






1.前言
1.1思路
此项目是利用python的requests库获取数据并且使用logging库进行日志记录后,再利用pymysql库将获取数据存放在数据库中,之后Jupyter Notebook中使用pandas将数据库中数据提取出来进行数据分析,再利用pyecharts进行数据可视化处理
1.2环境
环境配置:python3.9.1,centos7.9,MariaDB5.5.68
集成式开发软件:pycharm
2.数据获取并导入数据库
2.1利用requests库获取数据并用logging库进行日志记录
编写一个dl.py文件用于定义两个函数用于获取网页内容和图片地址
需先下载requests
pip install requests
logging库为标准库无需下载
# 导入 requests 库,用于发送 HTTP 请求
import requests
# 导入 logging 模块,用于记录日志
import logging
# 定义请求头,模拟浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"
}
# 定义一个函数 download,用于下载网页内容
def download(address):
# 发送 GET 请求,获取网页内容
response = requests.get(address, headers=headers)
# 记录日志,表示正在获取指定 URL 的内容
logging.info(f"正在获取url:{address}")
# 设置响应内容的编码为 UTF-8,确保中文等字符正确显示
response.encoding = 'utf-8'
# 获取响应内容的文本形式(HTML 或其他文本数据)
data = response.text
# 返回获取到的文本数据
return data
# 定义一个函数 download_img,用于下载图片
def download_img(url):
# 发送 GET 请求,获取图片的二进制内容
response = requests.get(url, headers=headers)
# 返回图片的二进制内容
return response.content
2.2将获取数据导入数据库中
进入浏览器中页面检查其源码获取网页内容url
BeautifulSoup(简称 bs4)是一个用于解析 HTML 和 XML 文档的 Python 库,常用于爬虫开发中提取网页数据。它能够将复杂的 HTML 文档转换为树形结构,方便用户遍历和搜索。
下载bs4库:pip install beautifulsoup4 lxml
本文使用vmware中搭建虚拟机,在centos7.9版本中使用mariadb

# 导入自定义的 download 函数,用于下载网页内容
from dl import download
# 导入 BeautifulSoup,用于解析 HTML 或 XML 数据
from bs4 import BeautifulSoup
# 导入 json 模块,用于处理 JSON 数据
import json
# 导入 pymysql 模块,用于连接和操作 MySQL 数据库
import pymysql
# 连接 MySQL 数据库
db = pymysql.connect(
host='192.168.20.137', # 数据库主机地址
port=3306, # 数据库端口号
user='root', # 数据库用户名
password='123456', # 数据库密码
db='mytest', # 数据库名称
charset='utf8' # 设置字符编码为 UTF-8
)
# 使用 download 函数下载指定 URL 的数据
data = download("https://games.mobileapi.hupu.com/1/8.0.1/bplcommentapi/bpl/score_tree/groupAndSubNodes?nodeId=1630709&queryType=hot&page=1&pageSize=10")
# 使用 BeautifulSoup 解析下载的数据(虽然这里下载的是 JSON 数据,BeautifulSoup 可能并不需要)
bs = BeautifulSoup(data, 'lxml') # 使用 lxml 解析器解析数据
# print(bs, type(bs)) # 打印解析后的对象及其类型(调试用)
# 将下载的 JSON 字符串解析为 Python 字典
data = json.loads(data)
# 从解析后的数据中提取角色信息
role = data['data']['nodePageResult']['data']
# 创建数据库游标,用于执行 SQL 语句
cursor = db.cursor()
# 删除已存在的表 all_role(如果存在)
sql = "DROP TABLE IF EXISTS all_role"
cursor.execute(sql)
# 创建新表 all_role
sql = """CREATE TABLE all_role(
id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, # 自增主键
image VARCHAR(50), # 图片 URL
description VARCHAR(20), # 角色描述
name VARCHAR(20), # 角色名称
hottestComments VARCHAR(255), # 热门评论
scoreAvg DECIMAL(5,2), # 平均评分(5位数字,2位小数)
scoreDistribution VARCHAR(50), # 评分分布
scorePersonCount INT # 评分人数
)
"""
cursor.execute(sql) # 执行创建表的 SQL 语句
# 定义插入数据的 SQL 语句
sql_insert = """INSERT INTO all_role(image, description, name, hottestComments, scoreAvg, scoreDistribution, scorePersonCount)
VALUES(%s, %s, %s, %s, %s, %s, %s)"""
# 遍历角色数据,插入到数据库中
for i in role:
image = i["node"]["image"][0] # 获取图片 URL
name = i["node"]["name"] # 获取角色名称
description = i["node"]["infoJson"]["desc"][0] # 获取角色描述
scoreAvg = i["node"]["scoreAvg"] # 获取平均评分
scoreDistribution = str(i["node"]["scoreDistribution"]) # 获取评分分布(转换为字符串)
hottestComments = i["node"]["hottestComments"][0] # 获取热门评论
scorePersonCount = i["node"]["scorePersonCount"] # 获取评分人数
# 将数据打包为元组,用于插入数据库
values = (image, description, name, hottestComments, scoreAvg, scoreDistribution, scorePersonCount)
# 执行插入操作
cursor.execute(sql_insert, values)
db.commit() # 提交事务,确保数据写入数据库
# 关闭游标和数据库连接
cursor.close()
db.close()
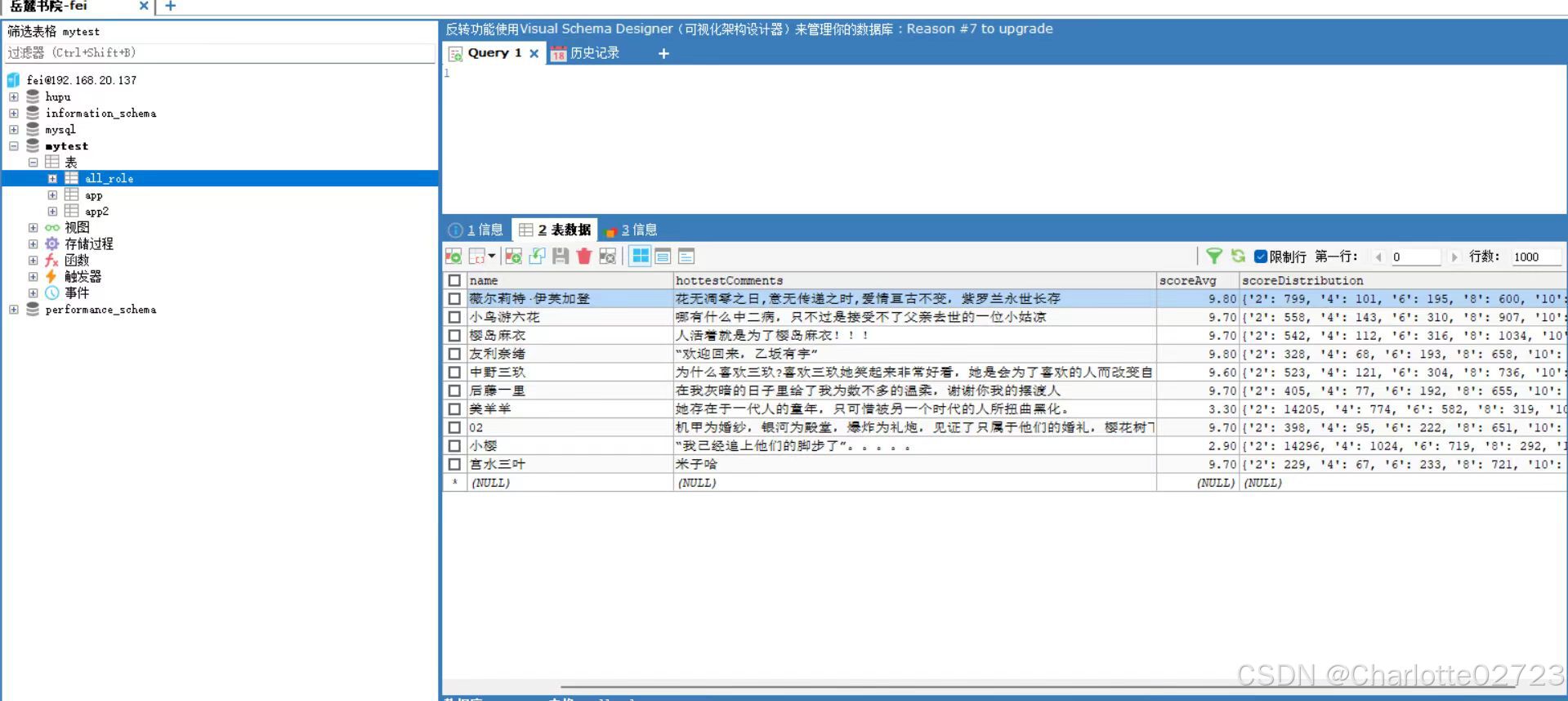
成功获取后如图:
3.数据分析
3.1使用JypyterNotebook
Jupyter Notebook 是一个基于 Web 的交互式工具,用于创建和共享包含代码、文本、公式、可视化等内容的文档。它广泛应用于数据分析、机器学习、教育和研究等领域。
Pandas 是 Python 中一个强大的数据处理和分析库,专为处理结构化数据(如表格数据)而设计
下载环境:
pip install jupyterlab
pip install notebook
pip install pandas
启动jupyter notebook
3.2使用pandas
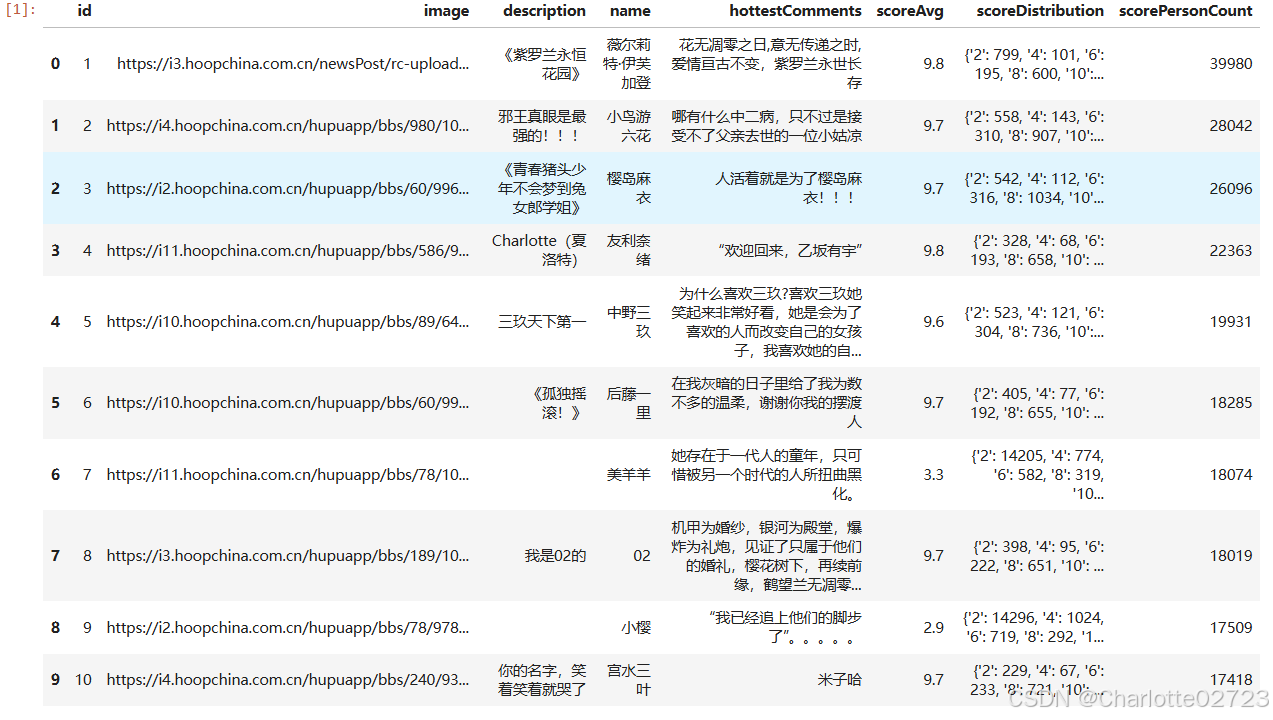
将数据库内容转化为pandas数据
import pymysql
import pandas as pd
# 建立数据库连接
conn = pymysql.connect(host="192.168.20.137", port=3306, user="root", passwd="123456", db="mytest")
# 执行SQL查询并将结果读取为DataFrame
query = "SELECT * FROM all_role"
df = pd.read_sql(query, conn)
# 关闭数据库连接
conn.close()
3.21进行数据清洗
print(df.isnull())
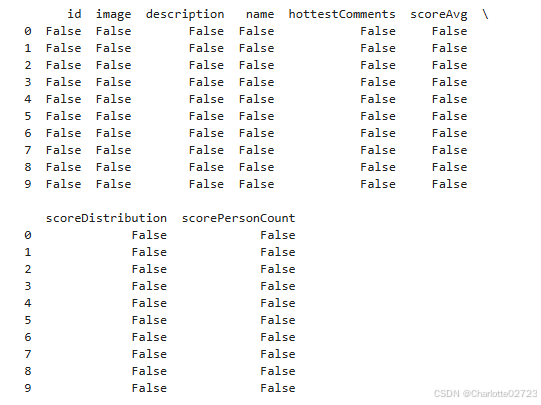
没有缺失值但有空白项,对数据进行修改
new_value = '暂无出处'
df.loc[df['name'] == '美羊羊' , 'description'] = new_value
df.loc[df['name'] == '小樱' , 'description'] = new_value
df
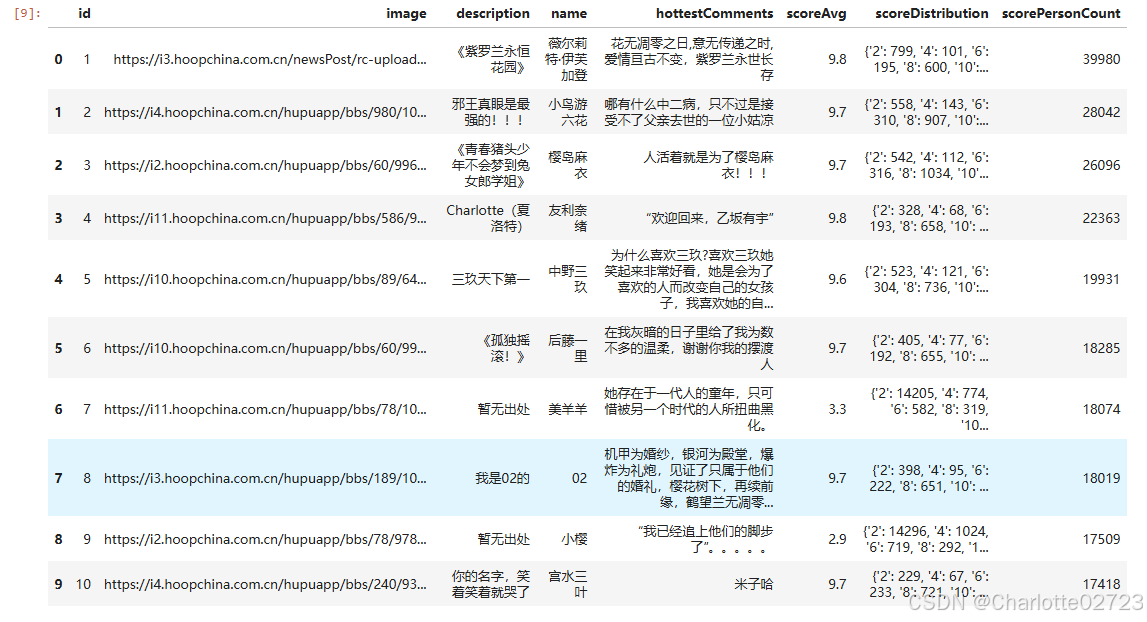
3.22进行数据分析
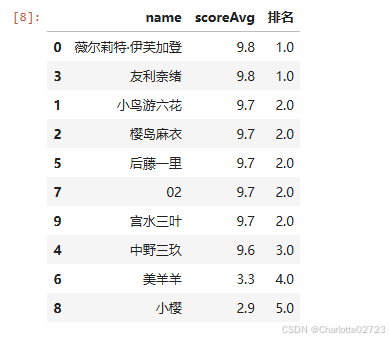
3.22.1.按评分从高到低重新排名并列出其名次
sorted_df = df.sort_values(by='scoreAvg', ascending=False)
sorted_df['排名'] = sorted_df['scoreAvg'].rank(ascending=False, method='dense')
result_df = sorted_df[['name', 'scoreAvg', '排名']]
result_df
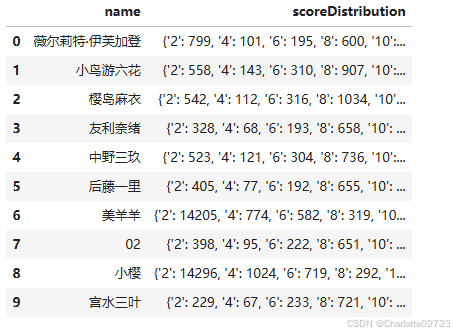
3.22.2.将评分数据获取出来并且转化为字典格式导出
score = df.loc[:, ['name', 'scoreDistribution']]
score_dict = df.set_index('name')['scoreDistribution'].to_dict()
score_dict

4.利用pyecharts数据可视化
下载:pip install pyecharts
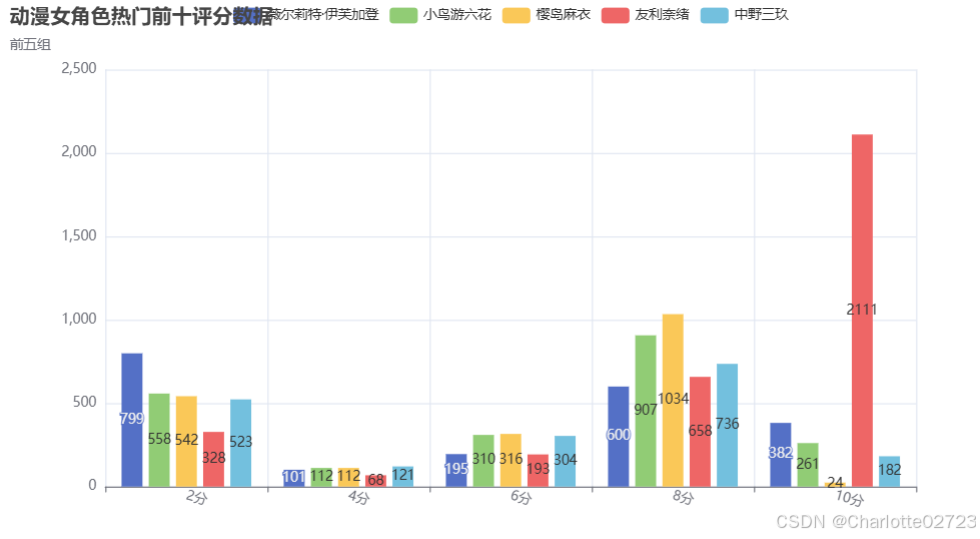
4.1动漫女角色热门前十评分数据显示-柱形图
from pyecharts import options as opts
from pyecharts.charts import Bar
bar1 = (
Bar()
.add_xaxis([
"2分",
"4分",
"6分",
"8分",
"10分",
])
.add_yaxis("薇尔莉特·伊芙加登", [799, 101, 195, 600, 382])
.add_yaxis("小鸟游六花", [558, 112, 310, 907, 261])
.add_yaxis("樱岛麻衣", [542, 112, 316, 1034, 24])
.add_yaxis("友利奈绪", [328, 68, 193, 658, 2111])
.add_yaxis("中野三玖", [523, 121, 304, 736, 182])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="动漫女角色热门前十评分数据", subtitle="前五组"),
)
.render("test1.html")
)
bar2 = (
Bar()
.add_xaxis([
"2分",
"4分",
"6分",
"8分",
"10分",
])
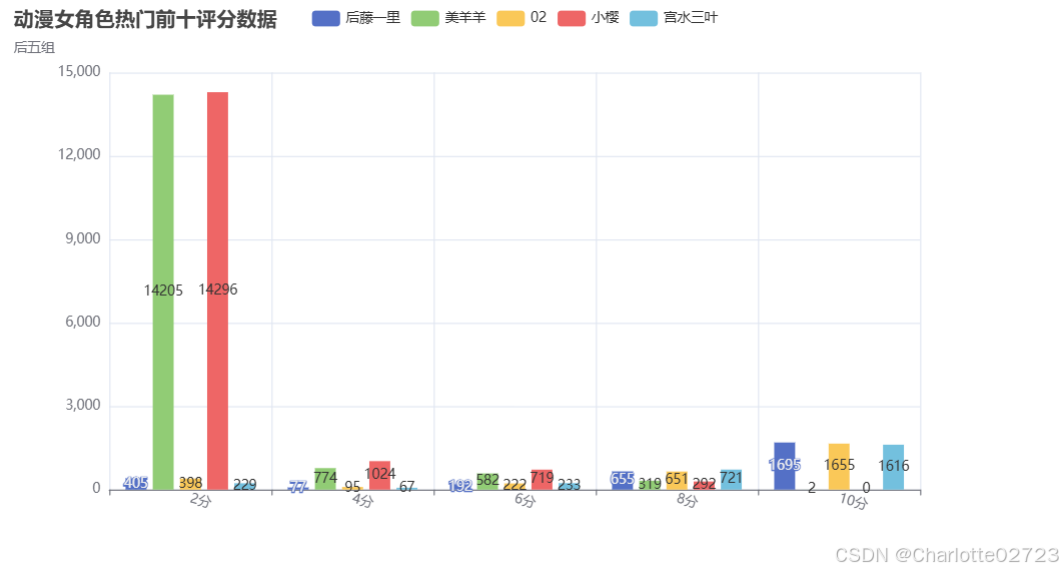
.add_yaxis("后藤一里", [405, 77, 192, 655, 1695])
.add_yaxis("美羊羊", [14205, 774, 582, 319, 2])
.add_yaxis("02", [398, 95, 222, 651, 1655])
.add_yaxis("小樱", [14296, 1024, 719, 292, 0])
.add_yaxis("宫水三叶", [229, 67, 233, 721, 1616])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="动漫女角色热门前十评分数据", subtitle="后五组"),
)
.render("test2.html")
)
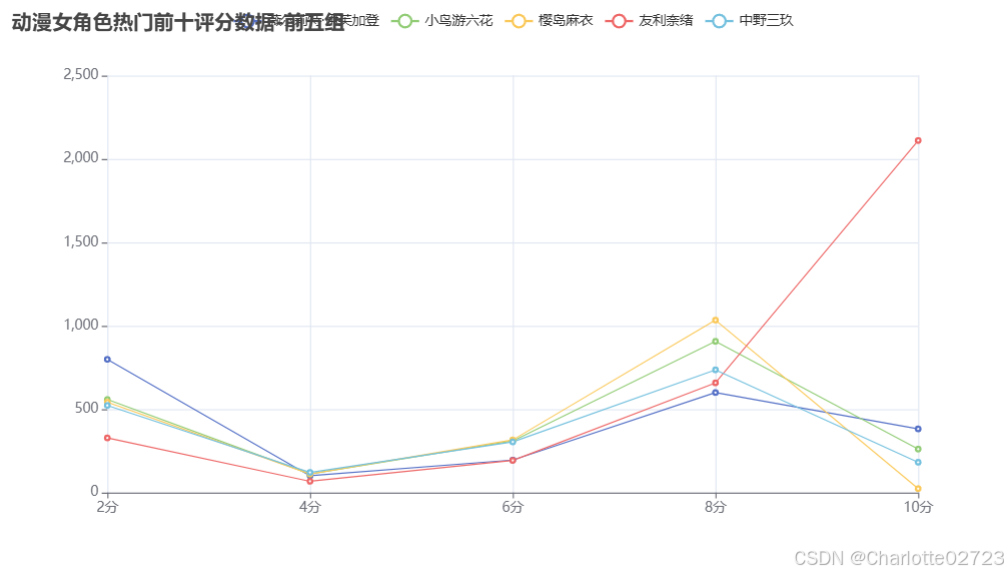
4.2动漫女角色热门前十评分数据显示-折线图
import pyecharts.options as opts
from pyecharts.charts import Line
x_data = ["2分", "4分", "6分", "8分", "10分"]
(
Line()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="薇尔莉特·伊芙加登",
y_axis=[799, 101, 195, 600, 382],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="小鸟游六花",
y_axis=[558, 112, 310, 907, 261],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="樱岛麻衣",
y_axis=[542, 112, 316, 1034, 24],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="友利奈绪",
y_axis=[328, 68, 193, 658, 2111],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="中野三玖",
y_axis=[523, 121, 304, 736, 182],
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="动漫女角色热门前十评分数据-前五组"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("line1.html")
)
import pyecharts.options as opts
from pyecharts.charts import Line
x_data = ["2分", "4分", "6分", "8分", "10分"]
(
Line()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
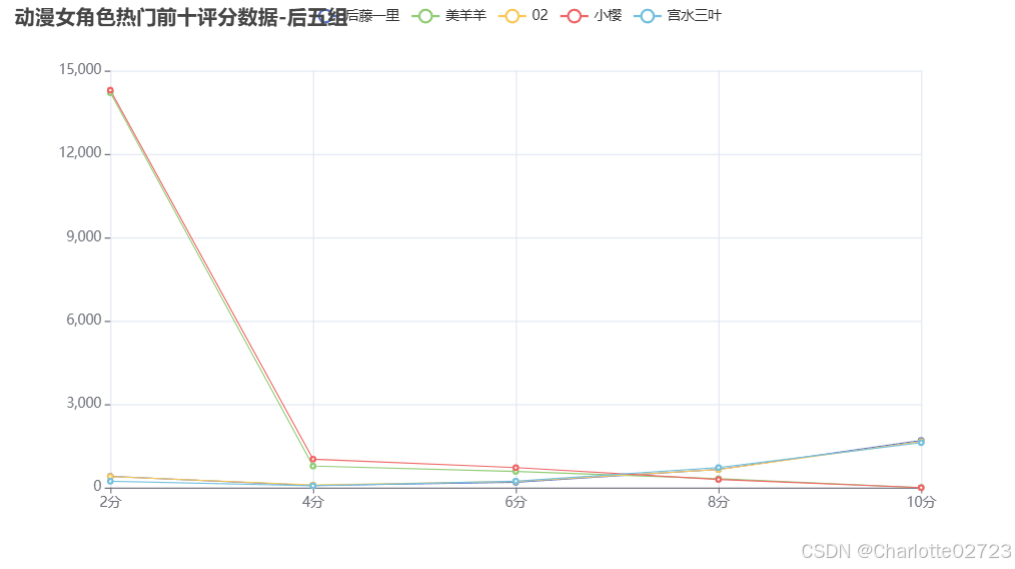
series_name="后藤一里",
y_axis=[405, 77, 192, 655, 1695],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="美羊羊",
y_axis=[14205, 774, 582, 319, 2],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="02",
y_axis=[398, 95, 222, 651, 1655],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="小樱",
y_axis=[14296, 1024, 719, 292, 0],
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="宫水三叶",
y_axis=[229, 67, 233, 721, 1616],
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="动漫女角色热门前十评分数据-后五组"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("line2.html")
)
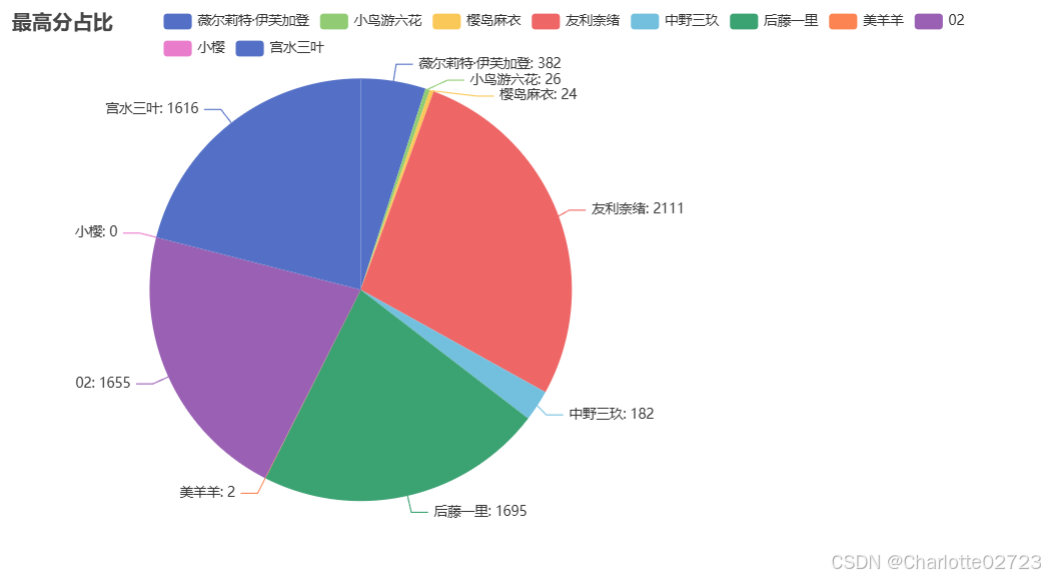
4.3评分最高和最低占比-扇形图
from pyecharts import options as opts
from pyecharts.charts import Pie
name=['薇尔莉特·伊芙加登',"小鸟游六花","樱岛麻衣","友利奈绪","中野三玖","后藤一里","美羊羊","02","小樱","宫水三叶"]
data=[382,26,24,2111,182,1695,2,1655,0,1616]
c = (
Pie()
.add(
"",
[list(z) for z in zip(name, data)],
center=["35%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="最高分占比"),
legend_opts=opts.LegendOpts(pos_left="15%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("pie_position.html")
)
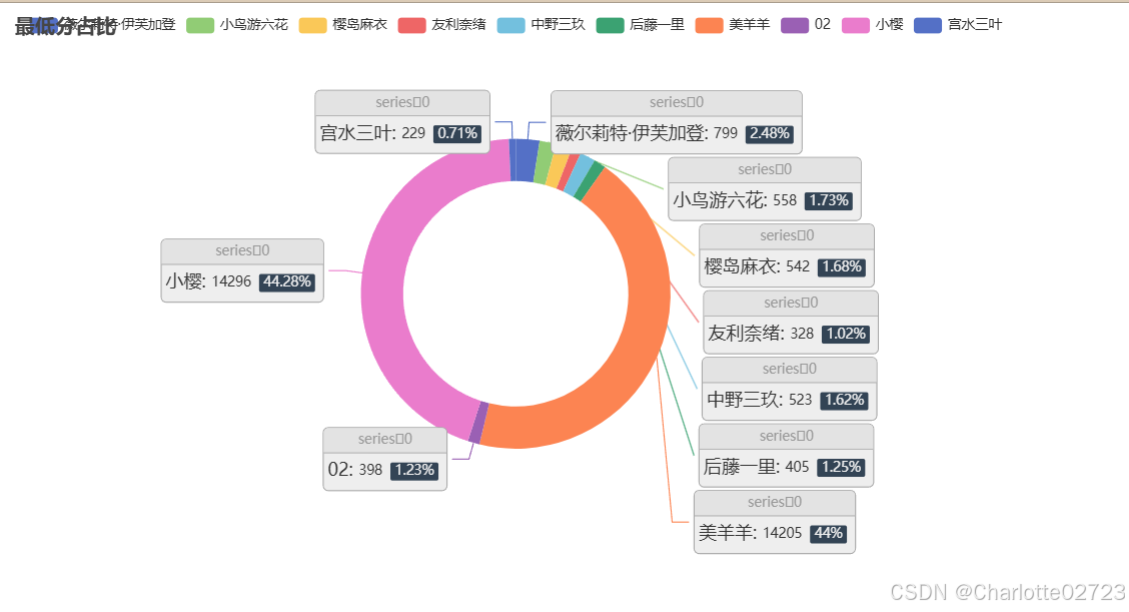
from pyecharts import options as opts
from pyecharts.charts import Pie
name=['薇尔莉特·伊芙加登',"小鸟游六花","樱岛麻衣","友利奈绪","中野三玖","后藤一里","美羊羊","02","小樱","宫水三叶"]
data=[799,558,542,328,523,405,14205,398,14296,229]
c = (
Pie()
.add(
"",
[list(z) for z in zip(name, data)],
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="最低分占比"))
.render("pie2.html")
)
5.总结
1.需要先利用requests库写出对应功能函数
2.需获取源码将其转换成json格式对其结构进行分析,再使用bs4库逐一获取想要数据
3.将数据利用pymysql导入数据库中保存
4.在jupyternotbook中将数据库中数据导出为pandas进行数据清洗和相应数据分析等
5.利用pyecharts对导出数据进行数据可视化

















 7902
7902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









