







文章目录
使用StyleText字体+背景生成某种风格的图片(数据合成) github链接(PaddleOCR的说明文档)
1. 介绍
1.1 工具简介
其实github上介绍的不错,同时在PaddlePaddle的微信公众号,知乎上也都有介绍,传送门在此,自行观看,不多做说明:
- github介绍说明(网上可以搜到的介绍基本都是从这个说明复制的):https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/StyleText/README_ch.md
1.2 TextRender和StyleText
参考腾讯微信小程序的文章:
2021年 3月22日 三年磨一剑——微信OCR轻松提取图片文字
上面这个文章,感觉就是对PaddleOCR进行了一个包装和细节优化,输出结果格式化,整体过程可以参考。
TextRender是利用图像处理的方法来合成数据,对已有语料或字符表字符随机组合,结合模糊、倾斜、透视变换和加背景等方法,生成接近真实场景中的文字图片,生成字符的数量、字体、大小和风格可控,速度快,是我们主要采用的合成方法。
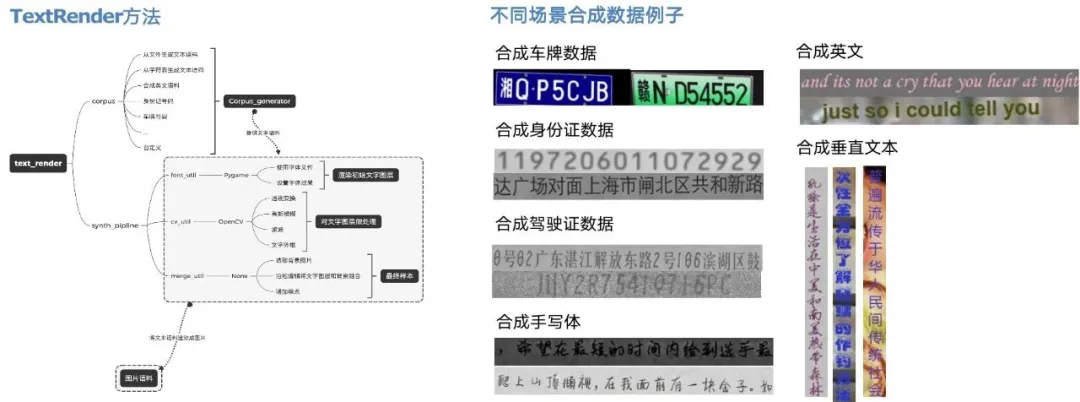
StyleText是采用模型风格迁移的方法,针对实际场景真实数据严重不足,TextRender无法合成文字风格(字体、颜色、间距、背景)的问题的补充,利用少许目标场景图像就可以批量合成大量与目标场景风格相近的文本图像。我们主要利用其补充badcase的数据。
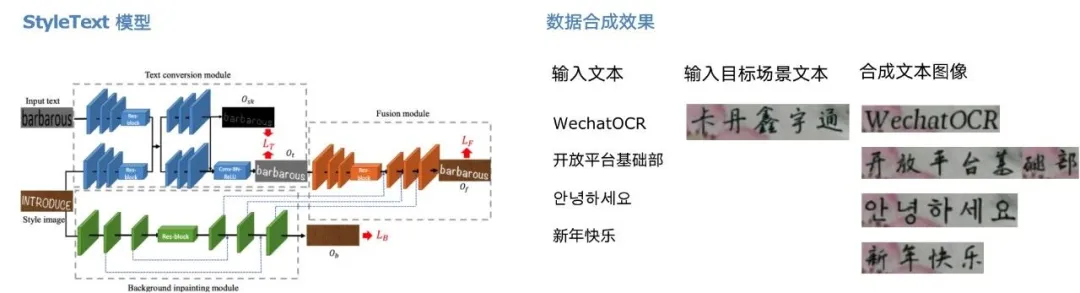
1.3 结论
参考我写的另一篇关于StyleText论文的文章:读论文——(Styletext)Editing Text in the Wild
最后的结论部分,可以知道这个工具的适用范围其实比较窄,是有限的,对原图质量要求也比较高。
建议先简单测试一下,可用再用,不可用就放弃吧,或者像微信OCR一样,大部分使用TextRender,少部分使用StyleText,生成一些有难度的图像。
2. 使用
2.1 StyleText使用
2.1.1 安装(其实就是下载模型)
在配置好PaddleOCR的前提下,可以在PaddleOCR的文件夹中看到StyleText的文件夹,
# 进入StyleText文件夹
cd StyleText
# 下载必须的内容,大致是300MB
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/style_text/style_text_models.zip
# 解压
unzip style_text_models.zip
解压后可以看到,创建了一个style_text_models的文件夹,里面存放着模型的参数文件

所以说明文档中给了提示,如果下载位置不是默认的,需要在configs/config.yml中修改模型文件的地址,修改时需要同时修改这三个配置:
bg_generator:
pretrain: style_text_models/bg_generator
...
text_generator:
pretrain: style_text_models/text_generator
...
fusion_generator:
pretrain: style_text_models/fusion_generator
2.1.2 简单使用
主要包括单张生成和批量生成两种方式,
- 分别对应
configs/config.yml和configs/dataset_config.yml这两个配置文件,这两个配置文件中大部分是一样的,批量生成的部分有一些新的配置项,可以注意一下。 - 同时,还分别对应
tools/synth_image.py和tools/synth_dataset.py这两个脚本
接下来,使用单张生成的方式来测试一下。
单张合成
需要准备一张风格图(参照的那个对象,图片上可以有文字)和一段语料(一个单词或者一句话都可以),比如:
-
语料:*JAERGB0546-111*
-
图片:

-
希望最终生成的图会类似于:

-
运行命令
我是在docker环境中,所以用的python3.7,原本的命令是python3,结合自己的环境去调用;
建议把风格图也放到example文件夹里,这样运行命令不用改很多python3.7 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/styleText2.png --text_corpus "*JAERGB0546-111*" --language en -
生成的结果就在
StyleText文件夹下,有三个文件,分别是:fake_bg.jpg提取出的背景图/风格图,fake_fusion.jpg合成结果以及fake_text.jpg(是用提供的字符串,仿照风格参考图中文字的风格,生成在灰色背景上的文字图片。)。
如下图,但是,我这个看起来效果并不好

2.2 不理想原因分析
2.2.1 风格图问题
分析原因:
| 项目 | 示例图.jpg | 自己图.png |
|---|---|---|
| 大小 | 144x32 | 349x66 |
| 位深 | 24 | 32 |
| 分辨率 | 96dpi | —— |
| 图像大小 | 3.30 KB (3,387 字节) | 30.0 KB (30,806 字节) |
原因1:可能是风格图中,空白区域太多了,风格图应该就像文字检测得到的结果的框图一样,只有一行文本的高度。(高度最好控制在32px或者48px,和论文中数据比较一致,会好一些。) 修改风格图使之只有一行文本的高度
修改高度为48之后,再去试验,可以看到。提取出的风格图依然不是很清晰

原因2,前景色和背景色区分度不够,背景色应该是彩色一点,或者说灰度和前景色区分度很大,换一张别的图试试。探索前景色和背景色区分度的问题
- 用这张图作为风格图

No. SUB RECIPE NAME这串字符作为语料,希望可以生成类似下图的效果

python3.7 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/styleText4.jpg --text_corpus "No. SUB RECIPE NAME" --language en # 这里可能涉及 shell脚本参数传递含有空格 报错的问题,可以注意一下

可以看到,效果依然不理想。
用默认的图去看看好了,排除配置文件的原因。考虑配置文件的问题
python3.7 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/2.jpg --text_corpus PaddleOCR --language en

可以看到,给的例子确实是给的例子。。。所以还是背景图要和前景有足够的区分度,比如:黑色和白色。给的示例图,基本字体都是黑色的

结合官方给的图片,其实还是要图片本身足够清晰,
- 金属表面那个合成其实也很模糊,几乎看不清字
- 韩语合成图片的部分,仔细看,其实也不是每一个都很清楚。(上面的风格图和下面的合成图其实都对不上号。真正用起来其实问题还是不少)
将之前的文件进行颜色二值化处理或颜色增强,保证前景色是黑色,背景色和前景色颜色差异足够大!(看看之前的图,其实文字生成部分比较简单,主要问题还是背景提取失误很大)
例如:二值化之后的图像
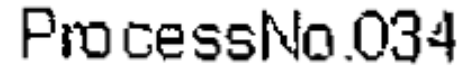
python3.7 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/styleText2-1.png --text_corpus "JAERGB0546-111" --language en

可以发现,当背景颜色和前景色差距足够大的时候,是可以分开的。。。毕竟都这么简单了,可以确定前景色和背景色区分度够高有助于分离,但是会对文字产生一些奇怪的形变。。。。
接下来考虑在配置文件中,修改有关前景和背景分离的参数,以及字体形变的参数,尽量可以使用字体本身的形态。读论文去。
2.2.2 语料长度问题
根据论文中给出的示例图,原图和生成图中,文本长度是差不多的。所以接下来尝试选定风格图之后,语料的长度和原图中文本长度差不多试试看

还是上面二值化之后的内容,原料内容变成JAERGB0546-11,比之前少一个1,这样字符长度都是13
python3.7 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/styleText2-1.png --text_corpus "JAERGB0546-11" --language en
#synth_image.py接收的参数args中,没有可以控制输出图片保存目录,就是直接产在当前目录下的

左边是14个字符的情况,右边是去掉一个1之后13个字符的情况。其实背景图没什么区别,但是生成内容,尤其是后面部分,有比较大的差距。
猜测:当语料比原图文本长时,当直接分离得到的背景图无法装下新的语料时,会采取一些额外的方式去把新图变长/缩短。这一例子中,原图的尺寸:231x71,生成新图的尺寸:169x23。但是配置文件(
config.xml)中出现的内容是:320x32
2.3 字体
文档上给出的说明是,用提供的字符串,仿照风格参考图中文字的风格,生成在灰色背景上的文字图片。
但是在两个配置文件中,都只看到了
TextDrawer:
fonts:
en: fonts/en_standard.ttf # 对应 Open Sans Regular(OpenType类型,但是也是ttf后缀)
ch: fonts/ch_standard.ttf # 对应 汉仪大黑简(TrueType类型)
ko: fonts/ko_standard.ttf
直接在Windows环境下双击这些字体文件,可以看到
ch_standard.ttf字体(其余类似):
en_standard.ttf字体
ko_standard.ttf字体
所以,如果需要使用特定的字体,需要自己提前在配置文件中进行配置,在对应语言的配置项中换成自己实际场景需要的字体。
比如:对我来说,英文就是consolas.ttf字体,中文就是等线字体,韩文可以直接删掉,用不到,哈哈。
TextDrawer:
fonts:
en: fonts/consolas.ttf #
ch: fonts/Deng.ttf # 等线字体
2.4 StyleText代码结构
github介绍中给出了整个StyleText代码结构,百度在AI上做的是真的很好!感谢百度的开发人员!!
StyleText
|-- arch // 网络结构定义文件
| |-- base_module.py
| |-- decoder.py
| |-- encoder.py
| |-- spectral_norm.py
| `-- style_text_rec.py
|-- configs // 配置文件
| |-- config.yml
| `-- dataset_config.yml
|-- engine // 数据合成引擎
| |-- corpus_generators.py // 从文本采样或随机生成语料
| |-- predictors.py // 调用网络生成数据
| |-- style_samplers.py // 采样风格图片
| |-- synthesisers.py // 调度各个模块,合成数据
| |-- text_drawers.py // 生成标准文字图片,用作输入
| `-- writers.py // 将合成的图片和标签写入本地目录
|-- examples // 示例文件
| |-- corpus
| | `-- example.txt
| |-- image_list.txt
| `-- style_images
| |-- 1.jpg
| `-- 2.jpg
|-- fonts // 字体文件
| |-- ch_standard.ttf
| |-- en_standard.ttf
| `-- ko_standard.ttf
|-- tools // 程序入口
| |-- __init__.py
| |-- synth_dataset.py // 批量合成数据
| `-- synth_image.py // 合成单张图片
`-- utils // 其他基础功能模块
|-- config.py
|-- load_params.py
|-- logging.py
|-- math_functions.py
`-- sys_funcs.py















 2865
2865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











