







统一寻址(Unified Memory):
可直接访问CPU内存、GPU显存,不需要手动拷贝数据。
CUDA 6在现有的内存池结构上增加了一个统一内存系统,程序员可以直接访问任何内存/显存资源,或者在合法的内存空间内寻址,而不用管涉及到的到底是内存还是显存。
CUDA 6的数据拷贝由程序员的手动转移,变成自动执行,因此,它仍然受制于PCI-E的带宽和延迟。
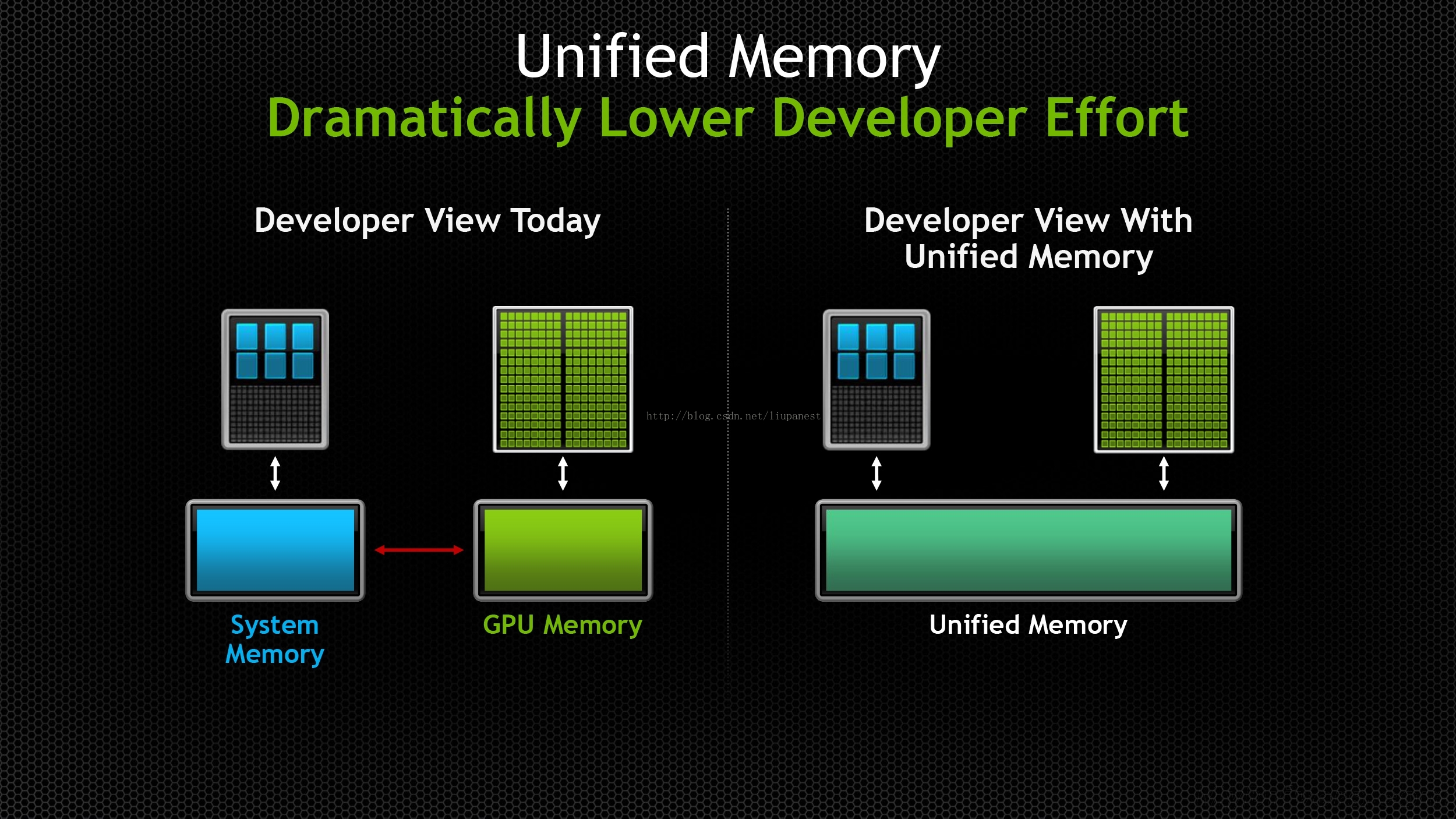
NVIDIA的统一内存寻址

上面这段代码显示了“统一寻址”的一个例子。两段代码都从磁盘中载入文件,并对文件中数据进行排序操作。它们仅有的不同在于,GPU的版本启动的kernel函数(并在启动后进行了同步的操作),在统一寻址中使用新的API cudaMallocManaged()对载入文件分配内存。
我们仅仅只分配一次内存,这个数据指针对于host端和device端都是可用的。我们可以直接从文件中读取数据到这片内存,并将指针直接传入CUDA核函数。
kernel函数执行完后,我们可以直接从CPU端获取数据。CUDA的运行环境隐藏了所有的复杂性,自动将数据转移到需要的地方。而统一寻址的最大优势就是避免了人为的数据
拷贝,为什么说人为呢,是因为即使是统一寻址也是要进行数据拷贝的,只不过现在这一部分有程序自动完成,而不用程序员操心了。因此,统一寻址后程序的执行效率并不会
显著改善,仅仅是为了方便而已。
使用统一寻址需要满足三个要求:
‣ Kepler 架构或者是最新架构的GPU,并且计算能力至少是3.0
‣ 64位的系统,64位的应用
‣ linux 或 Windows
例:减少深度复制
统一寻址的关键在于通过减少GPU kernel函数获取数据使深度复制的需求,简化异构计算内存模型。从CPU到GPU传递数据结构和指针需要深度复制。如下图:
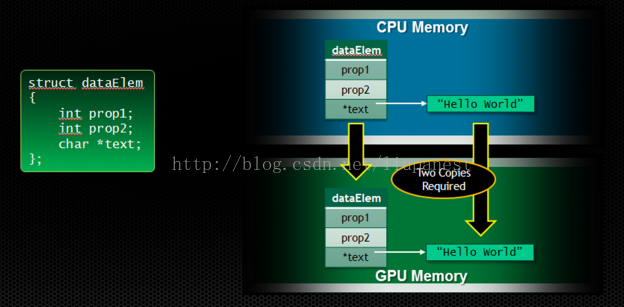
以下面这个结构体dataElem为例
- <pre name="code" class="plain">struct dataElem {
- int prop1;
- int prop2;
- char *name;
- }
- <pre name="code" class="plain">void launch(dataElem *elem) {
- dataElem *d_elem;
- char *d_name;
- int namelen = strlen(elem->name)+1;
- //Allocate storage for struct and name
- cudaMalloc(&d_elem, sizeof(dataElem));
- cudaMalloc(&d_name, namelen);
- //Copy up each piece separately, including new "name" pointer value
- cudaMemcpy(d_name, elem, sizeof(dataElem), cudaMemcpyHostToDevice);
- cudaMemcpy(d_name, elem-<name, namelen, cudaMemcpyHostToDevice);
- cudaMemcpy(&(d_elem->name), &d_name, sizeof(char*), cudaMemcpyHostToDevice);
- //Finally we can launch our kernel, but CPU & GPU use differernt copies of "elem"
- Kernel<<<...>>>(d_elem);
- }
- <pre name="code" class="plain">void launch(dataElem *elem) {
- Kernel<<<...>>>(elem);
- }
例:CPU/GPU共享链表
链表是非常常用的数据结构,但是由于它本质上是有指针组成的嵌套的数据结构,使得内存空间的传递非常复杂。没有统一寻址,CPU和GPU间的链表的共享是不易管理的。唯一的选择是在Zero-copy memory(pinned host memory)中分配内存,这意味着GPU端数据获取受制于PCI-express的性能。通过在Unified memory中分配链表数据,设备端可以在GPU上可以以设备端最好的性能正常的跟踪指针。这个程序可以保证一个单链表,链表中的元素可以从设备端或主机端增加或删除。
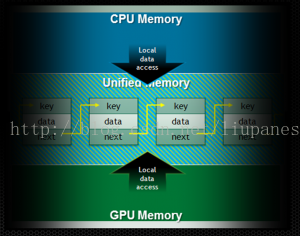
把代码中复杂的数据结构移植到GPU原本是件令人生畏的事,但是统一寻址使它变得简单。
C++统一寻址
统一寻址在C++数据结构中显得尤其闪耀。C++通过使用拷贝构造函数的类简化深度复制问题。拷贝构造函数创建一个类的对象,给它的成员分配空间,并把他们的值复制给另一个对象。C++也允许new和delete内存管理运算符的重载。这意味着我们可以创建一个基类,我们称之为Managed,在里面使用cudaMallocManaged()重载新运算符,下面给出代码
- <pre name="code" class="plain">class Managed {
- public:
- void *operator new(size_t len) {
- void *ptr;
- cudaMallocManaged(&ptr, len);
- return ptr;
- }
- void operator delete(void *ptr) {
- cudaFree(ptr);
- }
- };
- <pre name="code" class="plain">//Deriving from "Managed" allows pass-by-reference"
- class String : public Managed {
- int length;
- char *data;
- public:
- //Unified mamory copy constructor allows pass-by-value
- String(const String &s) {
- length = s.length();
- cudaMallocManged(&data, length);
- memcpy(data, s.data, length);
- }
- //...
- };
- 类似的,使dataElem类继承Managed
- // Note “managed” on this class, too.
- // C++ now handles our deep copies
- class dataElem : public Managed {
- public:
- int prop1;
- int prop2;
- String name;
- };
- </pre>通过这些盖面,C++类在unified memory中分配他们的内存,并自动处理深度复制。我们可以在unified memory中分配一个dataElem就像C++中的对象<p></p><p></p><pre name="code" class="plain">dataElem *data = new dataElem;
现在我们想kernel函数传递对象时就有了选择;想普通的C++,我们可以传递值或传递引用。
- // Pass-by-reference version
- __global__ void kernel_by_ref(dataElem &data) { ... }
- // Pass-by-value version
- __global__ void kernel_by_val(dataElem data) { ... }
- int main(void) {
- dataElem *data = new dataElem;
- ...
- // pass data to kernel by reference
- kernel_by_ref<<>>(*data);
- // pass data to kernel by value -- this will create a copy
- kernel_by_val<<>>(*data);
- }
__managed__引入了一种全局变量,在内存和显存中都可以使用,这是非常方便的,但是也有诸多限制,我测试发现只有把sm_10改成sm_30才能使用。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
#include <Windows.h>
using namespace std;
// 使用 __managed__
// 要求sm_30
__device__ __managed__ int ret[10];
__global__ void AplusB(int a, int b)
{
ret[threadIdx.x] = a + b + 2 * ret[threadIdx.x];
}
int main()
{
for(int i=0; i<10; i++)
{
ret[i] = i;
}
AplusB<<< 1, 10 >>>(10, 100);
cudaDeviceSynchronize();
for(int i=0; i<10; i++)
{
cout<< "A+B = " << ret[i] << endl;
}
Sleep(20000);
return 0;
}CUDA 4.0开始就支持统一虚拟寻址Unified Virtual Addressing(UVA)了,Unified Memory依赖于UVA,但他们不同。UVA为系统中所有内存提供虚拟的单一的虚拟内存地址,不论是设备内存,主机内存或是片上共享内存。它允许cudaMemcpy的使用,不管输入和输出参数在哪。UVA能够使用“Zero-Copy” memory, 一种pinned host memory,设备端能够通过PCI-Express直接获取,不需要memcpy。Zero-Copy提供了一些统一内存的便利性,但性能并不好,因为它总是和PCI-Express的低带宽和高延迟相关的。















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









