







分享
关于Python使用的一些个人分享,
包管理
在日常学习当中,我们完成任务一般只用到特定的库,且使用的Python版本不完全相同(尤其是一些仅存在于Python2.7的包),为了方便管理和打包,
我们可以安装多个版本Python,每个只安装特定模块,
完成特定任务(如机器学习相关算法)使用时在Pycharm中导入对应环境即可。
另外,使用开源环境Anaconda3对于包管理十分有效,十分推荐用于机器学习、数学分析等相关工作。
虚拟环境
在项目开发时,还推荐使用Python的venv,它可以有效和本机的全局Python环境隔离开,每个项目都可以拥有独立的依赖包环境,这样就可以做到互不影响。
# 在Windows环境下
# 创建新的虚拟环境
python3 -m venv new_environment_path
# 激活虚拟环境
cd new_environment_path
./Scripts/activate
# 推出虚拟环境
deactivate
# 包安装可以使用PIP或requirements.txt安装
在Pycharm当中,也可以基于所选版本环境,方便的创建虚拟环境,
自动求导机制
autograd包为张量上的所有操作提供了自动求导机制,可以做到在运行中确定反向传播。
在Pytorch中每个变量都存在两个属性,requires_grad和volatile.如果requires_grad为True,将会自动追踪对张量的操作,完成操作后,可以使用.backward()自动计算所有梯度。
import torch
from torch.autograd import Variable
x = Variable(torch.Tensor([2]), requires_grad=True)
y = x + 1
z = y ** 2
# 使用自动求导
z.backward()
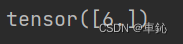
print(x.grad)
该函数求导为2x+2,2处的导数为6。
反向传播
在学习中使用了博主Joker-Tong的问题和代码:
问题简述:已知学习时间x与分数y的三组数据,推断x=4时的y值
import torch
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 设置权重W
w = torch.tensor([1.0]) # 假设 w = 1.0的情况
w.requires_grad = True
def forward(x): # y^ = wx
return x * w # w是tensor 所以 这个乘法自动转换为tensor数乘 , x被转化成tensor 这里构建了一个计算图
def loss(x, y): # 计算单个的误差 : 损失
'''
每调用一次loss函数,计算图自动构建一次
:param x:
:param y:
:return:
'''
y_pred = forward(x)
return (y_pred - y) ** 2
eli = []
lli = []
print('predict (before training)', 4, forward(4).item())
for epoch in range(100): # 每轮输出 w的值和损失 loss
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward() # 自动求梯度
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 权重的数值更新,纯数值的修改 如果不用.data会新建计算图
# 如果这里想求平均值 其中的累加操作 要写成sum += l.item()
w.grad.data.zero_() # 清空权重里梯度的数据,不然梯度会累加
eli.append(epoch)
lli.append(l.item())
print('progress:', epoch + 1, l.item())
print('Predict (after training)', 4, forward(4).item())
# 绘制函数
plt.plot(eli, lli)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
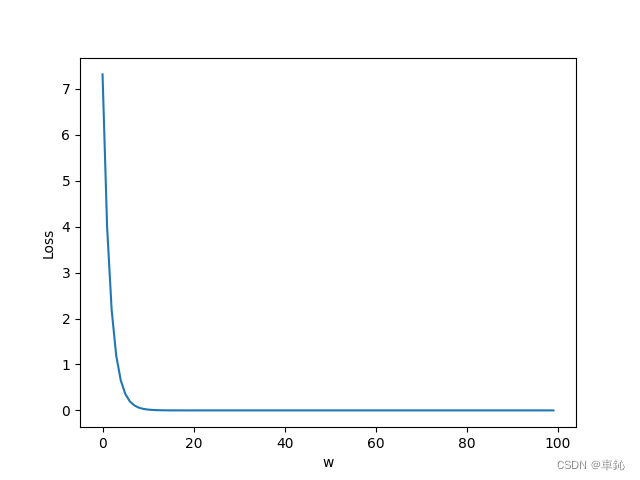
Loss变化图
轮次1:
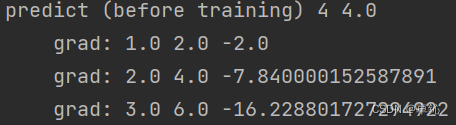
轮次10:
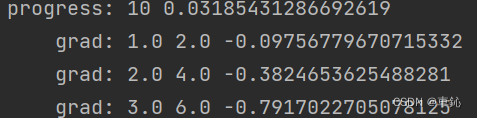
最后轮次与预测结果:
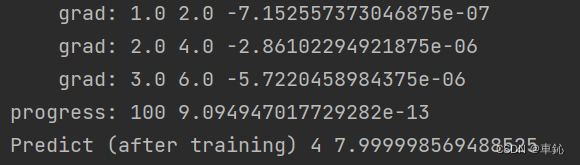
到第100轮次时,根据w预测的结果数值逼近8,相当接近假设为线性函数的取值。
附参考文章:
pytorch(三) Back Propagation 反向传播 (附详细代码+图解计算图)_Joker-Tong的博客-CSDN博客_pytorch反向传播代码@Joker-Tong














 4706
4706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









