




 文章介绍了TiDB分布式数据库的存储架构,包括TiDBServer、PD和TiKV的角色。通过模拟TiKV故障,展示了当超过一半副本损坏时,如何进行有损不安全恢复以恢复数据表的读写,但此方法可能牺牲数据一致性。文章强调了在执行有损恢复前需确认节点无法自动恢复的重要性。
文章介绍了TiDB分布式数据库的存储架构,包括TiDBServer、PD和TiKV的角色。通过模拟TiKV故障,展示了当超过一半副本损坏时,如何进行有损不安全恢复以恢复数据表的读写,但此方法可能牺牲数据一致性。文章强调了在执行有损恢复前需确认节点无法自动恢复的重要性。
高文锋 |后端开发工程师
目录
(二)测试表db 1.sbtest 1的region分布情况
一、前言
TiDB分布式数据库采用多副本机制,数据副本通过 Multi-Raft 协议同步事务日志,确保数据强一致性且少数副本发生故障时不影响数据的可用性。在三副本情况下,单副本损坏可以说对集群没什么影响,但当遇到多副本损坏的损坏丢失的时候,如何快速恢复也是DBA需要面对的问题,本次主要讲述对TiDB对多副本损坏丢失的处理方法。
二、TiDB数据库的存储架构
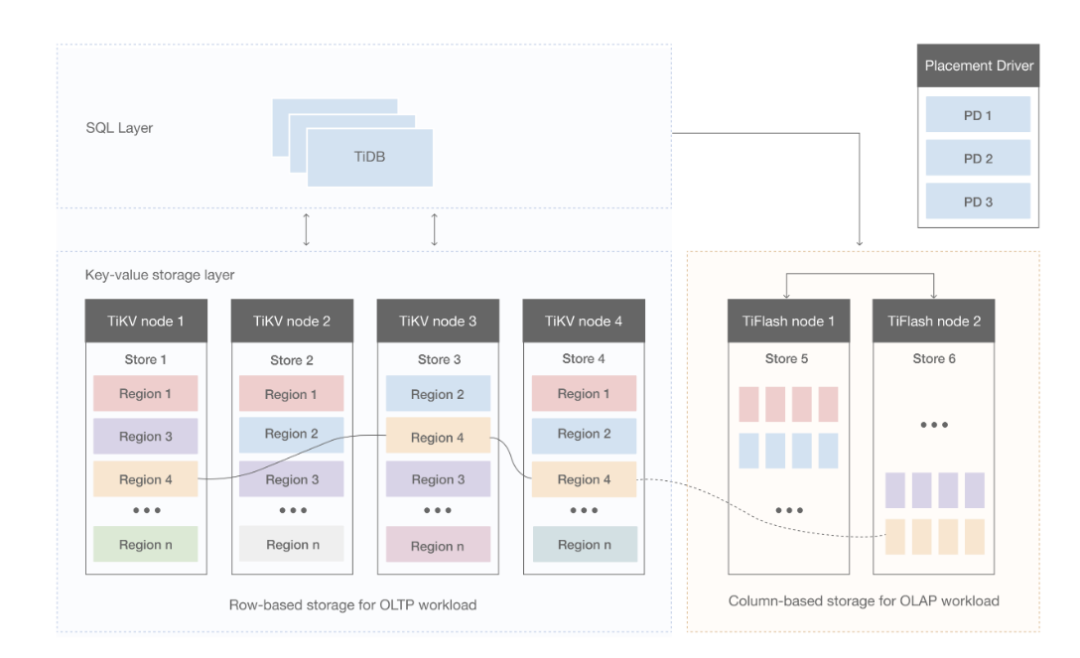
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
存储节点TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
三、集群信息
(一)Store情况
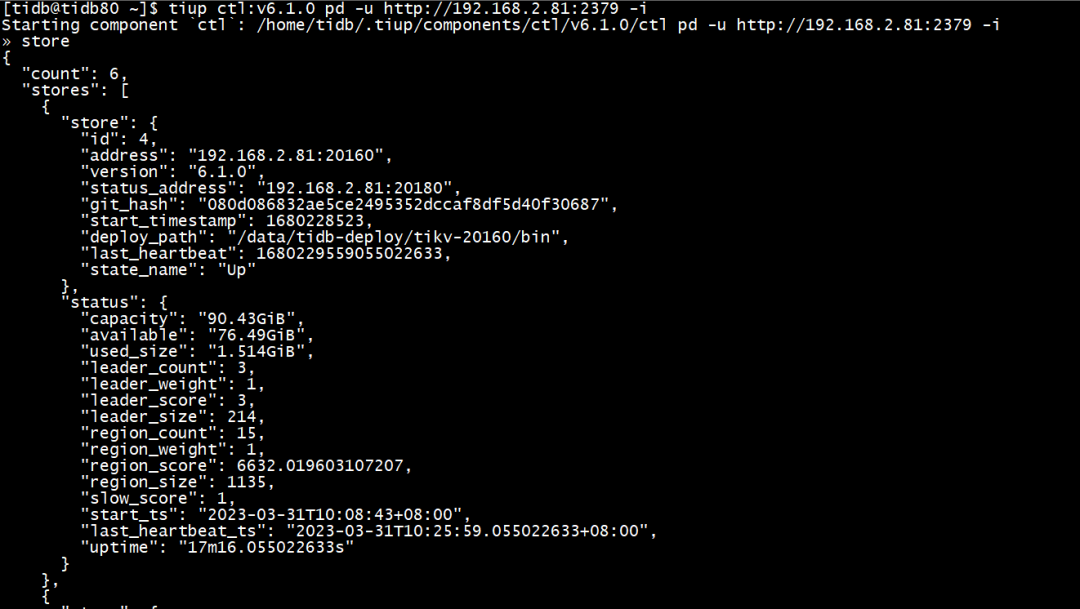
192.168.2.81:20160 ---> id=4
192.168.2.82:20160 ---> id=5
192.168.2.83:20160 ---> id=1
192.168.2.81:20161 ---> id=6247
192.168.2.82:20161 ---> id=6246
192.168.2.83:20161 ---> id=6248
(二)测试表db 1.sbtest 1的region分布情况

查看各4个region的分布情况
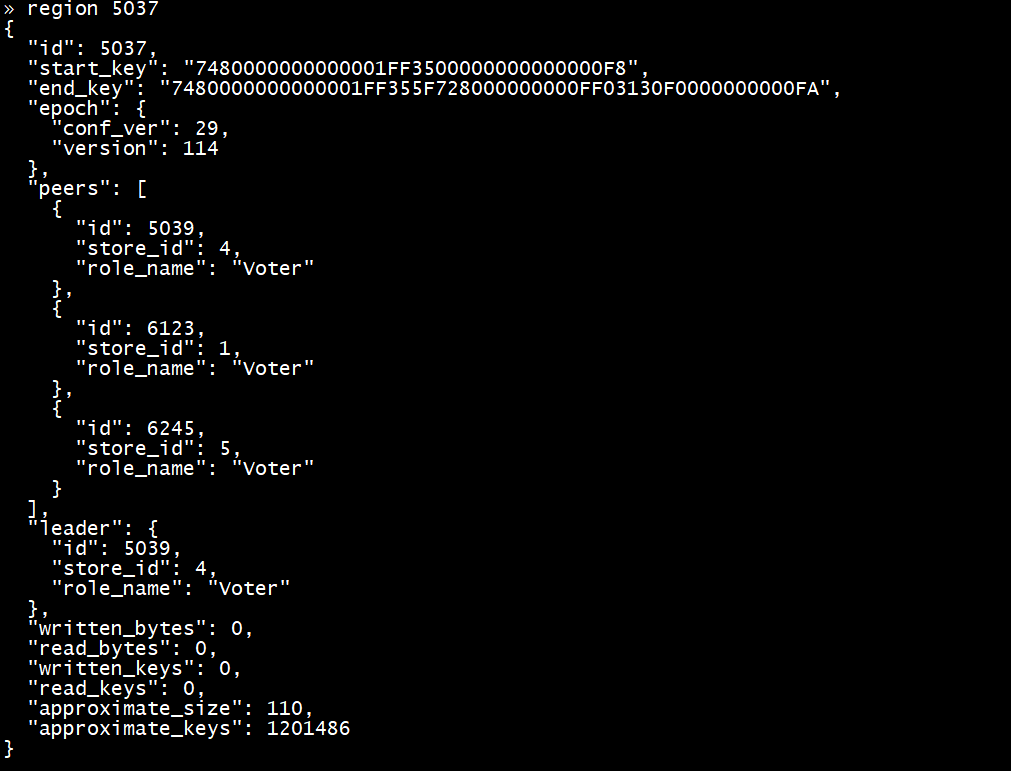
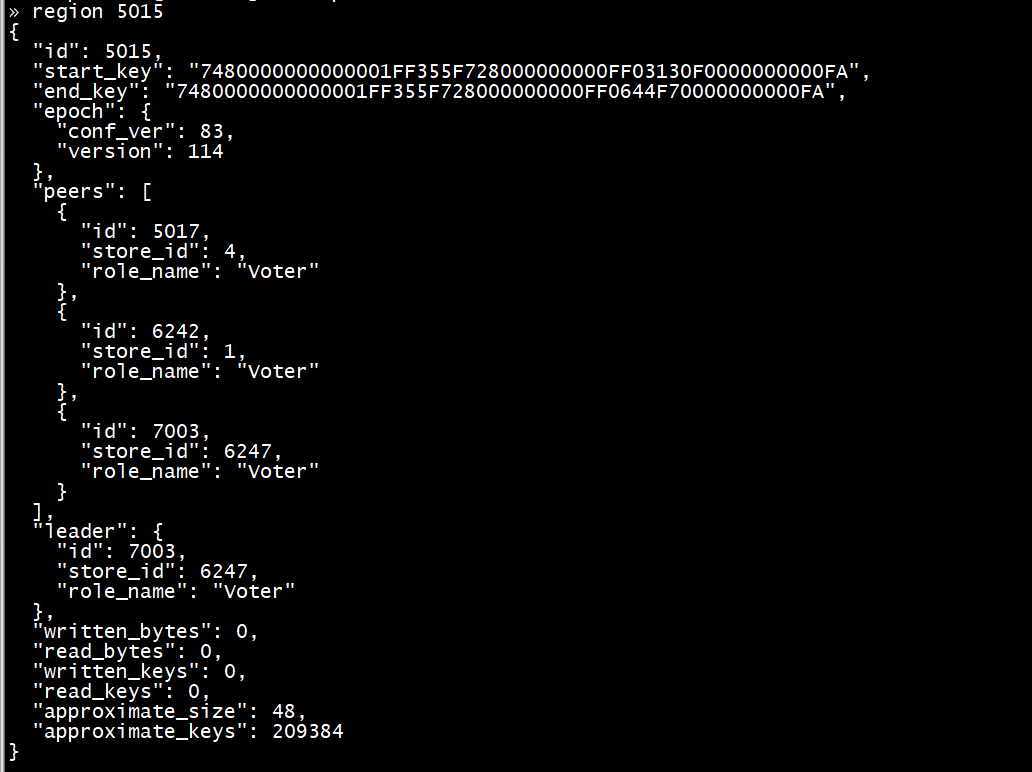
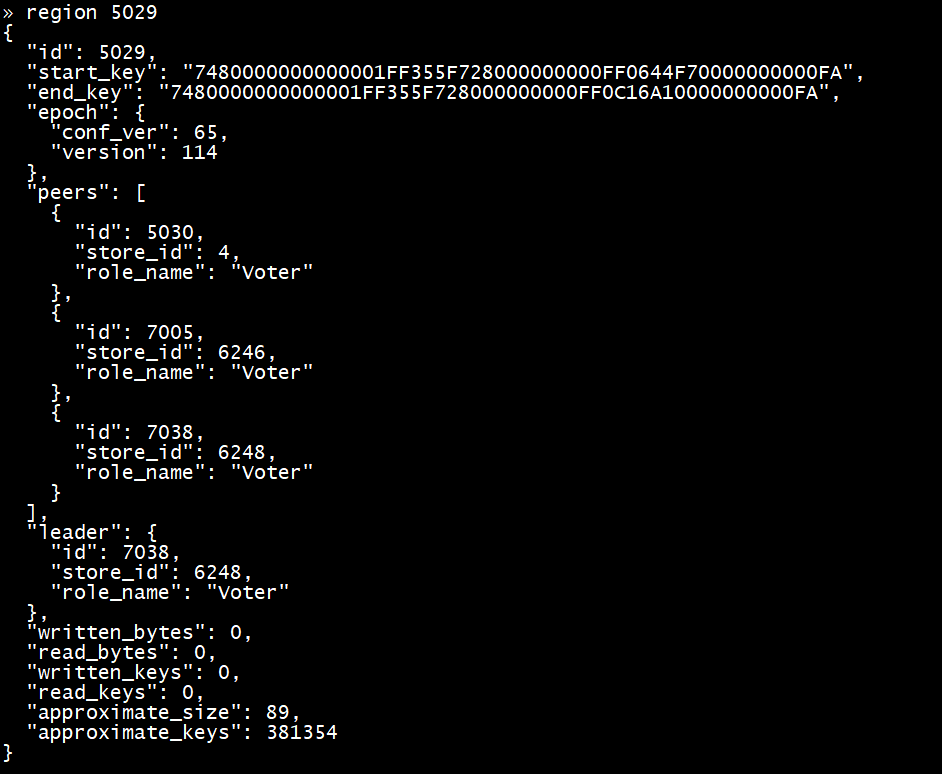

Region 5037 ---> leader:4 follower:1,5
Region 5015 ---> leader:6247 follower:1,4
Region 5029 ---> leader:6248 follower:4,6246
Region 6001 ---> leader:4 follower:1,6246
(三)模拟tikv出现故障
当模拟192.168.2.81:20160和192.1-68.2.83:20160出现故障时,即store id为1和4时,Region 5037,Region 5015,Region 6001将同时失去两个副本,包括leader和follower副本。
考虑到当前环境是虚拟机多实例环境,我们需要通过关闭系统服务的自动拉起功能来模拟tikv故障环境。
具体操作如下:
-
打开文件/etc/systemd/system/tikv-20160.service。
-
将Restart的值修改为no,原来默认是always,即总是拉起服务的意思,改为no后,服务挂掉后不会自动拉起。
-
使修改生效,执行命令systemctl daemon-reload。
杀掉192.168.2.81:20160和192.168.2.83:20160进程


查看集群状态,192.168.2.81:20160和192.168.2.83:20160出现Disconnected
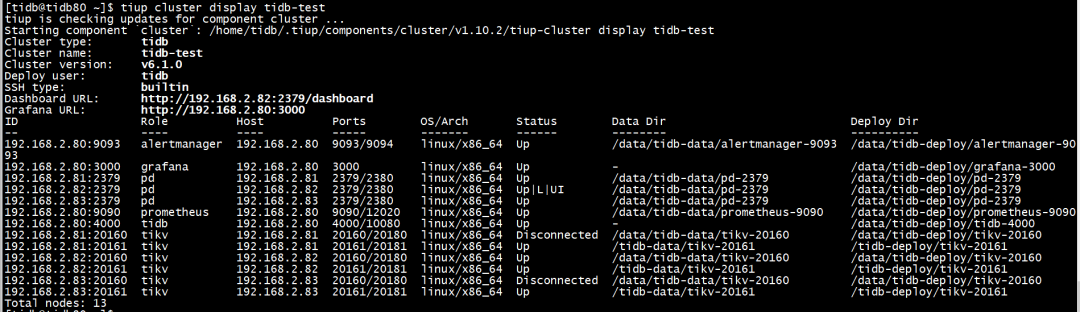
这时候查看db1.sbtest1的表,出现tikv超时

使用 pd-ctl 检查大于等于一半副本数在故障节点上的 Region,并记录它们的 ID(故障节点为store id 1,4)
region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(1,4) then . else empty end) | length>=$total-length) }"
{"id":3001,"peer_stores":[5,1,4]}
{"id":5015,"peer_stores":[4,1,6247]}
{"id":3021,"peer_stores":[5,1,4]}
{"id":6037,"peer_stores":[1,4,6248]}
{"id":6001,"peer_stores":[4,1,6246]}
{"id":6051,"peer_stores":[4,1,6246]}
{"id":5037,"peer_stores":[4,1,5]}
```db1.sbtest1表上面包含这3个region
{"id":5015,"peer_stores":[4,1,6247]}
{"id":5037,"peer_stores":[4,1,5]}
{"id":6001,"peer_stores":[4,1,6246]}
(四)有损不安全恢复
现在由于三副本已损坏大于等于一半副本数的region,此时对应表访问不了,这时通过有损恢复,但无法保证数据索引一致性和事务完整性。
在使用 Online Unsafe Recovery 功能进行数据有损恢复前,请确认以下事项:
-
离线节点导致部分数据确实不可用。
-
离线节点确实无法自动恢复或重启。
[tidb@tidb80 ~]$ tiup ctl:v6.1.0 pd -u http://192.168.2.81:2379 -i
» unsafe remove-failed-stores 1,4
Success!
» unsafe remove-failed-stores show
[
{
"info": "Unsafe recovery enters collect report stage: failed stores 1, 4",
"time": "2023-03-31 14:46:06.462"
},
{
"info": "Unsafe recovery enters force leader stage",
"time": "2023-03-31 14:46:13.675",
"actions": {
"store 5": [
"force leader on regions: 3021, 3001, 5037"
],
"store 6246": [
"force leader on regions: 6001, 6051"
],
"store 6247": [
"force leader on regions: 5015"
],
"store 6248": [
"force leader on regions: 6037"
]
}
},
{
"info": "Unsafe recovery enters demote failed voter stage",
"time": "2023-03-31 14:46:54.721",
"actions": {
"store 5": [
"region 3021 demotes peers { id:6068 store_id:1 }, { id:6208 store_id:4 }",
"region 3001 demotes peers { id:6209 store_id:1 }, { id:6217 store_id:4 }",
"region 5037 demotes peers { id:5039 store_id:4 }, { id:6123 store_id:1 }"
],
"store 6246": [
"region 6001 demotes peers { id:6019 store_id:4 }, { id:6238 store_id:1 }",
"region 6051 demotes peers { id:6142 store_id:4 }, { id:6206 store_id:1 }"
],
"store 6247": [
"region 5015 demotes peers { id:5017 store_id:4 }, { id:6242 store_id:1 }"
],
"store 6248": [
"region 6037 demotes peers { id:6039 store_id:1 }, { id:6041 store_id:4 }"
]
}
},
{
"info": "Unsafe recovery finished",
"time": "2023-03-31 14:47:05.170",
"details": [
"affected table ids: 201, 309, 314"
]
}
]
```检查数据索引一致性
#若结果有不一致的索引,可以通过重命名旧索引、创建新索引,然后再删除旧索引的步骤来修复数据索引不一致的问题
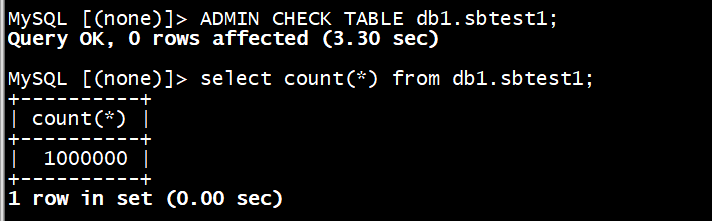
通过有损修复后,数据表可恢复读写
四、总结
1.在TiDB中,根据用户定义的多种副本规则,一份数据可以同时存储在多个节点中,这样可以确保在单个或少数节点暂时离线或损坏时,读写数据不会受到任何影响。然而,当一个Region的多数或全部副本在短时间内全部下线时,该Region将变为暂时不可用的状态,无法进行读写操作。
2.一旦执行了unsafe recovery,所指定的节点将被设为 Tombstone 状态,不再允许启动,执行过程中,所有调度以及 split/merge 都会被暂停,待恢复成功或失败后自动恢复
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,后台回复数据库,加入数据库技术交流群。



















 4832
4832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









