









原文链接:https://blog.csdn.net/yangshaojun1992/article/details/85003668
一、分析MapReduce执行过程
MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到HDFS的文件中。整个流程如图:

二、Mapper任务的执行过程详解
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper任务的处理过程又可以分为以下几个阶段,如图所示。

在上图中,把Mapper任务的运行过程分为六个阶段。
第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。
第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。分区是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。
第六阶段是对数据进行归约处理,也就是reduce处理,通常情况下的Comber过程,键相等的键值对会调用一次reduce方法,经过这一阶段,数据量会减少,归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
三、Reducer任务的执行过程详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。
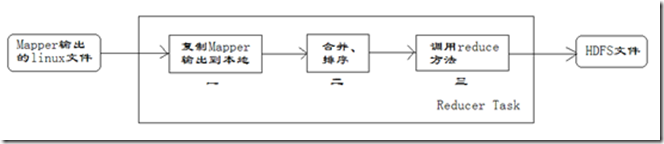
1、第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对,Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
2、第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序。
3、第三阶段是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
四、MapReduce原理

决定Mapper的数量
HDFS中数据的存储是以块的形式存储的,数据块的切分是物理切分,而split是在Block的基础上进行的逻辑切分。每一个split对应着一个Mapper进程。每个Split中的每条记录调用一次map方法。
一个文件被切分成多少个split就有多少个Mapper进程。
决定Reducer的数量
如: 10个key可以有1个reducer,但是这个reducer只能一次处理一个key,也就是说处理10次
10个key可以有大于10个reducer ,只不过有的reduce不进行key的处理。
10个key有10个reducer,这是最合理的分配,达到并行计算。
相同的key如何识别到指定的reducer进行计算呢?
对输出的key、value进行分区。
总结:Mapper阶段是并行读取处理的它的数量是由切片的数量决定的;Reducer阶段可以不并行,他的数量的是通过key进行规划,由人来决定。
五、hadoop运行原理之shuffle
hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心。shuffle的主要工作是从Map结束到Reduce开始之间的过程。首先看下这张图,就能了解shuffle所处的位置。图中的partitions、copy phase、sort phase所代表的就是shuffle的不同阶段。

shuffle被称作MapReduce的心脏,是MapReduce的核心。
由上图看出,每个数据切片由一个Mapper进程处理,也就是说mappper只是处理文件的一部分。
每一个Mapper进程都有一个环形的内存缓冲区,用来存储Map的输出数据,这个内存缓冲区的默认大小是100MB,当数据达到阙值0.8,也就是80MB的时候,一个后台的程序就会把数据溢写到磁盘中。在将数据溢写到磁盘的过程中要经过复杂的过程,首先要将数据进行分区排序(按照分区号如0,1,2),分区完以后为了避免Map输出数据的内存溢出,可以将Map的输出数据分为各个小文件再进行分区,这样map的输出数据就会被分为了具有多个小文件的分区已排序过的数据。然后将各个小文件分区数据进行合并成为一个大的文件(将各个小文件中分区号相同的进行合并)。
这个时候Reducer启动了三个分别为0,1,2。0号Reducer会取得0号分区 的数据;1号Reducer会取得1号分区的数据;2号Reducer会取得2号分区的数据。
一、Map端的shuffle
(1)在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
(2)写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
(3)最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
二、Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
(1)Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
(2)Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
(3)Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









