



文章探讨了AI工具对初级工程师的双面影响,指出过度依赖AI可能导致"认知负债"和能力空心化。作者区分了"浅层技能"(知道"是什么")和"内功心法"(理解"为什么"和"怎么做"),强调后者才是真正的核心竞争力。文章提出了四条实用法则:先思后问、刨根问底、刻意练习和源码为师,帮助程序员成为AI的主人而非奴隶,在AI时代构建不可替代的深度能力。
这是一个对初级工程师而言,最好也最坏的时代。
说它“最好”,是因为我们从未拥有过如此强大的工具。一名刚走出校门的毕业生,在入职的第一天,就能手握Claude Code、ChatGPT、Cursor、Copilot 等强大的 AI 编程助手。面对一个从未接触过的复杂任务——比如,为一个 Go 项目编写一个复杂的 gRPC 中间件——他可能只需要组织几次提示词,一段看起来完美、功能齐全、甚至带着[单元测试]的代码就诞生了。
那种“我什么都行”的强大感和即时满足感,是十年前的我完全无法想象的。
但说它“最坏”,也恰恰源于此。在这种令人沉醉的“魔幻”体验背后,一个直击灵魂的问题正在浮现:
这种惊人的“效率”,是在加速你的成长,还是在为你铺设一条通往“能力空心化”的捷径?
今天,我想和大家一起聊聊这个话题。这不仅是一份给初级工程师的生存指南,更是我们每一个身处 AI 浪潮中的技术人,都应该进行的深刻反思。
“浅层技能” vs “内功心法”:AI 正在拉开的差距
要理解 AI 带来的潜在风险,我们首先需要区分两种截然不同的技能:“浅层技能”与“内功心法”。
“浅层技能”,关注的是**“是什么”(“What”)**。在 AI 时代的初期,这主要体现为:
- 擅长编写精妙的 Prompt。
- 能快速地从 AI 处获得“能用”的代码片段。
- 熟练地进行“复制-粘贴-修改”的“胶水”工作。
而如今,随着 [Gemini CLI]这类编码智能体(Coding Agent)以及深度集成在 IDE 中的 AI 工具的兴起,这种“浅层技能”又演化出了一个更集成、也更具迷惑性的新形态。
“复制-粘贴”的动作消失了。取而代之的,是 Agent 直接读取你的整个代码库,然后给你一个可以直接应用的变更集(diff)。在这里,“浅层技能”表现为:
- 将高阶的、模糊的任务指令(‘重构这个文件’、‘修复这个bug’)下发给 Agent。
- 对 Agent 提出的变更集进行表面化的审查——检查代码风格是否一致、命名是否规范,但缺乏对底层逻辑、性能陷阱和安全隐患的深度洞察。
- 最终,熟练地点击‘应用’(Apply)或‘接受’(Accept)按钮,成为一个高效的“变更批准员”。
你看,无论是“复制代码”还是“批准变更”,其本质是相通的:你依然只停留在知道“是什么”,而没有深入到“为什么”。 你知道这段由 Agent 修改的代码能工作,但你很可能依然不清楚它背后的原理。这种新模式甚至更危险,因为它让你感觉更“专业”,更容易在不知不觉中放弃思考。
而**“内功心法”,关注的则是“为什么”(The “Why”)和“怎么做”(The “How”)**。这包括:
- 设计模式:为什么在这里 AI 选择用工厂模式,而不是单例模式?这两种模式的权衡是什么?
- 数据结构与算法:AI 生成的这个函数,其核心数据结构是什么?它的时间复杂度和空间复杂度在各种情况(最好、最坏、平均)下分别是多少?
- 架构权衡:这段看似独立的代码,被集成到系统中后,是会提升整个系统的内聚性,还是会引入一个危险的耦合点?
- 调试能力:当这段“完美”的 AI 代码,在生产环境中因为一个罕见的并发条件而出现诡异的 Bug 时,你有能力深入其中,定位并解决问题吗?
“浅层技能”决定了你使用工具的熟练度,而“内功心法”则决定了你作为一名工程师的能力天花板。
“舒适”的代价:正在累积的“认知负债”
问题在于,AI 工具太“舒适”了。它让我们能轻易地绕过那些艰难的、需要深度思考的“内功”修炼,直接获得“浅层”的结果。这种舒适感,正在让我们不知不觉地背上沉重的**“认知负债”(Cognitive Debt)**。
这个概念精辟地描述了一种权衡:我们用即时的便利,换取了长期的批判性思维、记忆力、以及创造性自主权的丧失。 你正在向机器借用脑力,但这笔债,未来需要连本带利地偿还。
最近的一项科学研究,用数据血淋淋地揭示了这一点。研究者将参与者分为三组写论文:纯脑力组、搜索引擎组和 LLM 组。结果令人震惊:
在 LLM 组中,83% 的参与者在写完论文后,几乎无法复述出自己文章中的任何观点(见下图)。而在另外两组,几乎每个人都能做到。
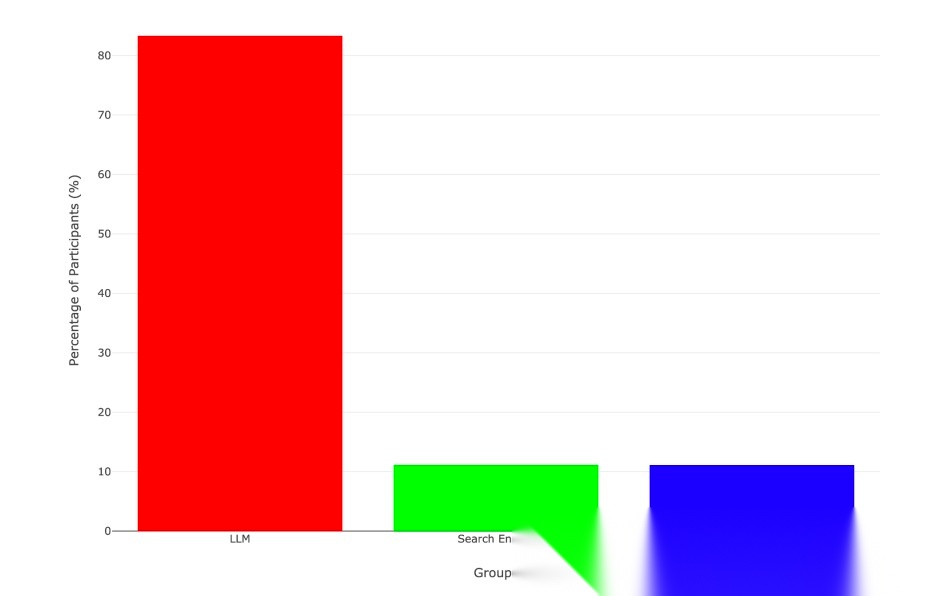
这证明了,当我们把思考过程完全外包给 AI 时,知识并没有真正“流经”我们的大脑,我们只是成为了一个信息的“搬运工”。
这背后,是纳西姆·塔勒布在其著作《反脆弱》中提到的深刻哲理:小的压力和不适,会让我们变得更强大。
- 肌肉,需要通过举起沉重的杠铃,在撕裂和修复中才能生长。
- 我们的大脑,同样需要通过“精神举重”——也就是主动思考、艰难探索、反复试错的“摩擦力”——才能成长。
而初级工程师的职业生涯前三年,正是进行这种“精神举重”、构建个人能力护城河最宝贵的黄金时期。如果在这个阶段,你沉迷于 AI 带来的舒适感,持续累积“认知负债”,无异于在一个本应最大化“肌肉增长”的年纪,选择了全程坐轮椅。
其长期危害是显而易见的:
- 成长停滞:解决问题的“认知肌肉”因缺乏锻炼而萎缩。
- 危险的“信心差”:你产生了一种“我能搞定任何代码”的虚假自信,但这与“我能维护和解释任何我写的代码”的真实能力之间,存在着巨大的鸿沟。这在团队协作和处理线上故障时,是极其危险的。
- 沦为“API 粘合工”:长期以往,你可能会彻底丧失从零开始构建系统的能力,沦为只会将 AI 生成的黑箱代码块“粘合”在一起的低阶操作员,失去了真正的工程创造力和不可替代性。
“破局”指南:如何成为 AI 的主人,而非奴隶?
那么,我们该如何打破这个困局?关键在于心态的转变和方法的调整。你需要将 AI 从一个无所不知的**“神谕”,转变为一个需要你引导和挑战的“陪练”**。
这里有四条具体的实战法则:
法则一:“先思后问”法则
在向 AI 提问前,强迫自己先进行独立思考。用纸笔、伪代码或注释,勾勒出你自己的解决方案轮廓。哪怕这个方案很粗糙,甚至可能是错的,这个思考的过程本身就是一次宝贵的“精神举重”。
然后,你可以这样做:
“不要让 AI 直接为你解题;相反,提供你自己的解法,让它解释你可能错在哪里,或者有哪些可以改进的地方。”
通过这种方式,你把 AI 从一个“答案机”变为一个能启发你、挑战你的“批判性思维伙伴”。你始终是思考的主导者。
法则二:“刨根问底”法则
永远不要满足于 AI 给出的第一份“能用”的代码。对它生成的每一段关键代码,都要像对待一位资深同事的 [Code Review]意见一样,进行苏格拉底式的反复追问:
- “你为什么选择这种数据结构?它和另一种方案相比,优劣势分别是什么?”
- “这段代码的时间复杂度和空间复杂度是多少?在什么情况下会达到最坏情况?”
- “请为这段代码生成五个可能会导致它出错的边缘案例(corner cases)。”
- “这段代码遵循了哪些设计模式?请为我解释这个模式的核心思想。”
通过这种刨根问底,你把 AI 从一个“代码生成器”,变成了一个免费的、24小时在线的、极具耐心的私人导师。
法则三:“刻意练习”法则
定期进行**“无 AI 编程”**的刻意练习。这就像健身房里的“力量训练日”。给自己设定一些小项目、算法题,或者工作中的某个非紧急模块,规定自己在不使用任何 AI 代码生成辅助的情况下,从零开始完整地实现它。
这个过程可能会让你感到“不适”,速度会很慢,甚至会碰壁。但请记住塔勒布的教诲:不适感不是麻烦,而是训练场。 这正是你构建底层能力、“流血流汗”的真实成长过程。
法则四:“源码为师”法则
当 AI 生成了一段使用了你从未见过的库函数或框架特性的代码时,不要只满足于知道“怎么用”。花15分钟时间,去看看那个函数或特性的源码实现。
这是理解其背后原理、设计哲学和实现细节的最直接方式。AI 可以为你指出一条通往宝藏的道路,但路边的风景和地下的矿藏,需要你自己去探索和挖掘。
你的不可替代性,藏在 AI 的“盲区”里
遵循以上法则,你会发现,AI 不仅不会成为你成长的障碍,反而会成为你成长的强大加速器。更重要的是,它会帮助你将精力聚焦在那些 AI 永远无法取代的、真正体现工程师价值的领域——也就是 AI 的“盲区”。
- 深度理解业务:AI 不懂你的用户,不懂你的商业模式。将技术与业务场景深度结合,提供有洞察力的解决方案,这是你的核心价值。
- 系统性思考:AI 能生成一个函数,但它尚无法设计一个健壮、可扩展、可维护的大规模生产级系统。培养自己的架构思维和全局视野,是你拉开差距的关键。
- 人际协作与沟通:理解团队成员的需求,清晰地阐述技术方案的利弊,组织有效的讨论,推动项目落地。这些“软技能”,在 AI 时代变得比以往任何时候都更加重要。
小结:别在黄金时代,选择一条最容易的路
职业生涯的初期,是一个人构建个人“能力护城河”最关键的时期。在这个阶段,最宝贵的不是表面的“效率”,而是**“成长深度”**。
AI 时代,给了我们前所未有的强大工具,但工具的价值,永远取决于使用者的智慧。
所以,请警惕那些让你过于舒适的捷径。不要在最需要“扎马步”的年纪,沉迷于“轻功”带来的快感。 真正的成长,永远伴随着求索的痛苦和突破的喜悦。让我们去拥抱那些有益的“摩擦力”,掌握那些 AI 无法生成的“内功心法”。
选择那条更难、但更有价值的路,你才能在未来的技术浪潮中,真正地立于不败之地。
为什么要学习大模型?
在科技飞速发展的当下,大模型已成为推动AI变革的核心引擎。2025年,大模型应用已经深入各行各业,从日常办公使用的DeepSeek、豆包、千问,到下游应用的自动驾驶/具身智能VLA,再到AIGC生成。大模型产业正经历技术普惠化、应用垂直化、生态开源化的深度变革,学习大模型成为把握人工智能革命主动权的关键。
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!

普通人如何学习大模型
最近收到不少留言:
- 我是做后端开发的,能转大模型方向吗?
- 看了很多教程,怎么判断哪些内容是真正有用的?
- 自己尝试动手搭模型,结果踩了不少坑,是不是说明我不适合这个方向?
其实这些问题,我几年前也都经历过。
那时我还是一名传统后端工程师,对大模型一知半解。刚开始接触时也很迷茫,常常不知道从哪里下手、该学哪些内容才算“有用”,搭建模型时也是各种踩坑、反复重来。
但正是一步步摸索、不断试错,我才走到了今天,从0起步,成功转型为大模型开发者。
所以我想跟你说:问题不在你,而是在学习方法。
今天我就以“过来人”的身份,分享一份亲测有效的大模型学习资源。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓

01. 大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!

02. 大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识

03. 大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

04. 大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









