







引言
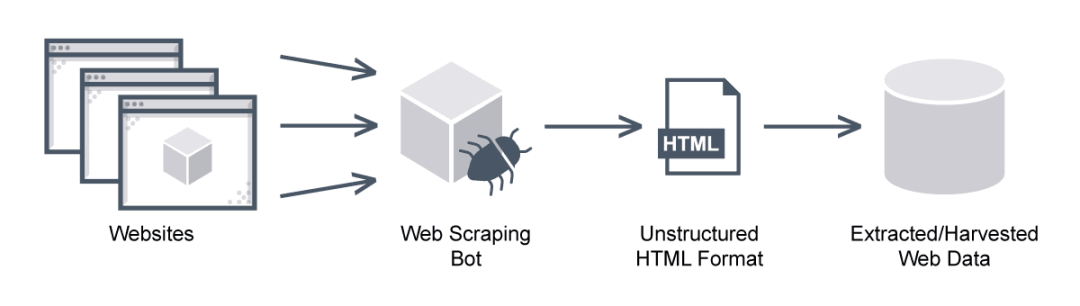
爬虫,又称为网络爬虫或网页爬虫,是一种自动浏览互联网的程序,它按照一定的算法顺序访问网页,并从中提取有用信息。爬虫软件通常由以下几部分组成:
- 用户代理(User-Agent):模拟浏览器访问,避免被网站识别为机器人。
- 请求处理:发送HTTP请求,获取网页内容。
- 内容解析:使用正则表达式或DOM解析技术提取所需数据。
- 数据存储:将提取的数据保存到数据库或文件中。
- 错误处理:处理请求超时、服务器拒绝等异常情况。
下面介绍几个我经常用的爬虫插件和工具,入门非常简单。
亮数据(Bright Data)
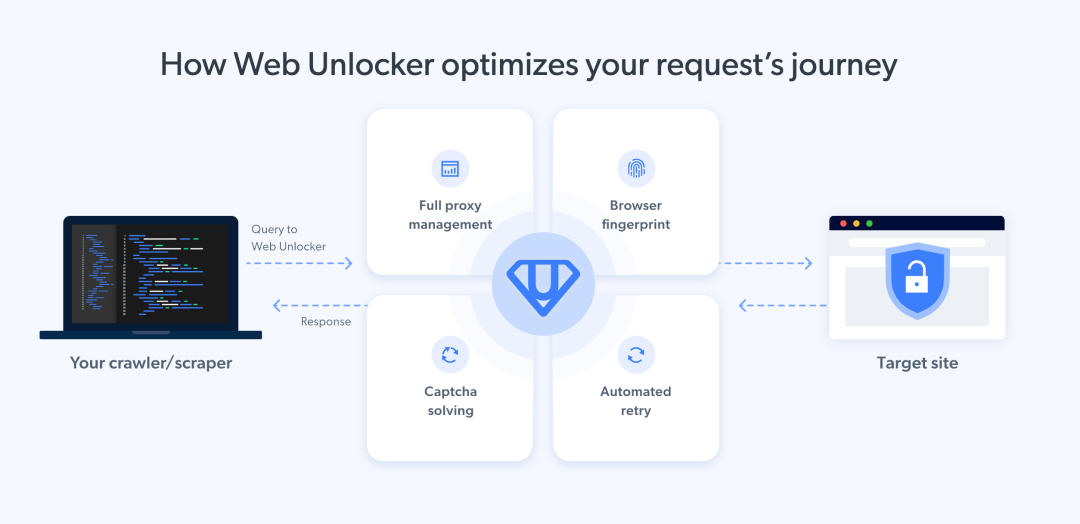
亮数据是一款强大的数据采集工具,以其全球代理IP网络和强大数据采集技术而闻名。它能够轻松采集各种网页数据,包括产品信息、价格、评论和社交媒体数据等。
网站:https://get.brightdata.com/weijun
「功能与特点:」
-
全球网络数据采集:提供一站式服务,将全网数据转化为结构化数据库。
-
商用代理网络:拥有超过7200万个IP,覆盖195个国家,每日更新上百万IP。
-
高效数据采集:能够达到170000请求/秒,每天处理高达1PT的网络流量。
-
技术驱动:拥有超3300项授权专利申报,持续引领行业创新。
-
稳定性:提供99.99%的稳定运行时间,即使在网络高峰期间也能保持稳定。
「使用方法:」
-
注册亮数据账号。
-
创建爬虫任务,选择合适的数据源和爬虫模板或编写爬虫代码。
-
设置任务参数,包括采集规则和数据存储选项。
-
启动任务,开始数据采集。
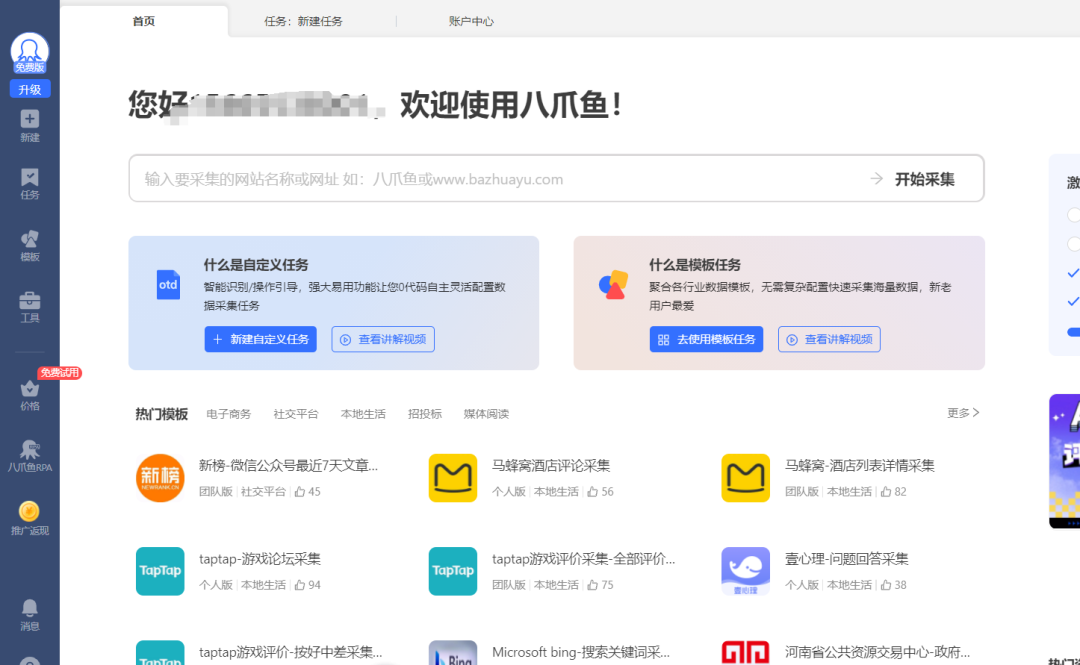
八爪鱼采集器
八爪鱼是一款面向非技术用户的桌面端爬虫软件,以其可视化操作和强大的模板库而受到青睐。
官网:https://affiliate.bazhuayu.com/hEvPKU
「功能与特点:」
-
可视化操作:无需编程基础,通过拖拽即可设计采集流程。
-
海量模板:内置300+主流网站采集模板,简化参数设置过程。
-
智能采集:集成多种人工智能算法,自动化处理复杂网站场景。
-
自定义采集:支持文字、图片、文档、表格等多种文件类型的采集。
-
云采集服务:提供5000台云服务器,实现24小时高效稳定采集。
「使用方法:」
-
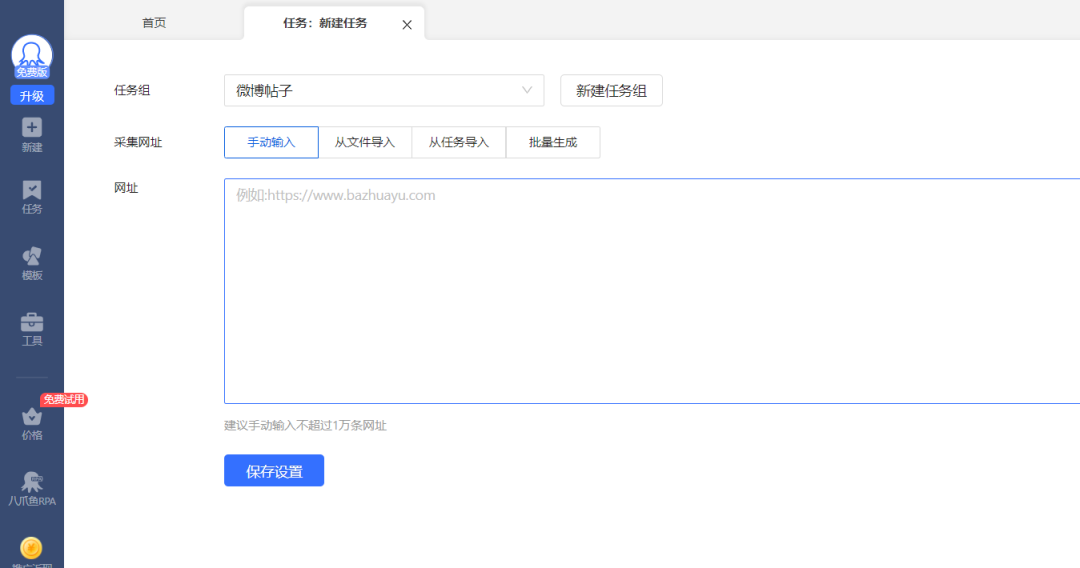
下载并安装八爪鱼采集器。
-
输入待采集的网址,开启“浏览模式”选择具体内容。
-
设计采集流程,创建采集任务。
-
开启采集,并通过“显示网页”查看实时采集情况。
-
导出采集数据,选择合适的文件格式进行保存。
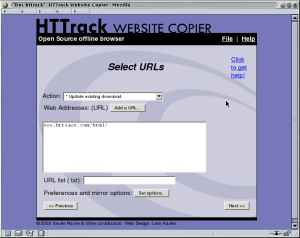
HTTrack
HTTrack是一款免费且功能强大的网站爬虫软件,它允许用户下载整个网站到本地计算机。
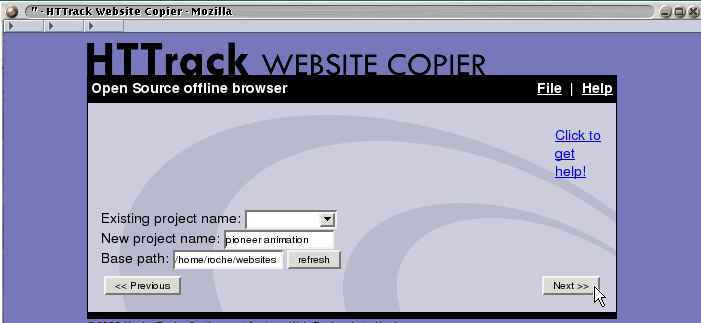
「功能与特点:」
-支持多平台,包括Windows、Linux和Unix系统。
-
能够镜像网站,包括图片、文件、HTML代码等。
-
用户可以设置下载选项,如并发连接数。
-
提供代理支持,可通过身份验证提高下载速度。
「使用方法:」
-
下载并安装HTTrack。
-
配置下载选项,如连接数和代理设置。
-
添加要下载的网站并开始镜像过程。
-
管理下载内容,包括恢复中断的下载。
Scraper
Scraper是一款Chrome扩展程序,适用于在线研究和数据提取。
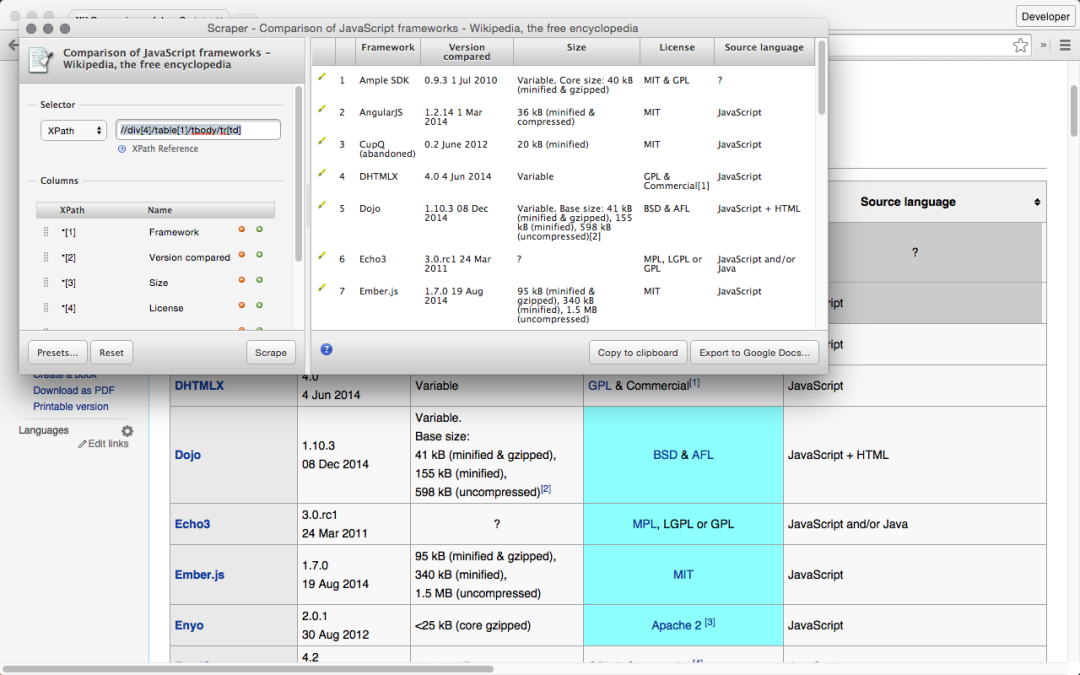
「功能与特点:」
-
免费易用,适合初学者和专家。
-
能够将数据导出到Google Sheets。
-
自动生成XPath,简化数据抓取过程。
「使用方法:」
-
在Chrome浏览器中安装Scraper扩展。
-
访问目标网站并选择要抓取的数据。
-
使用扩展的界面配置抓取规则。
-
导出数据到剪贴板或Google Sheets。
OutWit Hub
OutWit Hub是一个Firefox插件,专注于信息搜集和管理。
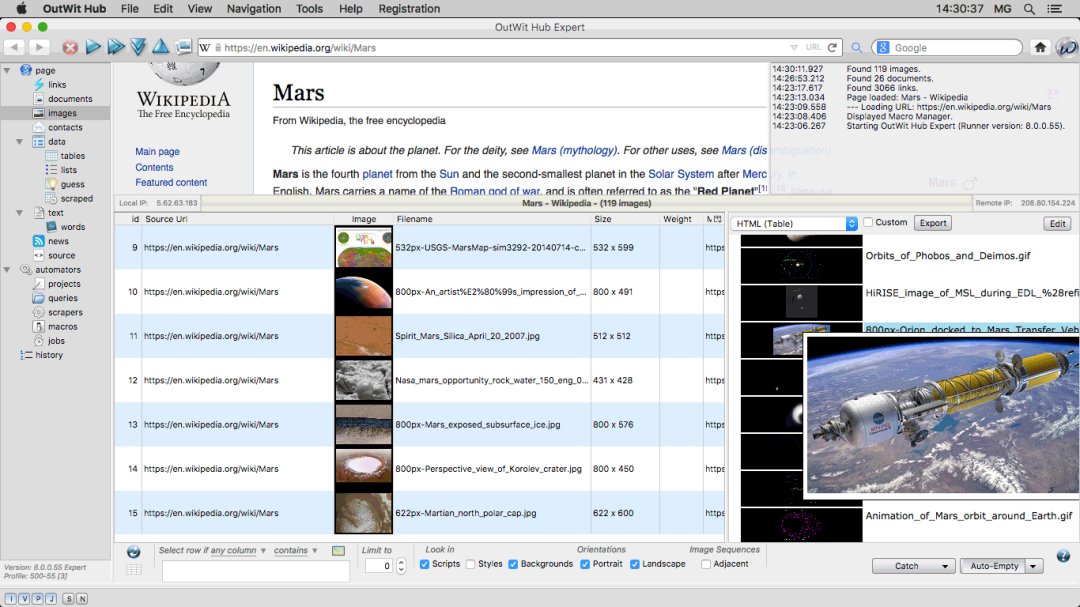
「功能与特点:」
-
允许用户抓取微小或大量数据。
-
可以从浏览器本身抓取任何网页。
-
创建自动代理来提取数据并进行格式化。使用方法:
-
在Firefox浏览器中安装OutWit Hub插件。
-
配置信息搜集任务和数据格式化规则。
-
使用插件抓取网页数据。
-
管理和导出搜集到的信息。
UiPath
UiPath是一款机器人过程自动化软件,也可用于网络抓取。
「功能与特点:」
-
自动从第三方应用程序中抓取Web和桌面数据。
-
跨多个网页提取表格和基于模式的数据。
-
提供内置工具处理复杂的UI。
「使用方法:」
-
安装UiPath软件。
-
配置数据抓取任务,使用其可视化界面设计流程。
-
利用内置工具抓取所需数据。
-
将抓取的数据导出或集成到其他应用程序中。
在选择爬虫软件时,你应根据自己的需求和技能水平进行选择。无论是需要简单的数据抓取,还是复杂的数据挖掘和分析,市场上的爬虫工具都能提供相应的解决方案。同时,使用爬虫软件时,也应遵守相应的法律法规,尊重数据的版权和隐私。
零基础怎么学Python爬虫?
这里分享给大家一套免费的学习资料,包含视频、源码/电子书,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以加我微信一起来学习交流。

Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
视频教程
大信息时代,传统媒体远不如视频教程那么生动活泼,一份零基础到精通的全流程视频教程分享给大家
实战项目案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
副业兼职路线

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









