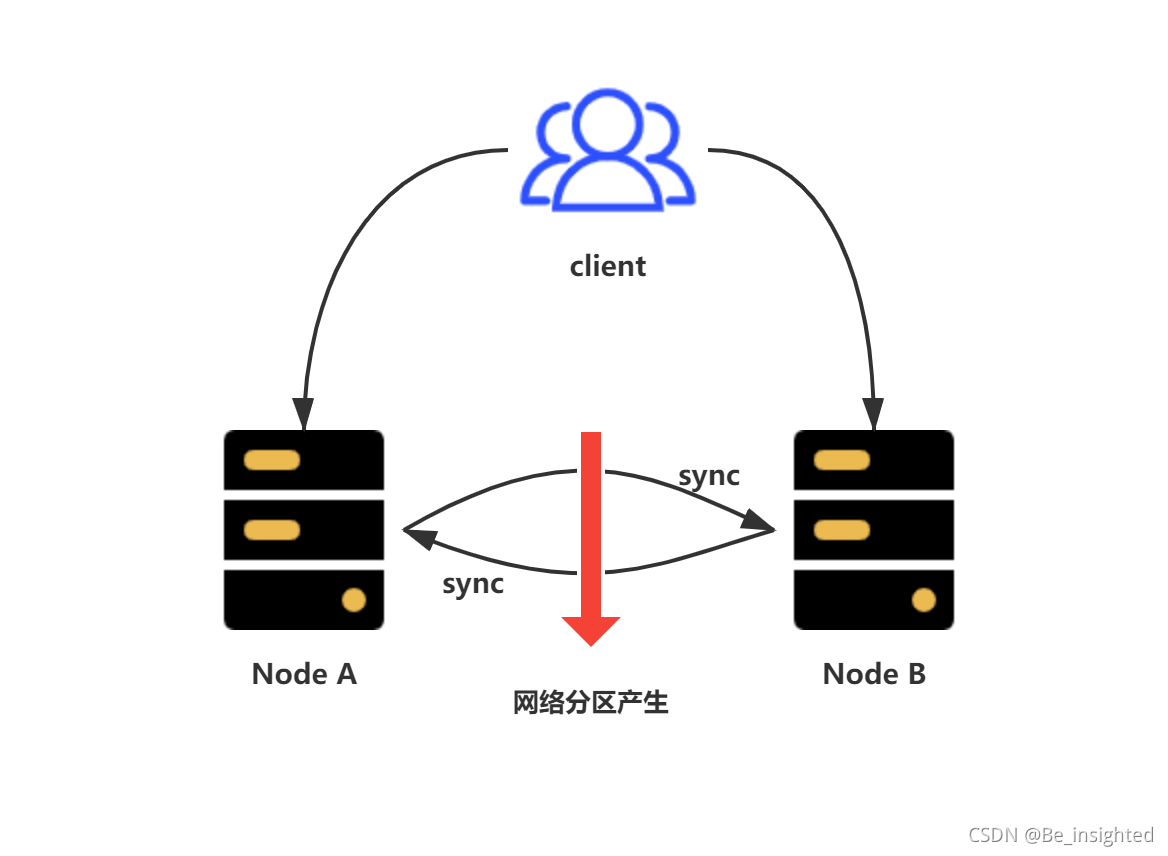
在上图中当网络分区产生的时候,分布式节点之间无法进行通信,数据无法及时同步,此时客户端对Node A节点数据的修改无法同步到Node B节点上,这会导致分布式系统中数据不一致,一致性(Consistency)将无法得到保证,如果此时要保证分布式系统中数据一致性,那么只能停止提供服务,等待节点网络恢复数据同步之后,在提供服务,但是这样系统就无法满足可用性(Availability)。
因此CAP原理可以这样简单的总结:当网络分区发生时,一致性和可用性不可兼得。
CAP理论应该如何取舍,CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。并且上面有分析在分布式系统中网络分区必然存在的问题,因此理论上CAP在分布式系统中只有CP和AP两种选择。
CP—不要求可用性(Availability),CP追求的是强一致性,每个服务器节点之间的数据必须保证完全一致,选择CP会导致系统在发生网络分区时,无法对外提供服务。CP强一致性的系统架构在银行转账系统中比较常见。Redis、HBase等数据库也是典型的强一致性分布式数据库。
AP—不要求一致性(Consistency),AP追求的是系统高可用,在网络分区发生时,分布式系统仍然能够提供服务,这会导致数据短暂的不一致性。AP高可用的系统架构在淘宝、京东等电商系统的秒杀活动中比较常见。
CA—不允许分区(Partition tolerance),这种情况不符合分布式系统架构,一般情况下都是Mysql、Oracle等RDBMS传统的关系型数据库。
关于CAP理论,其实比较简单,但是具体运用于分布式系统实现起来是非常复杂的。网上的文章非常多,我感觉其实只需要看下Robert Greiner的两篇文章就可以。
CAP Theorem: Explained
CAP Theorem: Revisited
分布式知识是考验一个程序员知识面广度和深度很好的度量标准,而分布式锁又是其中非常重要的一个知识点。可以说面试只要谈到分布式,没有不问分布式锁的。
我们知道分布式应用在进行逻辑处理的时候经常涉及到并发的问题,比如对一个转账修改一个用户的账户金额数据,此时可能会涉及多个用户同时对这个用户进行转账,它们都需要将数据读取到各内存中进行修改,然后再存刷新回去,这个时候就会出现并发问题:
这里假设初始account.money = 400
- 客户端A,向账户转账100,并未提交到Redis
- 客户端B,读取金额为400,并向账户转账200
- 客户端A提交
- 客户端B提交
最后account.money = 600
执行流程如下所示:
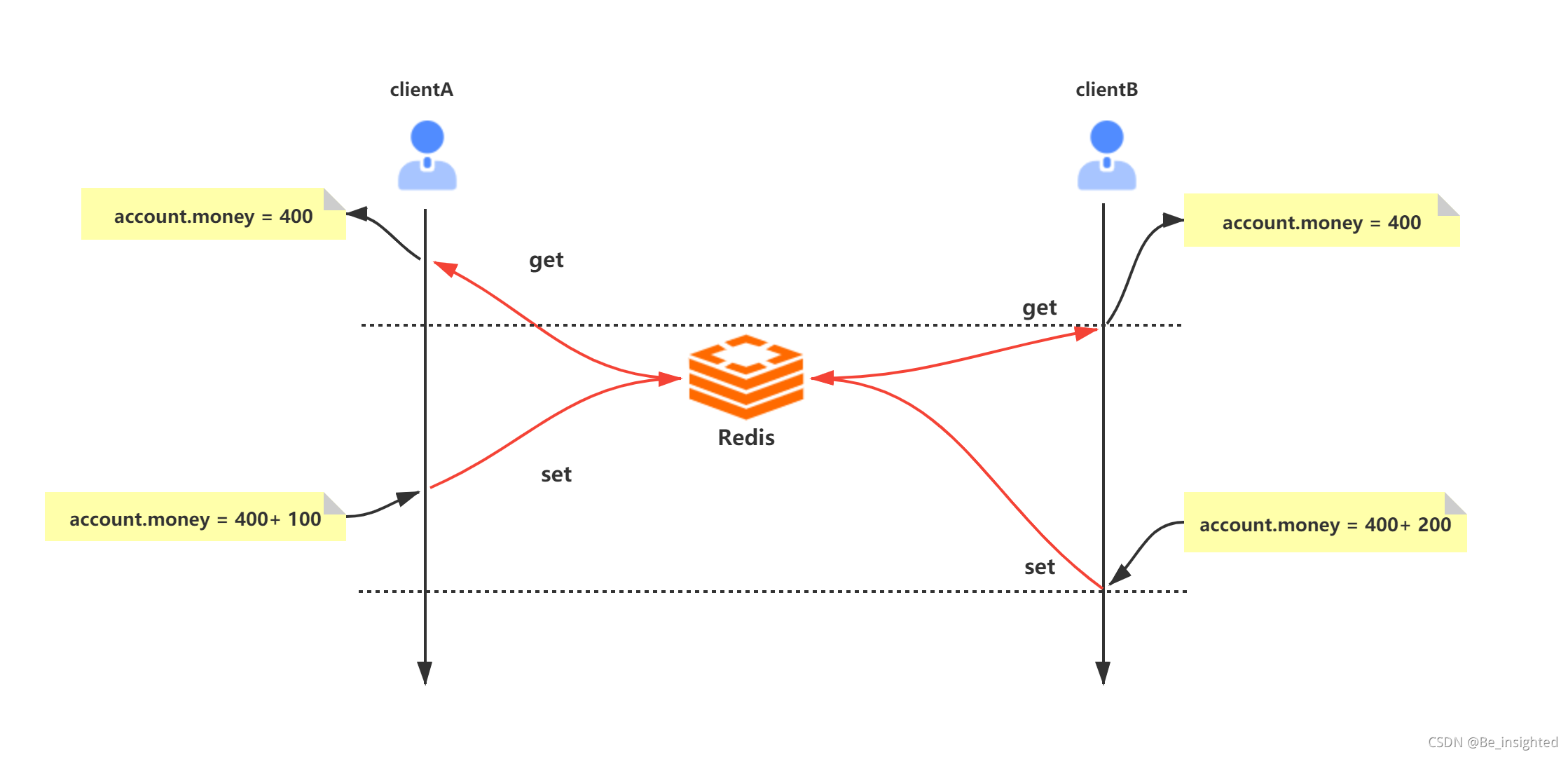
出现上述问题的主要原因是,“读取”和“写入”这两个操作并不是一个原子操作(所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程))。
关于上述问题的解决,分布式锁就可以派上用场了,我们通过分布式锁来限制程序的并发执行,就像Java中的synchronized,常见的分布式锁解决方案如下所示:
- 基于数据库锁机制实现的分布式锁
- 基于Zookeeper实现的分布式锁
- 基于Redis实现的分布式锁
本文和大家共同探讨的是基于Redis的分布式锁。
嗯……学过生物的宝宝们都知道,精细胞和卵细胞相遇的故事,上亿精细胞中最后也只会有一个幸运的精细胞和卵细胞发生甜蜜的爱情故事,这是因为当有一个精子进入卵子后,卵子会发生皮质反应、透明带反应使透明带对精子的结合能力下降,阻止了多精受精。分布式锁就好像卵细胞,而万千访问客户端就好比精细胞,无论客户访问并发多激烈,我们也应该保证分布式锁只被一个线程获取到。
12.2.2.1 setnx
我们将Redis实现分布式锁理解为上厕所蹲坑排队,只有一个坑,但是有多个人要到坑里面去,所以就只能一个一个的来了。
很多人一开始想到的是Redis中一般使用setnx(set if no exists)指令来实现,setnx是如果不存在,则 SET的简写,这个指令描述如下:
- 只在键 key 不存在的情况下,将键 key 的值设置为 value 。
- 若键 key 已经存在, 则 SETNX 命令不做任何动作。
- 127.0.0.1:6379> exists lock # lock key不存在
- (integer) 0
- 127.0.0.1:6379> setnx lock true # 设值成功
- (integer) 1
- 127.0.0.1:6379> setnx lock false # 覆盖失败
- (integer) 0
- 127.0.0.1:6379> del lock # 删除lock 释放
- (integer) 1
如上这种方案存在的问题非常明显,如果逻辑执行过程中间出现了异常,可能导致del key 指令没有执行,这样会产生死锁。如下图所示:
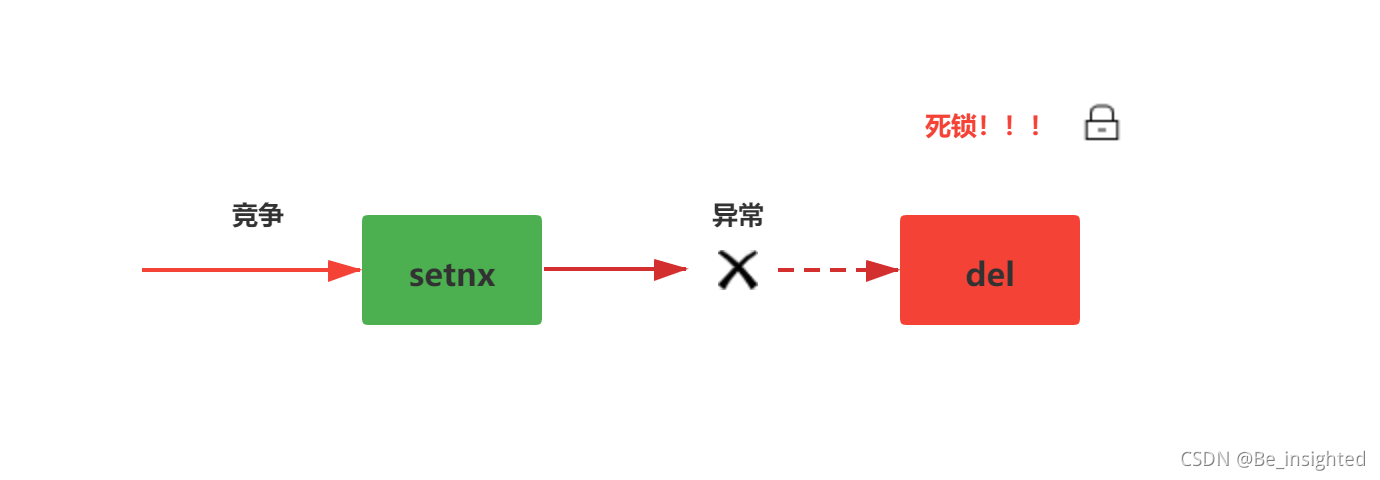
12.2.2.2 setnx + expire
在第一种解决方案的基础上,可能部分人会相到,既然主动删除key可能会出现异常情况,那么就设值key的过期时间到期自动删除。
- 127.0.0.1:6379> setnx lock true
- (integer) 1
- 127.0.0.1:6379> expire lock 10 # 设值过期时间10s
- (integer) 1
- 127.0.0.1:6379> setnx lock true # 10s内再次设值失败
- (integer) 0
- 127.0.0.1:6379> setnx lock true # 10skey过期,后设置成功
- (integer) 1
这种的方案和前面的方案其实并没有本质上的区别,它还是可能会出现服务器异常等情况,导致expire的不到执行的情况,换汤不换药,如下图所示:
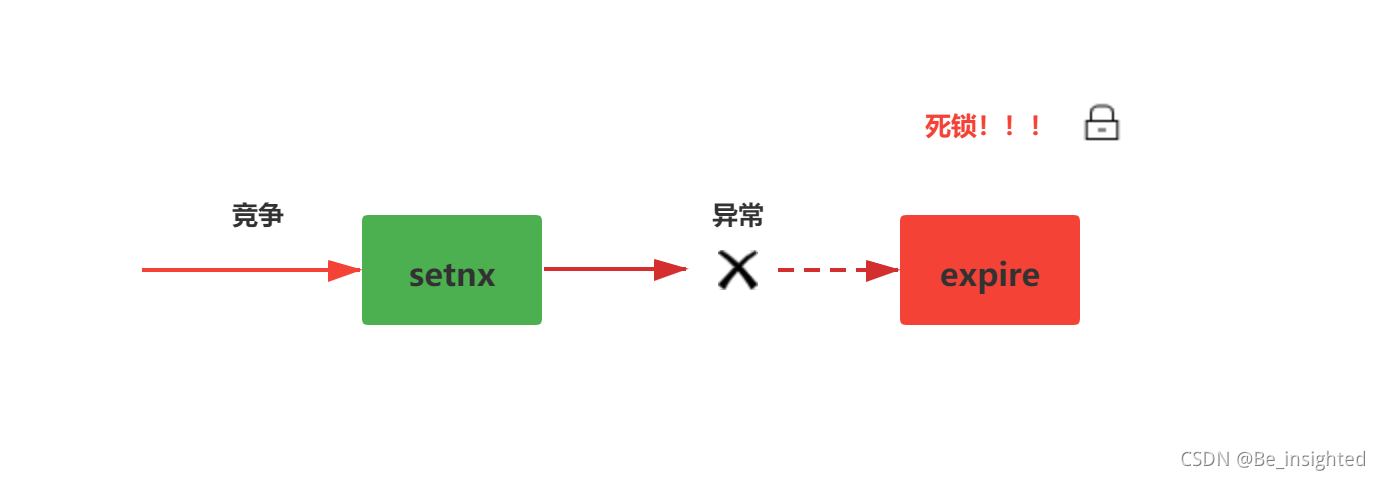
12.2.2.3 原子操作
基于上面两种方案,我们可以发现,产生问题的本质在于两个操作并不是原子操作。方案一中是setnx指令加一个del指令,方案二中是setnx指令加一个expire指令,这两个指令并不是原子指令。基于这个问题,Redis官方将这两个指令组合在了一起,解决Redis分布式锁原子性操作的问题。
先认真看set指令可选参数 EX 和 NX
set key value [EX seconds] [PX milliseconds] [NX|XX]
**EX **seconds :将键的过期时间设置为 seconds 秒。执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
PX milliseconds :将键的过期时间设置为 milliseconds 毫秒。执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
**NX **:只在键不存在时,才对键进行设置操作。执行 SET key value NX 的效果等同于执行 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。
- 127.0.0.1:6379> set lock true EX 10 NX # 设置 10s生效
- OK
- 127.0.0.1:6379> set lock true EX 10 NX # 10s内再次设值失败
- (nil)
- 127.0.0.1:6379> set lock true EX 10 NX # 10s后设置成功
- OK
如上这个操作就成功的解决了Redis分布式锁的原子操作问题。
12.2.2.4 解锁
Redis分布式锁加锁在上面讲述了,而Redis分布式锁的解锁过程其实就是将key删除,key的删除有客户端调用del指令删除,也有设置key的过期时间自动删除。但是这个删除不能乱删除,不能说客户端A请求的锁被客户端B给删除了……,那这把锁就是一把烂锁了。
为了防止客户端A请求的锁被客户端B给删除了这种情况,我们通过匹配客户端传入的锁的值与当前锁的值是否相等来做判断(这个值是随机且保证不会重复的),如果相等就删除,解锁成功。
但是Redis并未提供这样的功能,我们只能通过Lua脚本来处理,因为Lua脚本可以保证多个指令的原子性执行。
示例:
首先设置一个key,这个key的值是123456789,通过客户端传入的value值是否相等来校验是否允许删除这个key
- 127.0.0.1:6379> get lock
- (nil)
- 127.0.0.1:6379> set lock 123456789 # 设置一个key 值为123456789
- OK
- 127.0.0.1:6379> get lock
- "123456789"
在客户机上编写lua脚本,lock.lua文件,文件内容如下
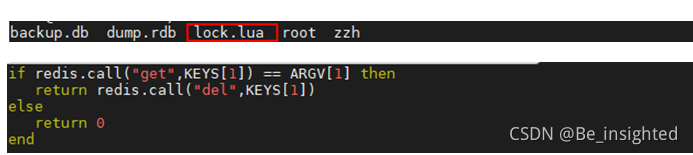
- if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
- else
- return 0
- end
测试通过错误的value值去执行lua脚本,这个时候删除key失败,返回0

通过正确的value值执行则返回1,说明key被删除了。

12.2.2.5 代码实现
一下演示一个spring boot项目来实现Redis分布式锁,为了方便大家使用,我贴出的代码比较全面,篇幅稍多。
pom依赖
- <parent>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-parent</artifactId>
- <version>2.3.4.RELEASE</version>
- </parent>
- <dependencies>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- </dependency>
- <dependency>
- <groupId>redis.clients</groupId>
- <artifactId>jedis</artifactId>
- <version>3.0.1</version>
- </dependency>
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- </dependency>
- <dependency>
- <groupId>cn.hutool</groupId>
- <artifactId>hutool-all</artifactId>
- <version>5.3.4</version>
- </dependency>
- </dependencies>
Redis配置文件
- package com.lizba.config;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import org.springframework.beans.factory.annotation.Value;
- import org.springframework.cache.annotation.CachingConfigurerSupport;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- import redis.clients.jedis.JedisPool;
- import redis.clients.jedis.JedisPoolConfig;
- /**
- * <p>
- * Redis简单配置文件
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/7/11 11:17
- */
- @Configuration
- public class RedisConfig extends CachingConfigurerSupport {
- protected static final Logger logger = LoggerFactory.getLogger(RedisConfig.class);
- @Value("${spring.redis.host}")
- private String host;
- @Value("${spring.redis.port}")
- private int port;
- @Value("${spring.redis.jedis.pool.max-active}")
- private int maxTotal;
- @Value("${spring.redis.jedis.pool.max-idle}")
- private int maxIdle;
- @Value("${spring.redis.jedis.pool.min-idle}")
- private int minIdle;
- @Value("${spring.redis.password}")
- private String password;
- @Value("${spring.redis.timeout}")
- private int timeout;
- @Bean
- public JedisPool redisPoolFactory() {
- JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
- jedisPoolConfig.setMaxTotal(maxTotal);
- jedisPoolConfig.setMaxIdle(maxIdle);
- jedisPoolConfig.setMinIdle(minIdle);
- JedisPool jedisPool = new JedisPool(jedisPoolConfig, host, port, timeout, null);
- logger.info("JedisPool注入成功!!");
- logger.info("redis地址:" + host + ":" + port);
- return jedisPool;
- }
- }
application.yml配置文件
- server:
- port: 18080
- spring:
- redis:
- database: 0
- host: 127.0.0.1
- port: 6379
- timeout: 10000
- password:
- jedis:
- pool:
- max-active: 20
- max-idle: 20
- min-idle: 0
获取锁与释放锁代码
- package com.lizba.utill;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.stereotype.Service;
- import redis.clients.jedis.Jedis;
- import redis.clients.jedis.JedisPool;
- import redis.clients.jedis.params.SetParams;
- import java.util.Arrays;
- import java.util.concurrent.TimeUnit;
- /**
- * <p>
- * Redis分布式锁简单工具类
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/7/11 11:42
- */
- @Service
- public class RedisLockUtil {
- private static Logger logger = LoggerFactory.getLogger(RedisLockUtil.class);
- /**
- * 锁键 -> key
- */
- private final String LOCK_KEY = "lock_key";
- /**
- * 锁过期时间 -> TTL
- */
- private Long millisecondsToExpire = 10000L;
- /**
- * 获取锁超时时间 -> get lock timeout for return
- */
- private Long timeout = 300L;
- /**
- * LUA脚本 -> 分布式锁解锁原子操作脚本
- */
- private static final String LUA_SCRIPT =
- "if redis.call('get',KEYS[1]) == ARGV[1] then" +
- " return redis.call('del',KEYS[1]) " +
- "else" +
- " return 0 " +
- "end";
- /**
- * set命令参数
- */
- private SetParams params = SetParams.setParams().nx().px(millisecondsToExpire);
- @Autowired
- private JedisPool jedisPool;
- /**
- * 加锁 -> 超时锁
- *
- * @param lockId 一个随机的不重复id -> 区分不同客户端
- * @return
- */
- public boolean timeLock(String lockId) {
- Jedis client = jedisPool.getResource();
- long start = System.currentTimeMillis();
- try {
- for(;;) {
- String lock = client.set(LOCK_KEY, lockId, params);
- if ("OK".equalsIgnoreCase(lock)) {
- return Boolean.TRUE;
- }
- // sleep -> 获取失败暂时让出CPU资源
- TimeUnit.MILLISECONDS.sleep(100);
- long time = System.currentTimeMillis() - start;
- if (time >= timeout) {
- return Boolean.FALSE;
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- logger.error(e.getMessage());
- } finally {
- client.close();
- }
- return Boolean.FALSE;
- }
- /**
- * 解锁
- *
- * @param lockId 一个随机的不重复id -> 区分不同客户端
- * @return
- */
- public boolean unlock(String lockId) {
- Jedis client = jedisPool.getResource();
- try {
- Object result = client.eval(LUA_SCRIPT, Arrays.asList(LOCK_KEY), Arrays.asList(lockId));
- if (result != null && "1".equalsIgnoreCase(result.toString())) {
- return Boolean.TRUE;
- }
- return Boolean.FALSE;
- } catch (Exception e) {
- e.printStackTrace();
- logger.error(e.getMessage());
- }
- return Boolean.FALSE;
- }
- }
测试类
- package com.lizba.controller;
- import cn.hutool.core.util.IdUtil;
- import com.lizba.utill.RedisLockUtil;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.web.bind.annotation.GetMapping;
- import org.springframework.web.bind.annotation.PathVariable;
- import org.springframework.web.bind.annotation.RequestMapping;
- import org.springframework.web.bind.annotation.RestController;
- import java.util.HashSet;
- import java.util.Set;
- import java.util.concurrent.CountDownLatch;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- import java.util.concurrent.atomic.AtomicInteger;
- /**
- * <p>
- * 测试
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/7/11 12:27
- */
- @RestController
- @RequestMapping("/redis")
- public class TestController {
- @Autowired
- private RedisLockUtil redisLockUtil;
- private AtomicInteger count ;
- @GetMapping("/index/{num}")
- public String index(@PathVariable int num) throws InterruptedException {
- count = new AtomicInteger(0);
- CountDownLatch countDownLatch = new CountDownLatch(num);
- ExecutorService executorService = Executors.newFixedThreadPool(num);
- Set<String> failSet = new HashSet<>();
- long start = System.currentTimeMillis();
- for (int i = 0; i < num; i++) {
- executorService.execute(() -> {
- long lockId = IdUtil.getSnowflake(1, 1).nextId();
- try {
- boolean isSuccess = redisLockUtil.timeLock(String.valueOf(lockId));
- if (isSuccess) {
- count.addAndGet(1);
- System.out.println(Thread.currentThread().getName() + " lock success" );
- } else {
- failSet.add(Thread.currentThread().getName());
- }
- } finally {
- boolean unlock = redisLockUtil.unlock(String.valueOf(lockId));
- if (unlock) {
- System.out.println(Thread.currentThread().getName() + " unlock success" );
- }
- }
- countDownLatch.countDown();
- });
- }
- countDownLatch.await();
- executorService.shutdownNow();
- failSet.forEach(t -> System.out.println(t + " lock fail" ));
- long time = System.currentTimeMillis() - start;
- return String.format("Thread sum: %d, Time sum: %d, Success sum:%d", num, time, count.get());
- }
- }
测试结果

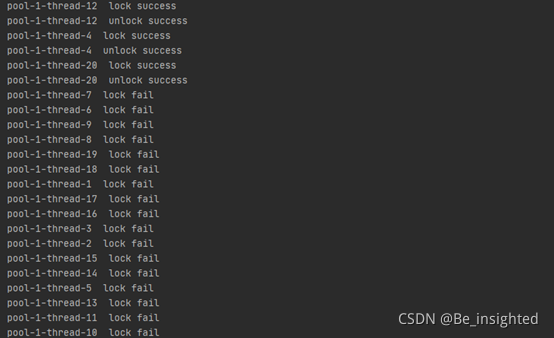
Redis分布式锁有一个问题是锁的超时问题,也就是说如果客户端A获取到锁之后去执行任务,任务没跑完锁的超时时间到了,锁就会自动释放,这个时候客户端B就能乘虚而入了,锁就会出现问题!
关于这个问题其实并没有完全的解决办法,但是能通过如下手段去优化:
- 尽可能不要在Redis分布式锁中执行较长的任务,尽可能的缩小锁区间内执行代码,就像单JVM锁中的synchronized优化一样,我们可以考虑优化锁的区间
- 多做压力测试和线上真实场景的模拟测试,估算一个合适的锁超时时间
- 做好Redis分布式锁超时任务未执行完的问题发生后,数据恢复手段的准备
上述的分布式锁,针对单节点实例的Redis是可行的;但是我们在公司根本不会用单节点的Redis实例,往往采用最简单的都是是Redis一主二从+Sentinel监控配置;在sentinel集群中,虽然主节点挂掉时,从节点会取而代之,客户端无感知,但是上述的分布式锁就可能存在节点之间数据同步异常导致分布式锁失效的问题。
正常情况下客户端向sentinel监控的Redis集群申请分布式锁:
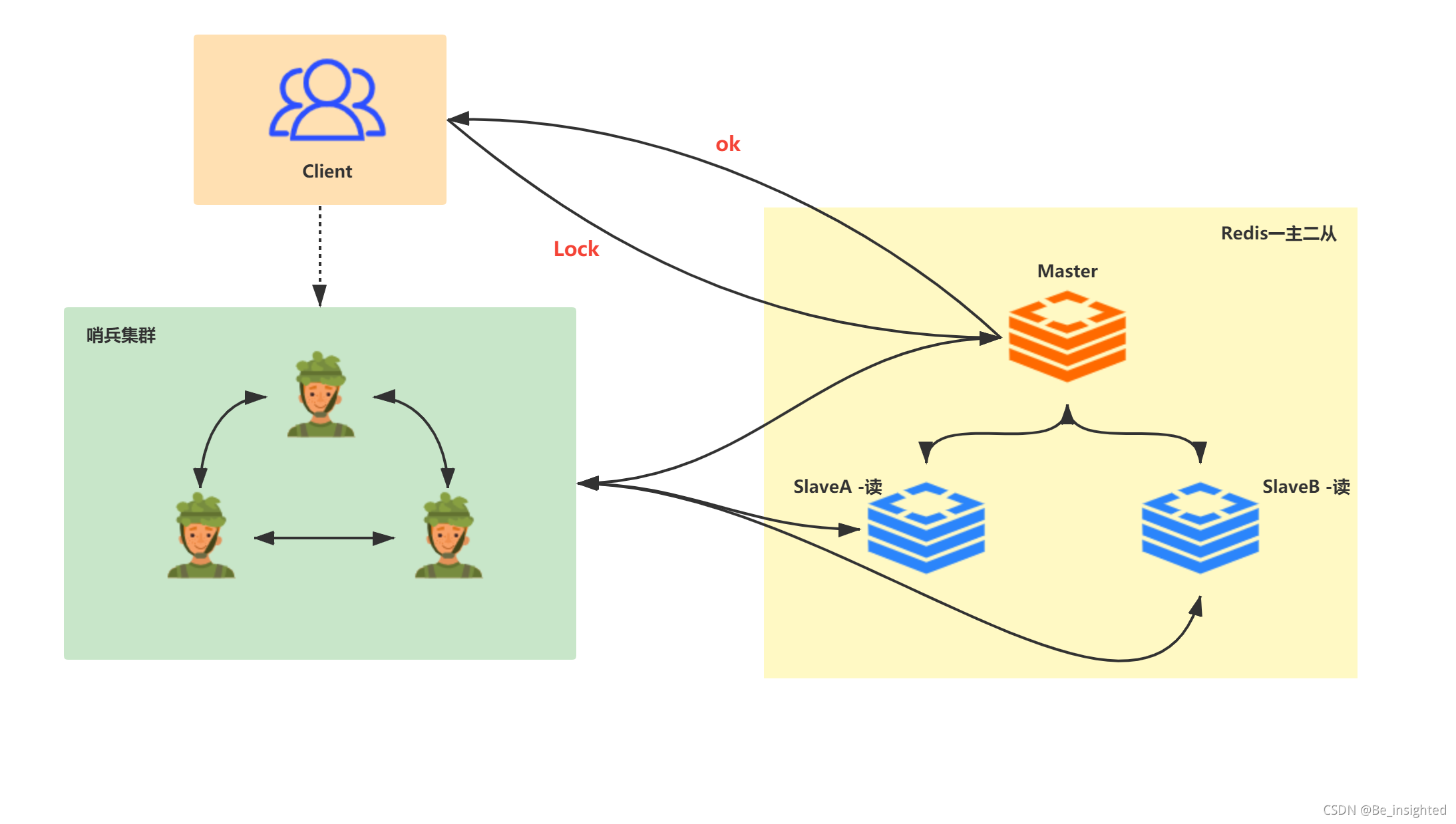
比如,客户端A在主节点(机器1)上申请了一把锁,此时主节点(机器1)挂掉了且锁没来得及同步到从节点(机器2和机器3),此时从节点(机器2)成为了新的主节点,但是锁在新的主节点(机器2)上并不存在,所以客户端B申请锁成功,锁的定义在这种场景中就出现了问题!
主节点宕机锁同步失败情况,其他客户端申请锁成功:
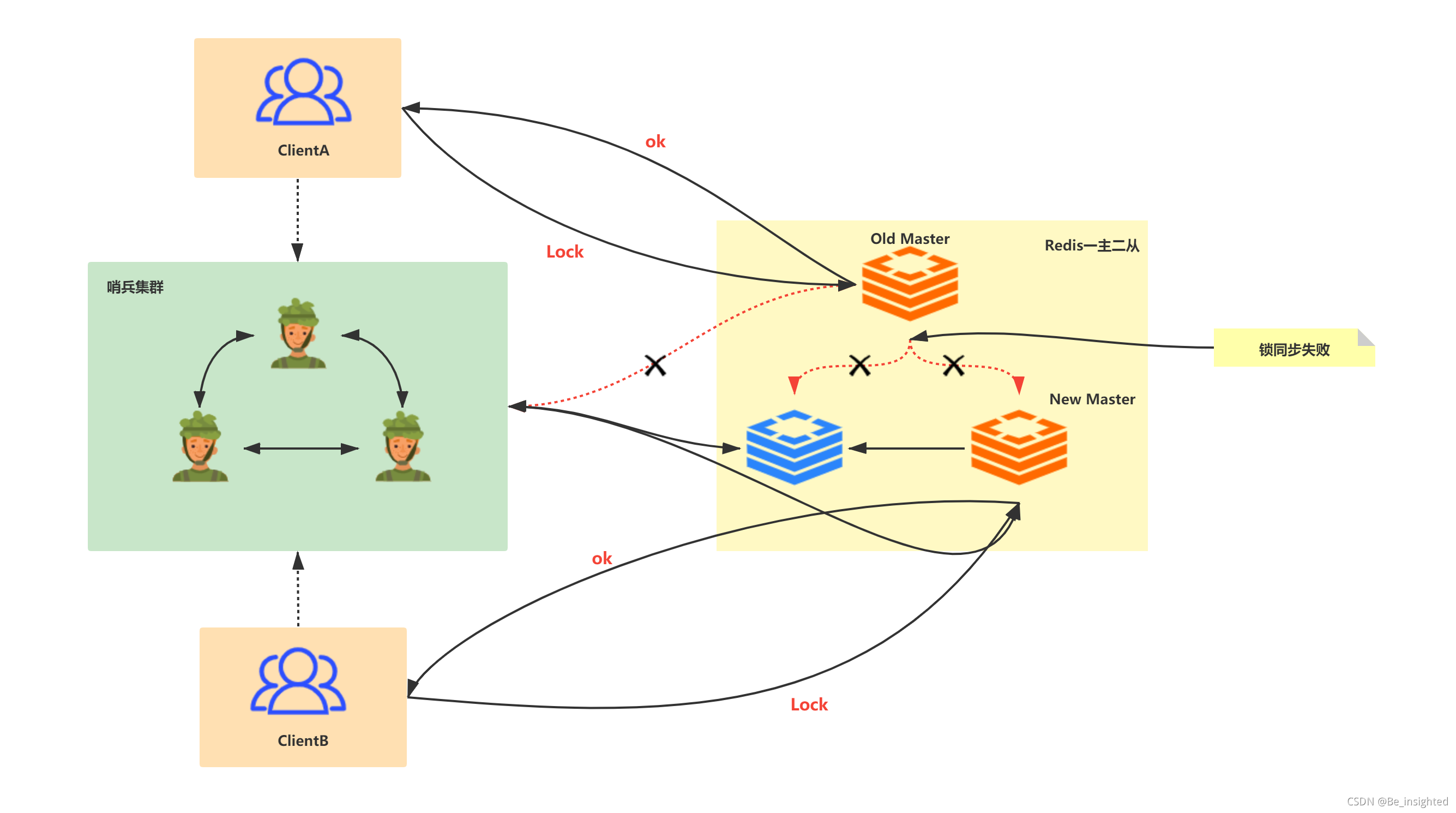
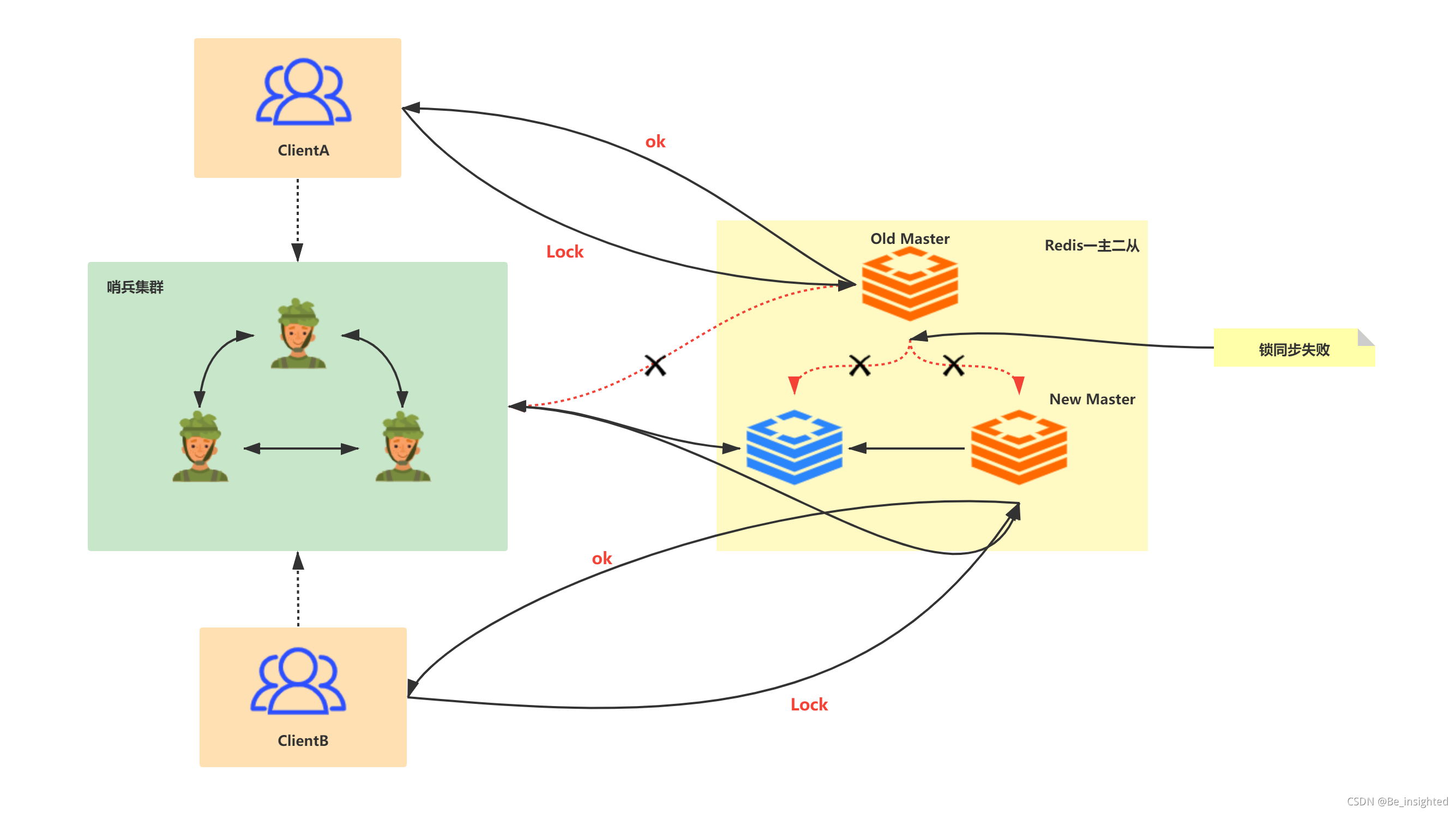
上述这种情况虽然之后发生在主从发生failover的情况才产生,但显然是不安全的,普通的业务系统或许能接受,但大金额的业务场景是不允许出现的。
12.3.2.1 简介
解决这个问题的办法就是使用RedLock算法,也称红锁。RedLock通过使用多个Redis实例,各个实例之间没有主从关系,相互独立;加锁的时候,客户端向所有的节点发送加锁指令,如果过半的节点set成功,就加锁成功。释放锁时,需要向所有的节点发送del指令来释放锁。RedLock的实现思路比较简单,但是实际算法比较复杂,需要考虑非常多的细节问题,如出错重试,时钟漂移等。此外RedLock需要新增较多的实例来申请分布式锁,不仅消耗服务器资源,也会有一定的性能下降。
其架构图如下,客户端向多个独立的Redis服务发送加锁指令(为了追求高吞吐量和低延时,客户端需要使用多路传输来对N个Redis Server服务器进行通信),过半反馈成功则加锁成功,Redis Server的个数最后为奇数。
Redis 中文版网站介绍
REDIS distlock -- Redis中国用户组(CRUG)
在上述的架构图中,存在5台Redis服务器用于获取锁,那么此时一个客户端获取锁需要做哪些操作呢?
- 获取系统当前时间(ms)
- 使用相同的key和随机值在5个节点上请求锁,请求锁的过程中包含多个时间值的定义,包括请求单个锁超时时间,请求锁的总耗时时间,锁自动释放时间。单个锁请求的超时时间不宜过大,防止请求宕机的Redis服务阻塞时间过长。
- 客户端计算获取锁的总时长和获取锁成功的个数,当所得个数大于等于3且获取锁的时间小于锁的自动释放时间才算成功
- 锁获取成功,则锁自动释放时间等于TTL减去获取所得消耗的时间(这个锁消耗的时间计算比较复杂)
- 锁获取失败,向所有的Redis服务器发送删除指令,一定是所有的Redis服务器都要发送
- 失败重试,锁获取失败后进行重试,重试的时间应该是一个随机值,避免与其他客户端同时请求锁而加大失败的可能,且这个时间应该大于获取锁消耗的时间
12.3.2.2 锁的最小有效时长
由于上面说到存在时钟漂移的问题,并且客户端向不同的Redis服务器请求锁的时间也会有细微的差异,所以有必要认真的研究一下客户端获取到的锁的最小有效时长计算:
假设客户端申请锁成功,第一个key设置成功的时间为TF,最后一个key设置成功的时间为TL,锁的超时时间为TTL,不同进程之间的时钟差异为CLOCK_DIFF,则锁的最小有效时长是:
TIME = TTL - (TF- TL) - CLOCK_DIFF
12.3.2.3 故障恢复
采用Redis来实现分布式锁,离不开服务器宕机等不可用问题,这里RedLock红锁也一样,即使是多台服务器申请锁,我们也要考虑服务器宕机后的处理,官方建议采用AOF持久化处理。
但是AOF持久化只对正常SHUTDOWN这种指令能做到重启恢复,但是如果是断电的情况,可能导致最后一次持久化到断电期间的锁数据丢失,当服务器重启后,可能会出现分布式锁语义错误的情况。所以为了规避这种情况,官方建议Redis服务重启后,一个最大客户端TTL时间内该Redis服务不可用(不提供申请锁的服务),这确实可以解决问题,但是显而易见这肯定影响Redis服务器的性能,并且在多数节点都出现这种情况的时候,系统将出现全局不可用的状态。
12.3.3.1 Redission简介
Redisson是架设在Redis基础上的一个Java驻内存数据网格(In-Memory Data Grid)。【Redis官方推荐】
Redisson在基于NIO的Netty框架上,充分的利用了Redis键值数据库提供的一系列优势,在Java实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
Redission github地址
Redission 分布式锁和同步器Wiki
8. 分布式锁和同步器 · redisson/redisson Wiki · GitHub
总而言之——Redisson非常强大
12.3.3.2 Reddison之RedLock使用
pom依赖
- <dependency>
- <groupId>org.redisson</groupId>
- <artifactId>redisson</artifactId>
- <version>3.3.2</version>
- </dependency>
测试类
- package com.liziba.util;
- import org.redisson.Redisson;
- import org.redisson.RedissonRedLock;
- import org.redisson.api.RLock;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.Config;
- import java.util.concurrent.TimeUnit;
- /**
- * <p>
- * 测试Redisson 之 RedLock
- * </p>
- *
- * @Author: Liziba
- * @Date: 2021/7/11 20:55
- */
- public class LockTest {
- private static final String resourceName = "REDLOCK_KEY";
- private static RedissonClient cli_79;
- private static RedissonClient cli_89;
- private static RedissonClient cli_99;
- static {
- Config config_79 = new Config();
- config_79.useSingleServer()
- .setAddress("127.0.0.1:6379") // 注意这里我的Redis测试实例没密码
- .setDatabase(0);
- cli_79 = Redisson.create(config_79);
- Config config_89 = new Config();
- config_89.useSingleServer()
- .setAddress("127.0.0.1:6389")
- .setDatabase(0);
- cli_89 = Redisson.create(config_89);
- Config config_99 = new Config();
- config_99.useSingleServer()
- .setAddress("127.0.0.1:6399")
- .setDatabase(0);
- cli_99 = Redisson.create(config_99);
- }
- /**
- * 加锁操作
- */
- private static void lock () {
- // 向3个Redis实例尝试加锁
- RLock lock_79 = cli_79.getLock(resourceName);
- RLock lock_89 = cli_89.getLock(resourceName);
- RLock lock_99 = cli_99.getLock(resourceName);
- RedissonRedLock redLock = new RedissonRedLock(lock_79, lock_89, lock_99);
- try {
- boolean isLock = redLock.tryLock(100, 10000, TimeUnit.MILLISECONDS);
- if (isLock) {
- // do something ...
- System.out.println(Thread.currentThread().getName() + "Get Lock Success!");
- TimeUnit.MILLISECONDS.sleep(10000);
- } else {
- System.out.println(Thread.currentThread().getName() + "Get Lock fail!");
- }
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- // 无论如何一定要释放锁 -> 这里会像所有的Redis服务释放锁
- redLock.unlock();
- }
- }
- public static void main(String[] args) {
- for (int i = 0; i < 10; i++) {
- new Thread(() -> lock()).start();
- }
- }
- }


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









