






作者 | 林天威 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/4711051331
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
Pi-0 是Physical Intelligence 成立后的第一个论文工作(全公司都署名了,豪华阵容)。这篇论文主要关注如何实现robot foundation model,并聚焦在两个方面:Pre/Post-Training 策略;基于Flow-Matching 的action expert。从结果看,pi-0可以实现比较强的泛化能力,并能实现非常实时的推理。比起之前的OpenVLA 等工作,pi-0 在端到端VLA这条路线上向robot foundation model 迈进了很多。

Motivation
Pi-0 的核心motivation 是将LLM 和VLM 领域中已经经过考验的Pre/Post-Training 训练范式迁移到机器人具身模型的训练过程中来,即:
Pre-training:在大规模且非常多样性的互联网语料库上对模型做预训练;
Post-training:在更精心设计的数据集上fine-tune (or "align") 模型,使模型输出更符合预期;
如何将这个范式迁移到机器人领域呢?Pi-0 的训练,实质上是三步:
Internet-scale Pre-Training: Pi-0 是基于一个训练好的开源VLM 模型继续训练的,因此这个开源VLM 模型的训练实质上相当于是Pi-0 模型训练的第一个阶段,提供了模型的多模理解能力;
Pre-Training:基于团队构造的一个10000 小时机器人操作数据集,进行了大规模训练。实质上,Pre-Training 后,Pi-0 模型就已经可以处理见过的任务,并zero-shot泛化到一些不那么难的任务上
Post-Training:对于一些新的很困难的任务,需要5-100 小时数据进行fine-tune.
作者认为,要获得一个具备良好泛化能力的robot foundation model,主要有三方面挑战:
数据的规模要足够大(数据量、本体丰富度、任务丰富度等);
模型的架构要合理(支持高频控制,连续action space控制);
Training recipe 要合理(训练策略,数据配比等);
围绕这几个问题,Pi-0 的核心设计如下节介绍。
The Pi-0 Model
模型结构
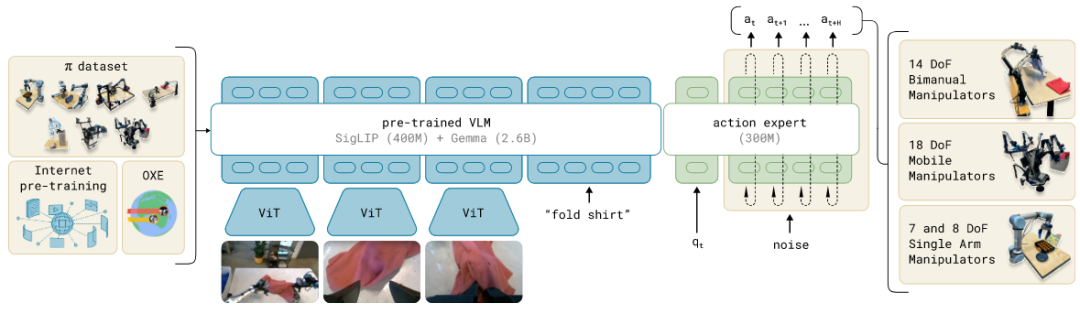
模型结构如上图所示:
模型基于一个Pre-Trained VLM (PaliGemma) 构建,其包含视觉Encoder 部分(SigLIP,400M)和Transformer 部分(Gemma,2.6B);
在预训练模型的基础上,Pi-0 通过MoE 混合专家模型的方式引入了一个action expert 来处理动作的输入和输出。这里是指,只有一个Transformer 模型,在处理文本和图像token 时,用的是原模型的参数;在处理action token 时,则用新初始化的action expert 的参数;
输入:模型的输入包括3帧最近的图像,文本指令,以及机器人本体信号(即各joint 当前angle)
输出:输出是称作action chunk 的形式,即未来一段时间的action 序列,这里的序列长度H 设定为50,对于50HZ 控制的情况,即相当于预测未来一秒钟的动作。这里action 的维度,设定为各个本体中最长的那个(18DoF),不够的本体则pad。(注意,这里action space 都设定在joint space,这有利于模型输出结果直接控制机械臂,避免了IK 解算环节)
Flow Matching as Action Expert
Flow matching 可以看作是diffusion 的一种变体,之前有听说但没仔细学习过,正好这次学习了下(知乎上也有很多不错的介绍文章,比如 笑书神侠:深入解析Flow Matching技术 )。Flow-Matching 主要是学习如何从一个噪声分布数据流形到目标分布数据流形之间的flow。Flow matching 的主要优势主要在于训练/推理方式比较简单、生成路径比较容易控制、稳定性更高等。Flow Matching +简单线性高斯概率路径的方案在生成任务上也获得了比较好的效果。
具体到Pi-0中:在action 预测任务中,在时间t我们要预测一个action chunk, 则优化目标为:
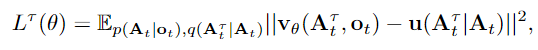
是 [0,1] 之间的数值,代表flow-matching 的timestep,0对应噪声分布,1对应目标分布;
即所对应的噪声流形到目标流形的中间流形。基于flow matching 的定义,我们可以将后验概率(即已知,来获得)表示为:
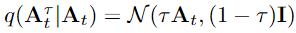
具体地,基于线性高斯路径策略,可以表示为(和扩散加噪过程很相似):
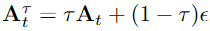
而在前面的训练损失函数中,我们实质监督的是,在这个时间点流形的 flow 或者说是速度方向(也因此这种训练方法叫做flow matching)。(,)指网络预测结果,其优化目标为:
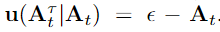
因此,diffusion 和flow matching 的训练都是一个去噪过程,但表示形式不同,前者预测的是添加的噪声,后者预测的是噪声到分布的方向。flow matching 可以通过控制优化路径来实现更灵活的生成控制。
在训练阶段,从一个beta 分布中采样(为了强调前段/噪声更多阶段的训练)。而在inferece 阶段,Pi-0 使用了10步均等步长(=0.1)的形式来实现flow matching 过程:
Pre-Training and Post-Training

作者认为预训练阶段最重要的就是diversity,用了一个10000小时规模的数据集训练:
数据集大部分是自采的(采集方式下一节介绍),仅9.1% 是开源的(Open-emb-x, droid 等)。数据集的自采集部分,包含了903 million timestep。
数据集中使用了多种本体,大部分都是双臂数据,基本都是aloha 数据
自采任务包含68个任务,但普遍都是比较复杂的符合任务,所以实质上包含的任务更多;
作者认为后训练阶段数据的要点是动作质量高,即动作要完成地一致且高效
Post-training 阶段的任务选择地和预训练有明显差异;
简单的任务,需要5小时数据,最复杂的任务需要100小时甚至更多;
Robot System

Pi-0 构造了一个还算比较丰富的多本体平台,如上图所示。具体信息整理如下:
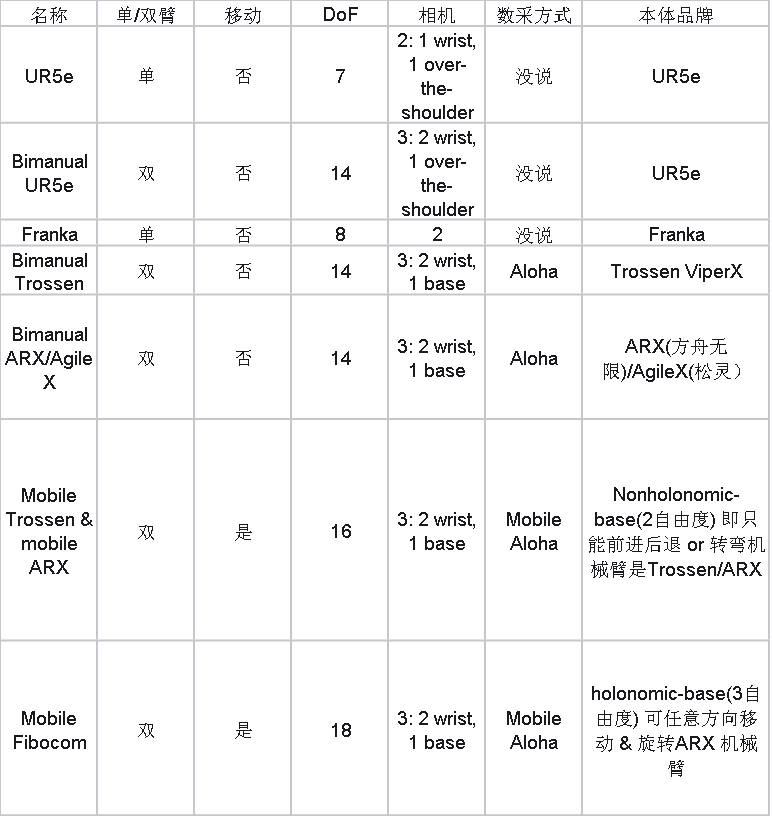
轻型机械臂用的都是Aloha 方案,主要是Trossen,ARX(方舟无限,国产)和AgileX(松灵,国产)
非轻型机械臂(UR5e 和Franka)用的不是Aloha 方案,没说啥采集方案。猜测应该是6D 鼠标等遥操设备。
这里面的所有任务都是夹爪,没做灵巧手;
Experiment
实验内容比较多,这里主要贴一下两个主要实验
Zero-shot evaluation
这个任务主要是想看Pre-Training 完的模型直接拿来用的效果,和OpenVLA,Octo 等方法比;


Pi-0 比OpenVLA 等方法效果好很多;
Pi-0-Parity 是训练步数比较少的模型 160k/700k,表明训练充分对模型效果影响很大
Pi-0-Small 是没有用Pretrain VLM 的模型,可以看出来效果也差了很多。
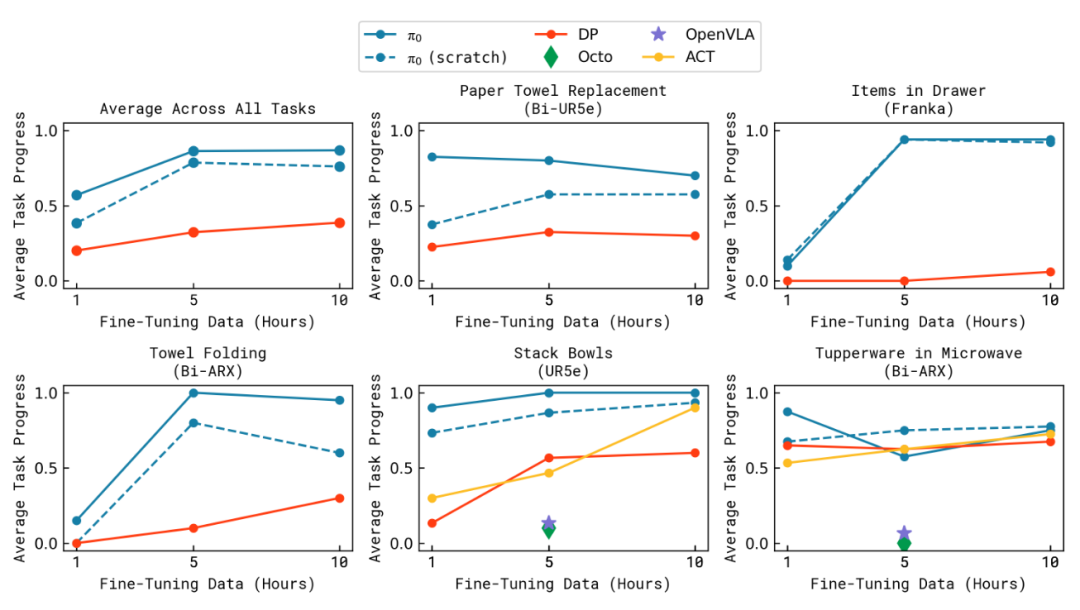
Post-Training Evaluation
在新的困难的灵巧任务上进行训练和测试:

部署 & 效率测评
这里补充一下附录里面提到的部署时的推理策略和推理效率。推理策略:
模型每次生成H timestep 的action chunk,H一般是50;
对于20Hz 控制的机械臂,需要2.5s 执行完;对于50HZ 控制的机械臂,需要1s 的执行完;
实质上,并不会等所有action 执行完再进入下一轮执行。对于20Hz 平台,在执行完16步(0.8s)后就会进入下一轮;对于50Hz平台,执行完25步(0.5s)后就会进入下一轮
这个执行策略,其实是每0.5s 做一次重新规划。这是因为Pi-0 并没有把历史决策作为输入,即这个模型并没有维护history 信息。所以这个方案实质上还是应该看作是一个开环方案。
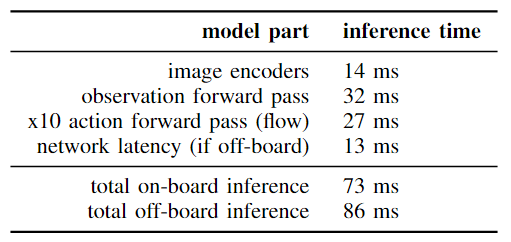
速度是在4090 上测试的,可以看出这个3.4B模型的推理还是很快的,应该用上了当前主流的推理加速
Off-board 指显卡不在设备上,通过wifi 通信,可以看出他们这个通信延迟做的也还行。
整体延迟控制在了100ms 内,这意味着他们其实最高可以以10FPS 频率来做重规划。
讨论 & 总结
Pi-0 方案可以看作是OpenVLA 这类VLA 方案的一次系统升级,主要是更好的训练数据 + 更好的Policy Head。而且Policy Head 和VLM 模型连接的方式,可能是一种很好的大小脑系统连接的路径。整个方案系统性很强,值得细读学习,整体读下来感觉也很好。
除了优点,还是有不少槽点和疑惑点的:
从预训练的层面,这篇工作似乎并没有带来太多新东西。当前大家对于“具身预训练”这个话题,可能更多还是希望能够减少需要大量人力投入的遥操数据采集环节。所以,这篇文章里面的Pre-Training,可能实质上对应的是我们认为的Post-Training,而Post-Training 对应的则是我们认为的few-shot adaption。
文章中提到一个观点:“高质量数据不能教会模型如何从错误中恢复”,那言下之意应该是低质量数据中一下错误后重新尝试的数据对这方面有帮助。这个观点很认同,但文中其实并没有分析训练数据中是否真的有这类数据,也没有做相关的佐证实验。
Pi-0 的框架没有加入history 我感觉还是比较可惜的,或许是他们的下一步吧;
模型部分,不同本体似乎没有加一个区分指示的token,只靠action space 维度区分不太靠谱;同时Pi-0 也没有展示本体层面的泛化能力。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









