









目录
协同过滤
在 2012 年初,爆出了这样一则新闻故事:一位男子进入一家Target商店,挥舞着手中的一叠优惠券,这些都是Target邮寄给他还在读高中的女儿的。他来的目的是谴责经理,因为这套优惠券都是诸如婴儿服装、配方奶和幼儿家具这类商品专享的。
听到顾客的投诉,经理再三道歉。他感觉很糟糕,想在几天后通过电话跟进,解释这是怎么回事。这个时候,反而是这位父亲在电话里进行了道歉。看来他的女儿确实是怀孕了。
她的购物习惯泄露了她的这个秘密。
出卖这位女生的算法很可能是,至少部分是,基于协同过滤。
什么是协同过滤?
协同过滤(collaborative filtering)是基于这样的想法,在某处总有和你趣味相投的人。假设你和趣味相投的人们评价方式都非常类似,而且你们都已经以这种方式评价了一组特定的项目,此外,你们每个人对其他人尚未评价的项目也有过评价。正如已经假设的那样,你们的口味是类似的,因此可以从趣味相投的人们那里,提取具有很高评分而你尚未评价的项目,作为给你的推荐,反之亦然。在某种程度上,这点和数字化配对非常相像,但结果是你喜欢的歌曲或产品,而不是与异性的约会。
对于怀孕的高中生这个案例,当她购买了无味的乳液、棉球和维生素补充剂之后,她可能就和那些稍后继续购买婴儿床和尿布的人匹配上了。
基于用户的过滤
我们将从被称为效用矩阵(utility matrx)的东西开始。它和词条-文档矩阵相类似,不过这里我们表示的是产品和用户,而不再是词条和文档。
这里,我们假设有顾客 A 到 D,以及他们所评分的一组产品,评分从 0 到 5
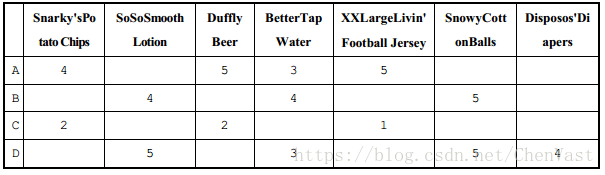
之前我们看到,当想要查找类似的项目时,可以使用余弦相似度。让我们在这里试试。
我们将为用户 A 发现最相似的其他顾客。由于这里的向量是稀疏的,包含了许多未评分的项目,我们将在这些缺失的地方输入一些默认值,这里填入 0。
我们从用户 A 和用户 B 的比较开始。
fromsklearn.metrics.pairwise import cosine_similarity
cosine_similarity(np.array([4,0,5,3,5,0,0]).reshape(1,-1),\
np.array([0,4,0,4,0,5,0]).reshape(1,-1))我们可以看到,这两者没有很高的相似性,这是有道理的,因为他们没有多少共同的评分。
现在来看看用户 C 与用户 A 的比较。
cosine_similarity(np.array([4,0,5,3,5,0,0]).reshape(1,-1),\
np.array([2,0,2,0,1,0,0]).reshape(1,-1))我们看到他们有很高的相似度(记住 1 是完美的相似度),尽管他们对同样产品的评价有所不同。为什么得到了这样的结果?
问题在于我们对没有评分的产品,选择使用0 分。它表示强烈的(负的)一致性。在这种情况下, 0 不是中性的。
如何解决这个问题?
我们可以做的是重新生成每位用户的评分,并使得平均分变为 0 或中性,而不是为缺失值简单地使用 0。我们拿出每位用户的评分,将其减去该用户所有打分的平均值。
例如,对于用户A,他打分的平均值为 17/4,或 4.25。然后我们从用户 A 提供的每个单独评分中减去这个值。
一旦完成,我们继续找到其他用户的平均值,从他们的每个评分中减去该均值,直到对每位用户完成该项操作。
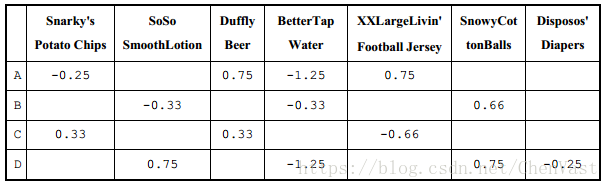
让我们在新的数据集上尝试余弦相似度。再次将用户 A 和用户 B、 C 进行比较。
A 和 B 之间的比较如下。
cosine_similarity(np.array([-.25,0,.75,-1.25,.75,0,0]).reshape(1,-1),\
np.array([0,-.33,0,-.33,0,.66,0]).reshape(1,-1))A 和 C
cosine_similarity(np.array([-.25,0,.75,-1.25,.75,0,0]).reshape(1,-1),\
np.array([.33,0,.33,0,-.66,0,0]).reshape(1,-1))我们可以看到, A 和 B 之间的相似度略有增加,而 A 和 C 之间的相似度显著下降。这正是我们所希望的。
这种中心化的过程除了帮助我们处理缺失值之外,还有其他好处,例如帮助我们处理不同严苛程度的打分者,现在每位打分者的平均分都是 0 了。注意,这个公式等价于 Pearson相关系数,取值落在-1 和 1 之间。
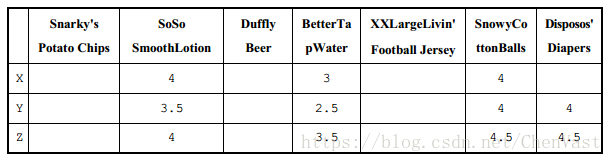
让我们现在采用这个框架,使用它来预测产品的评分。我们将示例限制为三位用户 X、Y 和 Z,我们将预测 X 尚未评价, 而和 X 非常相似的 Y 和 Z 已经评过的产品,对于 X 而言会得到多少分。
先从每位用户的基本评分开始
将中心化这些评分
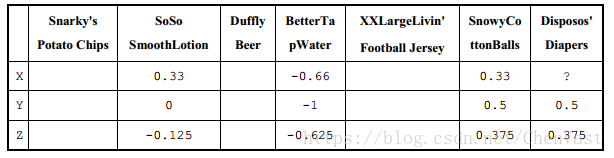
想知道用户 X 会给 Disposos' Diapers 打多少分。我们可以根据用户评分中心化之后的余弦相似度获得权重,并通过这些权重对用户 Y 和用户 Z 的评分进行加权计算。
先得到用户 Y 和 X 的相似度。
user_x = [0,.33,0,-.66,0,33,0]
user_y = [0,0,0,-1,0,.5,.5]
cosine_similarity(np.array(user_x).reshape(1,-1),\
np.array(user_y).reshape(1,-1))计算用户 Z 和 X 的相似度。
user_x = [0,.33,0,-.66,0,33,0]
user_z = [0,-.125,0,-.625,0,.375,.375]
cosine_similarity(np.array(user_x).reshape(1,-1),\
np.array(user_z).reshape(1,-1))现在有一个用户 X 和用户 Y 之间的相似度(0.42447212),以及用户 A 和用户 Z 之间的相似度(0.46571861)
整合起来,我们通过每位用户与 X 之间的相似度,对每位用户的评分进行加权,然后除以总相似度。
(0.42447212 × (4) +0.46571861 × (4.5)) / (0.42447212 +0.46571861) = 4.26
用户 X 对 Disposos' Diapers 的预估评分为 4.26
基于项目的过滤
这种方法远优于基于用户的过滤,它被称为基于项目的过滤。这是它的工作原理:每个被评分项目与所有其他项目相比较,找到最相似的项,而不是根据评分历史将每位用户和所有其他用户相匹配。同时,也是使用中心化余弦相似度。
我们有一个效用矩阵。这一次,我们将看看用户对歌曲的评分。每一列是一位用户,而每一行是一首歌曲。
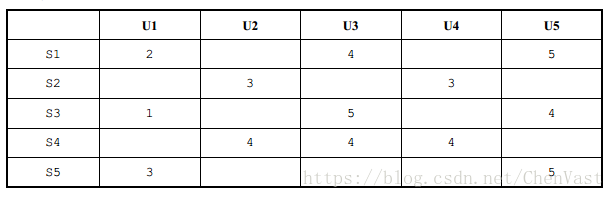
想知道 U3 对于 S5 的评分。这里,我们会根据用户对歌曲的评分来寻找类似的歌曲,而不是寻找类似的用户。
从每行歌曲的中心化开始,并计算其他每首歌曲和目标歌曲(即 S5)的余弦相似度。
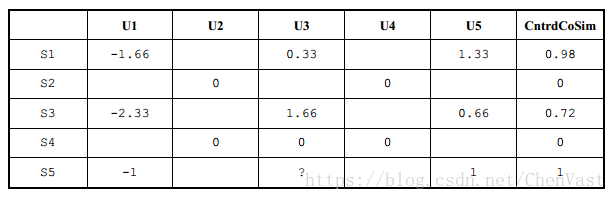
最右边的列是其他每行相对行 S5 的中心化余弦相似度。
需要选择一个数字, k,这是我们为预测 U3 对歌曲的评分,所要使用的最近邻居数量。在这个简单的例子中,我们使用 k = 2。
我们可以看到对于歌曲 S5, S1 和 S3 是和它最相似的,所以我们将使用 U3 对这两首歌的评分(分别为 4 和 5)。
计算评分
(0.98 × (4) +0.72 × (5)) / (0.98 +0.72) = 4.42
通过基于项目的协同过滤,我们可以看到 U3 很可能给 S5 打出高分 4.42。
基于用户的过滤不如基于项目的过滤有效,这是为什么呢?
很有可能,你的朋友和你有共同的爱好,但是你们每个人都有自己喜欢,而别人毫无兴趣的领域。
基于内容的过滤
作为一个音乐家, Tim Westergren 花了几年时间倾听其他有天赋的音乐家的作品,想知道为什么他们永远不能拔尖。他们的音乐很好,和你在电台收听到的那些一样好。然而,不知何故,他们从来没有大的突破。他想,一定是因为他们的音乐没有在足够的、合适的人们面前展示。
Tim 最终退出了音乐家的工作,开始从事电影背景音乐的作曲。在那里,他开始思考每一块音乐自己独特的结构或 DNA,并可以将其分解为不同的组成部分。思考一番之后,他开始考虑围绕这个想法创建一家公司,建立一系列音乐的基因组。他的一位朋友曾经创建并出售了一家公司, Tim 让他来运作这个想法。 Tim 的朋友喜欢他的想法,并开始帮助他写一个商业计划,并为该项目收集了首轮融资。行动开始了。
在接下来的几年里,他们雇用了一小群音乐家,对上百万首音乐细致地编写了几乎 400个不同的特征,每个特征从 0 到 5 进行打分——所有都是通过手,或者说是通过耳朵进行的。每首 3 到 4 分钟长的歌曲需要几乎半小时的评级。
这些特征包括如此的参数:如领唱歌手的声音有多么的沉重,或节奏是每分钟多少拍。
他们花费了近一年的时间完成了首个原型。它完全使用 Excel 中的 VBA 宏构建,花了差不多 4 分钟才返回一次推荐结果。但是,最后,它成功了,运作得非常好。
我们现在知道这家公司就是 Pandora Music,你很可能已经听说过或使用过其产品,因为每天它有来自世界各地数百万的用户。毫无疑问,它是基于内容过滤的成功范例。
在基于内容的过滤中,不再将每首歌曲视为一个不可分割的单位,而是将它变成特征向量,然后就可以使用我们的老朋友余弦相似度进行比较。
不仅歌曲可以被分解成为特征向量,听众也可以被转化为特征向量。听众的品味描述成为了空间中的向量,使我们可以测量他们的品味描述和歌曲本身之间的相似程度。
对于 Tim Westergren 来说,这是神奇的,因为不像其他推荐引擎依赖于音乐的人气,这个系统的推荐是基于固有的结构相似性。也许有人从来没有听过歌曲 X,但如果他们喜欢歌曲 Y,那么他们应该喜欢歌曲 X,因为这两首歌在基因上是几乎相同的。这就是基于内容的过滤。
混合系统
我们已经学习了推荐系统的两种主要形式。但是,需要注意的是,在任何大规模生产
环境中,推荐引擎可能同时利用这两项技术。这被称为混合系统,人们喜欢混合系统的原
因是,它有助于消除使用单一系统时可能存在的缺点。这两个系统在一起,创建了更强大
的解决方案。
检查每种类型的利弊
协同过滤的优点如下。
•没有必要手动创建特征。
协同过滤的缺点如下。
•如果没有大量的项目和用户,它不能正常工作。
•当项目数量远远超过可能被购买的数量时,效用矩阵会有稀疏性。
基于内容的过滤的优点如下。
•它不需要大量的用户。
基于内容的过滤的缺点如下。
•定义正确的特征可能是一个挑战。
•缺乏“意外的惊喜”
当一家公司缺乏大量的用户群,基于内容的过滤是更好的选择,但是随着公司的增长,加入协同过滤可以帮助我们为用户提供更多的“惊喜”。
摘自《Python机器学习实践指南》














 3659
3659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









