







一、数据库的 join 查询
数据库提供了多种类型的连接方式,它们之间的区别在于:从相互交叠的不同数据集合中选择用于连接的行时所采用的方法不同。
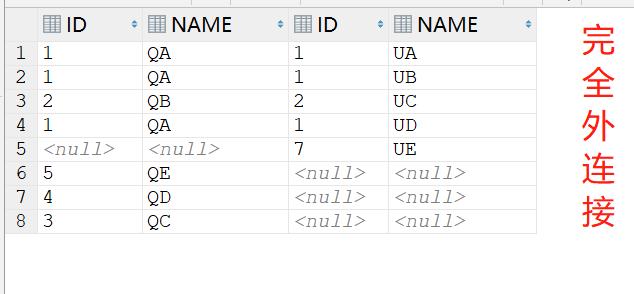
A.内连接
内连接,即最常见的等值连接。【两边的表都加限制】
B.外连接
- 左外连接:左表不加限制,保留左表的数据,匹配右表,右表没有匹配到的行中的列显示为 null。【左外连接就是在等值连接的基础上加上左表中的未匹配数据】
- 右外连接:右表不加限制,保留右表的数据,匹配左表,左表没有匹配到的行中列显示为 null。【右外连接就是在等值连接的基础上加上右表中的未匹配数据】
- 完全外连接:左右表都不加限制。即结果为:左右表匹配的数据+左表没有匹配到的数据+右表没有匹配到的数据。【完全外连接就是在等值连接的基础上将左表和右表的未匹配数据都加上】
连接的语法:【通常外连接省略outer关键字】
left/right/full outer join …on
left/right/full join …on
(+)号的作用:+号可以理解为补充的意思,即哪个表有加号,这个表就是匹配表。加在右表的列上代表右表为补充,为左外连接。加在左表的列上代表左表为补充,为右外连接。
注意:完全外连接不支持(+)写法。
创建两种表,生出测试数据:
CREATE TABLE TQA (
id number,
name VARCHAR2(10)
);
CREATE TABLE TUB (
id number,
name VARCHAR2(10)
);
INSERT INTO TQA VALUES(1,‘QA’);
INSERT INTO TQA VALUES(2,‘QB’);
INSERT INTO TQA VALUES(3,‘QC’);
INSERT INTO TQA VALUES(4,‘QD’);
INSERT INTO TQA VALUES(5,‘QE’);
INSERT INTO TUB VALUES(1,‘UA’);
INSERT INTO TUB VALUES(1,‘UB’);
INSERT INTO TUB VALUES(2,‘UC’);
INSERT INTO TUB VALUES(1,‘UD’);
INSERT INTO TUB VALUES(7,‘UE’);
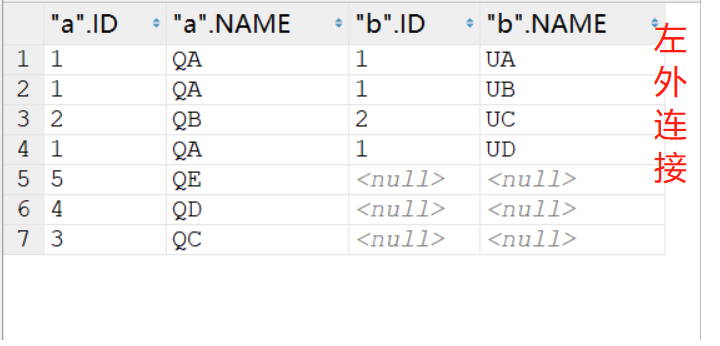
1️⃣左外连接

select * from TQA a left join TUB b on a.id=b.id;
select * from TQA a,TUB b where a.id=b.id(+);
2️⃣右外连接
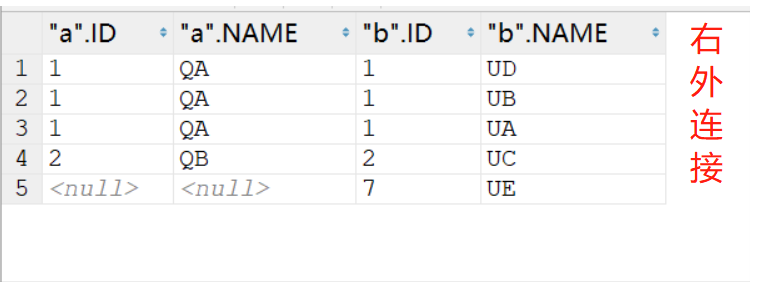
select * from TQA a right join TUB b on a.id = b.id;
select * from TQA a,TUB b where a.id(+)=b.id;
3️⃣完全外连接
select * from TQA a full join TUB b on a.id=b.id;
4️⃣等值连接(内连接也可省略关键字inner,直接写成join)
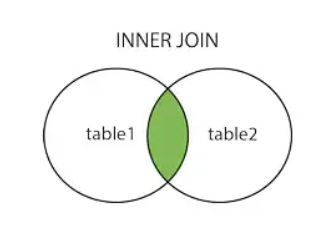
select * from TQA a,TUB b where a.id=b.id;
select * from TQA a join TUB b on a.id=b.id;~~~~~等值连接也可以这样写
select a.name,b.age from TQA a join TUB b using(id)【`using(id)`等价于`on a.id=b.id`】
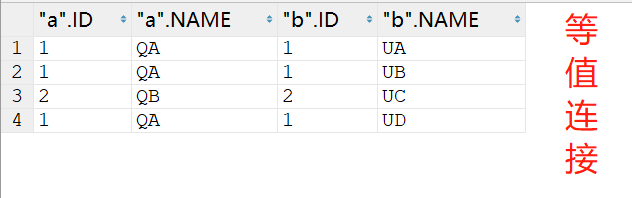
注意:等值连接和完全外连接是有区别的。等值连接是只把满足条件的两个表的行相连,然后显示出来。完全外连接是把匹配查询条件的、左表没有匹配到的、右表没有匹配到的行都显示出来。
二、总结
SQL 连接(inner/outer join)包括以下:
- 内连接(两边的表都加限制)–[inner] join
- 左外连接(左边的表不加限制)–left [outer] join
- 右外连接(右边的表不加限制)–right [outer] join
- 全外连接(左右两表都不加限制)–full [outer] join
在左外连接和右外连接时都会以主表为基础表,该表的内容会全部显示,然后加上主表和匹配表匹配的内容。 如果主表的数据在匹配表中没有记录,那么在相关联的结果集行中列显示为空值(null)。
内连接,可以使用"(+)",但是必须省略。即两张表均为"主表",都不是匹配表。而对于外连接, 也可以使用“(+) ”来表示。关于外连接使用(+)的一些注意事项:
- (+)操作符只能出现在 where 子句中,并且不能与 outer join 语法同时使用。
- 当使用(+)操作符执行外连接时,如果在 where 子句中包含有多个条件,则必须在所有条件中都包含(+)操作符。
- (+)操作符只适用于列,而不能用在表达式上。
- (+)操作符不能与 or 和 in 操作符一起使用。
- (+)操作符只能用于实现左外连接和右外连接,而不能用于实现完全外连接。
三、注意
left jon on:当 on 条件存在多个时候(left join on … and …)会出现一些与预期不符的查询结果。left join on 多条件失效,会导致主表的记录全部查出来,and 条件没有起作用。回顾 left join 的定义,主表会返回所有行,所以 left join 如果对左边表进行约束的话是不会生效的;但是,对 left join 的右边表添加条件的话是生效的!反之,right join 同理。

create table a(f1 int, f2 int, index(f1))engine=innodb;
create table b(f1 int, f2 int)engine=innodb;
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
表 a 和 b 都有两个字段 f1 和 f2,不同的是表 a 的字段 f1 上有索引。然后,两个表中都插了 6 条记录,其中在表 a 和 b 中同时存在的数据有 4 行。
1️⃣两个表 join 包含多个条件的等值匹配,是都要写到 on 里面,还是只把一个条件写到 on 里面,其他条件写到 where 部分?也就是如下 Q1 和 Q2 有何区别?
select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2);/*Q1*/
select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q2*/
这两个语句的语义逻辑并不相同。二者执行结果如下:
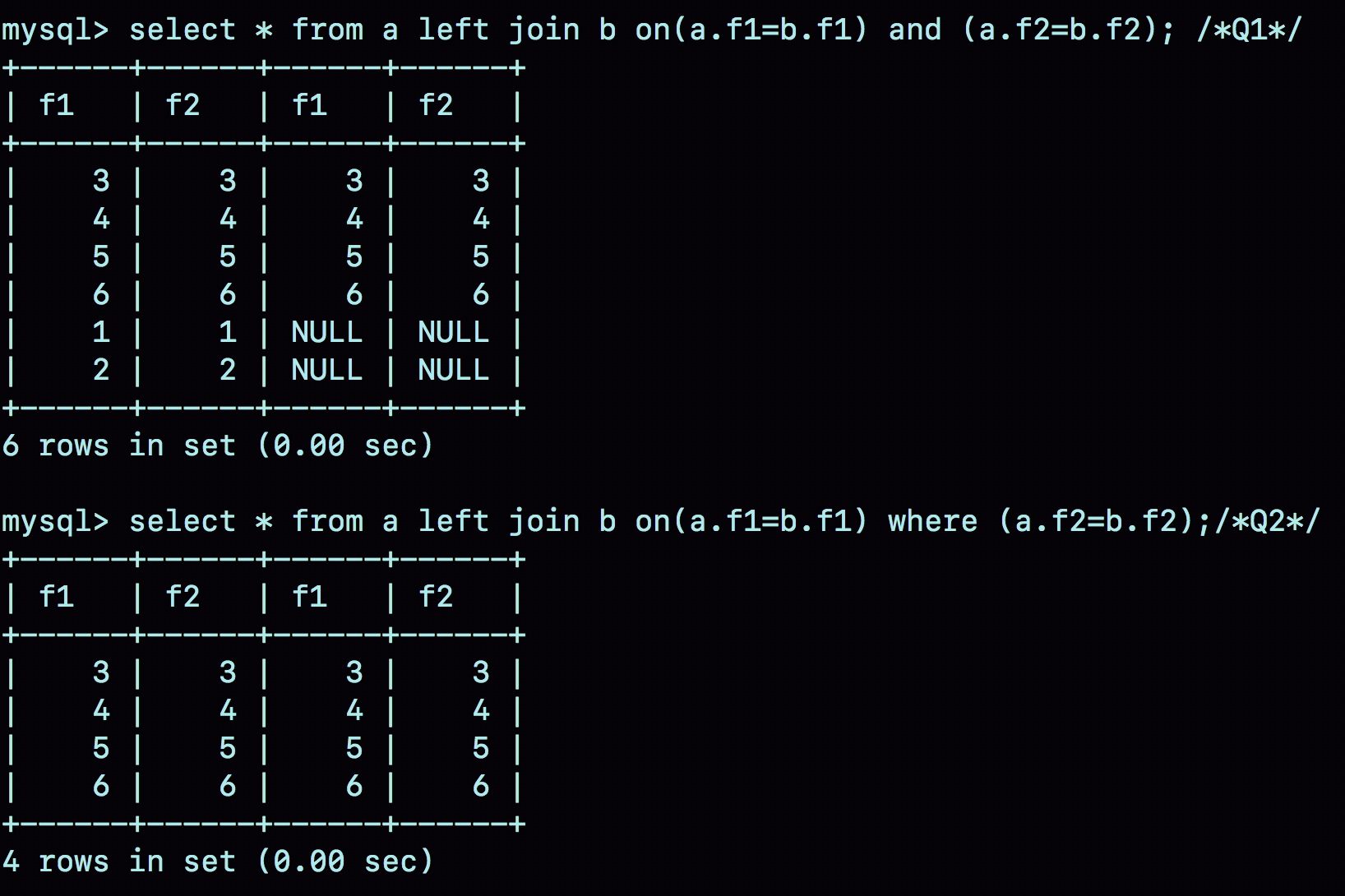
可以看到:
- Q1 返回的数据集是 6 行,表 a 中即使没有满足匹配条件的记录,查询结果中也会返回一行,并将表 b 的各个字段值填成 NULL。
- Q2 返回的数据集是 4 行。从逻辑上可以这么理解,最后两行,由于表 b 中没有匹配的字段,结果集里面 b.f2 的值是空,不满足 where 的条件判断,因此不能作为结果集的一部分。
Q1 的 explain 结果:

Q1 结果符合预期:驱动表是表 a,被驱动表是表 b。由于表 b 的 f1 字段上没有索引,所以使用的是 Block Nexted Loop Join(简称BNL) 算法。由此,这条语句的执行流程如下:
- 把表 a 的内容读入 join_buffer 中。因为是 select *,所以字段 f1 和 f2 都被放入 join_buffer 了。
- 顺序扫描表 b,对于每一行数据,判断 join 条件(也就是a.f1=b.f1 and a.f2=b.f2)是否满足,满足条件的记录,作为结果集的一行返回。如果语句中有 where 子句,需要先判断 where 部分满足条件后,再返回。
- 表 b 扫描完成后,对于没有被匹配的表 a 的行(也就是(1,1)、(2,2)这两行),把剩余字段补上 NULL,再放入结果集中。
对应的流程图如下: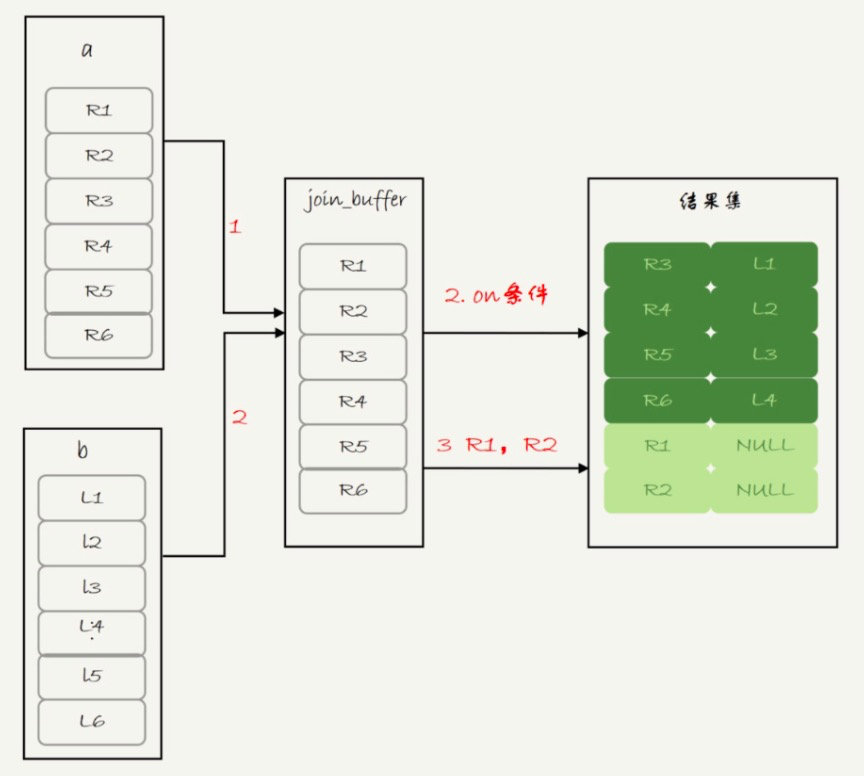
可以看到,这条语句确实是以表 a 为驱动表,而且从执行效果看,也和使用 straight_join 是一样的。
2️⃣如果用 left join 的话,左边的表一定是驱动表吗?
语句 Q2 的查询结果里面少了最后两行数据,是不是就是把上面流程中的步骤 3 去掉呢?看下语句 Q2 的 explain 结果:

可以看到,这条语句是以表 b 为驱动表的。而如果一条 join 语句的 Extra 字段什么都没写的话,就表示使用的是 Index Nested-Loop Join(简称NLJ)算法。因此,Q2 的执行流程:顺序扫描表 b,每一行用 b.f1 到表 a 中去查,匹配到记录后判断 a.f2=b.f2 是否满足,满足条件的话就作为结果集的一部分返回。
Q1 和 Q2 这两个执行流程为什么会有这么大差距?其实,这是因为优化器基于 Q2 这个查询的语义做了优化。
Q2 里面 where a.f2=b.f2 就表示,查询结果里面不会包含 b.f2 是 NULL 的行,如此 Q2 的语义就是“找到这两个表里面,f1、f2 对应相同的行。对于表 a 中存在,而表 b 中匹配不到的行,就放弃”。所以 Q2 虽然用的是 left join,但是语义跟 join 是一致的。
因此,优化器就把这条语句的 left join 改写成了 join,然后因为表 a 的 f1 上有索引,就把表 b 作为驱动表,这样就可以用上 NLJ 算法。在执行 explain 之后,再执行 show warnings,就能看到这个改写的结果,如图:
这个例子说明,即使在 SQL 语句中写成 left join,执行过程还是有可能不是从左到右连接的。也就是说,使用 left join 时,左边的表不一定是驱动表。
3️⃣这样看来,如果需要 left join 的语义,就不能把被驱动表的字段放在 where 条件里面做等值判断或不等值判断,必须都写在 on 里面。那如果是 join 语句呢?
select * from a join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q3*/
select * from a join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q4*/
执行 explain 和 show warnings,看看优化器是怎么做的: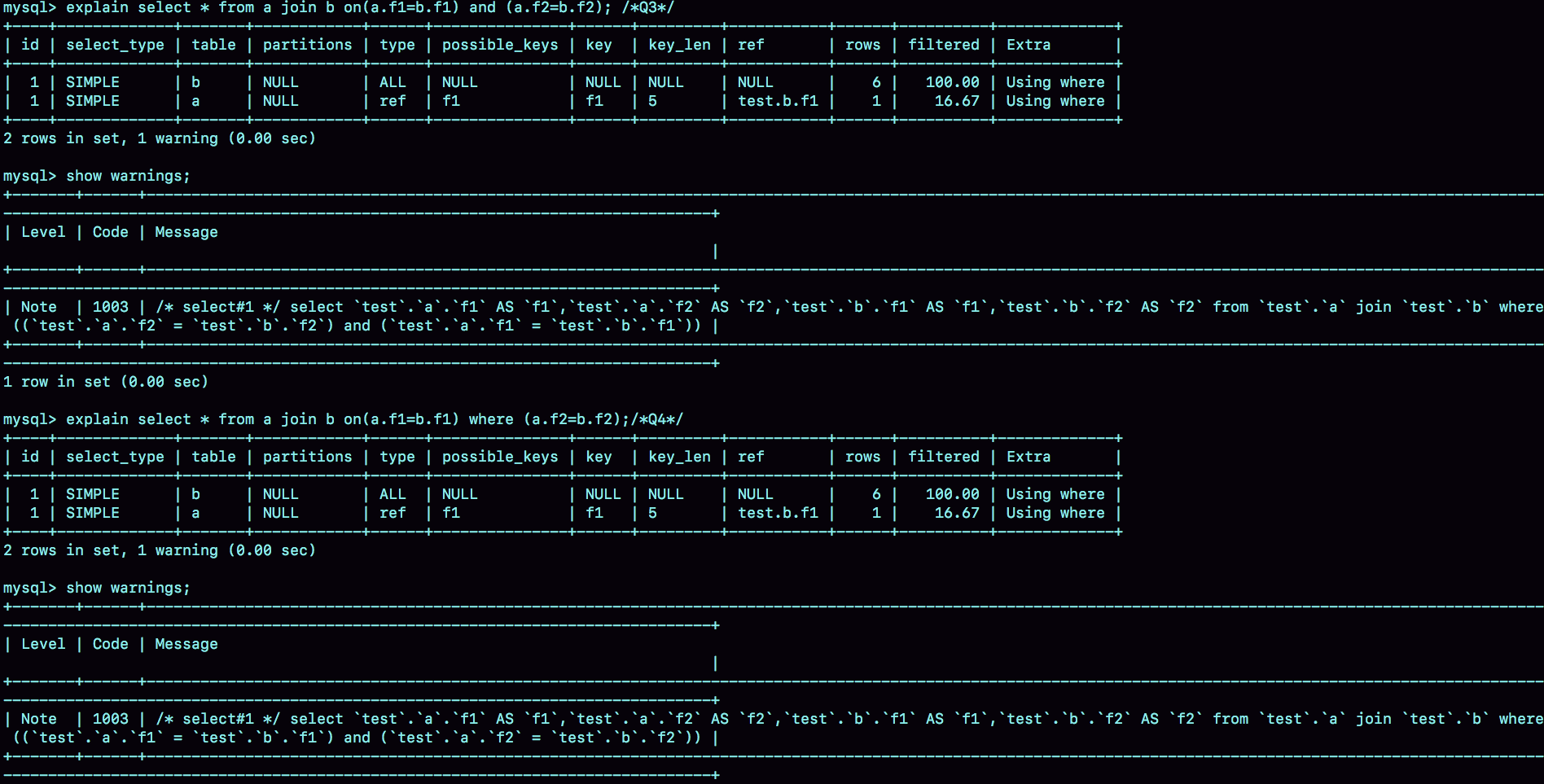
可以看到,这两条语句都被改写成:
select * from a join b where (a.f1=b.f1) and (a.f2=b.f2);
执行计划自然也是一模一样的。也就是说,在这种情况下,join 将判断条件是否全部放在 on 部分就没有区别了。
四、Simple Nested Loop Join 的性能问题
join 语句使用不同的算法,对语句的性能影响会很大。虽然 BNL 算法和 Simple Nested Loop Join 算法都是要判断 M*N 次(M和N分别是join的两个表的行数),但是 Simple Nested Loop Join 算法的每轮判断都要走全表扫描,因此性能上 BNL 算法执行起来会快很多。
1️⃣BNL 算法的执行逻辑
- 首先,将驱动表的数据全部读入内存 join_buffer 中,这里 join_buffer 是无序数组。
- 然后,顺序遍历被驱动表的所有行,每一行数据都跟 join_buffer 中的数据进行匹配,匹配成功则作为结果集的一部分返回。
2️⃣Simple Nested Loop Join算法的执行逻辑
顺序取出驱动表中的每一行数据,到被驱动表去做全表扫描匹配,匹配成功则作为结果集的一部分返回。
Simple Nested Loop Join 算法,其实也是把数据读到内存里,然后按照匹配条件进行判断,为什么性能远不如 BNL 算法?
解释这个问题,需要用到 MySQL 中索引结构和 Buffer Pool 的相关知识点:
-
在对被驱动表做全表扫描的时候,如果数据没有在 Buffer Pool 中,就需要等待这部分数据从磁盘读入;从磁盘读入数据到内存中,会影响正常业务的 Buffer Pool 命中率,而且这个算法天然会对被驱动表的数据做多次访问,更容易将这些数据页放到 Buffer Pool 的头部。
-
即使被驱动表数据都在内存中,每次查找“下一个记录的操作”,都是类似指针操作。而 join_buffer 中是数组,遍历的成本更低。















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











