







一、CUDA异构计算基础
1.CUDA简介
CUDA(Compute Unified Device Architecture),是一种基于C/C++的编程方法,支持异构编程的扩展方法,提供了简单明了的APIs,能够轻松的管理存储系统。目前CUDA支持的编程语言包括C/C++/Python/Java/Fortran等。
2.CUDA生态
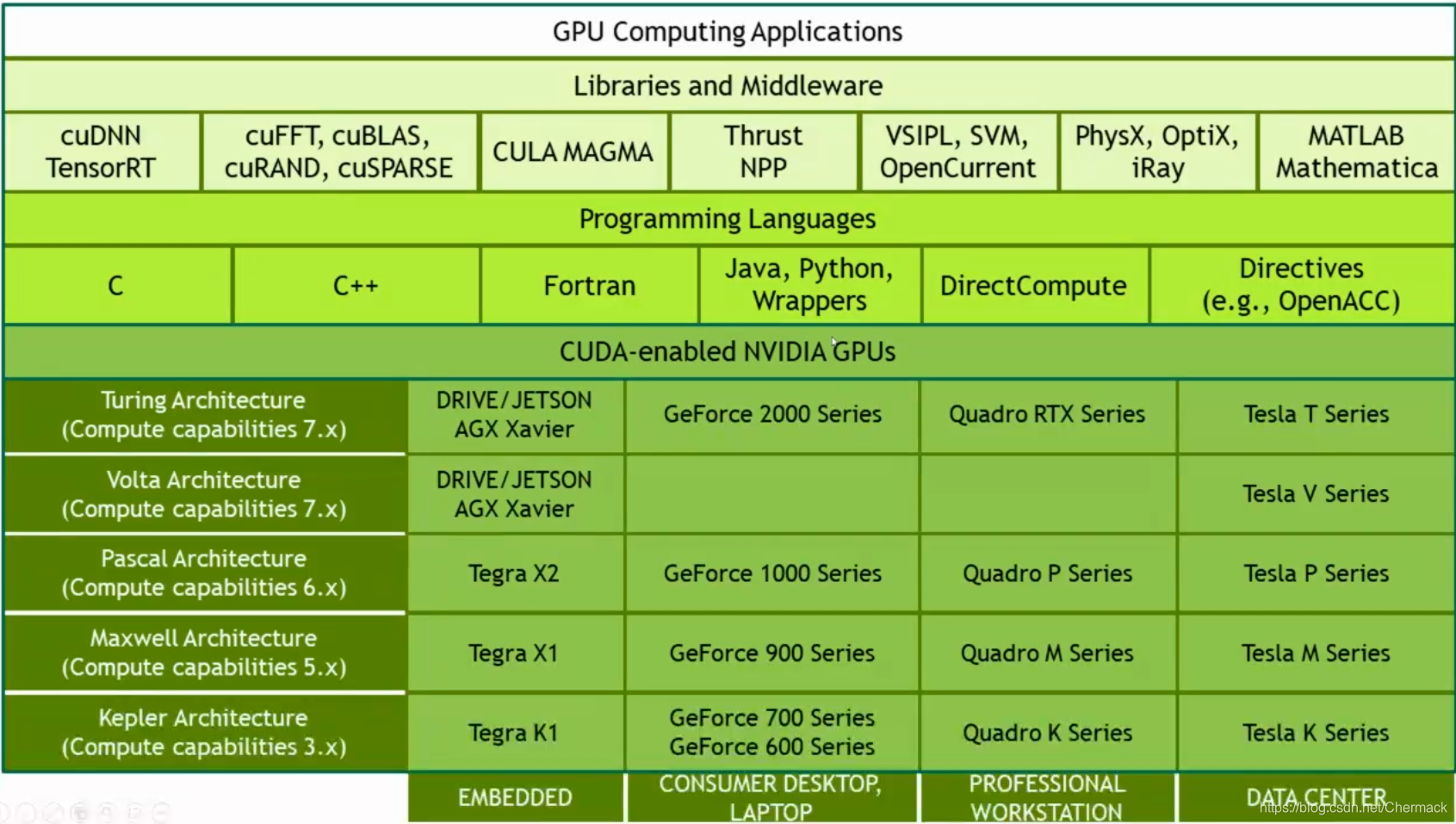
上图从上到下依次为:基于GPU计算的应用程序,一些GPU计算的库与中间件,编程语言,不同架构的GPU设备。
3.CUDA并行计算模式
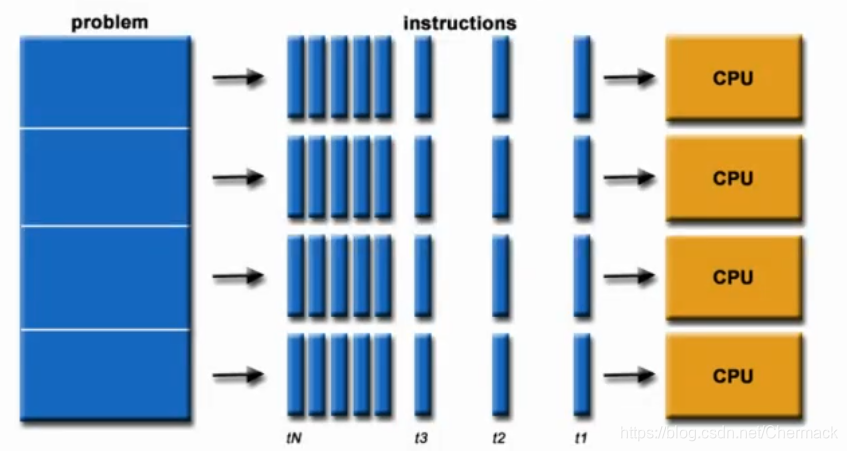
并行计算即是同时应用多个计算资源解决一个可以并行处理计算问题。
关键点有两个:一是拥有多个计算资源或处理器,二是一个大问题可以拆分为多个离散的部分同时进行。
4.术语:
当今的显卡拥有强大的计算能力,它有自己的计算核心和内存(在显卡中的内存称为现存),为了对CPU计算资源和GPU计算资源进行区分,异构计算中给出以下术语。
host:指的是CPU和主机内存(host memory)
device:指的是GPU和显存(device memory)
kernels:核函数,是一个由CPU发起的在GPU上执行的函数。
device function:只能由GPU调用的GPU上执行的函数

5.CPU结构
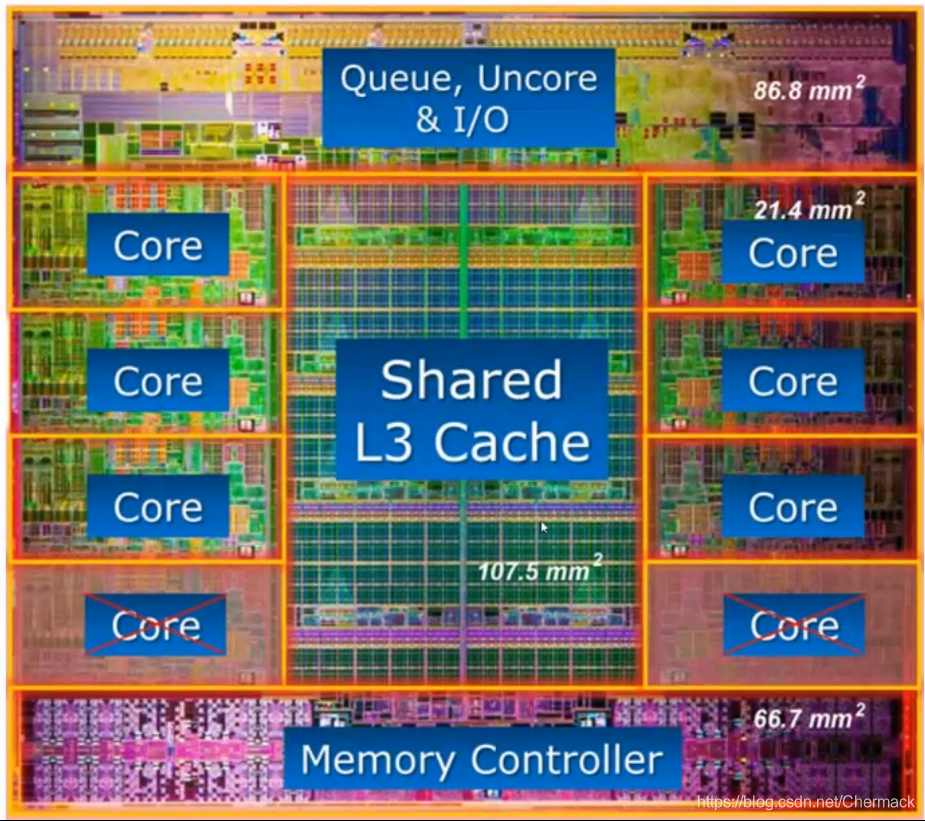
上图是一个8核心CPU内部结构图,可以看到核心(Core)所占的芯片的面积大概只有三分之一,更多的空间被用于作为存储(高速缓存Cache和内存控制器等)。
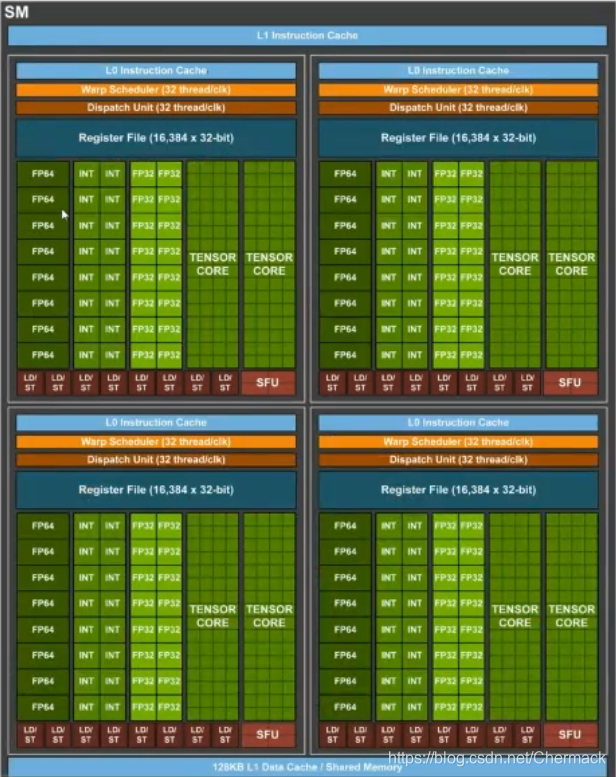
6、GPU结构
GPU结构则与CPU的设计理念有所不同,下图为GPU结构示意图,可以看到GPU中的计算核(图中深绿色部分)明显增多且数量巨大(实际的核心比示意图更多,多达上千个)。
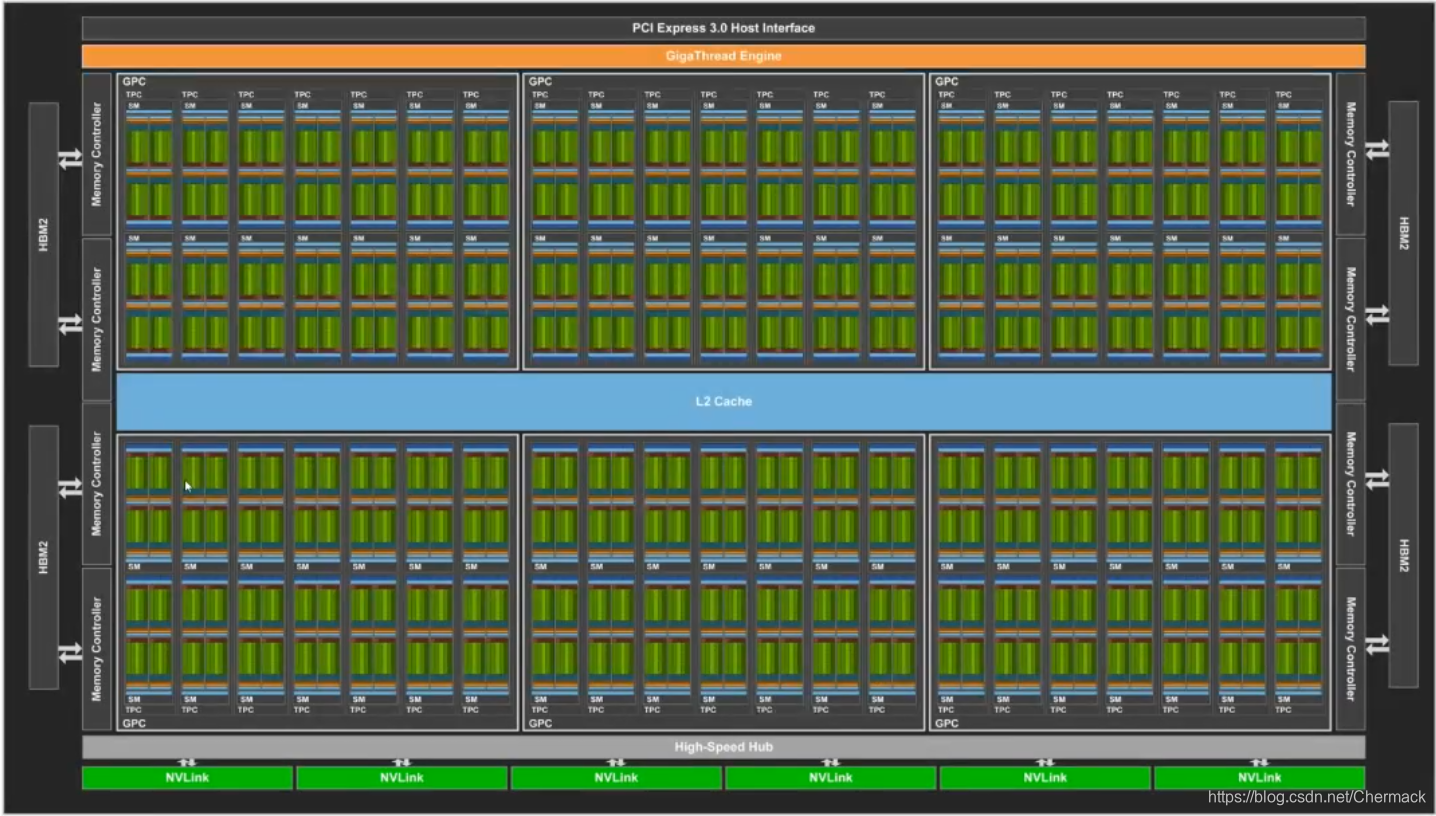
可以看到计算单元又被划分到不同的SM(stream multi-processor,流多处理器) 中,其中又包括了处理不同数据的核,有用于双精度浮点型计算的FP64,整数型计算的INT,单精度计算的FP32以及用于深度学习的TENSOR CORE以及计算之外寄存器和缓存等。
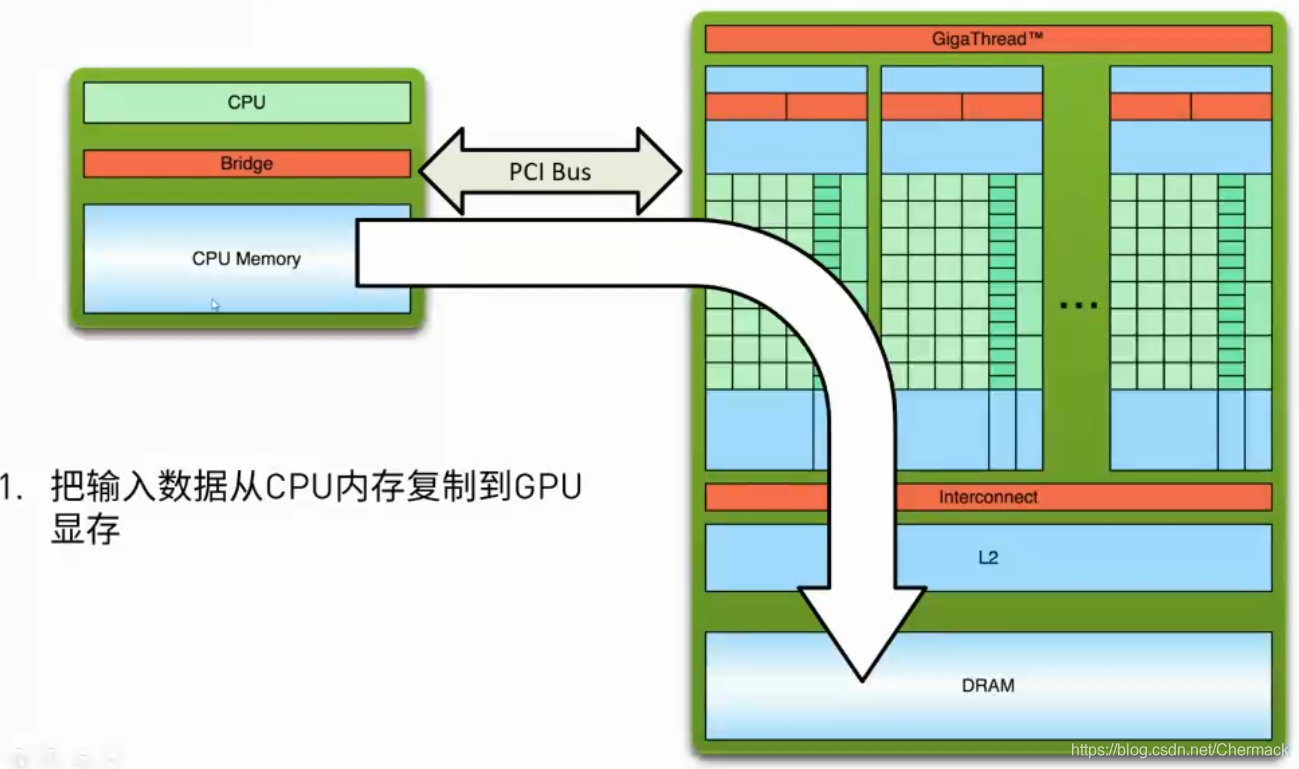
7.计算流程
①首先需要将数据从主机内存复制到GPU显存,因为CPU只能访问主机内存,GPU只能访问显存,因此需要并行计算的任务数据需要从host 拷贝到device。
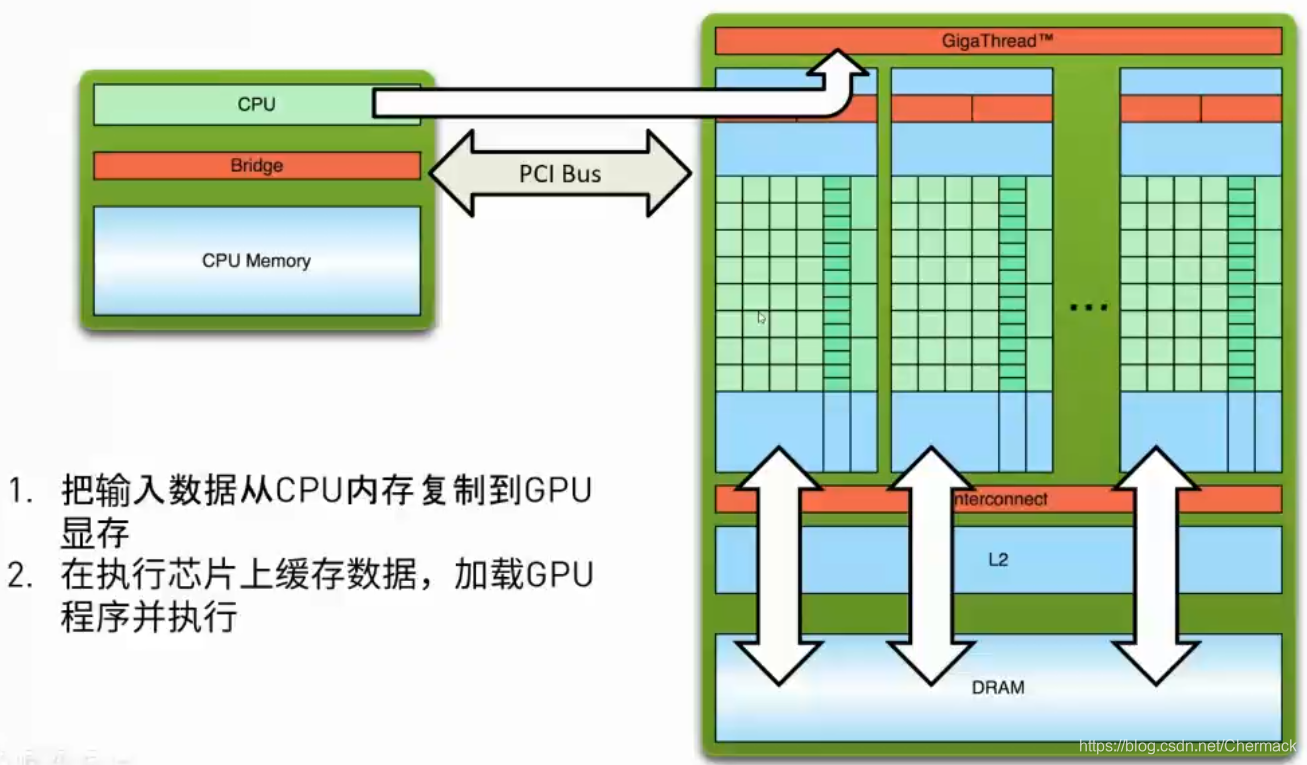
②然后,CPU会下发指令给GPU,使其加载GPU程序并进行执行。
③GPU程序执行完毕后,将显存中的结果从device拷贝回主机内存中,再进行其他的操作(保存,打印,展示等)。
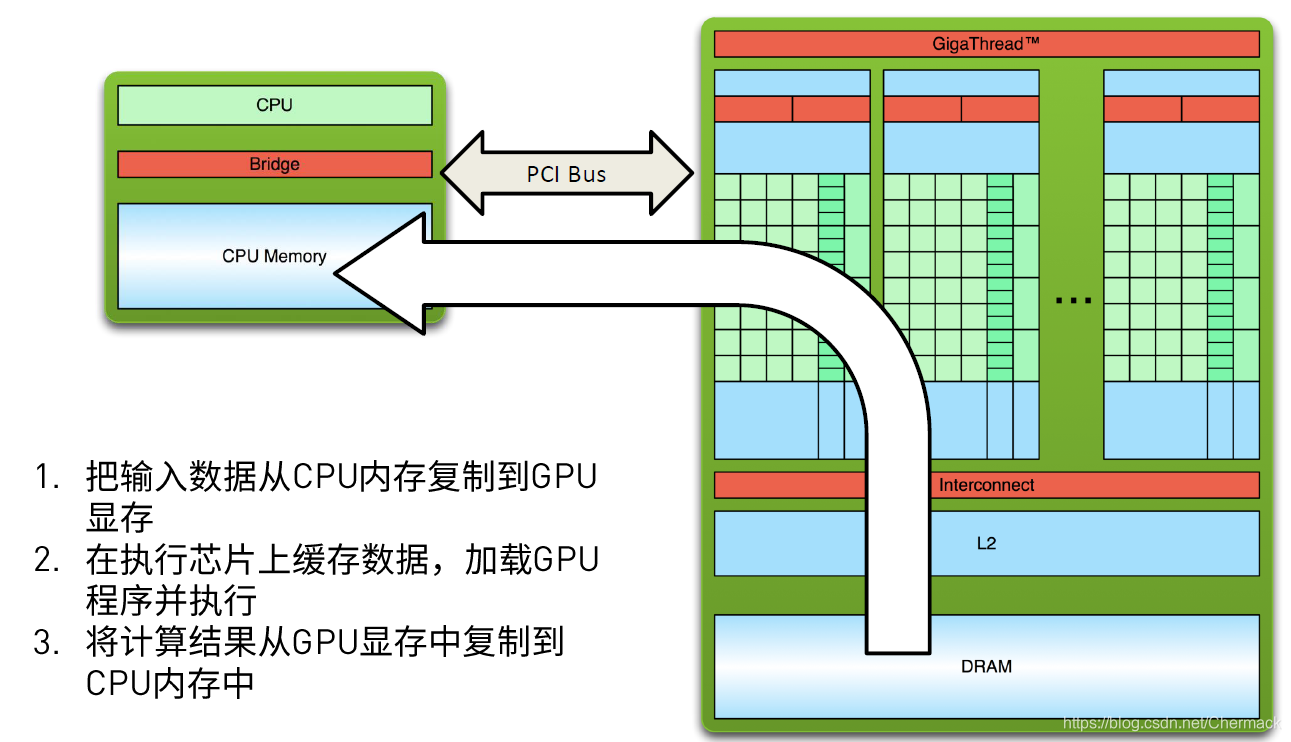
上面三步便是GPU编程的基本步骤,可以总结出一个简单的异构计算流程如下:先顺序执行CPU代码,遇到耗时的可以并行执行的程序时,采用GPU并行编程,然后回到CPU顺序执行处理逻辑,如此反复进行。
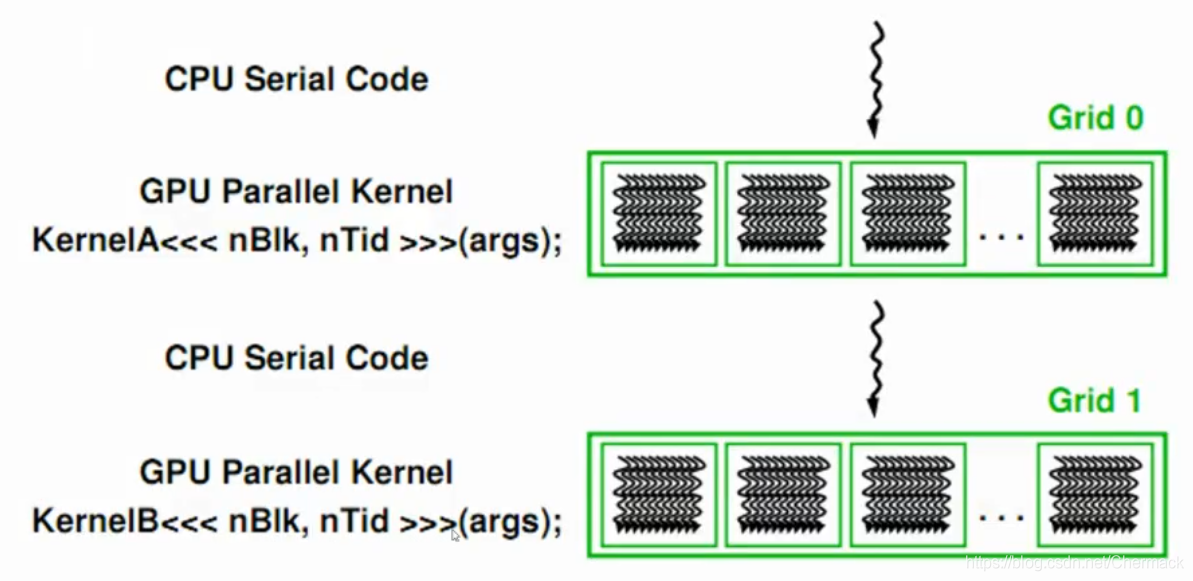
8.CUDA的线程层次
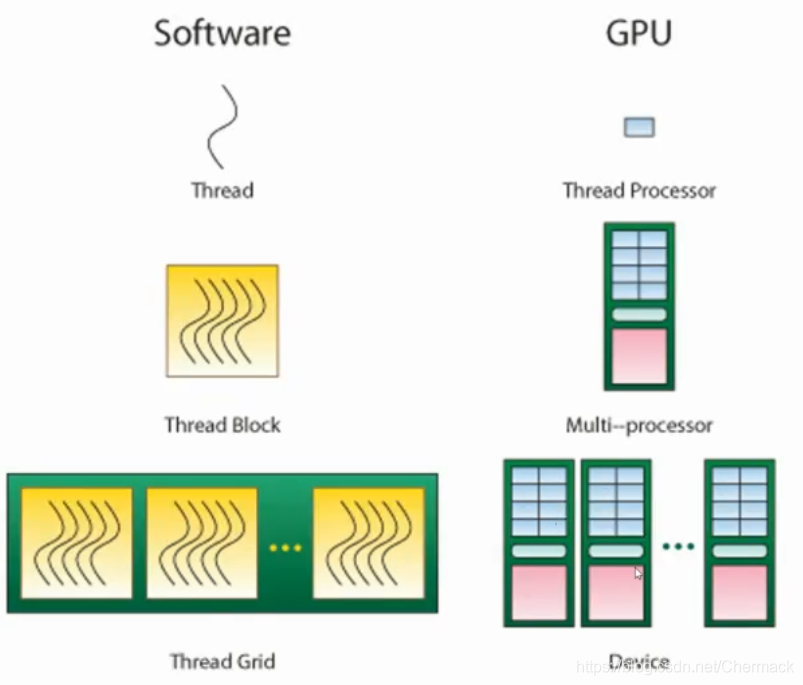
之前都是根据硬件的物理结构进行讨论的,接下来再对编程模型上CUDA的线程层次进行描述。CUDA将线程进行了二级分组,从大到小依次为Grid,Block,Thread。一个Grid包含多个Block,一个Block包含多个Thread。Grid与Block均可以是二维的或者三维的,一个二维的Grid和Block如图所示:
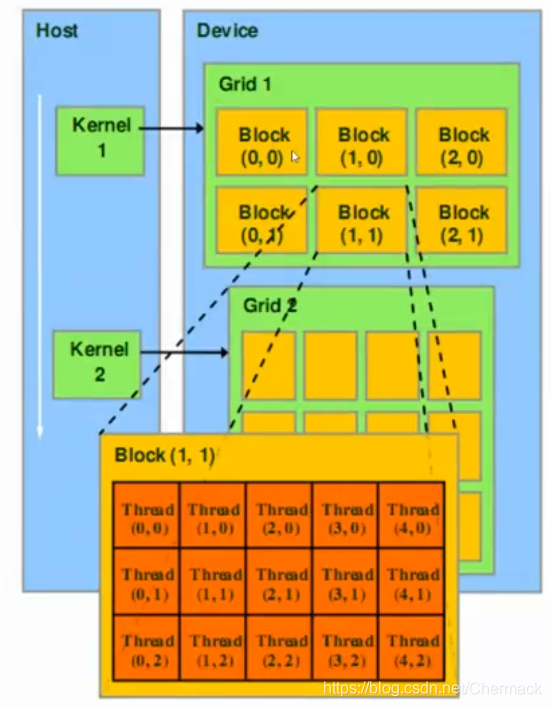
在默认情况下,执行一个GPU并行计算任务时,一个Thread对应于一个Thread Processor,即硬件里面的一个处理器核心。一个Block会对应一个SM单元。一个Grid则对应了一个GPU设备,如下所示:
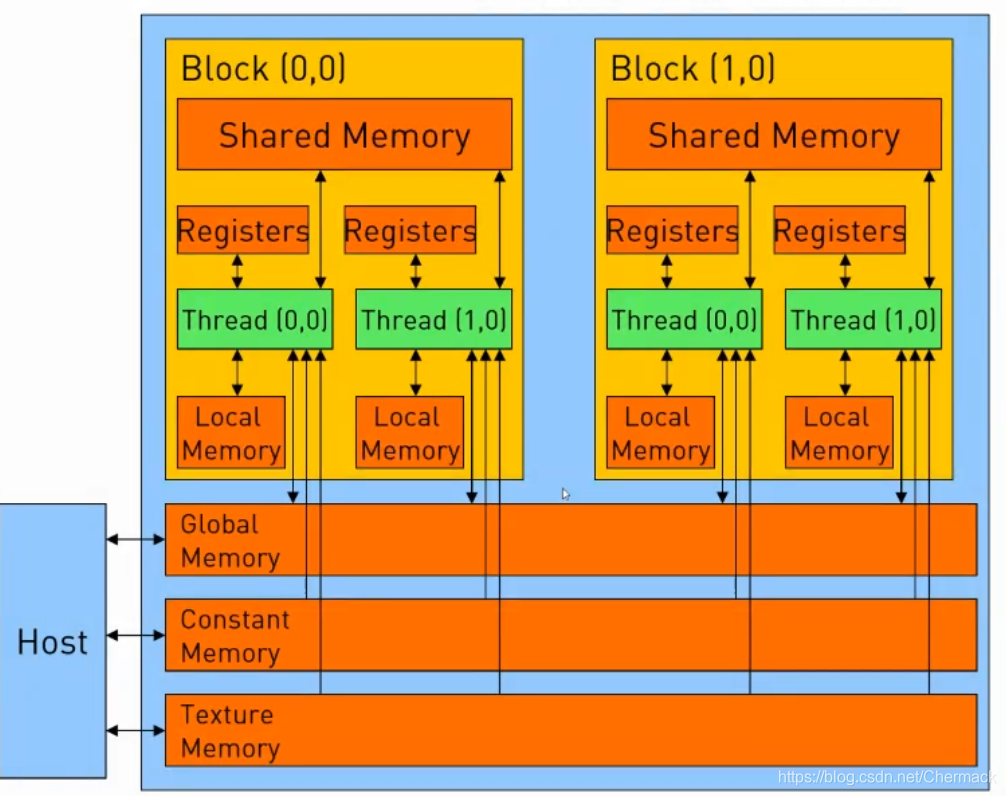
9.CUDA存储结构
下图为一个Grid(对应一个物理GPU设备)的存储结构示意图。图中的Global Memory(全局内存),Constant Memory(常量内存)与Texture Memory(纹理内存)都属于显存的一部分,与Host主机内存相对,在每一个Block之中又有Shared Memory(共享内存)提供给该Block所有线程的共享内存。每一个Thread(线程)又拥有自己的寄存器组(Registers)和本地内存(Local Memory)。
二、CUDA图像处理简单例子
1.环境需求
- python3.6+
- numba
- py-opencv
2.示例代码
import cv2
from numba import cuda
import time
import math
# GPU function
@cuda.jit()
def process_gpu(img):
tx = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
ty = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
for channel in range(3):
color = img[tx, ty][channel] * 2.0 + 30
if color > 255:
img[tx, ty][channel] = 255
elif color < 0:
img[tx, ty][channel] = 0
else:
img[tx, ty][channel] = color
# CPU function
def process_cpu(img, dst):
height, width, channels = img.shape
for h in range(height):
for w in range(width):
for c in range(channels):
color = img[h, w][c] * 2.0 + 30
if color > 255:
dst[h, w][c] = 255
elif color < 0:
dst[h, w][c] = 0
else:
dst[h, w][c] = color
if __name__ == '__main__':
img = cv2.imread("../image.jpg")
height, width, channels = img.shape
dst_cpu = img.copy()
start_cpu = time.time()
process_cpu(img, dst_cpu)
end_cpu = time.time()
time_cpu = (end_cpu - start_cpu)
print("CPU process time: " + str(time_cpu))
##GPU function
dImg = cuda.to_device(img)
threadsperblock = (32, 32)
blockspergrid_x = int(math.ceil(height / threadsperblock[0]))
blockspergrid_y = int(math.ceil(width / threadsperblock[1]))
blockspergrid = (blockspergrid_x, blockspergrid_y)
cuda.synchronize()
start_gpu = time.time()
process_gpu[blockspergrid, threadsperblock](dImg)
end_gpu = time.time()
cuda.synchronize()
time_gpu = (end_gpu - start_gpu)
print("GPU process time: " + str(time_gpu))
dst_gpu = dImg.copy_to_host()
# save
cv2.imwrite("result_cpu.jpg", dst_cpu)
cv2.imwrite("result_gpu.jpg", dst_gpu)
print("Done.")
3.代码解读
为了方便查看,再将线程层次图放在这里:
示例程序主要读入图片并进行亮度变换,算法为针对图片的每一个像素点的每一个通道的值都乘以2加上30。因为每一个像素都是独立的,所以该任务可以拆分为并行执行的任务。GPU部分,需要根据线程模型给每一个GPU处理核心分配任务。首先使用cuda.to_device(img) 将图片从主机内存拷贝到显存。然后,分配一个Block有(32,32)即1024个线程。然后根据图像的宽高和刚刚定义的Block大小,来确定Grid中分为多少个Block。
#GPU function
dImg = cuda.to_device(img)
threadsperblock = (32, 32)
blockspergrid_x = int(math.ceil(height / threadsperblock[0]))
blockspergrid_y = int(math.ceil(width / threadsperblock[1]))
blockspergrid = (blockspergrid_x, blockspergrid_y)
准备好以后,便通过调用核函数(Kernel function)来执行GPU程序,需要指定上方代码计算出的threadsperblock和blockspergrid :
process_gpu[blockspergrid, threadsperblock](dImg)
关于核函数(即GPU执行的函数)的定义,需要在函数上方写上 @cuda.jit() 注解,用于标识其为核函数。核函数内部可以根据定义的block大小和grid大小将计算任务分配到不同的计算单元上。根据cuda.blockIdx.x获取块ID的横坐标,乘以块的横坐标维度(本例为32)再加上线程ID的横坐标,即可唯一确定图像上的一个横坐标点。纵坐标的表示类似(这一块的实现类似于如何将二维数组转化为一维数组进行表示,可以参考相关内容进行理解)。
def process_gpu(img):
tx = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
ty = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
for channel in range(3):
color = img[tx, ty][channel] * 2.0 + 30
if color > 255:
img[tx, ty][channel] = 255
elif color < 0:
img[tx, ty][channel] = 0
else:
img[tx, ty][channel] = color
4.结果展示
运行本程序,可以看到GPU处理速度比CPU快很多,对比结果如下:
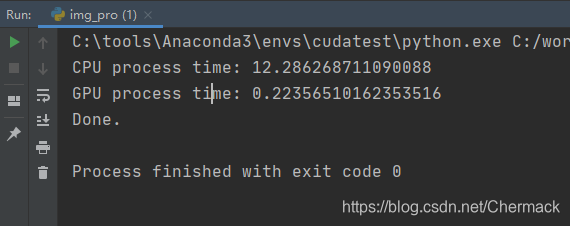
PS:上述实验结果为R7 1700X与RTX 2070对比。
原图为988 x 988如下:

CPU与GPU处理获得相同的结果如下:

参考
https://images.nvidia.cn/cn/webinars/2020/jun09/download-358293.pdf
https://info.nvidia.com/358293-ondemand.html














 3670
3670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









