



MySQL
简述下 WHERE 和 HAVING 的区别?
- WHERE:
- 在分组聚合之前进行过滤
- 后面不能接聚合函数
- HAVING:
- 在分组聚合之后进行过滤
- 后面可以接聚合函数
简述下 DROP、DELETE、TRUNCATE的区别?
- DROP:
- 将表直接删除
- DELETE:
- 将表中的数据清空,如果有自增,则不会把其索引清零
- TRUNCATE:
- 将表中的数据清空,如果有自增,则会把其索引清零
简述下 UNION 和 UNION ALL 的区别?
- UNION:
- 拼接两个表时会去重
- UNION ALL:
- 拼接两个表时不会去重
简述下 GROUP BY 和 PARTITION BY 的区别?
- GROUP BY
- 对指定的列进行分组;输入多行,输出一行,属于多进一出
- PARTITION BY
- 对指定的列进行分区;输入一行,输出一行,属于一进一出
Hadoop
简述下分布式和集群的区别?
-
分布式: 把一个任务拆分成很多个子任务,每个服务器运行相应的子任务。(即多个设备独立干同个工作下拆分的子工作)
-
集群: 多台服务器联合起来独立做相同的任务。(多个设备独立干同一个工作)
-
例子: 以做菜为例(做菜包含备菜,切菜,炒菜);为了提高效率,雇了3位厨师,每位厨师都对做菜进行备菜,切菜,炒菜,这就是集群的工作方式。如果一位去备菜,一位去切菜,一位去炒菜,这就是分布式的工作方式。
简述Hadoop技术栈的组成?
-
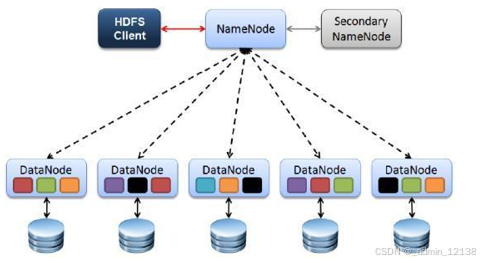
HDFS:分布式文件系统,解决海量数据存储
-
HDFS Client:
- 就是一个客户端
- 进行文件切分,当文件上传时,把该文件切分成一个一个的Block(默认128M),然后进行存储
-
NameNode:
- 相当于一个管理者
- 主要管理HDFS的元数据
- 元数据:
- 存储数据的数据,即文件路径,文件大小,文件名字,文件权限,文件的Block切片信息等。
- 元数据:
-
SecondaryNameNode:
- 它不是NameNode的热备,即当NameNode挂掉时,不能马上替换其并提供服务
- 非热备主要原因:
- 只有当NameNode存储到一定容量时,才会交付给SecondaryNameNode进行备份整合,所有如果NameNode挂掉时还未到一定交付容量,则会丢失这部分数据
- 非热备主要原因:
- 主要辅助NameNode进行元数据的储存
- 它不是NameNode的热备,即当NameNode挂掉时,不能马上替换其并提供服务
-
DataNode:
- 主要用于存储真实的数据库
- 主要用于存储真实的数据库
-
-
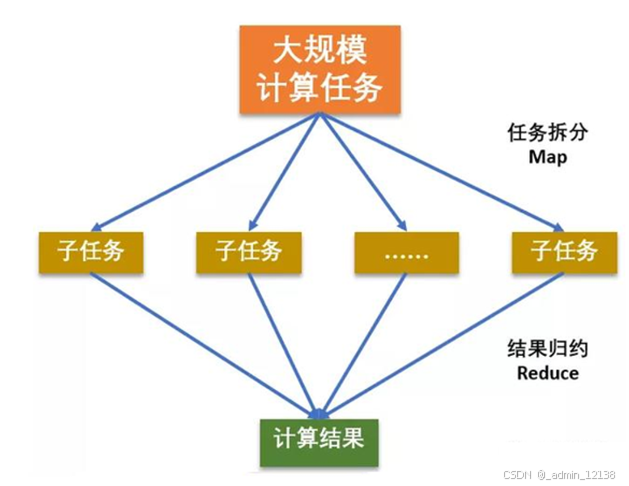
MapReduce:分布式运算编程框架,解决海量数据计算
- 核心思想
- 分而治之
- Map负责分解
- Reduce负责合并
- 核心思想
-
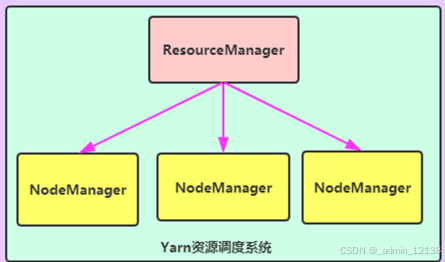
YARN:作业调度和集群资源管理框架,解决资源任务调度
- ResourceManager
- 相当于一个管理者
- 接收用户计算请求任务
- 负责集群的资源管理和分配
- NodeManager
- 负责执行管理者分配的任务
- 给MR的计算程序提供资源
- ResourceManager
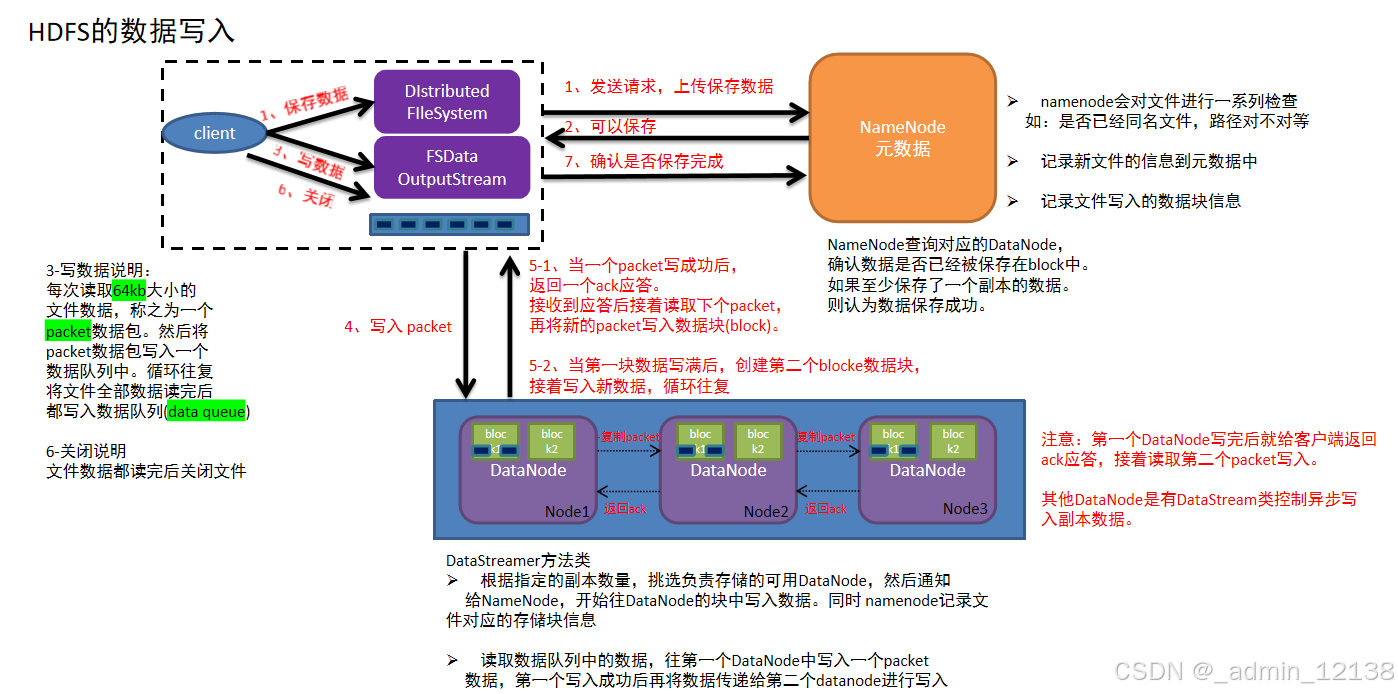
简述HDFS的数据写入
-
客户端发起写入数据的请求给namenode
-
namenode接收到客户端请求,开始校验(是否有权限,路径是否存在,文件是否存在等),如果校验没问题,就告知客户端可以写入
-
客户端收到消息,开始把文件数据分割成默认的128m大小的的block块,并且把block块数据拆分成64kb的packet数据包,放入传输序列
-
客户端携带block块信息再次向namenode发送请求,获取能够存储block块数据的datanode列表
-
namenode查看当前距离上传位置较近且不忙的datanode,放入列表中返回给客户端
-
客户端连接datanode,开始发送packet数据包,第一个datanode接收完后就给客户端ack应答(客户端就可以传入下一个packet数据包),同时第一个datanode开始复制刚才接收到的数据包给node2,node2接收到数据包也复制给node3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道
-
其他packet数据根据第一个packet数据包经过的传输通道和应答通道,循环传入packet,直到当前block块数据传输完成(存储了block信息的datanode需要把已经存储的块信息定期的同步给namenode)
-
其他block块数据存储,循环执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(namenode把该文件的元数据保存上)
-
最后客户端和namenode互相确认文件数据已经保存完成(也会汇报不能使用的datanode)
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
我自己的理解:
-
客户端给namenode发起写入数据的请求,收到请求后验证是否符合要求,若符合则告诉客户端可以写入;客户端收到可以应答后,对文件数据切分成默认128M大小的block块,并把块再细分为64kb的数据包;准备工作完成后,告诉namenode数据准备妥当,请求获取存储block块的datanode列表。
-
namenode会查看当前上传时间最短且空闲的datanode,整理好列表告知客户端;客户端收到列表信息开始发送数据包,当第一个datanode接受成功后,给客户端返回一个ack应答,如此客户端就会开始发送下一个数据包,与此同时第一个datanode也会复制刚才接受成功的数据包给第2个datanode,第二个接受成功再复制给第三个datanode,复制成功后都会返回一个ack应答;直至把整个block块传输成功。全部传输成功后,datanode会把已经存储成功的块信息同步给namenode。
-
如果整个文件只有一个block块,那么文件写入成功,客户端和namenode会相互确认保存成功的信息,同时也会汇报不能使用的datanode;如果有多个block块,那么客户端继续给namenode请求存储列表,上传其余的block块。
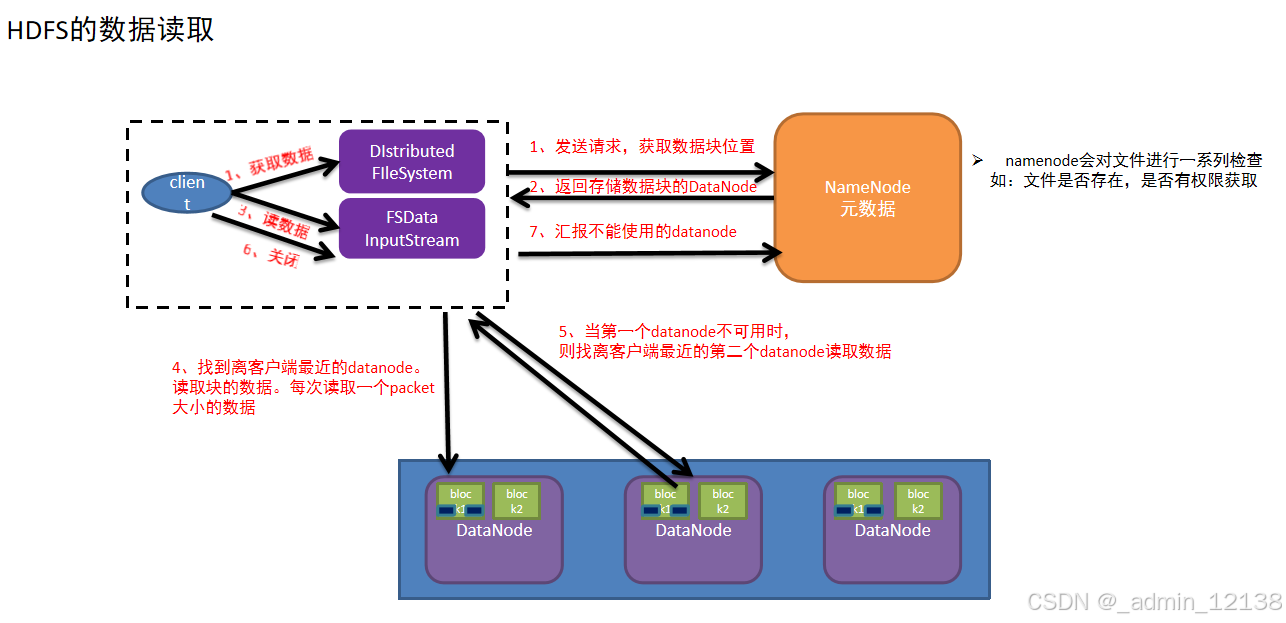
简述HDFS的数据读取
-
客户端发送读取文件请求给namenode
-
namdnode接收到请求,然后进行一系列校验(路径是否存在,文件是否存在,是否有权限等),如果没有问题,就告知可以读取
-
客户端需要再次和namenode确认当前文件在哪些datanode中存储
-
namenode查看当前距离下载位置较近且不忙的datanode,放入列表中返回给客户端
-
客户端找到最近的datanode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包)放到内存缓冲区中
-
接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据)
-
最后从内存缓冲区把数据通过流写入到目标文件中
-
最后客户端和namenode互相确认文件数据已经读取完成(也会汇报不能使用的datanode)
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
我自己的理解:
-
客户端给namenode发送读取请求,namenode接受到请求后,进行验证,如果符合要求,告知客户端可以读取;客户端收到可以读取的消息后,给namenode发送请求确认读取文件在哪个datanode中;namenode收到请求,会查看距离最近且空闲的datanode,放入列表中返回给客户端。
-
客户端得到列表后,与最近的datanode开始互通,读取相对应的文件block块信息,每次都是以64kb的数据包形式进行传输,客户端接收到的数据包会存入内存缓冲区;如果读取文件只有一个block块,则读完即可,如果有多个block块,客户端会继续与namenode确认其余块存储位置,以及与其余存储块信息的datanode进行互通,并传输数据包,直至该文件所有block块全部读取完毕到内存缓冲区。
-
客户端在内存缓冲区把所有数据包整合,得到完整文件数据,最后客户端再与namenode互相确认文件已经读取完毕,也会汇报不能使用的datanode。
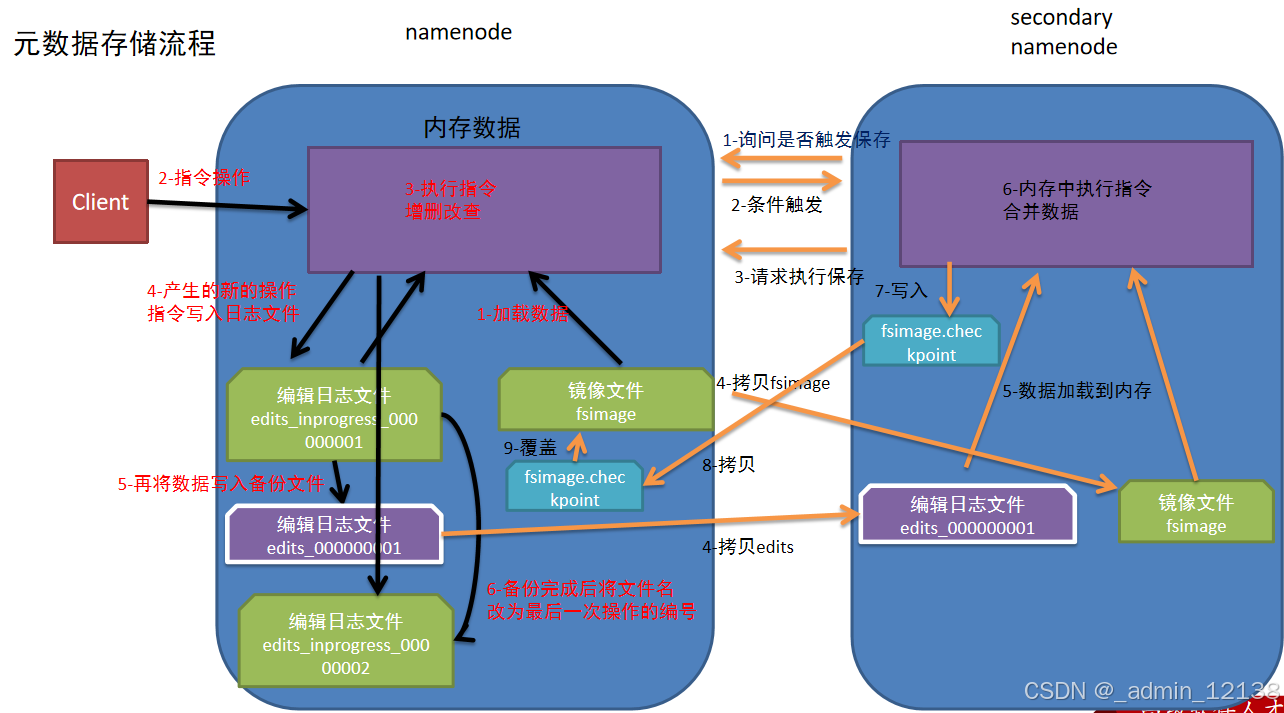
简述元数据存储流程
-
namenode第一次启动的时候先把最新的fsimage文件中内容加载到内存中,同时把edits文件中内容也加载到内存中
-
客户端发起指令(增删改查等操作),namenode接收到客户端指令把每次产生的新的指令操作先放到内存中
-
然后把刚才内存中新的指令操作写入到edits_inprogress文件中
-
edits_inprogress文件中数据到了一定阈值的时候,把文件中历史操作记录写入到序列化的edits备份文件中
-
namenode就在上述2-4步中循环操作…
-
当secondarynamenode检测到自己距离上一次检查点(checkpoint)已经1小时或者事务数达到100w,就触发secondarynamenode询问namenode是否对edits文件和fsimage文件进行合并操作
-
namenode告知可以进行合并
-
secondarynamenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行合并(这个过程称checkpoint)
-
secondarynamenode把刚才合并后的fsimage.checkpoint文件拷贝给namenode
-
namenode把拷贝过来的最新的fsimage.checkpoint文件,重命名为fsimage,覆盖原来的文件
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
我自己的理解:
-
namenode第一次启动的时候把最新的fsimage文件内容和edits文件内容加载到内存中,客户端发起增删改查的操作,namenode接收到客户端发出的指令,并把产生的新指令操作放到内存中;之后再把刚才内存中所存的指令写入到edits_inprogress文件中;edits_inprogress文件中的数据到了一定阈值的时候,会把文件写入到edits备份文件中。
-
当secondarynamenode检测到已经满足检查点中的一个(时间已经到了1小时,或者事务已经达到100w次),就会触发secondarynamenode询问namenode是否对edits和fsimage文件进行合并操作;当namenode告知可以时,secondarynamenode会把当前积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行合并。
-
namenode会把拷贝过来的最新fsimage.checkpoint文件,重命名为fsimage,并成为下次开机启动时加载的最新fsimage文件。
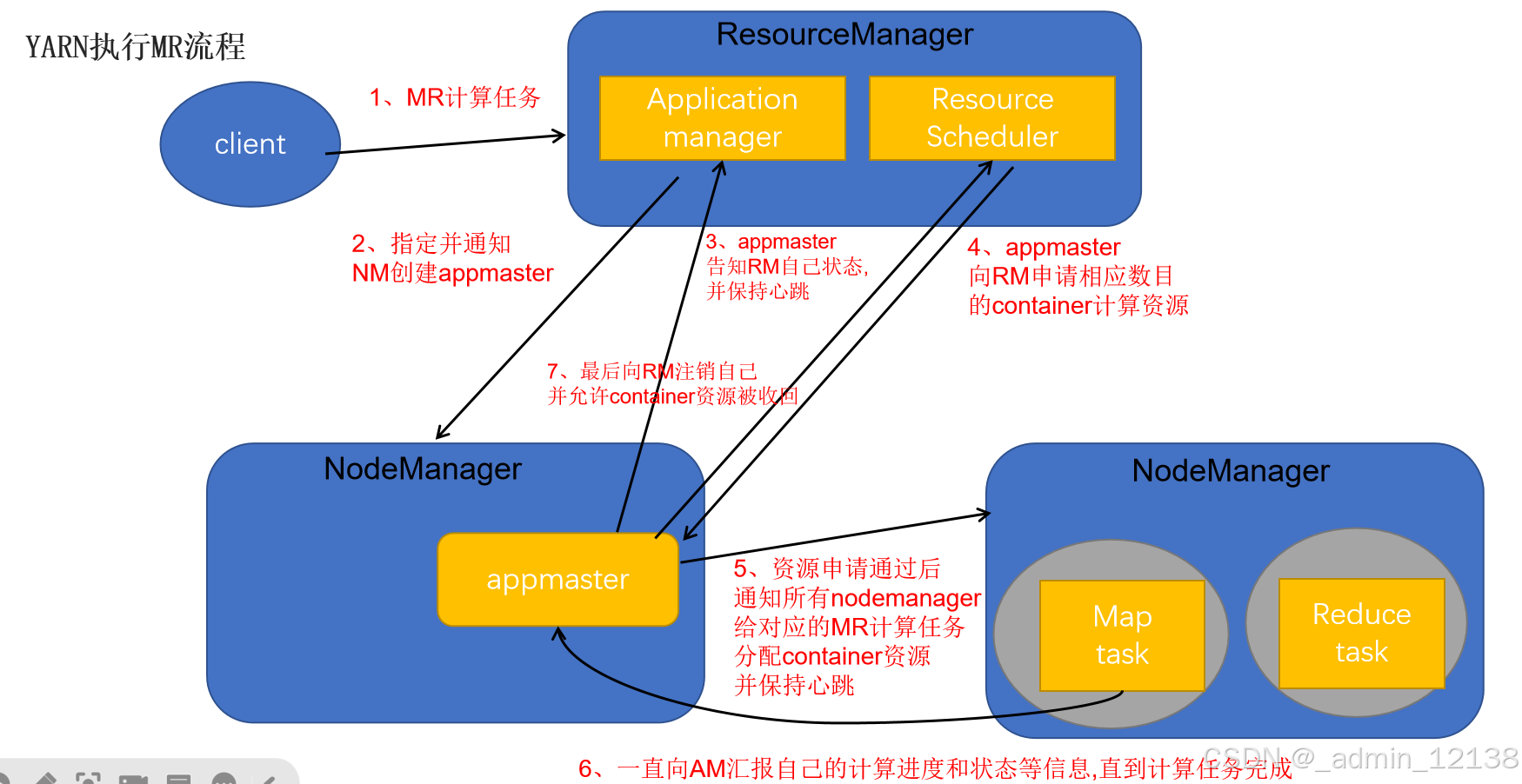
简述YARN提交MR流程
-
客户端提交一个MR程序给ResourceManager(校验请求是否合法…)
-如果请求合法,ResourceManager随机选择一个NodeManager用于生成appmaster(应用程序控制者,每个应用程序都单独有一个appmaster) -
appmaster会主动向ResourceManager的应用管理器(application manager)注册自己,告知自己的状态信息,并且保持心跳
-
appmaster会根据任务情况计算自己所需要的container资源(cpu,内存…),主动向ResourceManager的资源调度器(resource scheduler)申请并获取这些container资源
-
appmaster获取到container资源后,把对应指令和container分发给其他NodeManager,让NodeManager启动task任务(maptask任务,reducetask任务)
-
NodeManager要和appmaster保持心跳,把自己任务计算进度和状态信息等同步给appmaster,(注意当maptask任务完成后会通知appmaster,appmaster接到消息后会通知reducetask去maptask那儿拉取数据)直到最后任务完成
-
appmaster会主动向ResourceManager注销自己(告知ResourceManager可以把自己的资源进行回收了,回收后自己就销毁了)
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
我自己的理解:
-
客户端提交一个MR程序给ResourceManager,ResourceManager验证是否符合要求,如果符合,将随机选择一个NodeManager用于生成appmaster,该appmaster会主动向ResourceManager注册自己,告知自身状态,并与其保持心跳;appmaster会根据任务情况计算所需资源,计算完后主动向ResourceManager的资源调度器申请并获取这些container资源
-
appmaster获取到资源后,把对应指令和container分配给其他NodeManager,让这些NodeManager启动task任务,NodeManager和appmaster始终保持心跳,把自己任务计算进程和状态信息告知给appmaster;当maptask任务完成后会通知appmaster,其接收到消息会通知reducetask,让其去maptask那拉取数据,直到最后任务完成
-
任务完成后,appmaster会主动向ResourceManager注销自己,并告知其可以把配分的资源进行回收,销毁
简述hadoop的两种发行版本(CDH、Apache)的优缺点
- Apache
- 优点
- 开源免费:无需付费
- 文档详细,方便学习和解决问题
- 缺点
- 维护麻烦
- 各个组件兼容性复制
- 优点
- CDH
- 优点
- 稳定性强,兼容性好
- 更新速度快
- 维护简单
- 缺点
- 灵活性不高
- 成本大
- 优点
Hive
简述下 ETL 和 ELT 的区别?
- ETL: 抽取Extract, 转化Transform , 装载Load 的过程
- 将数据从源系统中抽取出来,经过转换处理后再加载到目标系统中
- 适用于数据清洗和整合
- 转换过程中使用独立的服务器和批处理作业
- ELT: 抽取Extract, 装载Load, 转化Transform 的过程
- 将数据直接加载到目标系统中,然后在目标系统中进行转换和处理
- 适用于实时响应和分析
- 处理性能取决于目标系统的计算和存储能力
请简述Hive元数据服务配置的三种模式?
-
内嵌模式
- 优点
- 配置简单 Hive命令可以直接使用
- 缺点
- 不适用于生产环境,derby和Metastore服务都嵌入在Hive Server进程中
- 一个服务只能被一个客户端连接(如果使用客户端较多,非常浪费资源)
- 元数据不能共享
- 优点
-
本地模式
- 优点
- 可以单独使用外部的数据库(如MySQL)
- 元数据可以共享
- 缺点
- 相对浪费资源,Metastore嵌入到了Hive进程中,每启动一次Hive服务,则会内置启动一个Metastore
- 优点
-
远程模式
- 优点
- 可以单独使用外部数据库(如MySQL)
- 可以共享元数据
- 本地可以连接接Metastore服务,也可以连接hiveserver2服务
- 增加了扩展性(其他依赖Hive的软件都可以通过Metastore访问Hive)
- 缺点
- 如果想要启动Hiveserver2服务,需要先启动Metastore服务
- 优点
数据库和数据仓库的区别?
- 数据库:
- 面向事务的设计
- 捕获数据而设计
- 一般存储业务数据
- 尽量避免冗余,处理小数据
- 数据仓库:
- 面向主题设计
- 分析数据设计,只做查询和少量插入操作,因此有很强的稳定性和鲁棒性
- 一般存储历史数据,反映历史变化
- 特意引入冗余,处理大数据
简述下数仓经典三层架构?
- ODS层(原始数据层)
- 又叫贴源层
- 用来存储原始数据,做备份
- DW层(数据仓库层)
- DWD(数据细节层)
- 用来对数据进行清洗(即过滤无效和垃圾数据)、转换(即字段名、格式处理)
- DWM(数据中间层)
- 使用join联合多张表形成明细宽表
- 例如
- 订单表、订单配送表、订单退款表、订单评价表… --> 订单明细宽表
- DWS(数据服务层)
- 对DWM层数据计算得到指标和维度,形成汇总宽表(即数据集市)
- DWD(数据细节层)
- ADS层(数据应用层)
- 根据需求方的需求,读取DWS层的数据,进行分析计算,得到要求的可视化数据
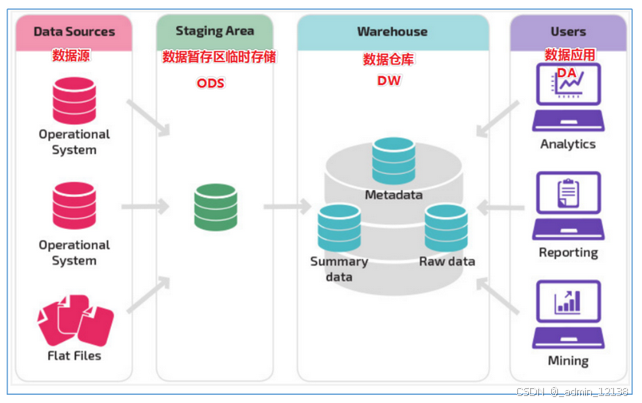
- 根据需求方的需求,读取DWS层的数据,进行分析计算,得到要求的可视化数据
简述Hive的调优
-
Hive数据压缩: 使用黄金组合ORC文件格式数据+snappy压缩算法,通常都是直接在建表时进行指定;snappy算法相比于其他算法压缩和解压效率均更有性价比
-
行列存储: 对表进行列存储,即ORC文件格式,能大大提高查询效率
-
fetch抓取: 设置more方案,这样会保证更多的sql操作不走MR,如全表扫描、查询某几个列、简单的limit操作以及简单条件查询这四种都不会走MR
-
local本地模式: 设置本地模式,当输入数据都满足小于以下这两个特性后,才能执行本地;即设置本地MR最大处理的数据量,设置本地MR最大处理的文件数量
-
分区裁剪: 当执行sql时,能在join之前执行的条件过滤操作,一定要提前过滤;如果操作的是一张分区表,那么查询的时候一定要带上分区字段,来减少扫描的数据量,从而提高效率
-
执行计划explain: 模拟优化器执行sql查询语句,查询后可以查看sql是如何处理,从而帮助我们了解底层原理,进而辅助调优
-
join优化: 通过map join解决数据倾斜问题,仅适用于小表和大表之间的join;针对于大表与大表之间,可以使用提前过滤,即join之前先把能过滤的条件过滤完,再join;如果表中有很多NULL值也可以使用将NULL值替换为随机数,从而减少数据倾斜;可以创建分桶表,把大文件分成多个小文件
-
列裁剪: 在读取数据的时候,只读取有效列数据,从而忽略其他无关列信息
-
count(distinct): 如果需要进行去重操作,可以使用先分组再聚合的方式,这样会执行两个MR,但当数据量够大时,会节省效率
-
动态分区: 创建一个新的动态分区的数据表,需要先关闭动态分区的严格模式
-
并行执行: 当服务器有资源时,可以把没有关联的MR并行执行,不必排队等候
-
严格模式: 限制一些效率极低的sql,即执行order by 不加 limit;出现笛卡尔积现象的sql;查询分区表,不带分区字段
-
笛卡尔积: 避免导致笛卡尔积现象,即避免join时不加on条件,或者无效的on条件;关联条件不要放置在where语句;无法确认关联条件,建议确认清楚再关联
-
JVM重用: 开启后,运行container的容器可以重复使用
-
推测执行: 推测出执行MR很久的任务,并为其启动一个备份任务,让其与原任务同时处理数据,并选用最先成功运行的任务结果作为最终结果;建议关闭
简述三范式建模和维度建模的区别
-
三范式: 无重复、冗余的数据
- 特点
- 原子性: 不可再分性
- 唯一性: 避免部分依赖
- 非主键字段依赖于联合主键的部分字段
- 独立性: 消除传递依赖
- 一个非主键字段依赖于另一个非主键字段,即非主键字段之间相互依赖
- 特点
-
维度建模: 支持重复、冗余数据
简述数据仓库分层的特点
- 分层后为单向依赖(即有向无环图),可以避免循环依赖
- 结构清晰,易于查找使用
- 一步拆分为多步,分析难度降低
- 复用中间表
- 性能提高
- 易于维护
简述什么是维度和指标?
-
维度
-
字符串类型、特征数据
指标 -
数值类型、行为数据
SQL例子
SELECT
-- 指标: 订单量字段、销售额字段
COUNT(订单id) 订单量,
SUN(订单价格) 销售额
FROM 订单表
-- 维度: 日期字段、城市字段
GROUP BY 订单日期, 城市;
简述下关系建模的中的ER模型
- 在需求调研时,创建ER模型
- 实体
- 矩形
- 属性
- 椭圆
- 关系
- 棱形
简述下维度建模中事实表和维度表的区别
- 事实表 -> 订单表、访问记录表
- 行为数据
- 数据量大
- 更新频率快
- 维度表 -> 商品表、日期表、地区表
- 特征数据
- 数据量小
- 更新频率较低
简述下事实表和维度表的分类
- 维度表分类
- 高基数维度表 -> 数据量多、可辨识度高
- 低基数维度表 -> 数据量少、可辨识度低
- 事实表分类
- 事务事实表
- 每个行为都是一行数据
- 周期快照事实表
- 在一定周期内,对业务的状态进行汇总
- 累积快照事实表
- 行为数据的全流程信息,包含了多个不同的时间字段,比如订单明细宽表
- 事务事实表
简述下维度建模的三种模型
-
星型模型
- 优点
- 性能高
- 缺点
- 结构复杂
- 优点
-
雪花模型
- 优点
- 结构清晰
- 缺点
- 性能低
- 优点
-
星座模型
- 优点
- 同星型模型
- 与星型模型的区别
- 星型模型只有一张事实表,星座模型有多张事实表共同复用维度表
- 优点
ZooKeeper
简述下ZooKeeper的各个类型节点,以及各类型的的特点
- 持久节点
- 一但创建,不会随着会话的断开就删除,一直存在于zookeeper服务器上
- 临时节点
- 会话断开就会删除该节点,再次创建会话时已经不存在
- 不能有子节点
- 序列节点
- 创建节点后,会在节点名后自动增加10位序列号
- 容器节点
- 当该节点的最后一个子节点被删除时,该节点也会被自动删除
- TTL节点
- 针对持久性的节点,可以设置一个存活时间,如果在存活时间内这些节点没有任何修改且没有子节点,将自动删除这些节点
简述下ZooKeeper如何进行选举
- 场景1: 集群首次启动时的选举
- 当集群中的每台服务器启动时,会将自己作为leader候选人,投票内容包括了自身的myid(服务器编号)和zxid(事务id)
- 每台服务器会将自身的投票信息发送给集群中其他开启的服务器,并接收其他服务器的投票信息
- 接收到投票信息后,每台服务器都会优先比较zxid(事务id),zxid(事务id)较大的服务器优先作为leader,如果zxid(事务id)相同,则再比较myid(服务器编号),myid(服务器编号)较大的服务器作为leader
- 只要有过半的服务器都投给了同一个服务器,那么该服务器则被选为leader,其他服务器都为follower
- 场景2: 运行过程中leader故障时的选举
- 所有正常的服务器会重新发起投票,投票规则与首次启动一致,都优先投自身
- 服务器会接收其他服务器的投票信息,跟首次启动时的规则一致,优先比较zxid(事务id),zxid(事务id)大的优先为leader;如果zxid(事务id)相同,则再比较myid(服务器编号),myid(服务器编号)大的优先为leader
- 如果有过半的服务器都投给同一个服务器,那么该服务器则被选为新的leader,其他服务器都为follower


















 737
737



 到【灌水乐园】发言
到【灌水乐园】发言








