







AUC计算公式推导
基本公式推算

基本排名的公式推算
2.详解如何计算AUC?
计算AUC时,推荐2个方法。
方法一:
在有M个正样本,N个负样本的数据集里。一共有MN对样本(一对样本即,一个正样本与一个负样本)。统计这MN对样本里,正样本的预测概率大于负样本的预测概率的个数。 ,其中,
,其中, 
这样说可能有点抽象,我举一个例子便能够明白。
| ID | label | pro |
|---|---|---|
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.35 |
| D | 1 | 0.8 |
假设有4条样本。2个正样本,2个负样本,那么M*N=4。即总共有4个样本对。分别是:
(D,B),(D,A),(C,B),(C,A)。
在(D,B)样本对中,正样本D预测的概率大于负样本B预测的概率(也就是D的得分比B高),记为1
同理,对于(C,B)。正样本C预测的概率小于负样本C预测的概率,记为0.
最后可以算得,总共有3个符合正样本得分高于负样本得分,故最后的AUC为
在这个案例里,没有出现得分一致的情况,假如出现得分一致的时候,例如:
| ID | label | pro |
|---|---|---|
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.4 |
| D | 1 | 0.8 |
同样本是4个样本对,对于样本对(C,B)其I值为0.5。
最后的AUC为 
方法二:
另外一个方法就是利用下面的公式:
这个公式看起来有点吓人,首先解释一下每一个符号的意思:
公式的含义见: 公式解释
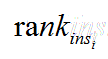 ,代表第i条样本的序号。(概率得分从小到大排,排在第rank个位置)
,代表第i条样本的序号。(概率得分从小到大排,排在第rank个位置)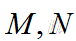 分别是正样本的个数和负样本的个数
分别是正样本的个数和负样本的个数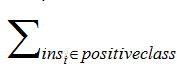 只把正样本的序号加起来。
只把正样本的序号加起来。
同样本地,我们用上面的例子。
| ID | label | pro |
|---|---|---|
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.35 |
| D | 1 | 0.8 |
将这个例子排序。按概率排序后得到:
| ID | label | pro | rank |
|---|---|---|---|
| A | 0 | 0.1 | 1 |
| C | 1 | 0.35 | 2 |
| B | 0 | 0.4 | 3 |
| D | 1 | 0.8 | 4 |
按照上面的公式,只把正样本的序号加起来也就是只把样本C,D的rank值加起来后减去一个常数项 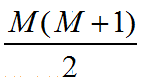
即:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









