







 KNN算法是一种基于距离测量的分类方法,通过计算样本间的相似度来决定分类归属。本文介绍了算法的基本流程,包括选择合适的K值对分类影响的探讨,以及如何利用sklearn库实现KNN。同时,讨论了算法的优缺点,如计算量大和可解释性差的问题。
KNN算法是一种基于距离测量的分类方法,通过计算样本间的相似度来决定分类归属。本文介绍了算法的基本流程,包括选择合适的K值对分类影响的探讨,以及如何利用sklearn库实现KNN。同时,讨论了算法的优缺点,如计算量大和可解释性差的问题。
- 算法概述
“如果走像鸭子,叫像鸭子,看起来还像鸭子,那么它很可能就是一只鸭子”。简单地说,KNN采用测量不同特征值之间的距离方法进行分类。如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
- 算法流程
- 依公式计算 Item 与 D1、D2 … …、Dj 之相似度。得到Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)。
- 将Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)排序,若是超过相似度阈值t则放入邻居案例集合NN。
- 自邻居案例集合NN中取出前k名,依多数决,得到Item可能类别。
- 参数K的选取
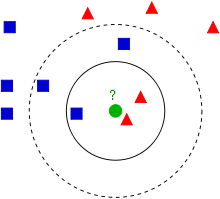
- 如何选择一个最佳的K值取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。比如下图,待测样本(绿色圆圈)既可能分到红色三角形类,也可能分到蓝色正方形类。如果k取3,从图可见,待测样本的3个邻居在实线的内圆里,按多数投票结果,它属于红色三角形类,票数1:2.但是如果k取5,那么待测样本的最邻近的5个样本在虚线的圆里,按表决法,它又属于蓝色正方形类,票数2(红色三角形):3(蓝色正方形)。
- 计算两者间距离,用哪种距离会更好呢?计算量太大怎么办?假设样本中,类型分布非常不均,该怎么办呢?
- K太小,分类结果易受噪声点影响;K太大,近邻中又可能包含太多其他类别的点。K值通常采用交叉验证来确定。经验规则:K一般低于训练样本数的平方根。
- 经典例子
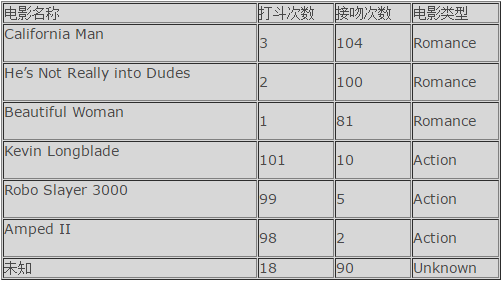
这个数据用打斗次数和接吻次数来界定电影类型,接吻多的是Romance类型的,而打斗多的是动作电影。现在有一部名字未知的电影,打斗次数为18次,接吻次数为90次的电影(这里名字未知是为了防止能从名字中猜出电影类型),它到底属于哪种类型的电影呢?
import numpy as np
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier() #取得knn分类器
data = np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]]) # <span style="font-family:Arial, Helvetica, sans-serif;">data对应着打斗次数和接吻次数</span>
labels = np.array([1,1,1,2,2,2]) #<span style="font-family:Arial, Helvetica, sans-serif;">labels则是对应Romance和Action</span>
knn.fit(data,labels) #导入数据进行训练'''
knn.predict([18,90])
- sklearn实现
- class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)
- 优缺点
- 优点:
- 简单,易于理解,易于实现,无需估计参数,无需训练;
- 适合对稀有事件进行分类;
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
- 缺点:
- 计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
- 可解释性较差,无法给出决策树那样的规则。















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









