







 这篇博客梳理了编译原理的关键知识点,包括编译程序结构、文法类型、正规式与DFA转换、语法分析方法(LL(1)、LR方法)、语法制导翻译、优化技术如DAG算法、以及目标代码生成。还详细介绍了NFA到DFA的转换步骤,并给出了消除左递归和构造LL(1)分析表的实例。
这篇博客梳理了编译原理的关键知识点,包括编译程序结构、文法类型、正规式与DFA转换、语法分析方法(LL(1)、LR方法)、语法制导翻译、优化技术如DAG算法、以及目标代码生成。还详细介绍了NFA到DFA的转换步骤,并给出了消除左递归和构造LL(1)分析表的实例。
小崔考点记录:
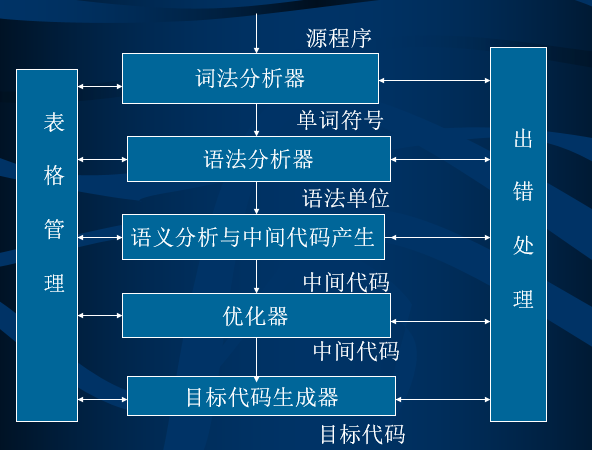
1、编译程序总框图 前端 后端
2、文法产生句型 推导 文法四种形式 会写简单文法(三型、二型)
3、正规式->NFA->DFA(不要忘记化简DFA)
4、5、语法分析:自上而下->递归、预测分析、LL(1):消除左递归、消除回溯、FIRST、FOLLOW、预测分析表
自下而上->句柄概念 LR方法: LR(0),LR(1),SLR(1),LALR,二义文法
6、S属性文法,L属性文法 概念
7、什么是中间代码?哪几种?优缺点
语法制导翻译成中间代码(独立的四元式表,语法分析过程的描述,遗留问题存于nextlist?)
8、活动记录 参数传递
优化:局部、循环、全局
DAG算法(局部优化)
无用赋值
从右向左运算效率高 注意活跃信息
目标代码的生成:目标代码生成算法 待用信息 活跃信息 地址描述 寄存器信息 块与块之间(寄存器不能传值)
编译程序总框图:
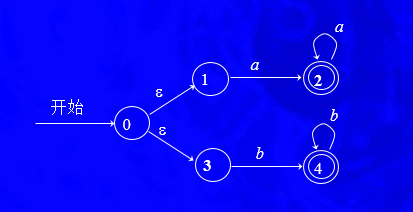
NFA
1. (a|b)*ab的NFA

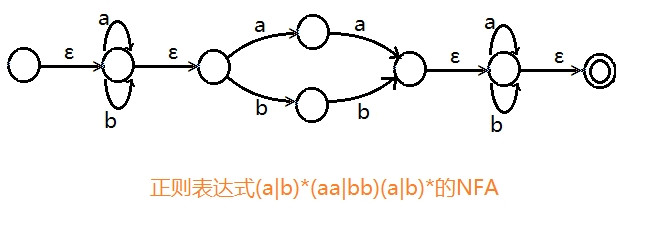
3.
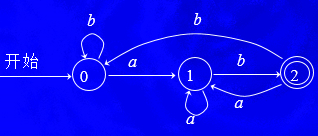
DFA
1. (a|b)*ab的DFA ?
NFA到DFA的变换
从NFA构造等价的DFA的一般思想是让新构造的DFA的每个状态代表NFA的一个状态集,这个DFA用它的状态去记住该NFA在读入符号后能到达的所有状态。
1、


2、一篇很详细讲解NFA如何转化DFA的CSDN博客:http://blog.csdn.net/lovesummerforever/article/details/9060887
3、[例子] 构造下列正规式相应的最简DFA。
(a|b)*a(a|b)
解:(1)由正规式到NFA

(2)
| a | b | |
| {0} | {0,1} | {0} |
| {0,1} | {0,1,2} | {0,2} |
| {0,1,2} | {0,1,2} | {0,2} |
| {0,2} | {0,1} | {0} |
生成此表的方法:初始为{0},因为0和1之间就需要a了。{0}和a结合能到达0和1,所以在<{0}, a>处填{0, 1},同理,对于{0, 1, 2}和a结合(0,1,2分别和a结合)能到达0,1,2,所以在<{0,1,2}, a>处填{0,1,2},而{0, 1, 2}和b结合,0与b结合到达0,1与b结合到达2,2与b结合到达空,所以在<{0,1,2}, b>处填{0,2}。
(3)

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









