







论文链接:https://arxiv.org/abs/1511.00561
1、简介
目前,利用深度神经网络进行语义分割虽然取得了一定效果,但在进行特征提取的时候,通过pooling进行下采样,会导致结果较为粗糙。为得到更好的分割效果,本文作者提出了一种用于语义分割的全卷积网络:SegNet网络,提高分辨率的同时对于边界的定位较为准确。
SegNet以场景理解为目标应用,是一种end-to-end网络,该网络作为FCN的变形,相较于FCN需要更小的存储空间,并且利用pooling indices进行upsampling,在存储空间以及计算方面均具有较高效率,同时具有较高的准确度。
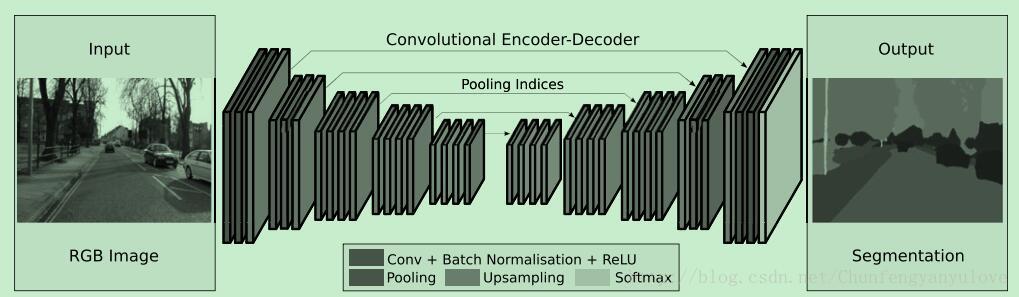
2、SegNet结构
SegNet包含两部分,分别为encoder网络以及decoder网络,encoder网络采用VGG结构,由VGG16的前13个卷积层构成,去掉全连接层,一方面可以得到较高分辨率的特征图,另一方面可以使网络的参数数量有较大的减少(134M减少到14.7M)。与之对应decoder也具有13层,decoder的最后连接多类别的softmax分类器进行像素的分类。
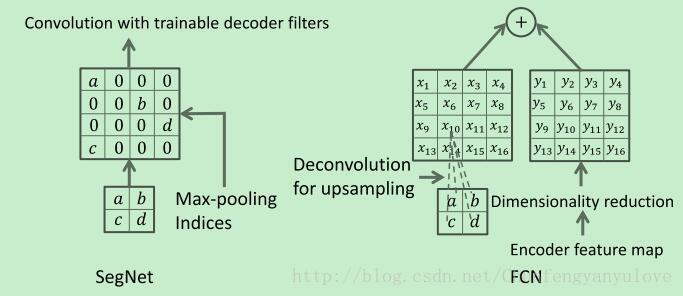
由于在segment的过程中,边界轮廓信息是至关重要的,然而在进行下采样的过程中,许多信息会丢失,所以需要在下采样之前对轮廓信息进行保存,本文采用一种有效的方法,即max-pooling indices。max-pooling indices方法如下图2所示,在此不再详述。
max-pooling indices的优势:
- 使边界轮廓更准确。
- 降低参数数量,实现end-to-end的训练。
- 该结构可以很好的合并到各种encoder-decoder结构中
3、不同decoder实验分析
为验证不同decoder结构的标线,作者针对SegNet以及FCN网络设计了不同的decoder结构,并进行了详细的实验分析,实验结果如图3所示。
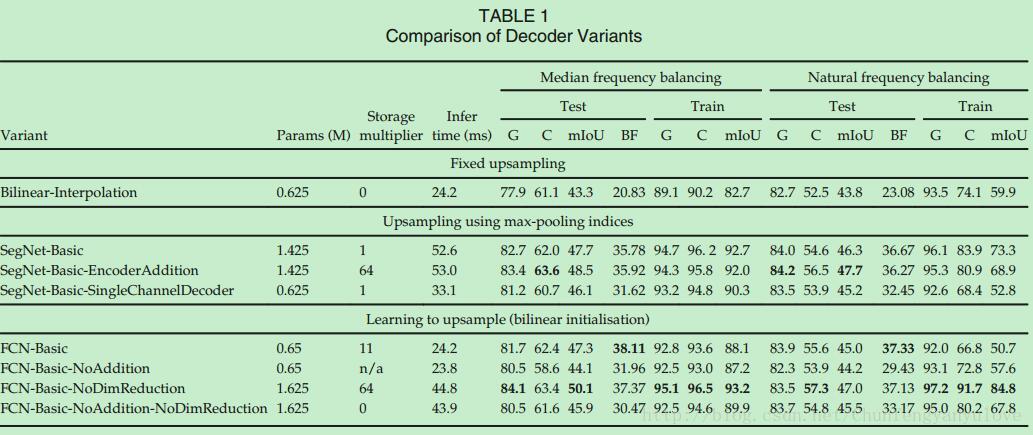
其中,网络介绍如下:
- Bilinear-Interpolation : 双线性插值上采样。
- SegNet-Basic: 4*(encodes[conv+bn+relu+maxpooling]+decoders[conv+bn]),kenel size: 7*7。
- SegNet-Basic-SingleChannelDecoder: decoder采用单通道滤波器,可以有效减少参数数量。
- SegNet-Basic-EncoderAddition: 将decoder与encoder对应的特征图相加。
- FCN-Basic:与SegNet-Basic具有相同的encoders,但是decoders采用FCN的反卷积方式。
- FCN-Basic-NoAddition:去掉特这天相加步骤,字学习上采样的卷积核。
- FCN-Basic-NoDimReduction: 不进行降维。
通过表1分析,可以得到如下分析结果:
- bilinear interpolation 表现最差,说明了在进行分割时,decoder学习的重要性。
- SegNet-Basic与FCN-Basic对比,均具有较好的精度,不同点在于SegNet存储空间消耗小,FCN-Basic由于feature map进行了降维,所以时间更短。
- SegNet-Basic与FCN-Basic-NoAddition对比,两者的decoder有很大相似之处,SegNet-Basic的精度更高,一方面是由于SegNet-Basic具有较大的decoder,同时说明了encoder过程中低层次的feature map的重要性。
- FCN-Basic-NoAddition与SegNet-Basic-SingleChannelDecoder:证明了当面临存储消耗,精度和inference时间的妥协的时候,我们可以选择SegNet,当内存和inference时间不受限的时候,模型越大,表现越好。
作者总结到:
- encoder特征图全部存储时,性能最好。 这最明显地反映在语义轮廓描绘度量(BF)中。
- 当限制存储时,可以使用适当的decoder(例如SegNet类型)来存储和使用encoder特征图(维数降低,max-pooling indices)的压缩形式来提高性能。
- 更大的decoder提高了网络的性能。
4、场景实验
作者分别在CamVid以及SUN RGB-D数据集进行实验,实验结果如下表:
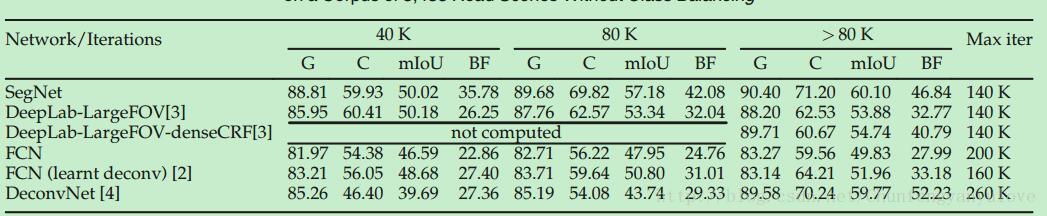
由上表可以发现,当训练次数少的时候,SegNet的优势明显,但是当训练次数增加后,DeconvNet的BF精度已经超过了SegNet,但是总体而言,SegNet具有较好的精度。

在这个分类任务中,所有的模型的表现均较差,主要原因在于类别较小并且类别分布偏差,DeepLab-LargeFOV,具有较高的mIoU,但是SegNet具有较高的G,C,BF分数。














 2857
2857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









