







Fork/Join
在JDK7之后,Java加入了并行计算的框架Fork/Join,来解决系统中大数据计算的性能问题。在这里要强调的是并行并不是并发,并行是指系统内有多个任务同时执行,并发是指系统内有多个任务同时存在。不同的任务按时间分片的方式切换执行,由于切换的时间很短,给人的感觉好像是在同时执行。
Fork/Join采用的是分治法,Fork是讲一个大任务拆分成若干个子任务,子任务分别去计算,而Join是获取子任务的计算结果,然后合并。就像分布式里面的MapReduce一样。Java的Fork/Join是一个递归的过程,子任务被分配到不同的核上执行,效率最高。
ForkJoinPool
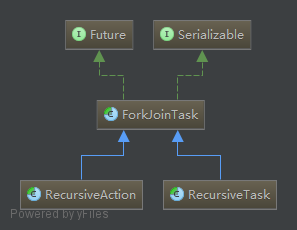
Fork/Join框架的核心类是ForkJoinPool,ForkJoinPool是ExecutorService的一个实例,它能够接收一个ForkJoinTask,并得到计算结果。ForkJoinTask有两个子类, RecursiveAction(无返回结果), RecursiveTask(有返回结果)。定义任务时,只要继承这两个类就可。
下面是一个实例,计算一个超大数组所有元素的和。
public class ForkJoinPoolTest extends RecursiveTask<Integer>{
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 100;//阈值
private long[] array;
private int low;
private int high;
public ForkJoinPoolTest(long[] array, int low, int high) {
this.array = array;
this.low = low;
this.high = high;
}
@Override
protected Integer compute() {
int sum = 0;
if(high - low <= THRESHOLD){
//小于阈值这直接计算
for(int i=low;i<high;i++){
sum += array[i];
}
} else{
//将一个大任务分成两个小任务
int mid = (low + high) >>> 1;
ForkJoinPoolTest left = new ForkJoinPoolTest(array, low, mid);
ForkJoinPoolTest right = new ForkJoinPoolTest(array, mid+1, high);
//分别计算
left.fork();
right.fork();
sum = left.join() + right.join();
}
return sum;
}
public static void main(String[] args) throws InterruptedException, ExecutionException{
long[] array = geeArray(50000);
System.out.println(Arrays.toString(array));
//创建任务
ForkJoinPoolTest task = new ForkJoinPoolTest(array, 0, array.length - 1);
long begin = System.currentTimeMillis();
//创建线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
//提交任务到线程池
forkJoinPool.submit(task);
//获取结果
Integer result = task.get();
long end = System.currentTimeMillis();
System.out.println(String.format("结果 %s 耗时 %s ms", result, end - begin));
}
private static long[] geeArray(int size){
long[] array = new long[size];
for(int i=0;i<array.length;i++)
array[i] = new Random().nextLong();
return array;
}
}通过调整阈值(THRESHOLD),可以发现耗时是不一样的。















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









