






什么是Shape Context
Shape Context是一个用于形状识别的,非常经典的特征(一串便于计算机处理的数字)提取方法,它由Serge Belongie和Jitendra Malik 于2002年在他们的文章“Shape matching and object recognition using shape contexts”中提出。这种特征提取方法使得计算机能够衡量形状之间的相似性,并且能够同时得出形状上的点对应关系。
Shape Context在表示形状时,首先会在形状的轮廓上采样N个点;而对每一个点来说,会利用其周围点的信息,为其提取一个向量,来表示这个点(具体的提取方法可以参考原始的论文)。如此一来,每一个形状便由N个向量来表示了;向量之间是可以衡量距离的,在确定这种距离的衡量方式后,便可以利用匈牙利(Hungarian)算法找出两个形状之间,N对N的最佳匹配关系了。当然文章的作者又进一步提出可以使用TPS(Thin Plate Spline)变换对待匹配的形状进行不断的形变,以取得更佳的匹配结果,这里便不做介绍。
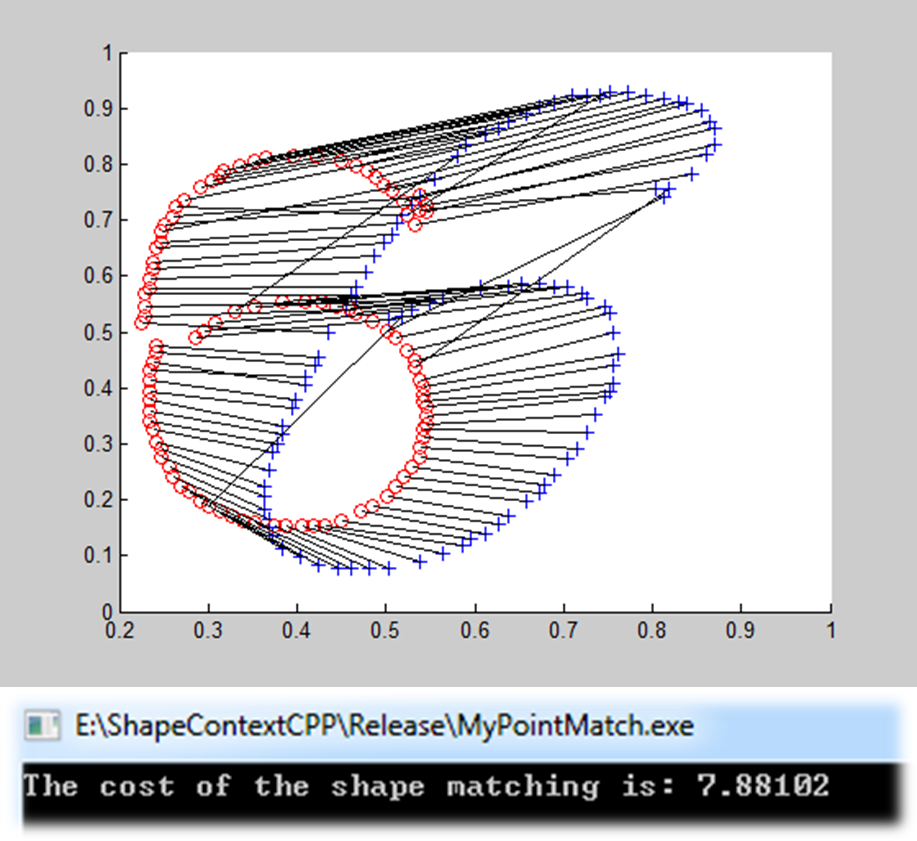
相同形状轮廓点的匹配
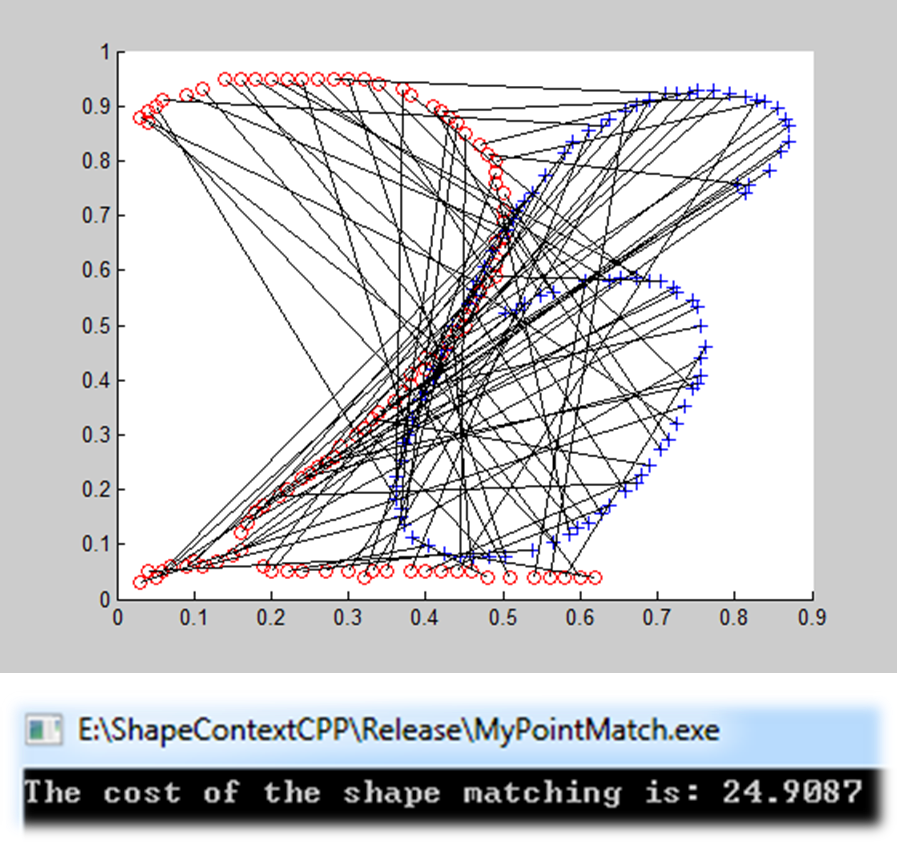
不同形状轮廓点的匹配
利用Shape Context进行字符识别
利用Shape Context进行字符识别的过程,便是找出与待识别形状最相似模板库图像的过程。这个过程虽然思路比较简单,不过其中也有一些需要注意的东西,这里写一下我自己的做法。
1)模板字符库的准备由于Shape Context可以在形状发生倾斜、位移、大小等平面变换时,都可以进行比较良好的匹配。所以与基于统计的模型不同,使用Shape Context特征的每一种字符只需要较少的模板就可以进行识别了。这里的实验对每一种字符仅使用一到两个模板,每一个模板都是由手工绘制的单像素轮廓图。
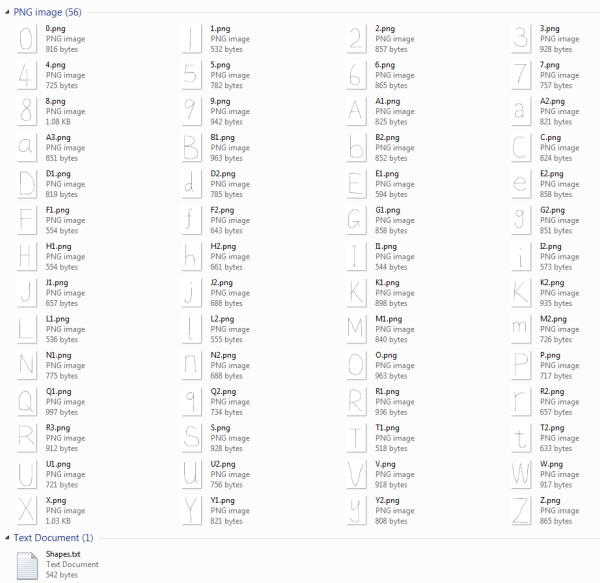
用于识别的字符模板库
2)形状点的采样
在使用Shape Context提取形状的特征时,首先会在形状轮廓上采样N个点。而实际输入图像的轮廓点个数一般是未知的,而根据图像大小的不同,这些点的坐标的大小也是不同的,因此需要对这些情况进行一些预处理。
当输入图像的轮廓点足够时,首先可以将图像中包含轮廓的最小区域截取出来,然后将这个区域中的轮廓采样N个点,最后将这些点的坐标保持长宽比缩放到[0-1]区间,以完成尺度归一化的目的。
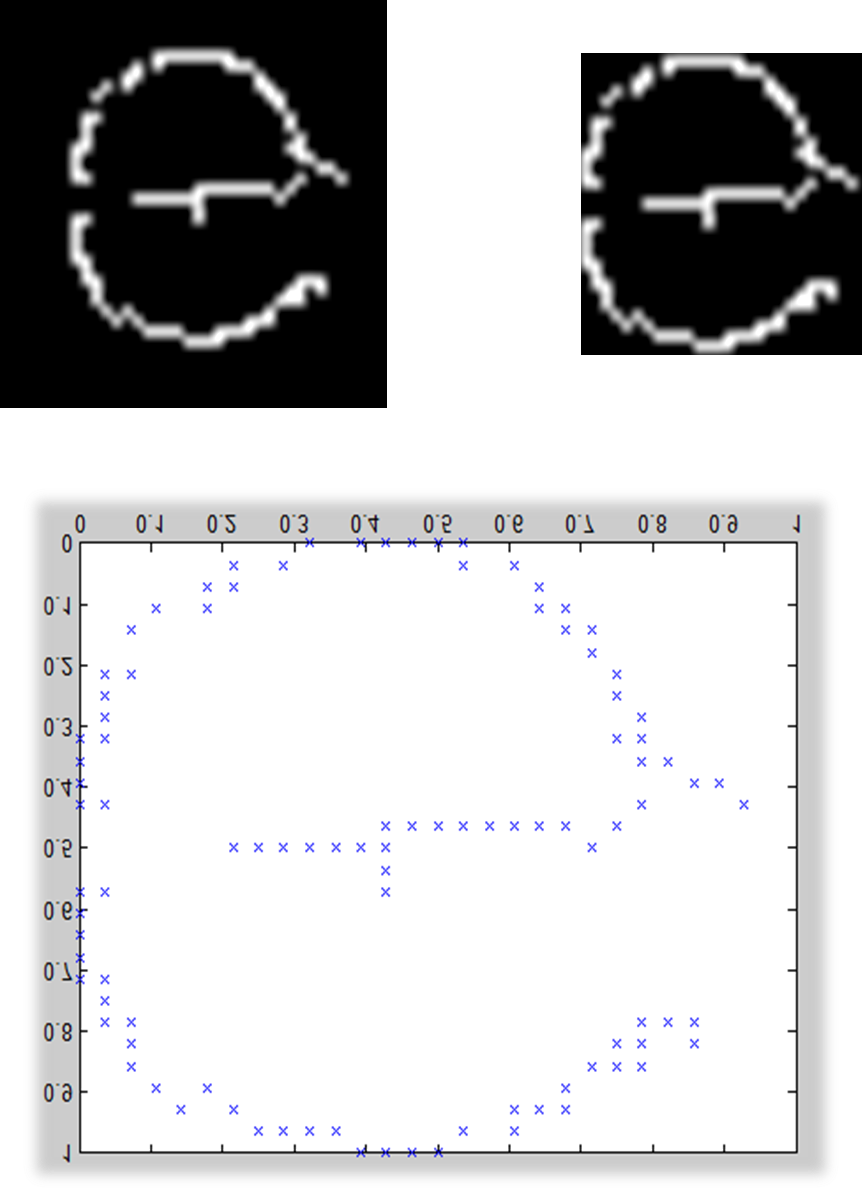
对输入图像的轮廓点进行采样及归一化
而当输入图像的轮廓点个数不足时,我们可以将图像进行放大,待轮廓点个数足够时,再按上面的方法进行采样。不过需要注意的是,图像放大时候,原来的形状轮廓可能会变粗,因此还需要进行图像的细化操作,使得轮廓的宽度尽量保持单像素宽。
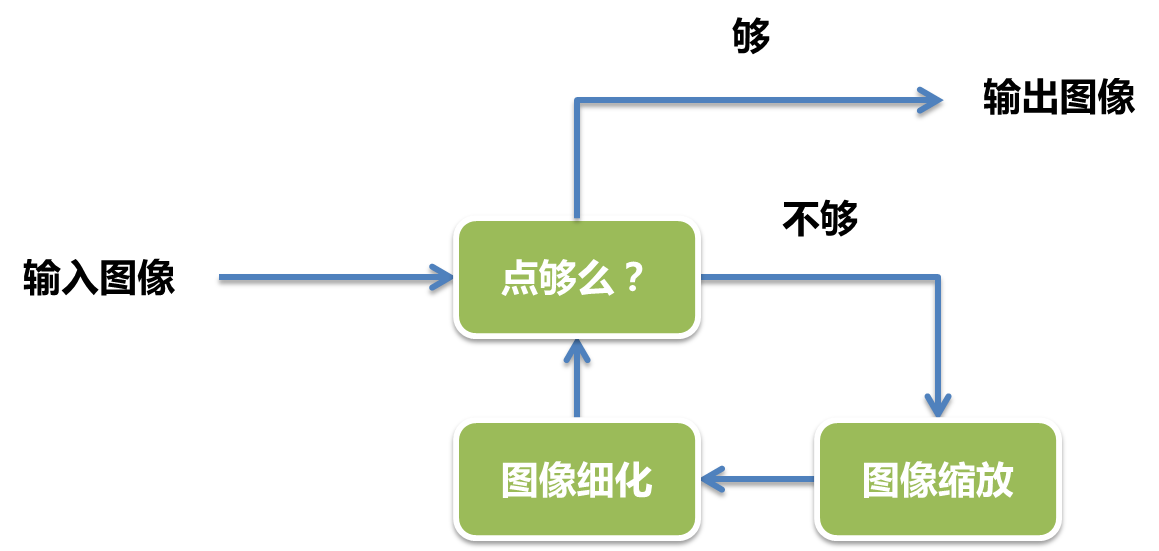

输入图像轮廓点个数不够时的处理
字符识别程序的演示















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









