






重要概念
事务的ACID
- 原子性(Atomicity):即不可分割性,事务中的操作要么全不做,要么全做
- 一致性(Consistency):一个事务在执行前后,数据库都必须处于正确的状态,满足完整性约束
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行
- 持久性(Durability):事务处理完成后,对数据的修改就是永久的,即便系统故障也不会丢失
脏读、幻读、不可重复读
- 脏读,读取了未提交的数据
- 不可重复读,事务A期间读取多次b,b被其他事务影响,导致值不可重复
- 幻读,幻读和不可重复读有点像,它是事务A期间统计多次同一批数据,统计结果不一样。原因是被其他事务影响。它们的区别主要在于前者读取精确的某几条数据,后者则是范围统计——多版本不好控制
主从复制的原理
- 主数据库有个bin log记录了所有sql语句
- 把主数据库的bin log的语句复制到从数据库
- 从数据库在relay log重做日志中再执行一遍这些sql
具体而言,
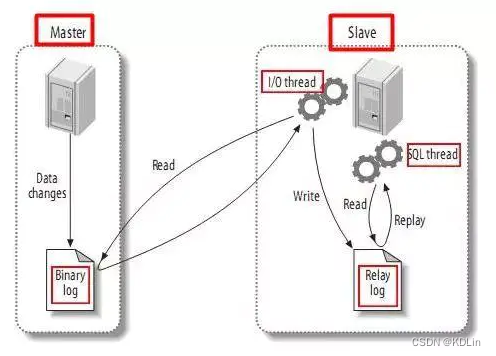
- 主数据库启用输出线程,输出bin log
- 从数据库IO线程,负责从主数据库里拉取bin log,写入到relay log
- sql线程,将relay log重做
三大日志
bin log、redo log和undo log
bin log是归档日志,用于主从复制、数据备份等。
redo log是重做日志,用于实现事务持久性。在事务在提交时断电重启后,可以正常从中恢复。
undo log为回滚日志,用于实现事务的原子性,即当事务失败时,可以全部操作都取消。
bin log和undo log都是MySQL里边服务层的概念,它记录的是逻辑记录,例如完成了什么SQL。而redo log是存储层的物理操作日志,例如“在某个数据页上做了更改”。
在执行更新语句过程,会记录 redo log 与 binlog 两块日志,以基本的事务为单位,redo log 在事务执行过程中可以不断写入,而 binlog 只有在提交事务时才写入,所以 redo log 与 binlog 的写入时机不一样。
buffer与同步
既然是日志,那就躲不开缓存和落盘策略,这当然也是很通用的一些解决实践。这里以redo log为例:
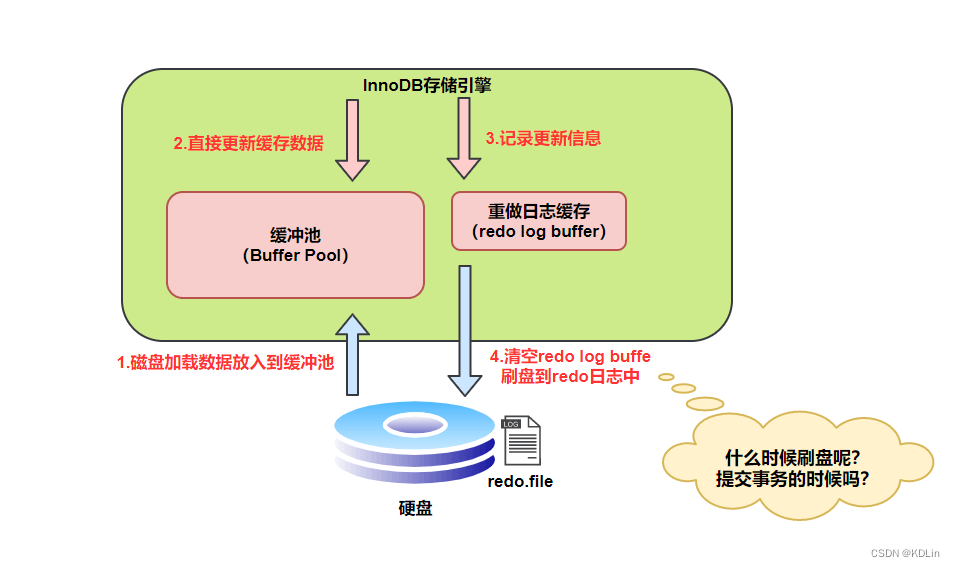
落盘时机,可以通过配置来指定:
- 0,事务提交不落盘,根据异步同步线程的时间来定(通常是1s)
- 1,每次事务提交都落盘
- 2,写入pagecache,介于0和1之间
日志提交的事务
在进行数据库操作的时候,需要同时操作多个日志,这个时候如何保证事务性呢?例如,宕机之后,如何确保binlog和redo log的数据是一致的?
这和[[分布式事务]]做的事情基本是一样的。MySql中采用两阶段进行日志的事务提交。
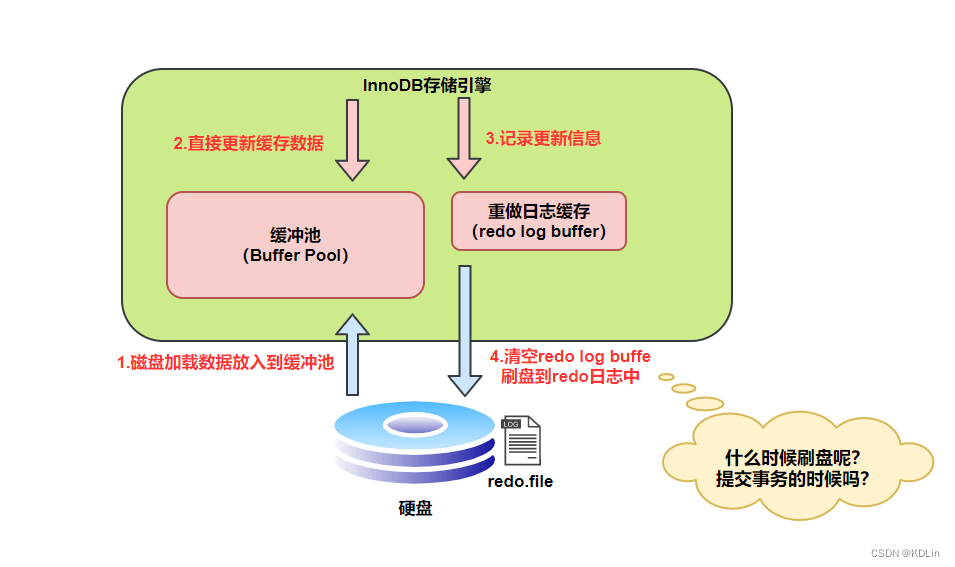
将redo log拆成两个阶段,最终提交阶段在binlog完成之后再提交。故障恢复的时候,不管在什么阶段,一切认准binlog的提交记录。即使在redolog commit期间出错,那么只要binlog落库成功,说明redolog一定parepare完成,可以恢复提交。
这又侧面印证了一个想法:分布式事务,其实本质上是把一件很大的、多阶段的过程,拆解,细分,尽可能把最终这个影响数据一致的过程缩小到最小粒度,尽管无法完全消除,尽可能减少出错的可能性。例如上述例子,就是把耗时的redolog写入过程拆出去,缩小到最终redo log的提交这个更短、更细粒度的过程上。
MVCC如何实现
copy on write
MVCC其实体现的是copy on write的一种思想——追求数据不变性,那么就直接复制一份快照。
数据库这么大的数据量,当然不可能是真的复制一整个库、一整个表,只需要复制相应的行就可以了。那么MySQL到底是怎么实现的呢?
这是必然是一个非常复杂的机制,涉及到并发SQL复杂操作、多版本数据、各个事务之间实时的可见性管控。
核心的有两点:
数据库通过两个核心隐藏列来完成多版本记录:
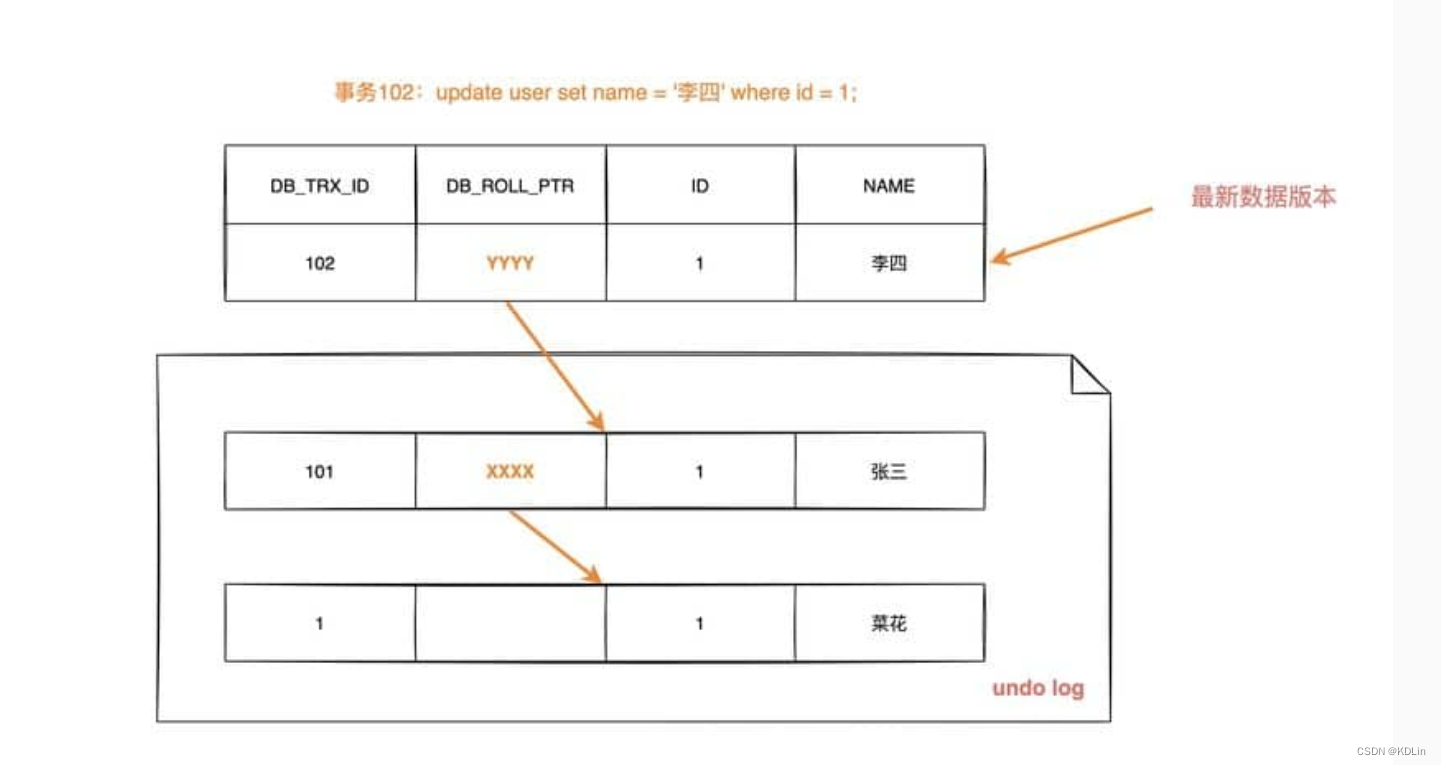
- DB_TRX_ID,当前事务ID。单调递增,因而可以通过大小确定当前事务和其他事务的可见性——对比事务ID大小即可。例如,事务ID小于它的就可见,大于它的就不可见。你可以理解,这个就是版本。
- DB_ROLL_PTR。回滚指针,指向对应的redo log记录。上边记录了“版本号”,那么,我们就会好奇,copy on write中的精髓,copy又是怎么体现的呢?答案就是,通过回滚指针。它不会直接复制一行出来,而会在原行上边修改,如果需要找到上一个版本,就通过回滚指针找到redo log,从而找到上一个版本。
从插入和更新来分析实际分析一下:
insert,由于是新增数据,所以不需要redo log指针,只需要记录事务id。

update,更上边分析一样,除了记录事务ID还得记录回滚指针。
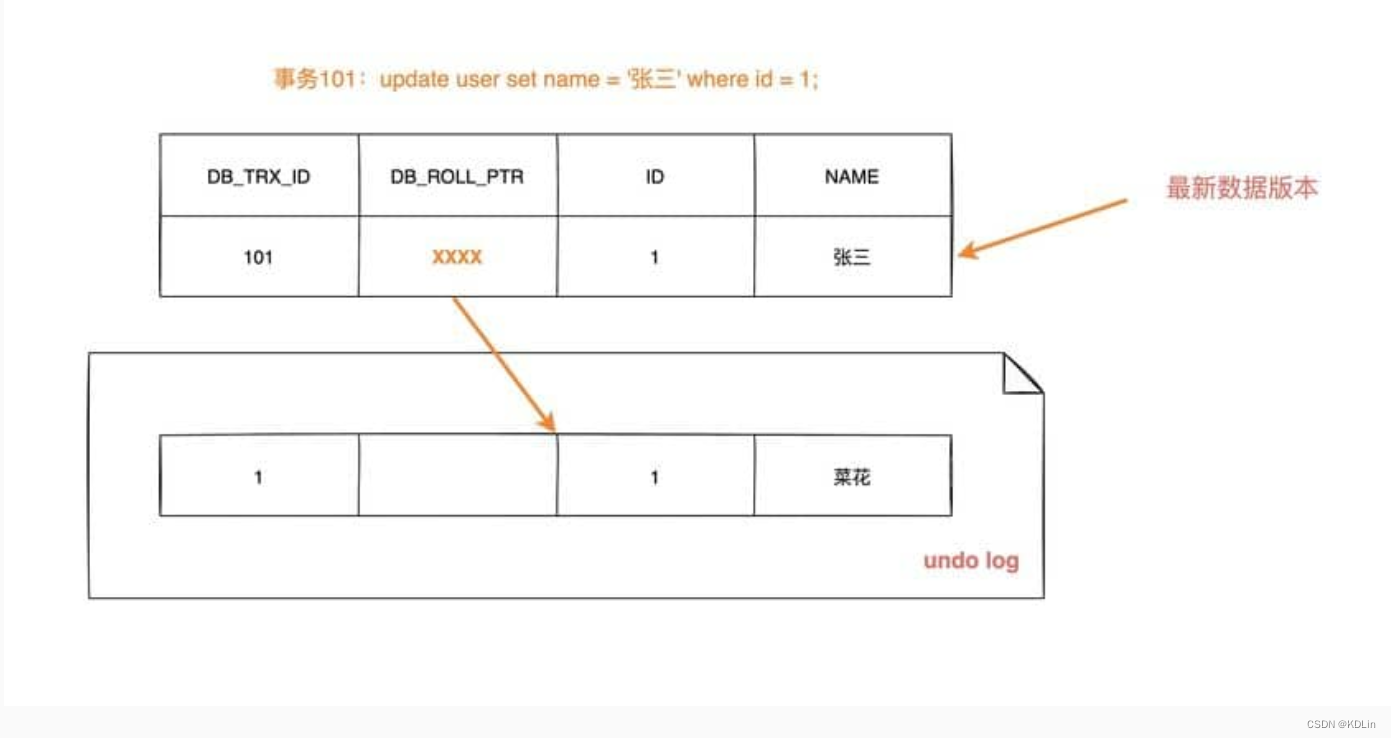
第二次修改,这里重点来了,多版本如何copy呢?答案是拉链:
可见性保证
事务之间可见性的如何保证,这个也是一大难题。
大致描述一下我的理解:MySQL在开启事务的时候,会收集当前活跃的事务列表,于是它就可以通过事务ID,加上上边的多版本数据,去分析当前存在的数据变更,自己可见的是哪些,不可见的是哪些。
下边是当前可视视图的声明。
class ReadView {
private:
trx_id_t m_low_limit_id; /* 目前出现最大的事务ID,大于等于这个 ID 的事务均不可见 */
trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
m_closed; /* 标记 Read View 是否 close */
}
处于最大、最小ID之间的,就是活跃但不可见的事务列表。

事务的实现
好了,这下我们有充足的知识可以来讨论如何实现事务了。
整体方案
- 原子性,undo log,事务中断恢复
- 持久性,redo log,同步写回磁盘,提交断电时可恢复
- 隔离性,通过读写锁和MVCC来实现的
- 一致性,通过上述三者来实现的。
隔离性,对应四种隔离级别
READ UNCOMMITTED
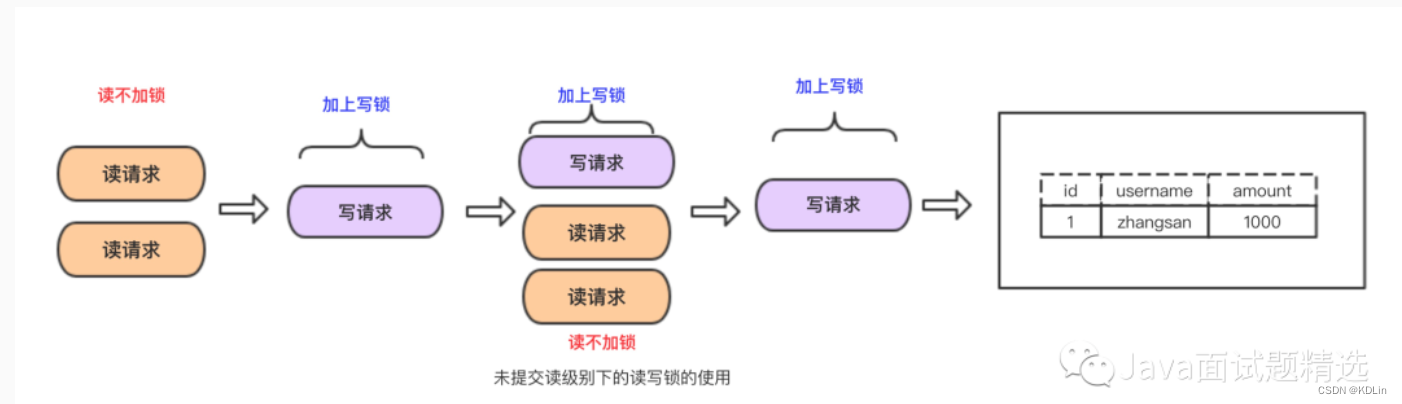
读不加锁,不排斥写。
- 优点:读写并行,性能高
- 缺点:造成脏读
READ COMITTED
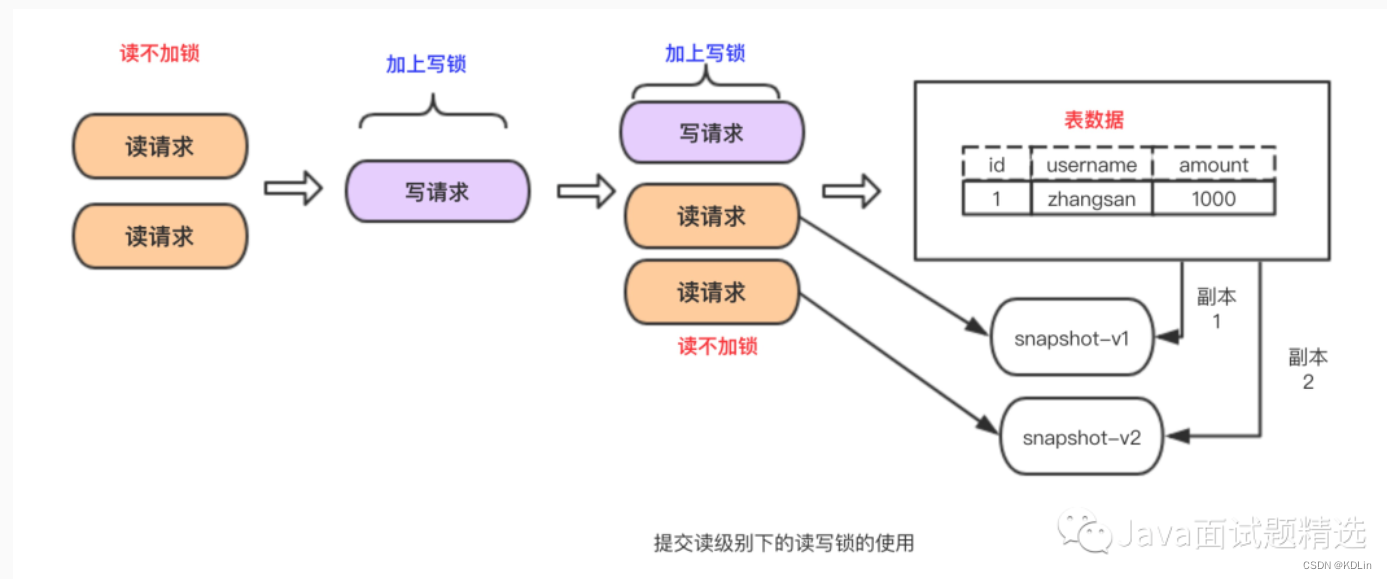
读不加锁,读写分离。但这里MVCC的方式,是每次读的时候,都会读取不同版本,这会造成不可重复读问题。
当然,也有幻读问题。
REPEATABLE READ(Mysql默认隔离级别)
最简单的方式,读写锁实现,让读写串行:
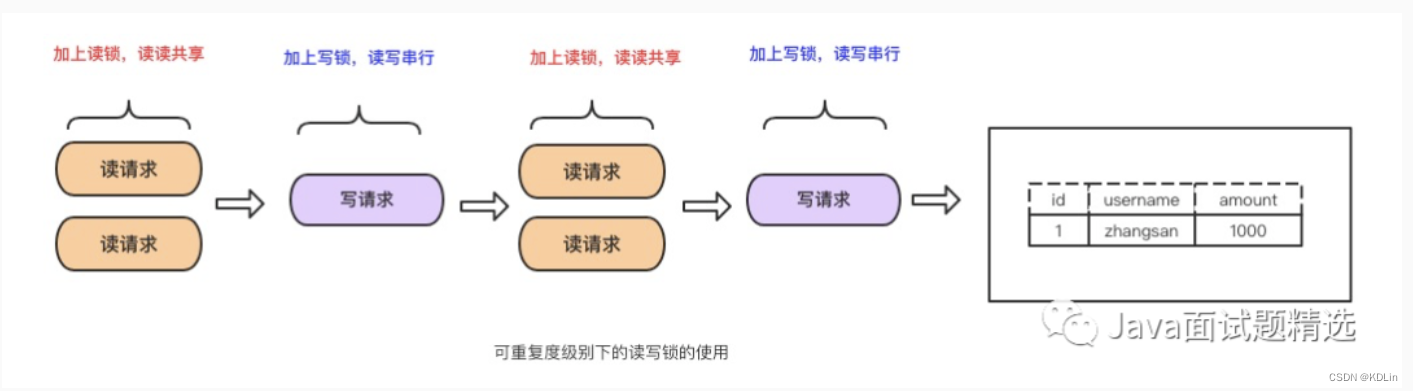
- 优点:实现起来简单
- 缺点:无法做到读写并行
MVCC
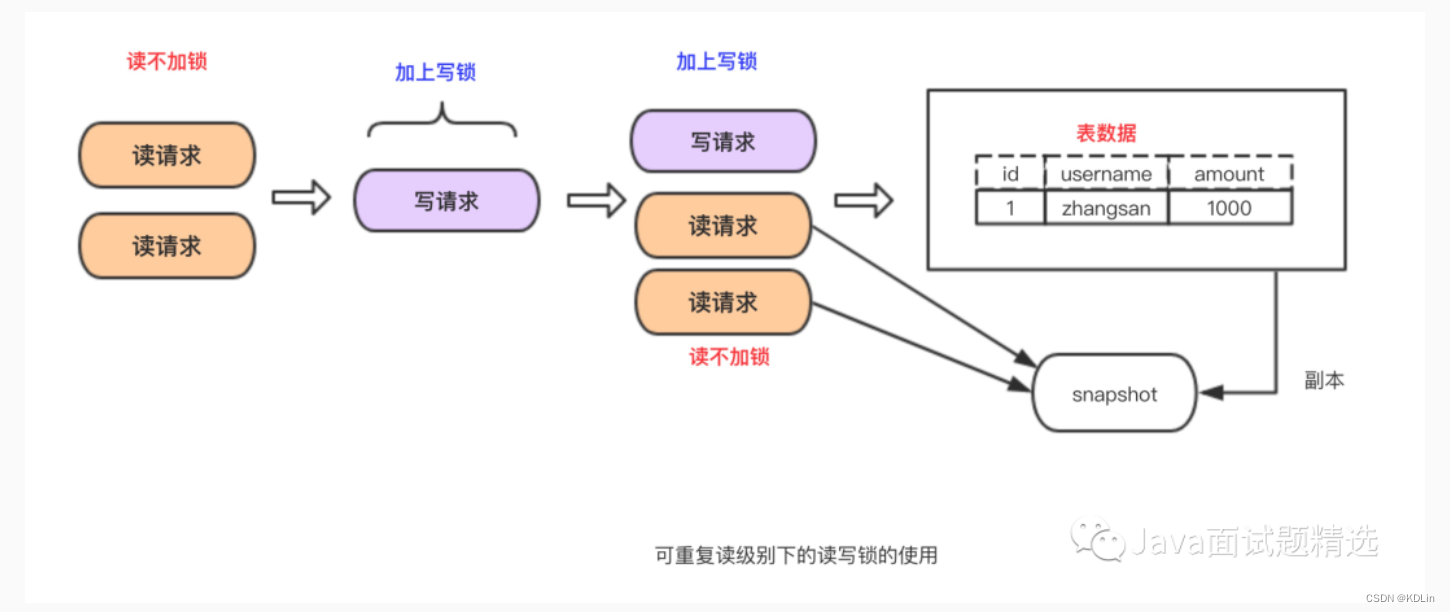
通过版本控制,解决版本不同问题产生不可重复读的问题
- 优点:读写并行
- 缺点:实现的复杂度高,依然存在幻读的问题
InnoDB是可以解决幻读的,大致的思想也很简单, Next-key Lock对查询间隙进行加锁,不让插入自然也就不会有幻读问题。
SERIALIZABLE
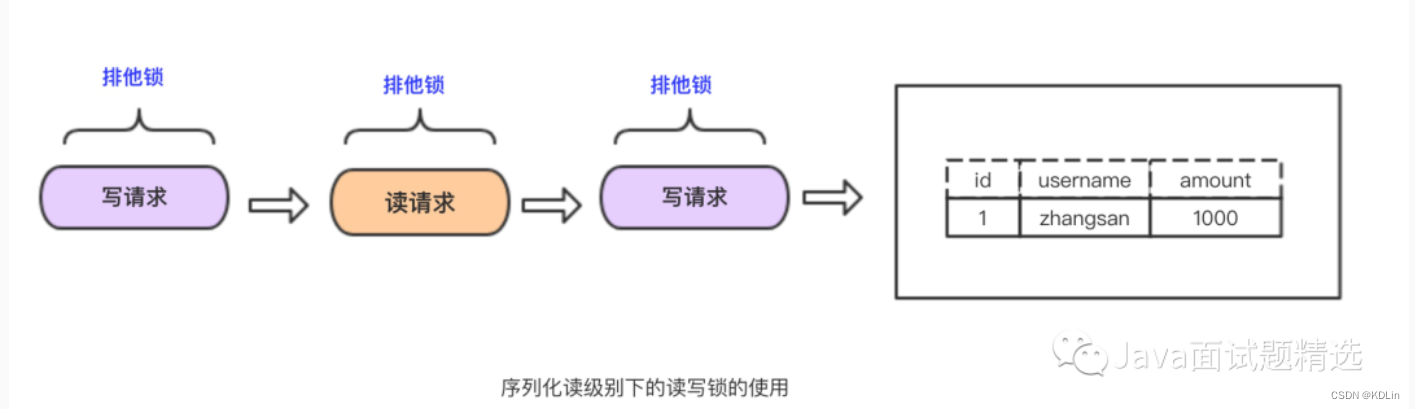
注:
可线性化和可串行化,听起来很像,感觉也很像。其实不太一样,两者是分布式数据库中的一致性模型,但后者主要指事务中的一种隔离级别。
我的理解是,最大的区别在于,可线性化要求对于所有事件,都必须满足所有时刻的先后可见性。而可序列化仅需要保证多个并行的事务和某个事务序列结果一致即可。
这非常像Java中重排和happen-before的理念。
参考
- https://blog.csdn.net/weixin_36380516/article/details/107572412
- https://javaguide.cn/database/mysql/innodb-implementation-of-mvcc.html#readview















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









