







本文是 ECCV2016 的工作,主要是介绍了一个在当时是新的姿态估计的网络结构。这里主要是对整个网络的结构和思想进行一个梳理,可以进一步明白后序一些基于此网络结构的工作(例如ECCV2018 CornerNet),不涉及到 姿态估计领域 的一些见解和讨论,所以本文主要就是分为两节,引出课题和介绍 hourglass 网络。
原文链接: https://arxiv.org/abs/1603.06937
源码链接: http://www-personal.umich.edu/~alnewell/pose
1. Introduction
准确的姿态估计是理解人类在图片或者视频中行为的关键。对于一张单独的 RGB 图像, 我们希望可以准确定位出一些身体重要的关键点。对于人体姿态的理解及姿体结构对于高层任务,例如人机交互等是很重要的。
在姿态估计领域同样有着多个严峻的挑战。一个好的估计系统必须对遮挡还有严重的变形有很好的鲁棒性,能检测出一些奇特的姿势,包括对光照和衣服等变化的影响具有不变性。
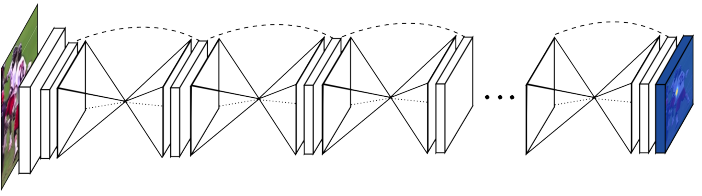
本文提出 “stacked hourglass” 的网络来进行姿态估计,它可以获取到所以尺度图像的信息,因为网络结构的下采样和上采样操作,从结构上看像一个沙漏(hourglass) 而得名,像其他卷积方法一样,我们也将输入图片下采样到一个很小的分辨率,再上采样,并将统一尺寸的特征结合起来。另一方面,hourglass 网络由于它更对称的拓扑结构又不同于之前的一些网络设计。
本文级联了多个 Hourglass 的结构并结合了中间监督的使用,重复的双向推理对网络最后的性能至关重要。
随着 DeepPose 工作的提出,人们把姿态估计的目光从一些传统方法转向了深度网络。 DeepPose 是直接对人体的关节点的坐标 x,y 进行回归。
单个 “horglass” 模块结构如下图所示:
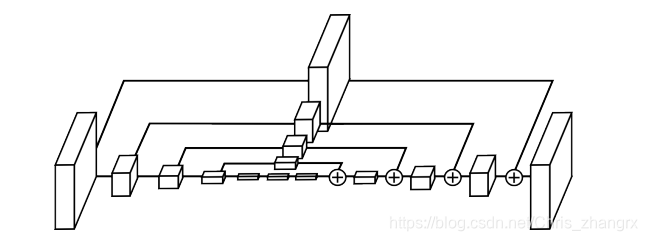
这里的 “hourglass” 结构很像 FCN,结构最大的不同点就是更加对称的容量分布(包括特征从高分辨率到低分辨率,从低分辨率到高分辨率),可能其他工作,FCN 或者 holistically-nested 结构都是高分辨率到低分辨率(down-top)容量比较大(结构较复杂),低分辨率到高分辨率(top-down)就结构简单。 这里的结构也与一些做分割,样本生成,去噪自编码器,监督/半监督特征学习等的结构很像,但是操作的本质不同, “hourglass” 没有使用 unpooling 操作或者是解卷积层,而是使用了最简单的最近邻上采样和跨层连接来做 top-down(上采样)。还有一个不一样的点是,本文工作堆叠了多个 “hourglass” 的结构来构建整个网络。
——————————————————————————————————————————————
这里为什么要做多个 “hourglass” 结构的级联?
文中指出相互关键点之间也是有关系的,知道了双肩就更好预测肘,知道了肘的位置就更好的预测手的位置,而每一个 “hourglass” 结构都很会产生一个热力图预测,这样级联起来,上一个 “hourglass” 学习并预测的关节点之间的联系也可以为下一级所用。
——————————————————————————————————————————————
2. Network Architecture
2.1 Hourglass design
Hourglass 结构的设计主要是源于想要抓住每个尺度信息的需求。例如一些局部信息对识别一些特征(例如脸,手等)很重要,而对于最后姿态的估计需要对整个身体有一个好的理解,这就要抓住很多局部的特征信息并结合起来。人的朝向,他们四肢的排列,相邻关节的关系都是在不同尺度图像中最好辨认的。 而 hourglass 则是一个简单的,最小化的设计,有这个能力捕捉全部的特征信息并做出最后的像素级别的预测。
有的工作采用多分支的结构来达到整合多分辨率的目的,本文则是采用单一网络+跨层连接来保留每一个分辨率的空间信息,hourglass 结构最低会将特征图降到 4x4 的分辨率。
top-down 阶段: 采用卷积层 + maxpooling
down-top 阶段: 采用 [参考文献15] 中提出的最近邻上采样 + 跨层连接
因为要跨层连接,进行点加(element-wise addtion),所以它们对应分辨率的通道数都是一样的,这就成了更加对称的结构。 最后输出端用连续两个 1x1 的卷积层来产生最后的输出。
2.2 Layer Implementation
上面提出的 “hourglass” 只是一个形状像沙漏的结构,内部的实现细节还是很灵活的,文中也对一些结构进行了探索,例如从 GoogLeNet,ResNet 中学习的用连续的 3x3 代替 5x5,残差结构, Inception 结构等 ,最终定下的设计是使用:残差结构,最大的卷积核不超过 3x3, 瓶颈结构。
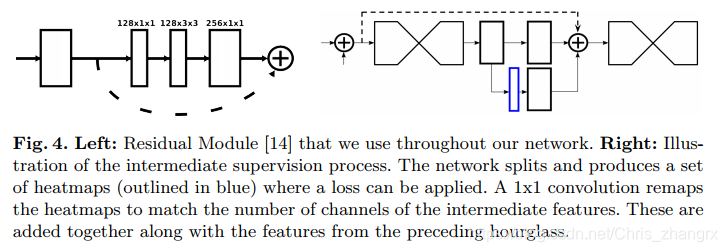
整个网络如果直接使用 256x256 的分辨率将会需要很大的 GPU 内存,所有最高的分辨率以及最后输出的分辨率都是 64x64,这并不影响最后的结果。 整个网络从一个卷积核大小是 7x7,stride=2 的卷积层开始,后面跟一个残差模块和一个 Max-pooling,让分辨率直接从 256 降到 64. 沙漏模块之前还是两个残差模块,所有的残差模块的输出都是 256 个通道。
2.3 Stacked Hourglass with Intermediate Supervision
上面提到为什么做多个 “hourglass” 结构的级联,并且每一个级联预测的 heatmaps (上图中蓝色区域)都会与真值对比产生一个 loss,最后将这些 loss 都加在一起,文中通过实验证明了这样做比只考虑最后一个 loss 的结果要好很多,这种考虑网络中间部分输出的训练就是中间监督(intermediate supervision)














 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









