







1.elasticsearch元素简介
- node、replica和shard
node表示elasticsearch集群中的一台虚拟机机器,其作用是提升分布式应用的容错性和可用性。其中每个虚拟机(节点)只有一个索引的所有shards的一部分。
replica相对于数据的备份,其主要是表示一个索引的备份,其通过number_of_replicas来设置除主数据索引外,还有多少个备份索引。类似于数据库中的备库作用。replica的作用主要是提供数据的容错性和读的可用性、并发度与吞吐量。
shard表示一个索引要被分为多少个shard,其通过number_of_shards来设置一个索引有多少个shard构成,其中同一个节点不存在同样的shard.
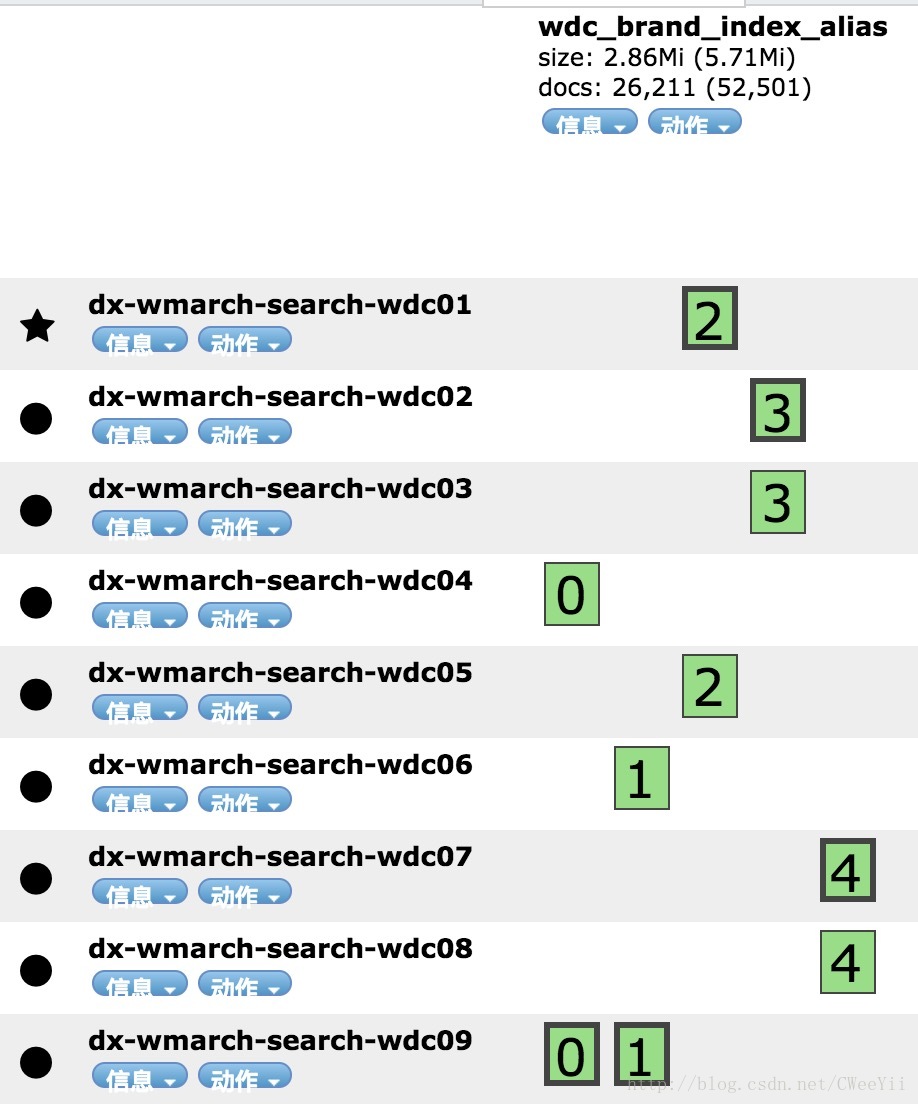
如上图所示:elasticsearch集群中有9个node. 其中wdc_brand_index_alias索引由5个shard构成(number_of_shards=5),索引备份数量是1(number_of_replicas=1),加上主索引总共为2。例如在索引中的主shard是通过黑边框来表示的,索引的主shard分布在0=dx-wmarch-search-wdc09 1=dx-wmarch-search-wdc09 2=dx-wmarch-search-wdc01 3=dx-wmarch-search-wdc02 4=dx-wmarch-search-wdc07。同时将索引的主shard放在不同的机器上主要是提升索引的更新效率,在主shard更新后其会同步到从shard上。具体执行过程会在索引和docId讲解。 - docId和routing
Elasticsearch的路由机制与其分片机制有着直接的关系。Elasticsearch的路由机制即是通过哈希算法,将具有相同哈希值的文档放置到同一个主分片中。这个和通过哈希算法来进行负载均衡几乎是一样的。而Elasticsearch也有一个默认的路由算法:它会将文档的ID值作为依据将其哈希到相应的主分片上,这种算法基本上会保持所有数据在所有分片上的一个平均分布,而不会产生数据热点。
自定义的Routing模式,可以决定数据的在主shard的分布,这样使我们的查询更具目的性。我们不必盲目地去广播查询请求,取而代之的是:我们要告诉Elasticsearch我们的数据在哪个分片及其备份分片上。 - 文档的新建、索引和删除
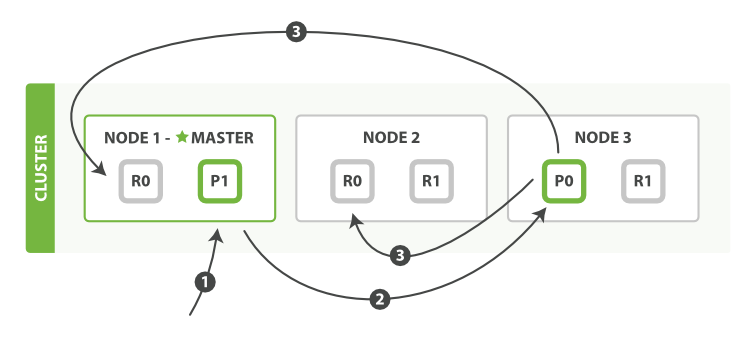
其过程如下:1)客户端将请求发送到master node上 2)master node根据routing字段路由到指定shard上(图中node3 的P0节点),并更新文档信息(对于删除操作只将该文档标记为删除状态,在索引进行合并的时候才会真正的删除文档数据。对于新增操作只是将该文档添加到索引中。对于更新操作其转化为删除+新增) 3)主备数据的同步过程,将主shard的更新结果同步到备shard上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。 - replication
复制默认的值是sync。这将导致主分片得到复制分片的成功响应后才返回。保证数据的强一致性。
如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
默认的sync复制保证主从数据的强一致性。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载,造成主从同步,其保证的是最终一致性。 - consistency
sync方式并不是要求所有的操作都成功之后才会返回给客户端,其只要求过半分片成功即可(paxos算法)。 - timeout
当分片副本不足时会怎样?Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置timeout参数让它终止的更早:100表示100毫秒,30s表示30秒。
注意:新索引默认有1个复制分片,这意味着为了满足quorum的要求需要两个活动的分片。当然,这个默认设置将阻止我们在单一节点集群中进行操作。为了避开这个问题,规定数量只有在number_of_replicas大于一时才生效。 - 检索文档(路由方式)
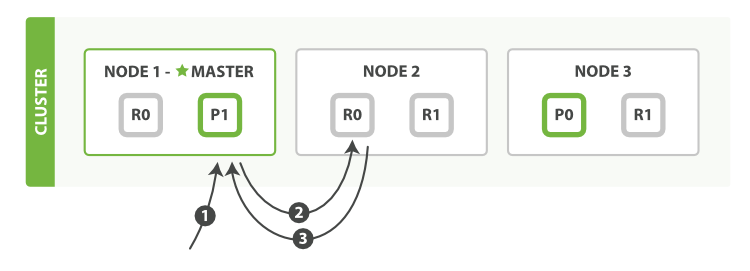
下面我们罗列在主分片或复制分片上检索一个文档必要的顺序步骤:
客户端给Node 1发送get请求。
节点使用文档的_id确定文档属于分片0。分片0对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。
Node 2返回文档(document)给Node 1然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。读副本是有可能出现主有从无的情况。但是sync方式会保证写成功后,所有的读都是强一致性的。 - 检索文档(非路由方式)

阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
所以非路由的方式会检索整个索引,而路由的方式只会检索一个shard,因此效率更高。
2.elasticsearch与关系数据库对应关系
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns
Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
其中常用的mapping字段是:index对应于database,type对应于table,row对应document,column对应于field。
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
正如数据操作一样:查询时需要数据库.数据表的形式,elasticsearch查询时也需要 megacorp(索引)/employee(type),在elasticsearch的type对应于java中的domain对象。
GET /megacorp/employee/_search?q=last_name:Smith3.elasticsearch集群节点
- 可选为master节点:node.master=true node.data=false。该类型的节点有几率成为master节点,该类型节点提供如下功能:1)节点的自动发现(集群中节点崩溃移除节点;节点恢复加入到集群)2)搜索、更新、删除操作的路由功能,将指点数据的操作路由到指定的shard上 3)搜索操作的二级聚合(将每个shard的搜索结果进行汇总和排序)[默认所有节点都具有二级聚合的功能]
- data节点:node.master=false node.data=true。该类型的节点负责具体的索引操作:新增、修改、删除、搜索。因此该节点需要高CPU、高内存的机器。同样具有二级聚合的功能
- client节点:node.master=false,node.data=false。该类型节点只提供搜索结果的二级聚合功能。
- 默认可master和data节点:节点默认是即可以成为master节点,同样具有存储检索索引功能的data节点。其具有上面介绍的所有功能。因此该类型节点在搜素或者更新操作很频繁的时候,容易被其他机器人为宕机,从而进行重新选主,造成集群的脑裂。(集群中同时存在两个master节点,并且被不同的机器follow)
集群选型:
- 轻量型服务:全部节点都可以设置为node.master=true,node.data=true,可以更高的利用集群中机器的性能。
- 高访问量服务:提供三台node.master=true node.data=false的节点,三台的目的是防止单点故障和脑裂的发生(过半原理(N+1)/2)。其他的机器作为node.master=false node.data=true的索引机器,并根据集群中索引机器数量,合理的设置shard的数量,提高并发度,降低集群压力。shard = hash(routing) % number_of_primary_shards。如果觉得检索性能还有瓶颈还可以考虑加入一些client类型机器node.master=false node.data=false,专门负责检索的二级聚合。















 3734
3734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









