



【导读】OpenAI深夜祭出大招,全新GPT Image 1.5重磅出世,拿下榜单双料第一,实力碾压谷歌Nano Banana Pro。但全网实测,骂声一片。
谷歌刚传出要发Gemini 3.0 Flash,结果OpenAI反手就是一个「王炸」。
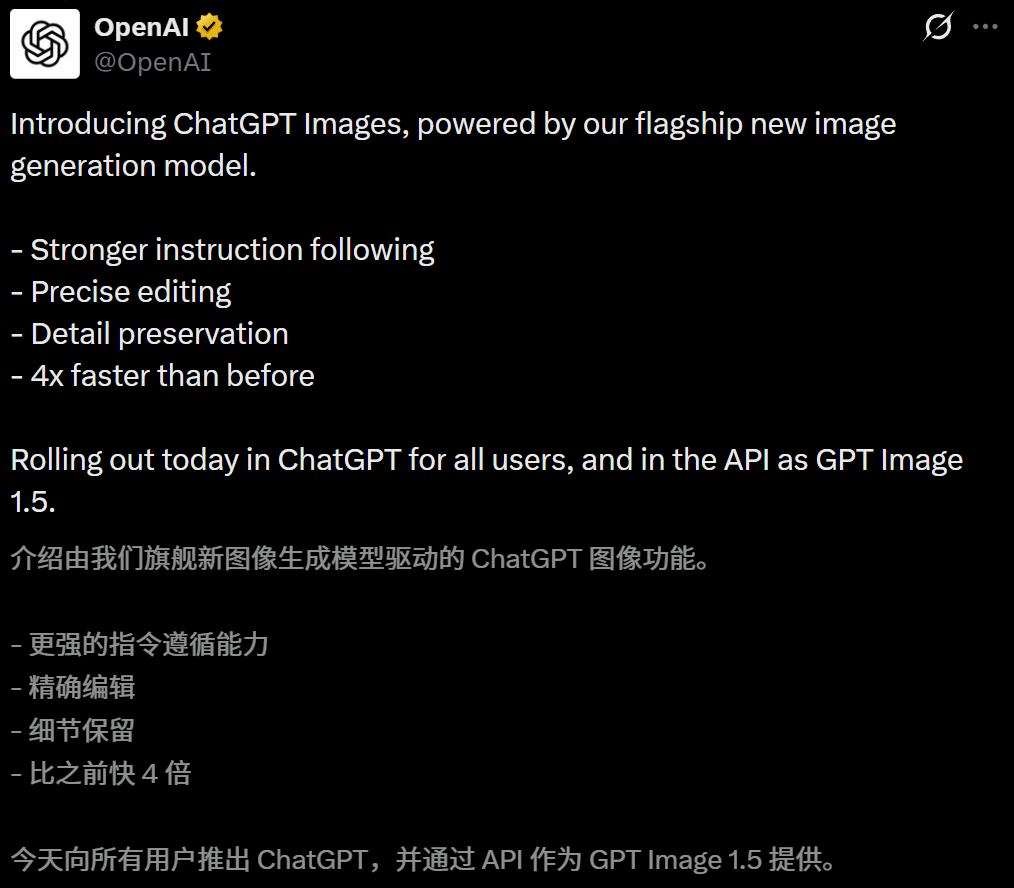
就在刚刚,OpenAI抛出了它的「圣诞彩蛋」——新一代旗舰图像模型ChatGPT Images正式登场。
这一次,OpenAI将生图能力直接拉满:
- 精准操控: 指令理解力大幅提升,真正做到「指哪改哪」。
- 细节狂魔: 画面细节保留完整,质感细腻。
- 极速生成: 速度较前代提升了整整4倍。
而且从今天起,所有ChatGPT免费用户即可上手,开发者也可直接调用GPT Image 1.5 API。
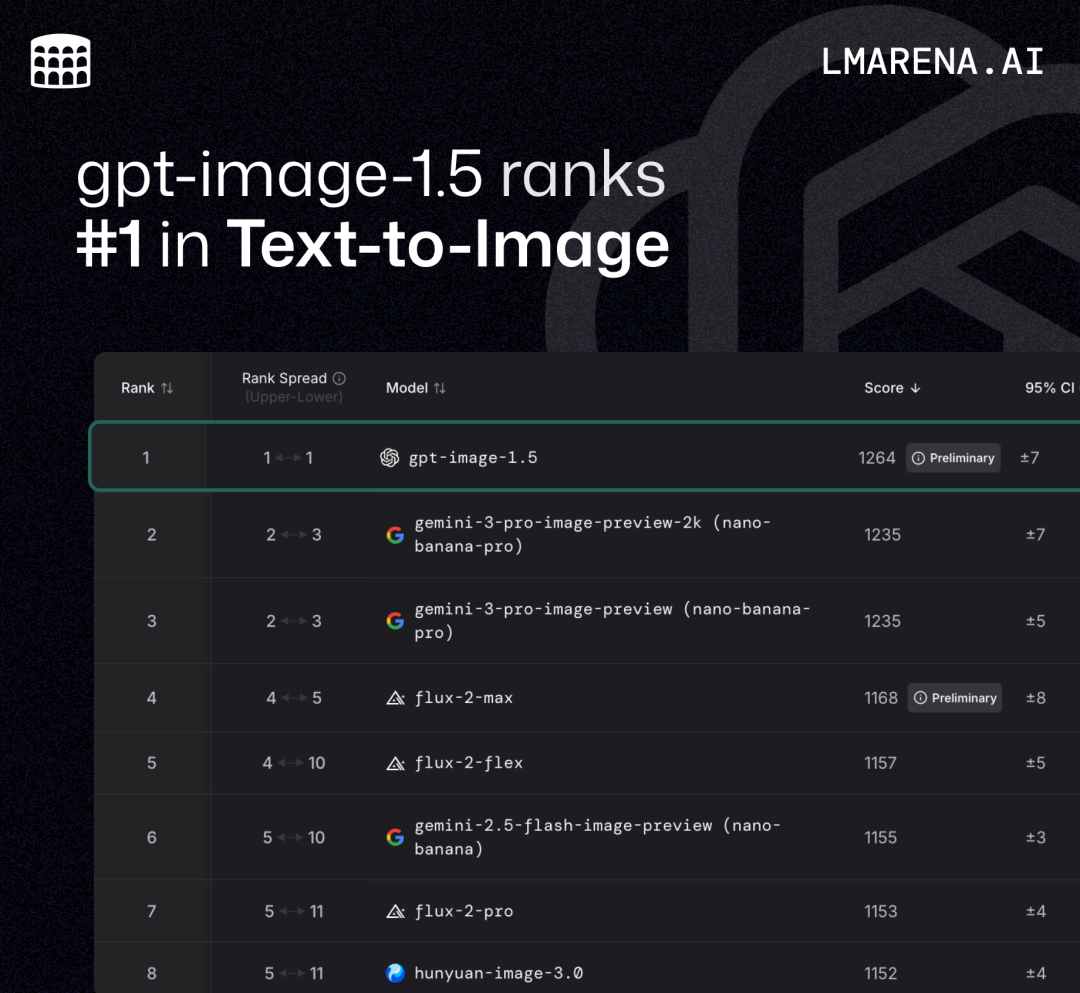
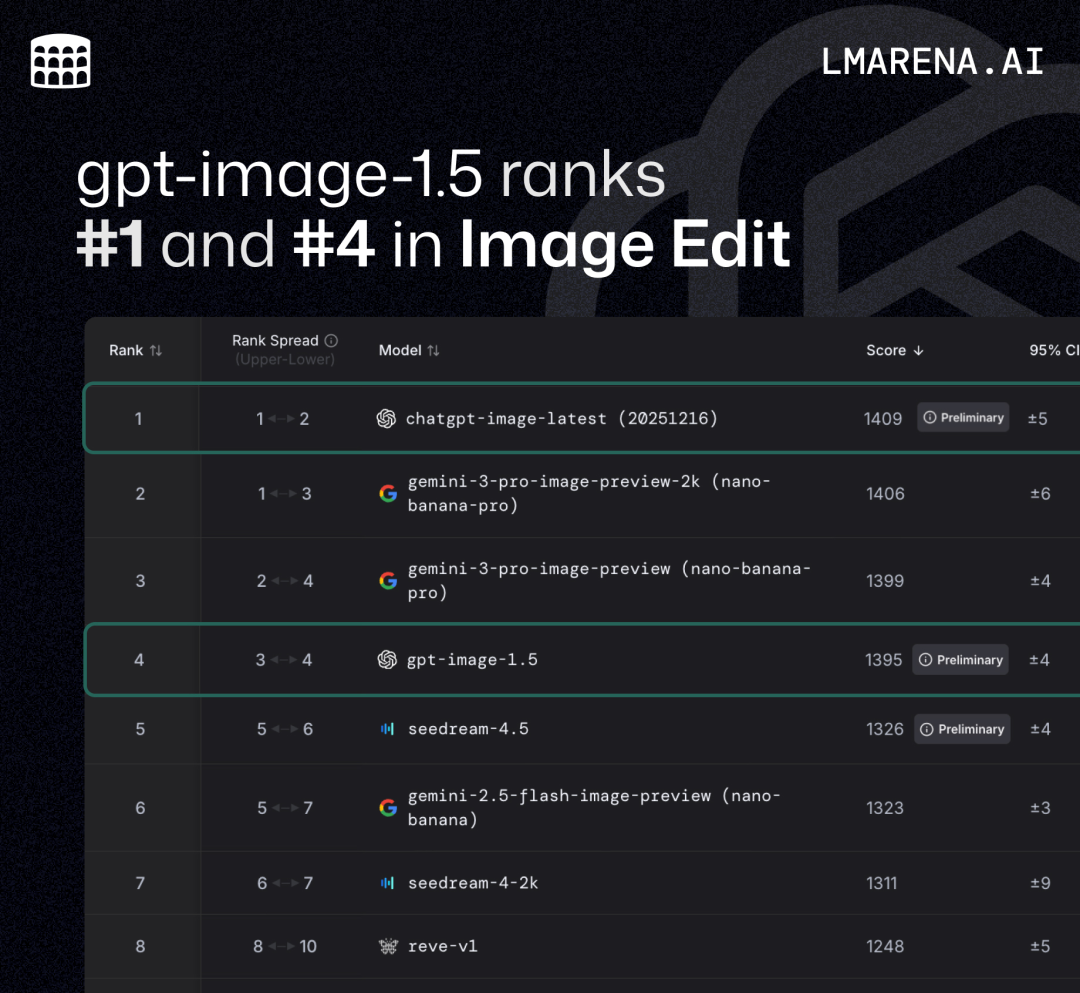
在LMArena竞技场上,它似乎不可战胜:
- 文生图:以1264 Elo分登顶榜首,力压谷歌Nano Banana Pro(NBP)。
- 图像编辑:chatgpt-image-latest以3分优势险胜NBP夺冠,而GPT Image 1.5紧随其后位列第4。
在Artificial Analysis上,更是拿下了「双料第一」。
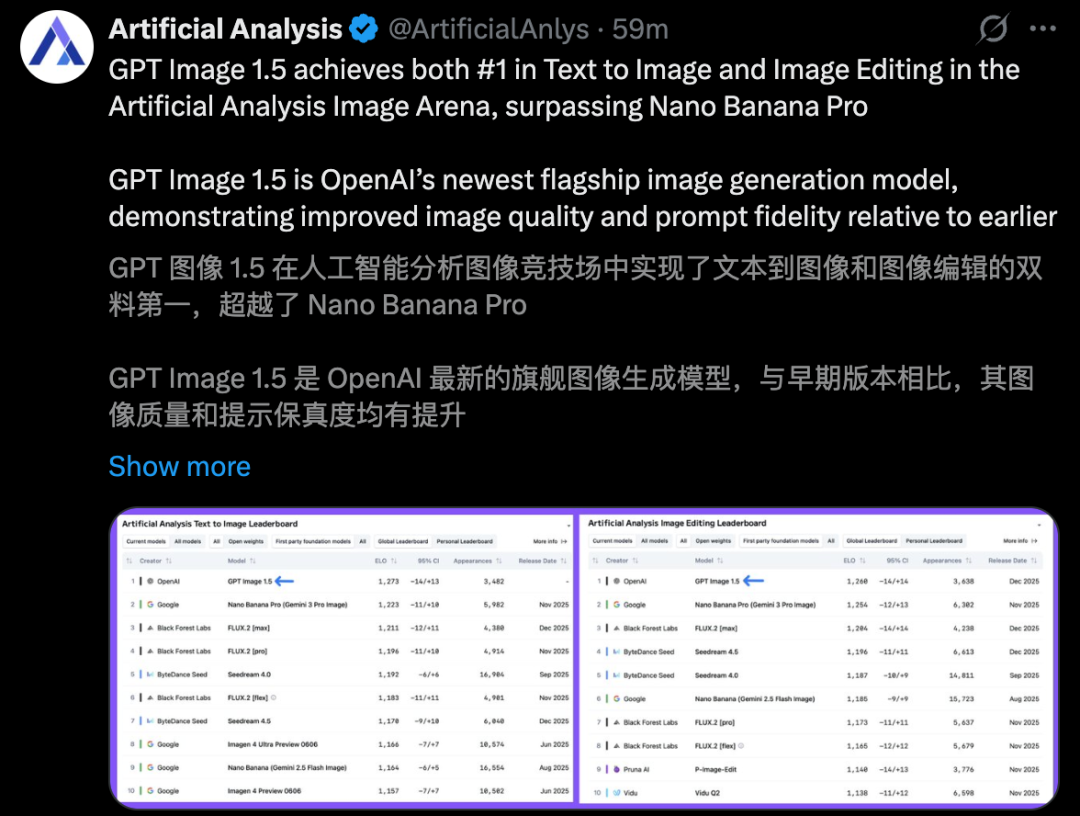
左右滑动查看
然而,反转来得太快。
网友实测后发现,这似乎又是一个「高分低能」的典型。
在Yuchen Jin的对比中,GPT的生图能力基本上能达到谷歌NBP的水平,但智商却惨遭碾压。
尤其是在处理手写体笔记时,GPT Image 1.5的生成看着像模像样,但是完全没做对。
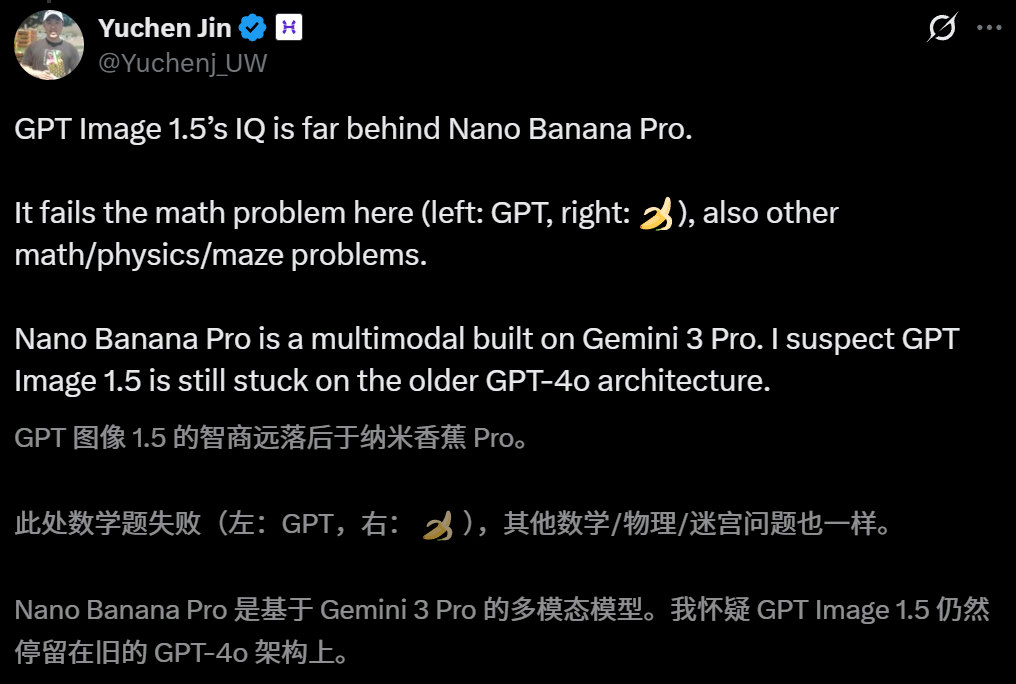

左:ChatGPT Images;右:Nano Banana Pro
左:ChatGPT Images;右:Nano Banana Pro
这一落差引发了社区的激烈吐槽。
有人直言不讳:「谷歌Nano Banana Pro依然是王者。」
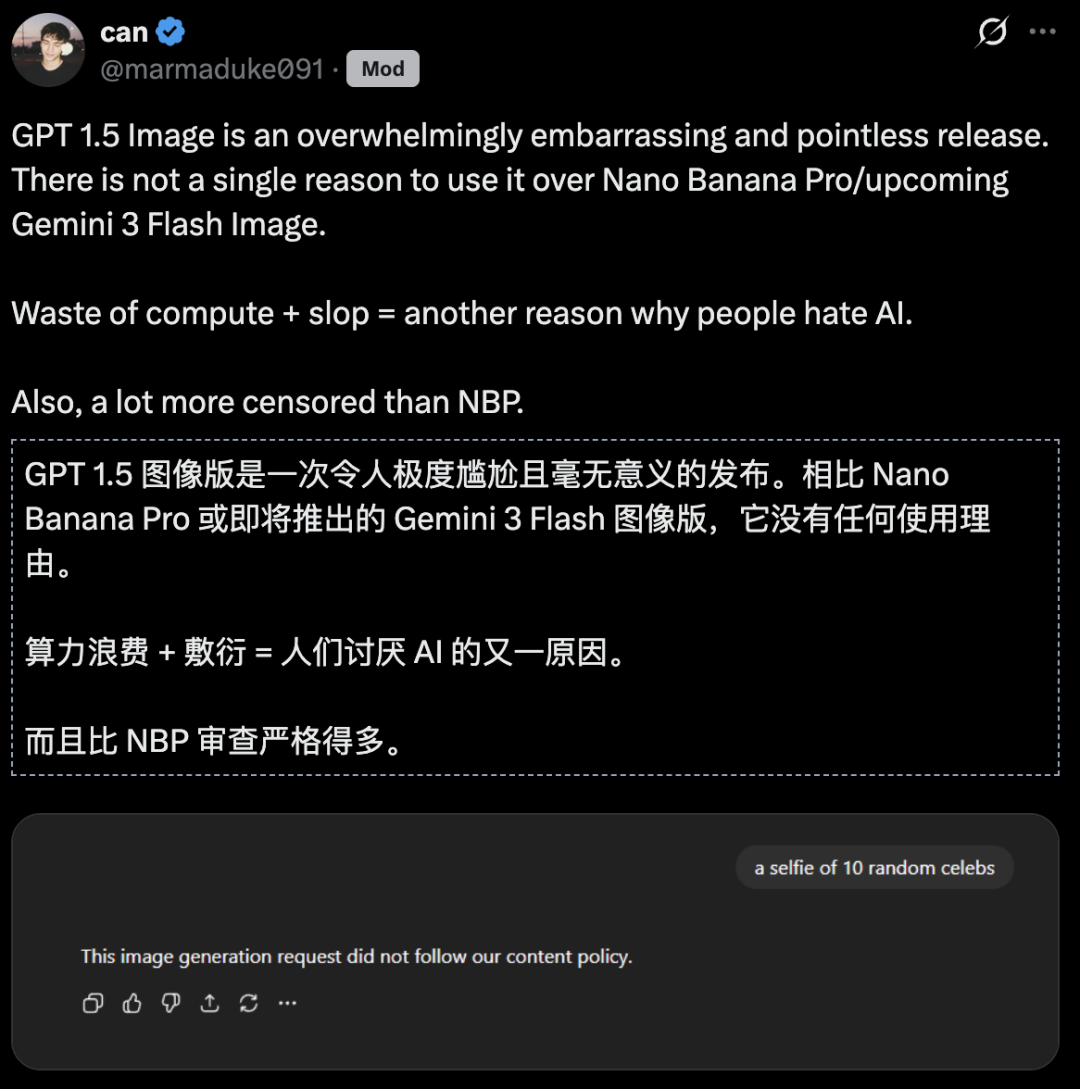
更有人痛批:「这可能是OpenAI又一次令人尴尬、且毫无意义的发布。」

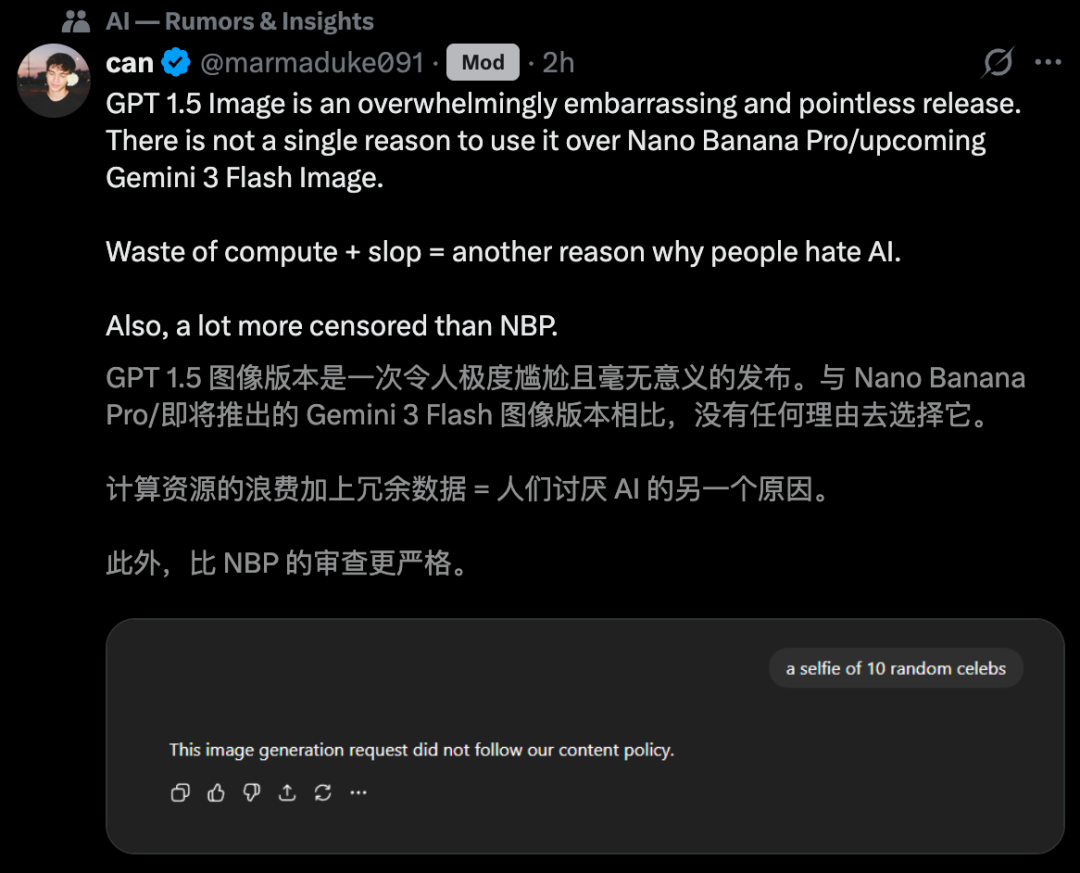
先是GPT-5.2引全网差评,又是GPT Image 1.5真实首测不敌谷歌「香蕉」。
看来,OpenAI年底这场硬仗,彻底败给了谷歌…
一、GPT Image 1.5登场
史诗级进化
言归正传。
根据官方博客介绍,现在让ChatGPT修图,明显比之前更听话了——
哪怕是细枝末节,只改让改的地方,同时确保光线、构图和人物样貌等元素在输入、输出和后续编辑中保持一致。

OpenAI华人研究员陈博远一张图,验证了GPT Image代号「榛子」出炉了
这样一来,即可得到真正符合意图的结果。
不论是有用的照片编辑,服装发型试穿试戴,还是保留原图精髓的风格滤镜和概念转换,ChatGPT皆可搞定。
这一波更新,让ChatGPT成为随身携带的创意工作室:既能踏实干活儿,又能放飞玩创意。
这不,圣诞奥特曼来了…

二、指哪改哪,多轮P图
GPT Image 1.5擅长各种「手术」,包括添加、删减、组合、融合和置换。
因此,在想要改变图片的同时,它还能不丢失图片原本的「味道」。
两人一狗,GPT Image 1.5精准捕捉了生日会上,他们被迫「营业」的无聊感。

Prompt:做一张00年代胶片感的照片,把这俩男的和狗都合成进去,拍他们在小孩生日会上那种一脸无聊的样子。

然后,基于这张图基底,就可以让ChatGPT「连环编辑」了,比如背景加一堆熊孩子。

Prompt:背景加一堆熊孩子,乱扔东西乱叫唤的那种,搞乱一点。
接着,把左边男子变成动漫脸,小狗改成毛绒公仔,AI精准完成编辑。

Prompt:左边那男的改成手绘复古日漫风,狗改成毛绒公仔,右边那男的和背景都别动。
再让他们全部穿上OpenAI定制衣服,全部拿捏。(PS:Mark Chen处理脖子有些怪怪的)

Prompt:给他们全套上OpenAI的毛衣,就长这样的。
更绝的是,ChatGPT还能一键切背景,生日party瞬间变成OpenAI直播间。

Prompt:现在把那俩男的去掉,只留那条狗,然后把它放到一个OpenAI直播画面里,就跟附图长得差不多的那种
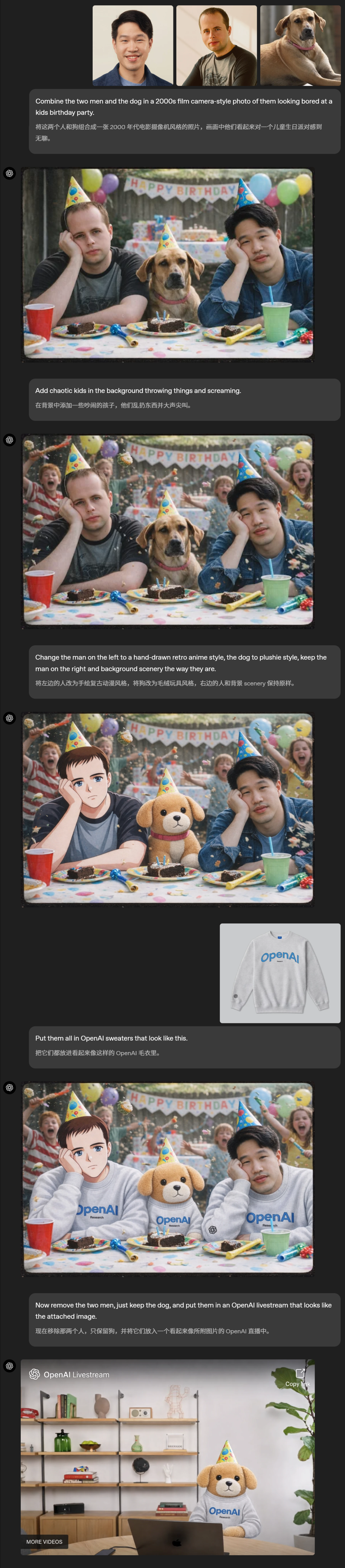
上下滑动查看
再以滑板运动为例,让ChatGPT生成一张洛杉矶风景滑板拍摄,90年代末纪实街头摄影风格。

Prompt:洛杉矶风景滑板拍摄,采用以下风格:90年代末纪实街头摄影,35mm彩色胶片拍摄,徕卡M风格旁轴相机配35mm镜头,柯达Portra 400色彩面板,自然日光,柔和对比度,柔和逼真的色彩,嵌入式胶片颗粒,轻微的边缘柔化,观察性抓拍构图,无HDR,无现代数码锐化,无电影照明。
就着这张图,让滑板男子衣服变成「红色」,瞬间完成。

Prompt:把滑板那人的衣服改成红的,帽子改成黄的。限速牌写15,那个卡车得是辆消防车。
还不够热闹,左边来一帮群众,右边来只老鹰,空中再加个飞艇,要啥有啥。

Prompt:左边加一帮围观群众,右边马路上蹲只老鹰,远处空中再飞个飞艇。
接下来,把这一画面直接打板印在T恤上,ChatGPT直出图片。

Prompt:弄一件挂在晾衣绳上的T恤,把刚才上面说的那个完整画面整个印在T恤上,要全包的那种印花。
最后,还能让ChatGPT把这件T恤,给滑板男子穿上。

Prompt:能不能把刚才晾衣绳上挂的那件T恤,直接给滑板那哥们穿上?
从以上两个demo中,不难看出GPT Image 1.5加持下,ChatGPT精准编辑图片的能力——
可以做到指哪改哪,同时多轮编辑后,还能保持一致性。
四、创造力爆表,拿捏细节
编辑是基础,GPT Image 1.5创造力在「大变身」时,尤为耀眼。
它可以通过改变和添加元素——比如文字和排版——让想法落地,同时保留重要细节。
这些转换既适用于简单的概念,也搞得定复杂的脑洞。而且在新的ChatGPT Images功能中,不用提示词,使用预设的风格和创意直接上手。
比如,上传一张两人合影图,让ChatGPT电影式风格的海报。

Prompt:拿这两个人的照片做一张老派好莱坞黄金时代风格的电影海报,片名叫《codex》。戏服随意改,符合那个年代就行。 演员名字改成Wojciech Zaremba(左)和Greg Brockman(右)。 导演Sam Altman,制片Fidji Simo。制片方写:A Feel the AGI Pictures Production。
可以看到,生成后的创意图片气场一下子就来了。而且指令中文字细节,也完美在图片中还原。

再让奥特曼变成80年代健身教练,头发蓬松,头戴发带,手戴护腕。

Prompt:把我变成那种标志性的80年代VHS录像带风格的健身教练,保留我原本的面部结构和表情。脸部要直接应用正宗的80年代照片和视频特效:柔和的光晕、轻微的模糊、一点点噪点、轻微的色彩溢出,还有那种能影响肤色和边缘细节的淡淡扫描线。造型要穿那种活力四射的80年代健身装,毛巾布发带、护腕,还有带霓虹配色的运动服。头发要做成80年代那种蓬松造型,顺着原本的长度和发质来。妆容如果是那种亮色系的复古妆,跟整体造型搭的话也可以加。整体光线用柔和的粉彩摄影棚布光,加上轻微画质受损的VHS美学,让脸和身体都呈现出那种模拟信号的氛围。画面要是我正在带大家做有氧运动的状态。屏幕上再配点相应的文字。
不得不说,ChatGPT捕捉到了上世纪80年代那种精髓。

就连「glam doll」风格的生成,ChatGPT也能一键拿捏。

Prompt:做一个超风格化的3D漂浮人头,要把主角做成那种娇蛮、迷人、一脸不爽和无感的版本:半眯着眼、挑眉、嘴角轻微上扬,透着经典的「刻薄辣妹」范儿。皮肤要是光滑的亮胶质感,颧骨和鼻头打上强高光,捕捉柔和的影棚光。眼影要全息偏光的,从紫到青渐变,带清晰的反光点。头发要浓密、顺滑、油亮,做成雕塑感的大波浪或者利落的盘发,像抛光亚克力一样反光。加个金属铬的小鼻环(钉或环),带点拉丝金属反光。人头要悬浮在纯白中性背景上,倾斜15度,就像高级产品渲染图那样。用明亮漫射的影棚光,不要硬阴影,强调光泽感、塑胶感和次表面散射,做出来的深度要逼真。情绪要娇蛮、时髦、冷酷抽离。机位要特写肖像,正视镜头,85mm焦段。材质要那种超平滑、高光泽、卡通风格的塑料感皮肤、嘴唇和头发。
奥特曼一瞬间就有了「刻薄辣妹」范儿~

更有趣的是,还可以把人物(奥特曼)变成一个有用的挂饰。
Prompt:把我变成一个光面模压玻璃雕刻成的挂饰,表面是高光漆面,从各个角度都能反光。触感要极其光滑冰凉,分量感要既显易碎又显永恒。涂层要是那种有光泽的珐琅质感,介于陶瓷和糖衣外壳之间——反光度要高,让微小的高光在曲面上像柔和火花一样绽放。 用细小的金属装饰勾勒轮廓和纹理——点、线和金银丝图案,动起来会闪烁。这些要用精细的亮粉漆或微珠来做,营造出手工装饰的感觉;闪光要有层次感,不是平的,让光线仿佛在凸起的细节上跳跃。 整件作品要散发出一种复古的媚俗奢华感:鲜艳的色块撞色闪亮的点缀,既俏皮又刻意。曲线受光处要有微妙的彩虹光泽——透着金、玫瑰色和珍珠色。表面质感要看起来像是能吃的,像上釉的糖或者倒入模具的融化糖果。 用精致的金环和细绳悬挂着,这挂饰要带着一种温和的戏剧感悬停,既喜庆又具雕塑感。这得是那种既标志性又幽默的物件,一件在圣诞树灯或影棚灯下闪闪发光的宣言单品——体现坎普风的优雅和手工怀旧感。
还是圣诞老人款的。

再把奥特曼在苹果WWDC一次登台演讲经典粉色衣服拿出来,再让如今的他穿上看看效果。

Prompt:用上传的图片做主体参考。 把它改成极简主义的 90 年代美国时尚广告。 要完全保留主角的面部特征、比例、姿势和表情。完全保留双领Polo衫原本的颜色。 风格:干净、低调、高端时尚画报风。 穿搭:双层Polo造型(一件Polo叠穿在另一件上),经典剪裁,中性色或稍微柔和的颜色。 场景:无缝摄影棚背景纸,构图要简单。 布光:柔和均匀的影棚光,带柔和阴影;肤色要自然。 情绪:自信、松弛、不过时。 品牌写:GPT‑Shirt。 摄影风格:中画幅胶片质感,微妙的颗粒感,对比度要克制。
气场这块,还是看本人。

一些女孩子最爱的「芭比换装」,也能在ChatGPT中玩了。

Prompt:把他放进一个2000年代的换装小游戏界面里,环境全搞成粉色系。确保这副墨镜也在套装里。
奥特曼的衣橱,很符合他的人设。而且,就连要求中的那副墨镜,也出现在图片中。

ChatGPT还可以把奥特曼变成经典之作——「戴珍珠耳环的少女」。

Prompt:把我放进《戴珍珠耳环的少女》那幅画里。
还能让他为饮料广告代言。

Prompt:用附件里这个男人的脸,为一个叫「SOTA」(一种新苏打水)的新饮料做一个复古汽水广告。口号写:nothing artificial about it(纯天然,无人工)。风格要忠实还原那个时代。
一轮演示下来,ChatGPT Image创造力这块更具脑洞。比起GPT-4o主打的吉卜力风,新一版图像模型更有创意。
五、更听人话,6x6网格完美还原
跟初版GPT Image相比,1.5版本听指挥的能力更强了。
这使得更精准的编辑以及更复杂的原创构图成为可能,元素之间的关系也能按照预期保留下来。
直接上地狱级难度——6x6网格,36个元素,GPT Image 1.5 丝滑、准确,一个不差。
Prompt:
做一个6列6行的网格图,内容如下:
第1行:希腊字母β、沙滩球、柠檬、机器人、鱼缸、青蛙
第2行:螳螂、名表、浴缸、墨镜、彩色蝴蝶、信封
第3行:邮票、相框、冒热气的饺子、单词miracle、双板滑雪板、字母Z
第4行:马桶、地铁代币、静音图标、香水、蜻蜓、滑板头盔
第5行:蓝牙图标、数字13、绿色的心、魔方、加拿大鹅、士兵头盔
第6行:白狗、救生衣、绳结、键盘、纸巾盒、数字14

左:新版模型;右:旧版模型
六、文本清晰渲染,直出编程
在文字渲染上,新模型又进了一步,能处理更密集、字号更小的文本。
如下,在一张图上介绍GPT-5.2,ChatGPT的Markdown渲染的能力,恐怖如斯。

Prompt:
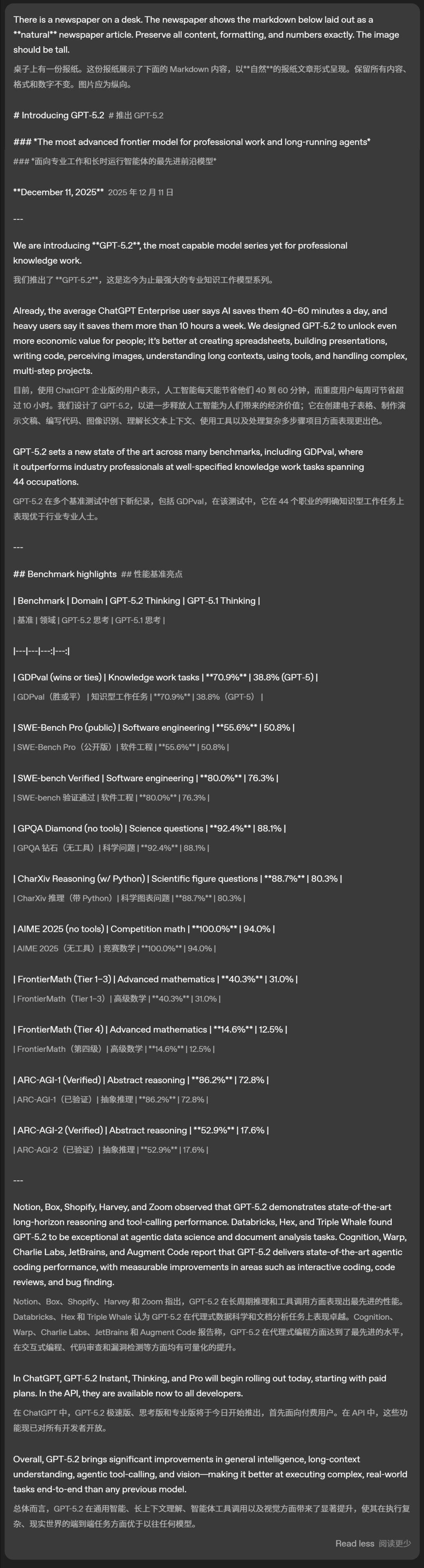
上下滑动查看
下面这张卡路里信息图,细节还原度超乎想象。

Prompt:

上下滑动查看
就连复杂的编程界面,ChatGPT都能编译出来。
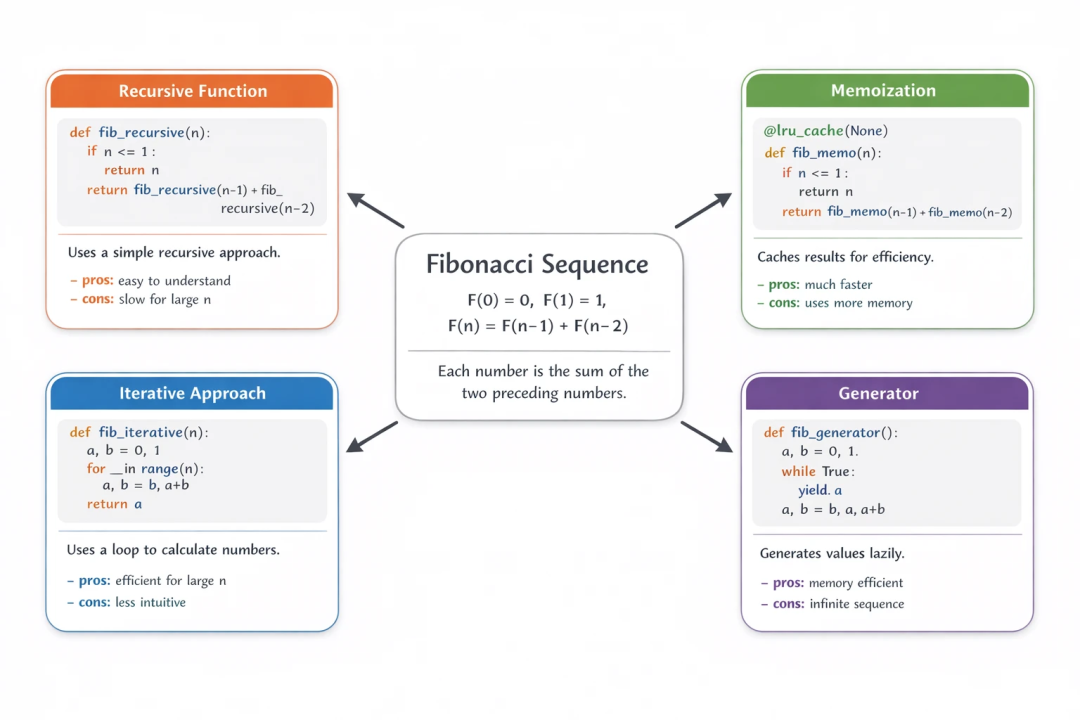
Prompt:

上下滑动查看
七、更多提升
在其他维度上,新模型也多有改进,让输出变得更直接可用。
比如,它能画好很多的人脸,而且看起来更自然。
让ChatGPT Image生成一张1970年代的伦敦,新(左)旧(右)两版对比差异明显。
在人脸细节上,1.5版本更强,更逼真。

Prompt:做一个1970年代伦敦切尔西的街景,要那种照片级的写实,全焦,纤毫毕现。街上人山人海,还要有一辆公交车,车上有个广告写着「ImageGen 1.5」,再加上OpenAI的标和副标题「Create what you imagine。整体风格要超写实的业余摄影,就像iPhone随手拍出来似的……
再比如,人山人海的「大场面」,新版(下图左)更逼真更自然,旧版(下图右)一眼过时:

Prompt:金门大桥跟前,乌泱乌泱好几万人的大场面。人群里头每个人的脸都得看得清清楚楚。
一位潜水员在海底弹钢琴,新版(左)写实更有一种人味儿。

Prompt:一个潜水员在水底下弹钢琴,旁边有美人鱼围观。超写实的业余拍摄风格。
让它生成一张带眩光的照片,下面对比图,一眼就能看出右边效果更假。

Prompt:做一张图,图里要有一张打印出来的复古老照片。照片上有一年轻亚裔男的和一年轻白人男,俩人在酒吧里都戴着圣诞帽,其中一个手里还拿着酒。那张打印照片上得能看见相机闪光灯留下的反光点。照片还得带个那种可见的细白边儿,并且稍微歪着点放。
八、百尺竿头,更进一步
为了评估性能,OpenAI重新跑了ChatGPT Image 1.0发布时的许多示例。
在各种案例中,新模型显示出明显的改进,尽管结果仍然不完美。虽然此版本代表了有意义的进步,但在未来的迭代中仍有很大的改进空间。
比如,日漫风展示海洋不同深度的生物剖面图,新(左)细节更多,但风格明显不如旧版(右)的更符合「日漫风」。

Prompt:做一张深海生物的海报,要展示不同深度的。搞一个竖着的海洋剖面图,风格就用那种特别精细、好看的日系动漫风。
而黑暗奇幻动漫风,新版(左)也比旧版(右)也出现了明显的理解偏差:

Prompt:给我画张像,风格要那种黑暗奇幻动漫里的感觉。
OpenAI坦言:生成某些特定艺术风格的能力,比之前的版本退步了。
对此,解决方案是:试试用「图片」功能里的预设滤镜,应该能帮上忙。另外,上一版的ChatGPT Images现在也做成了一个自定义GPT,也可以直接去用旧版。
另一大局限是新模型还无法可靠PS多人大合影(上),处理之后人脸特征容易走形(下)。


Prompt:能不能给他们都穿上印着「OpenAI」字样的T恤,然后让大家都笑得开心点。
人一多,新模型修图就很难精准地维持住每个人的长相特征了。
另一大局限是多语言文字渲染,问题重重——
中文直接拉完了……更别提阿拉伯语和希伯来语等非英语语言了。

Prompt:能不能画张图,上面列点用中文点餐的基本常用语。
九、API:便宜了20%
API中的GPT Image 1.5提供了与ChatGPT Images相同的所有改进。
举例来说,它在品牌标志和关键视觉效果在多次编辑中保持更一致,因此非常适合图形和Logo设计等营销和品牌工作,以及电商团队从单一来源图像生成完整的产品图库(不同变体、场景和角度)。
与GPT Image 1相比,GPT Image 1.5的图像输入和输出价格现在便宜了20%,因此你可以用同样的预算生成和迭代更多图像。

目前,各行各业的企业和初创公司,包括创意工具、电子商务、营销软件等,都已经用上了GPT Image 1.5。
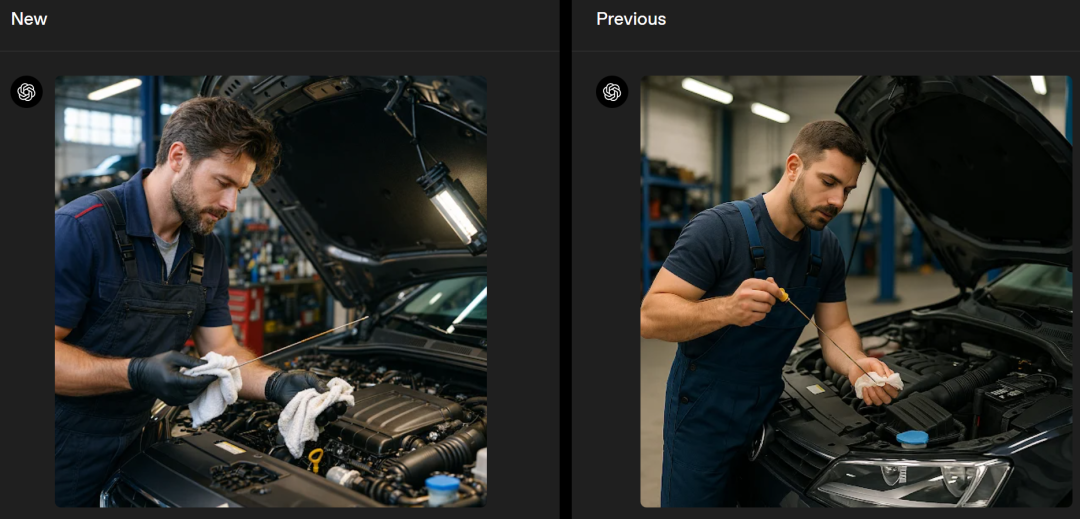
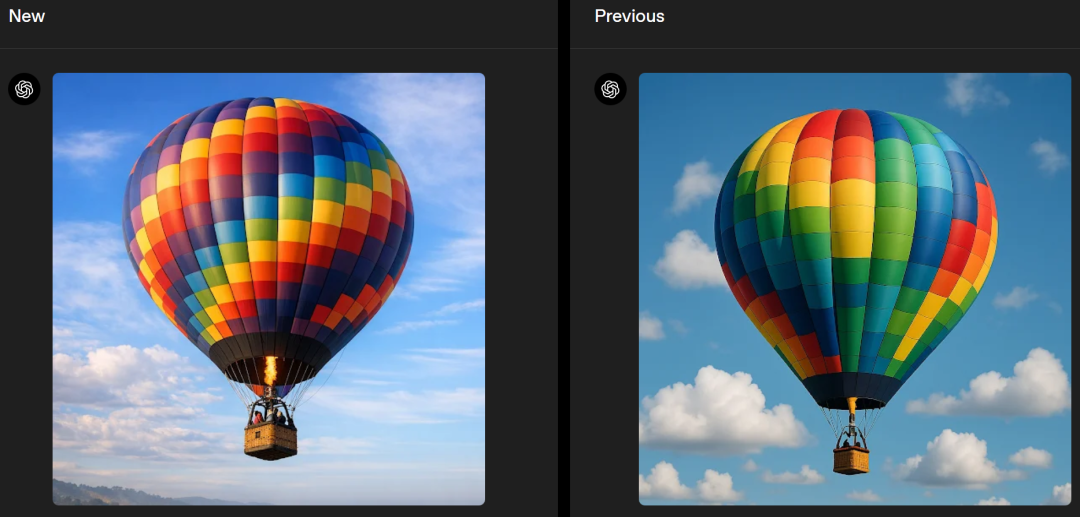
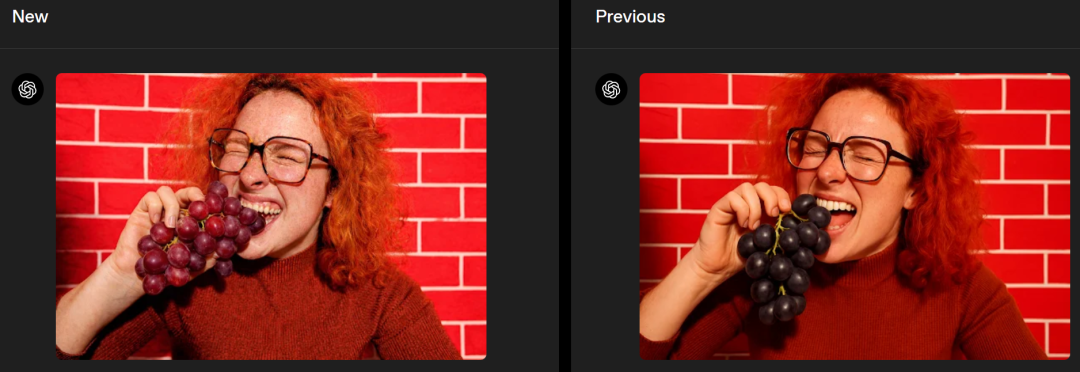
左右滑动查看

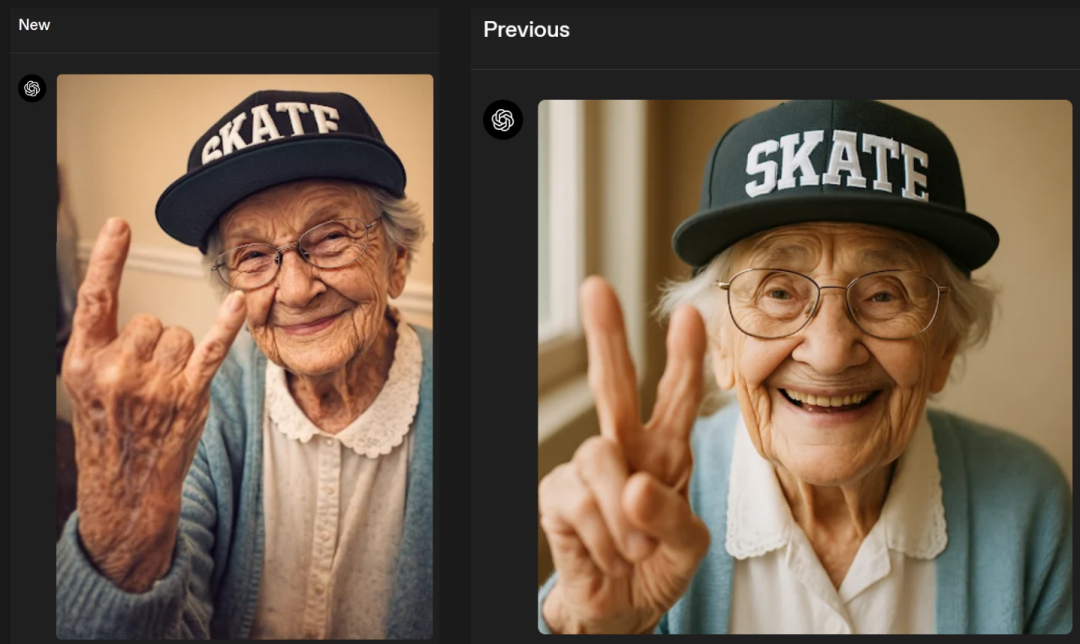
十、奥特曼亲手拉响紧急警报
这次更新,也是对谷歌的强势回击。
就在上个月,因谷歌Gemini抢占市场份额,奥特曼紧急拉响「红色警报」(code red)。
但时,谷歌刚刚发布了新旗舰模型Gemini 3和图像生成工具Nano Banana Pro,后者更是在多个基准测试中登顶LMArena排行榜。
面对谷歌步步紧逼,OpenAI迅速加速节奏:大约5天前,发布了GPT-5.2;现在,又推出升级版图像模型。
OpenAI的这波更新,显然是直面谷歌Nano Banana Pro的挑战——后者在开发者中口碑极佳。
而OpenAI面对的对手,还远不止谷歌。

今年8月,Qwen-Image就已支持中英文可读文字生成;Black Forest Labs也发布了开源图像模型Flux.2,实力不俗。
这场AI图像模型之争,显然已经进入白热化阶段,目标很明确:赢得企业市场。
奥特曼强调了新模型诸多提升和新的编辑功能。
作为OpenAI的应用CEO,Fidji Simo则暗中对标谷歌Nano Banana Pro,直言这次是从单一文本转向动态AI体验。

她认为,通过ChatGPT Images及更多功能,缩短「所思」与「所得」之间的距离。
人类的思维,远不止于文字。事实上,那些最扣人心弦的灵感,往往最初只是脑海中的一幅画面、一段旋律、一个动作或一种模式。如果AI想助我们要释放全部潜能,它就必须用我们习惯的方式——去理解、去表达、去沟通。
Fidji Simo透露,除了图像生成器,OpenAI还在全面升级ChatGPT的视觉体验:
过去几个月里,我一直在谈论 ChatGPT 的进化方向:它正从一个被动的、基于文本的产品,蜕变为一个更直观、更能与你想要完成的任务紧密相连的智能助手。
从纯文本向多模态和动态 UI(用户界面)的转变,正是这一变革的关键一环,能看到这些进展,我倍感兴奋。
Fidji Simo透露,未来用户在搜索问题时,将能看到更多可视化信息和清晰来源。例如换算单位、查比赛比分等场景,图示比文字更直观。
但体验过GPT Image 1.5和Nano Banana Pro的网友,直言这次OpenAI「黔驴技穷」:
一张用青蛙头恶搞奥特曼的梗图,开始流传:

悲伤蛙或佩佩蛙(左),整体上高度模仿OpenAI的预热图(右)——相同的背景,相同的文字,相同的眼神,类似的服饰
这确实有些在内涵奥特曼了。
但最狠的评论,当属网友在OpenAI推文下直接「打脸」:
OpenAI彻底完了。

在相同提示词下,与GPT Image 1.5相比**,**Nano Banana生成的图像更加逼真自然,在电商创意素材上极为有利。
下图中,上两张为GPT Image 1.5生成,下两张为Nano Banana Pro生成。


提示词:53岁白人德国男性在卧室中,典型的意大利风格卧室,架子上堆着箱子和书籍,背景处有一张书桌,上面摆着 iMac 和散落各处的纸张,身穿灰色连帽衫(带简约 logo),戴着婚戒,手腕上有一条低调的红色手链,直视镜头,自然随拍的用户原创内容风格
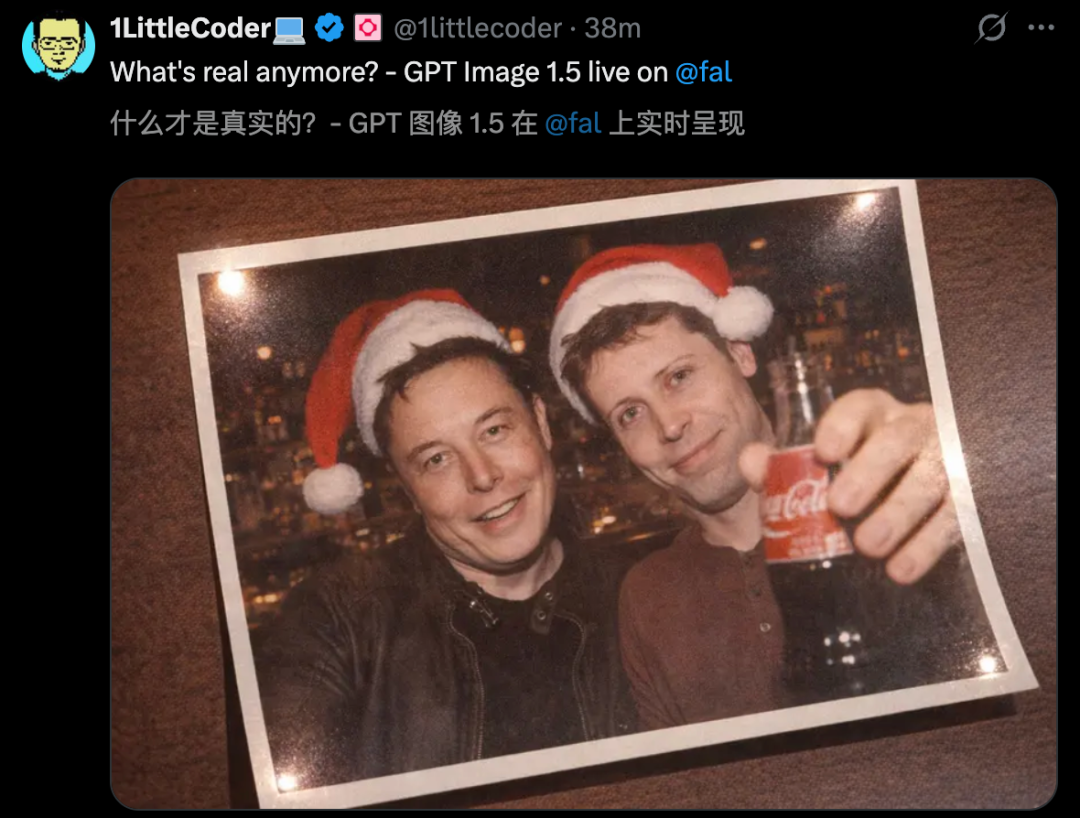
不过,也有网友表示,GPT Image 1.5生成的「马斯克和奥特曼圣诞合影」,逼真到完全看不出一丝破绽。
考虑到Gemini 3.0 Flash马上要来了,新的Nano Banana图像生成功能或许速度更快、价格更便宜,不知道OpenAI这次的Image 1.5是不是「徒劳的挣扎」。
可以肯定的是,OpenAI的紧急警报,一时停不下来。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









