







在构建大工程的时候,编译效率低下往往令人非常烦恼。Google显然意识到了这一点,其内部开发并使用了Bazel(目前已经开源),Bazel使得原本用Maven需要10多分钟才能构建完成的项目在秒级的时间就完成。为什么Bazel速度这么快?通过我们组对源码的研究,得到了以下结论:
一、Bazel采用特殊的增量模型,只编译必须要编译的文件。
在介绍其增量模型前,首先需要了解几个必要的概念。
数据模型:
1.SkyValue:。包含输入文件,输出文件,源文件和配置文件等。是图中的节点。
2.SkyKey:路径。是一个字符串,哈希这个字符串将得到路径对应的节点。
3.SkyFunction: 用来评估哪些节点是需要编译的递归函数,以SkyKey为参数。
Bazel增量模型的数据结构是一棵树:

其中SkyValue作为结点,如FileA,其本质是文件或者包。边为依赖关系,如FileB向FileD连一条边,表示FileB依赖于FileD。那么依赖关系图就建立了。
SkyFunction以SkyKey为参数,SkyKey又映射到SkyValue。
我们通过顶层的SkyKey来调用SkyFunction,图1中就是映射到FileA的SkyKey。
对这个图进行并行的深度优先搜素遍历来判断哪些结点是需要被重新编译的。加入我们更改了FileB,我们知道FileB的反向传递闭包上的所有点都是需要被重新编译的,即FileB,FileA。增量模型完成了"只编译必要文件"。
进一步的,在这个自底向上的模型中,如果更改了FileI,按照上述思路,我们需要编译FileI,FileD,FileB,FileA。假如我们发现FileB编译后仍然与之前编译后的代码相同,那么我们就不需要编译FileA。
二、Bazel还用到了分布式缓存技术
仅仅使用增量模型,要达到10秒构建的要求是远远不够的,Bazel采用集群式的服务端大量缓存远程数据,这样我们可以将必要信息和编译信息缓存在远程服务,如果代码没有没有更改,那么我们在没有本地缓存的情况下,可以利用远程服务端缓存,这样即使我们更换了电脑,任然能够利用之前的编译信息来快速编译。
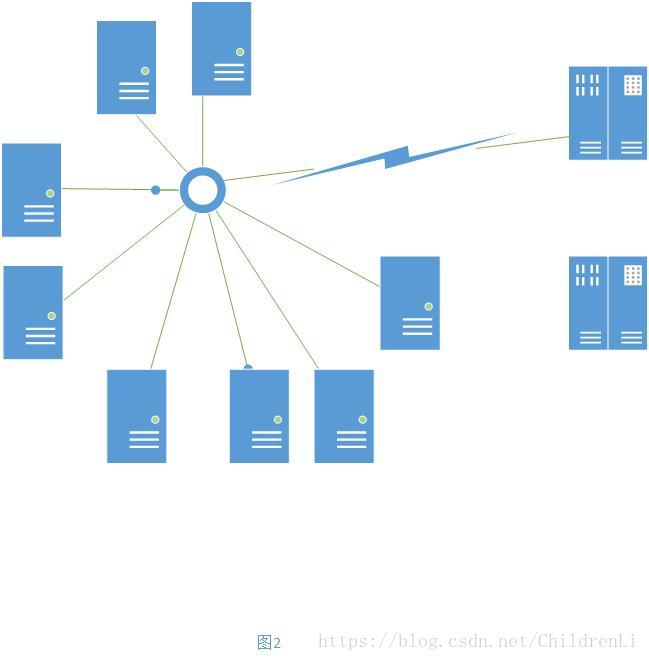
图中描述的是一个中心节点,将一群服务器集成化,来达到集群式缓存的效果,客户端电脑通过中心节点与服务器集训进行信息交互,利用服务端的缓存。他产生了两方面的作用:
1.使得缓存数据能在多台电脑之间共享
2.缓存一些必要文件使得编译速度提高,特别是在局域网中速度能得到进一步提高。














 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









