








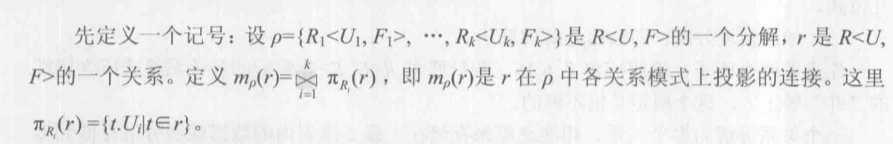

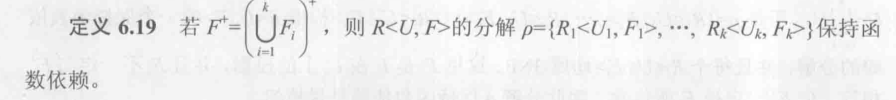
从上面的定义, 保持无损连接的模式分解, 每个Ui必须包含作为连接的属性, 而函数依赖是要把产生关联的属性分到一起.
无损连接的判定
1. 如果分解后的关系模式形如{U1, U2}, 里面只有两个,那很好做,就判断U1交U2->U1-U2或U1交U2->U2-U1是否成立,成立的话肯定是无损连接 .
2. 如果是两个以上, 一个关系模式R(A1,A2,A3,…,An),R上的一个函数依赖集合F以及一个分解p{{R1,F1},{R2,F2},…,{Rk,Fk]}.
(1) 建立表
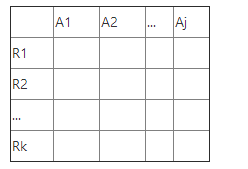
(2)填表: 若Aj属于Ri, 则将第i行第j列填为aj, 否则填入bij.
(3) 修改表: 逐一考察F中的函数依赖X->Y,X可能包含一个或者多个属性,如果这(个)些属性对应于表中的列的值相同,则值相等的行所对应的Y属性所有的列的值也相等。(比方说X->Y,X是A1A2所对应的属性,Y是属性A4。由第一步,如果表中第一行和第二行的值相等,那么表中A4对应的第一行和第二行的值也要修改成一样的。)如果其中有aj,则将bij改成aj;如果没有aj,就将他们都改成bij,一般来说i是值相等的行中最小的行号。
(4) 反复(指在前一次修改地基础上,反复进行,直到表中的数据不再改变)进行(3),若发现某一行变成a1,a2,…,aj,则可以得出分解p{{R1,F1},{R2,F2},…,{Rk,Fk]}具有连接不失真性。
函数依赖性判断
对F上的每一个α→β使用下面的过程
result:=α;
while(result发生变化)do for each分解后的Ri t=(result∩Ri)+∩Ri
result=result∪t
这里的属性闭包是在函数依赖集F下计算出来的。如果result中包含了β
的所有属性则函数依赖α→β。分解是保持依赖的当且仅当上述过程中F的
所有依赖都被保持。

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









