



虽然大多数eBPF程序都能采集和传输内核事件数据,但在实际应用中,kprobes、fprobes和tracepoints因其精准的事件挂钩能力和丰富的数据获取能力,成为性能监控和系统调用跟踪的首选方案。
这些工具虽然功能存在交叉,但各有侧重:kprobes/fprobes适合动态内核函数级深度分析,而tracepoints则以其稳定性更适合生产环境监控。本文将深入解析它们的适用场景,帮助您做出最优选择。
Tracepoint(跟踪点)
Tracepoint 是 Linux 内核中预定义的钩子点,eBPF 程序可以挂载到这些 tracepoint 上,在内核执行到这些点时运行自定义逻辑。
例如,sys_enter_execve tracepoint 捕获 execve 系统调用的进入点,提供执行程序和其参数的信息,可用于安全审计或用户行为分析。
你可以通过以下命令查看所有可用于 eBPF tracepoint 的事件:
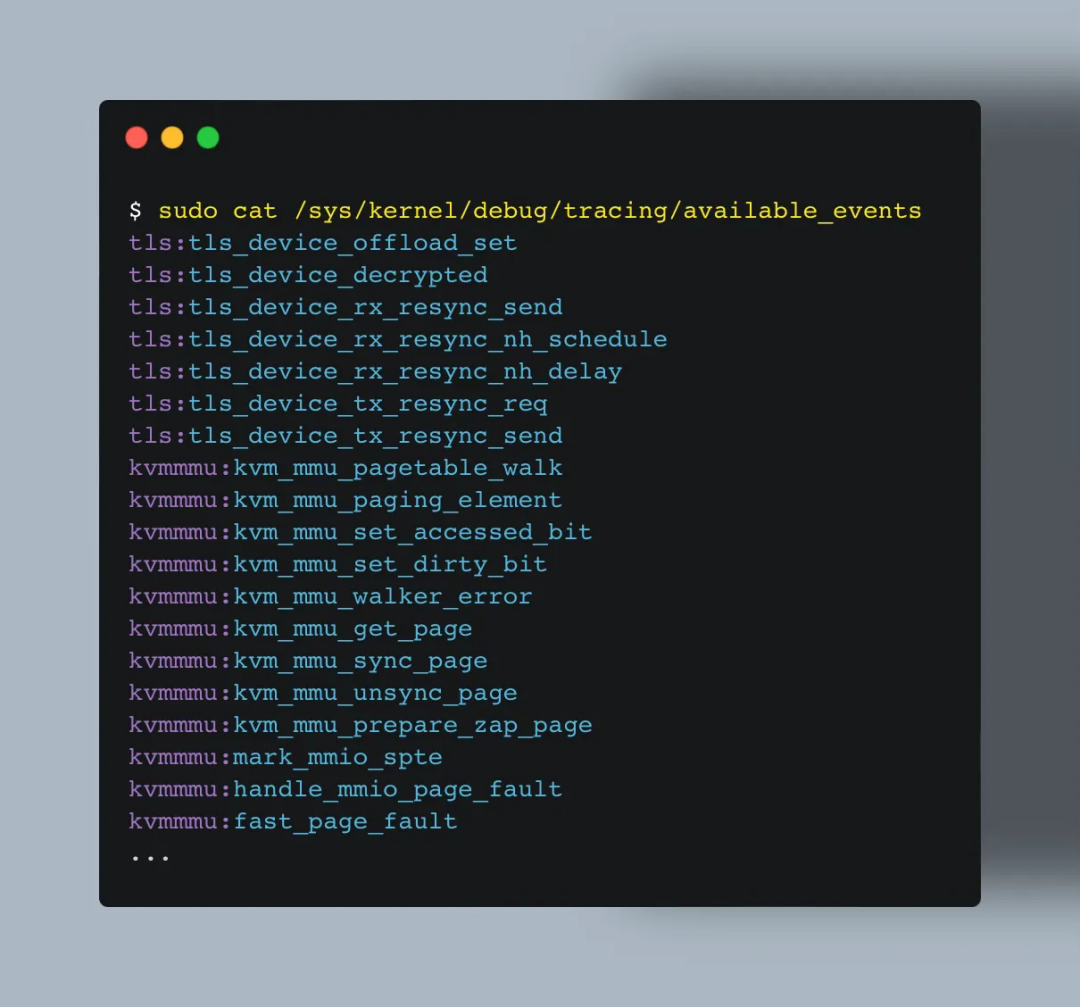
输出格式为 <类别>:<名称>。
你可以通过查看 /sys/kernel/debug/tracing/events///format 来查看 tracepoint 的输入参数。
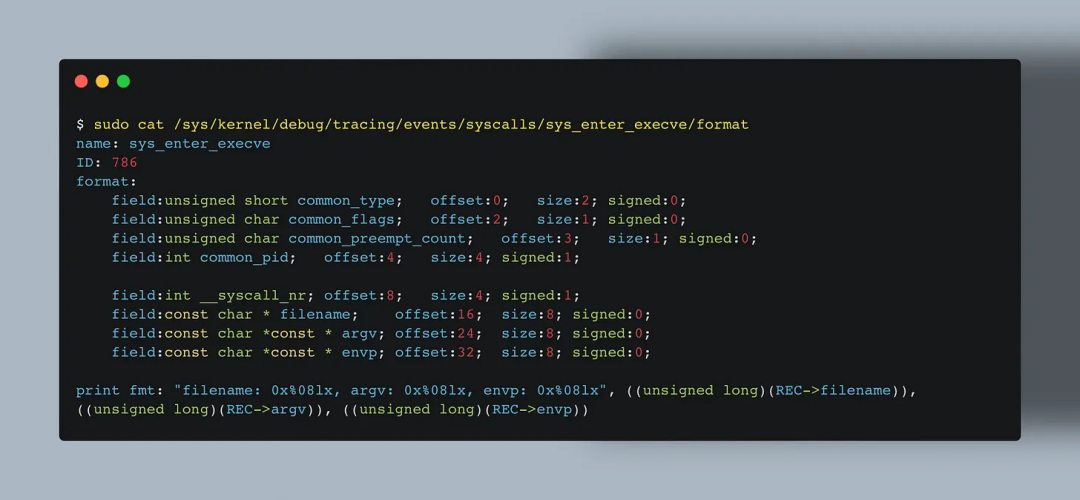
由于早期架构设计限制,eBPF程序无法直接访问前四个系统调用参数。
不过,其他字段通常可以通过 eBPF 程序访问,例如 format 文件中 print fmt 行展示的内容。
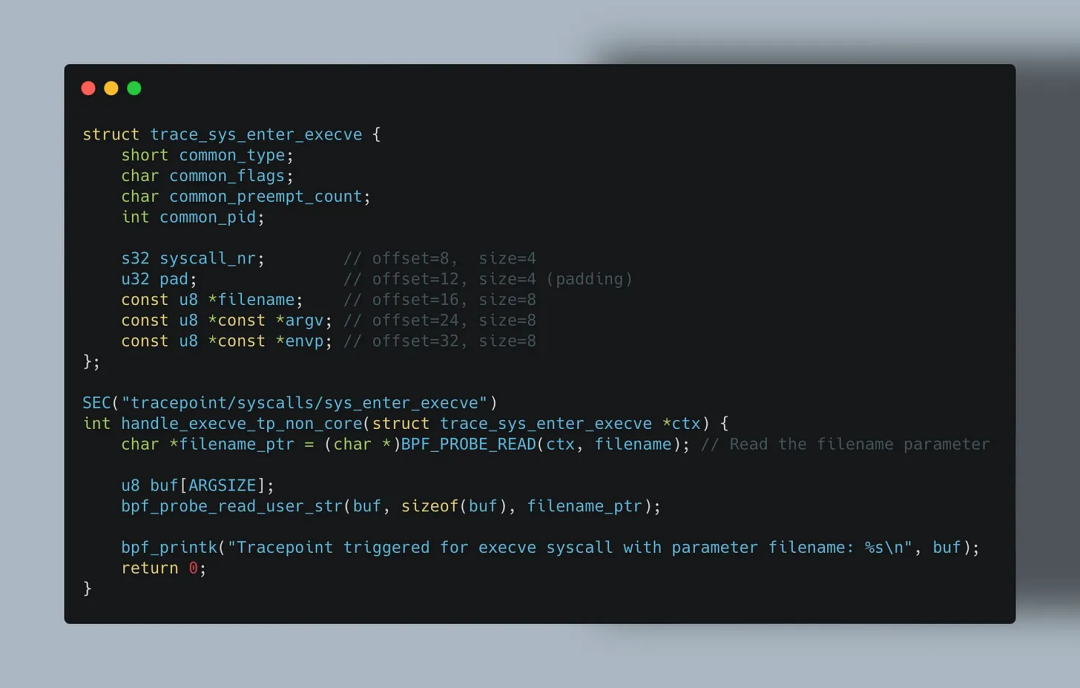
💡 SEC("tp/xx/yy") 和 SEC("tracepoint/xx/yy") 是等价的,可以根据个人喜好选择。
缺点:
-
Tracepoint 只能存在于内核开发者事先定义的地方,如果你需要跟踪未支持的内容,就需要换种方式。
-
Tracepoint 受内核版本影响,使用前需要确认是否存在。
不过,tracepoint 在不同内核版本中通常比较稳定,如有变动,可使用 BPF_CORE_READ() 这类 CO-RE 工具实现可移植读取。
此外,需要确保程序加载时使用的输入上下文在目标内核中存在。例如,自定义的 trace_sys_enter_execve 结构体可能没有对应的 BTF 类型,导致 CO-RE 无法自动定位变量偏移。
因此应使用 vmlinux.h 中定义的 struct trace_event_raw_sys_enter。
💡 vmlinux.h 是内核头文件,为 eBPF 提供结构定义:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Raw Tracepoint(原始跟踪点)
Raw Tracepoint 与常规 Tracepoint 看起来类似,也可挂接到 /sys/kernel/debug/tracing/available_events 中列出的事件。
但主要区别在于 Raw Tracepoint 不传递参数上下文,而是通过 struct bpf_raw_tracepoint_args 提供事件的原始参数。
因此,Raw Tracepoint 相较于常规 Tracepoint 性能稍好。
另一个显著区别:内核中并没有对每个系统调用都静态定义 tracepoint,而是只对通用的 sys_enter/sys_exit 提供支持。
💡 sys_enter 在所有系统调用进入时触发,sys_exit 在其返回时触发,可获取返回值。
因此,若想跟踪特定系统调用,必须在 Raw Tracepoint 中通过 syscall ID 做“过滤”。
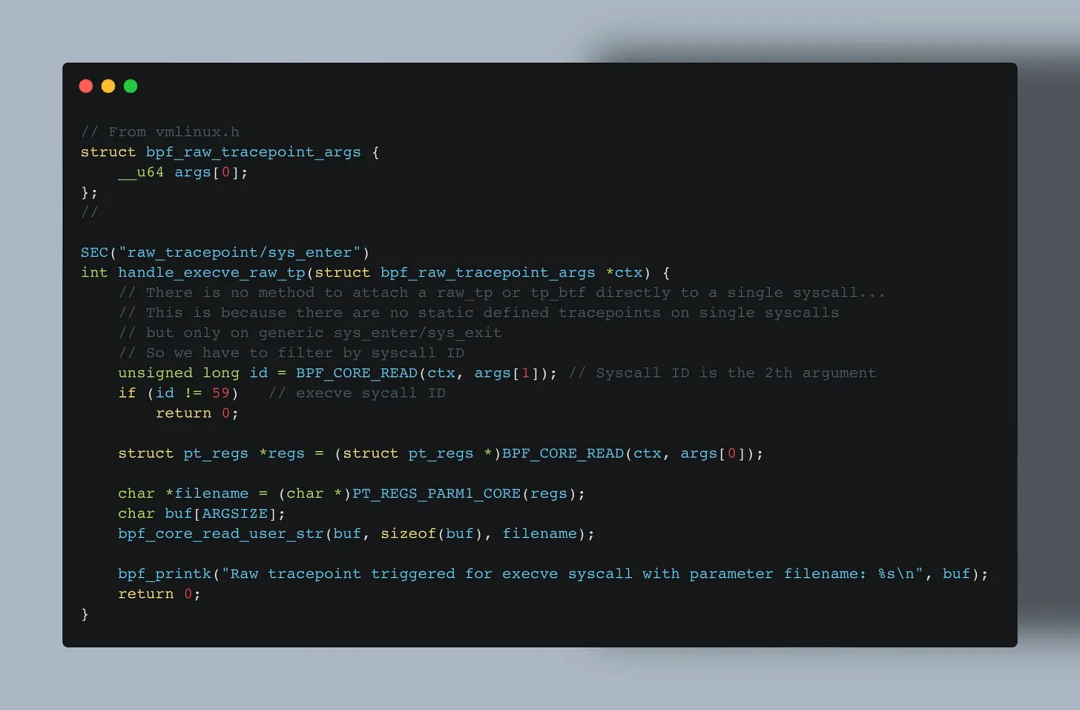
这与 Tracepoint 通过 perf 事件直接挂接特定事件(如 tp/syscalls/sys_enter_execve)不同。
💡 Perf 事件是 Linux 内核的一项功能,用于捕获硬件事件、软件事件和 tracepoints。
此外,读取系统调用参数需要从 CPU 寄存器中提取。System V ABI 指定了参数应存在哪些寄存器中。
由于依赖寄存器,因此需要为特定架构编译程序,例如使用 clang 的 --target 标志。
Kernel Probe(kprobe)
虽然 Tracepoint 和 Raw Tracepoint 足以满足许多场景,但它们的限制是只能使用预定义的钩子点。
kprobes 允许动态挂接任何内核函数,包括函数内部的任意位置,而不仅是函数头或返回点。
💡 使用 notrace 标记的函数不能被 kprobes 跟踪。
可以通过 grep 在 /proc/kallsyms 中查找所有内核符号(函数、变量等):
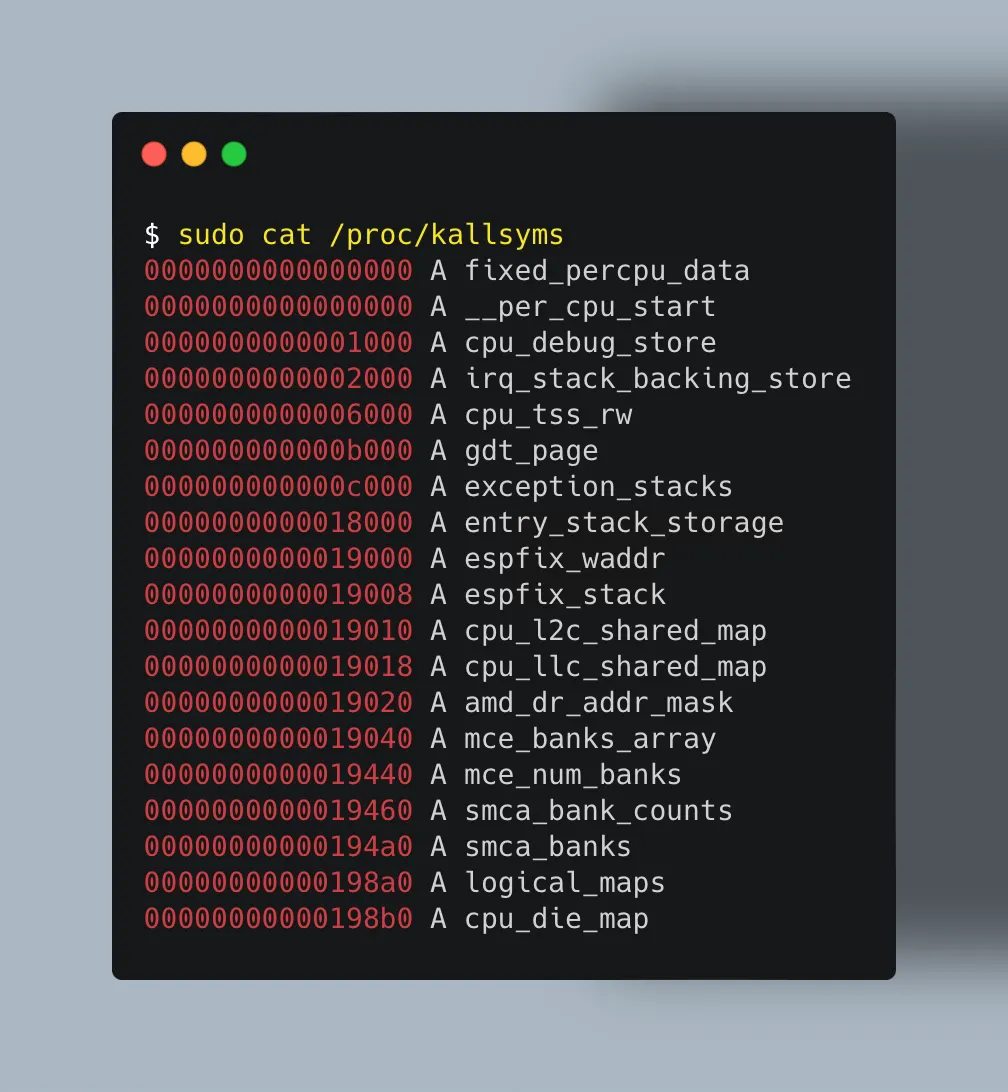
💡 若函数未出现在 kallsyms 中,可能是被编译器内联了,或者在 /sys/kernel/debug/kprobes/blacklist 中被列入黑名单。
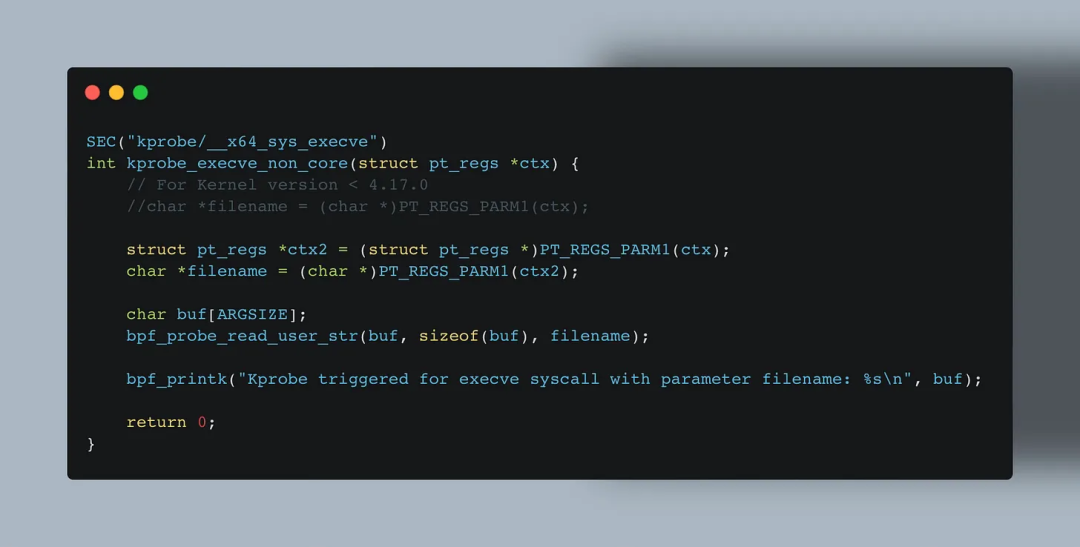
但 kprobes 的问题在于依赖于当前内核代码,缺乏跨版本稳定性。函数在不同内核版本中可能被重命名、删除或结构体字段被更改。
相比之下,Tracepoint 输入参数变化不大,因此不使用 BPF_CORE_READ() 也可正常运行。但若想写出可移植的 kprobes 程序,则必须使用 CO-RE 工具族。
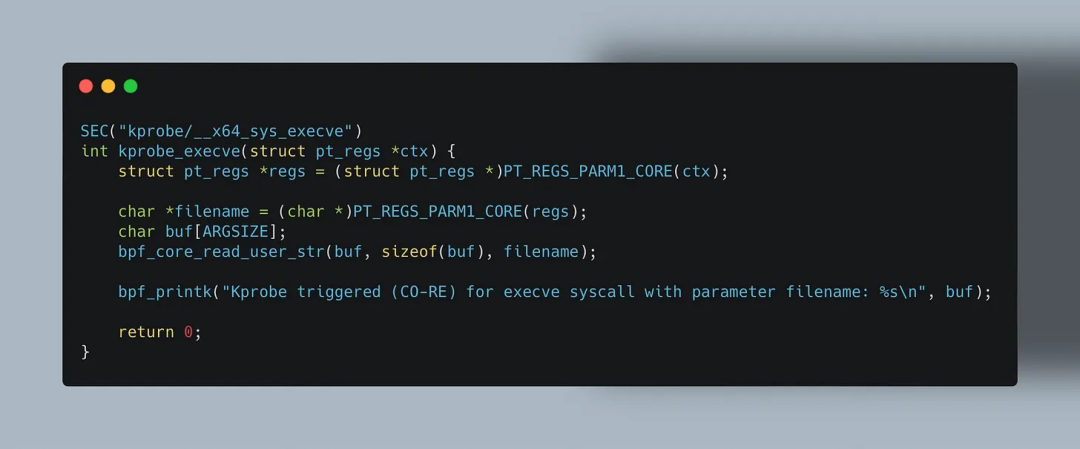
kretprobes(kprobe 的返回点变体)同样存在上述问题。
支持 BTF 的 Raw Tracepoint
令人意外的是,有时候我们不需要使用 BPF_CORE_READ() 这类辅助函数来实现 CO-RE 可重定位读取。
在某些 BTF 启用的 eBPF 程序类型中,可以直接访问内核内存,也就是说可以直接读取输入上下文参数。
支持这种直接访问的程序类型包括:BTF-enabled 的 Raw Tracepoint 和 Fprobes。
使用这些程序时,eBPF 可以直接从内核中读取参数,无需使用 BPF_CORE_READ() 或 BPF_PROBE_READ()。
这类程序接收的是一个 u64 数组,表示被跟踪函数的参数。
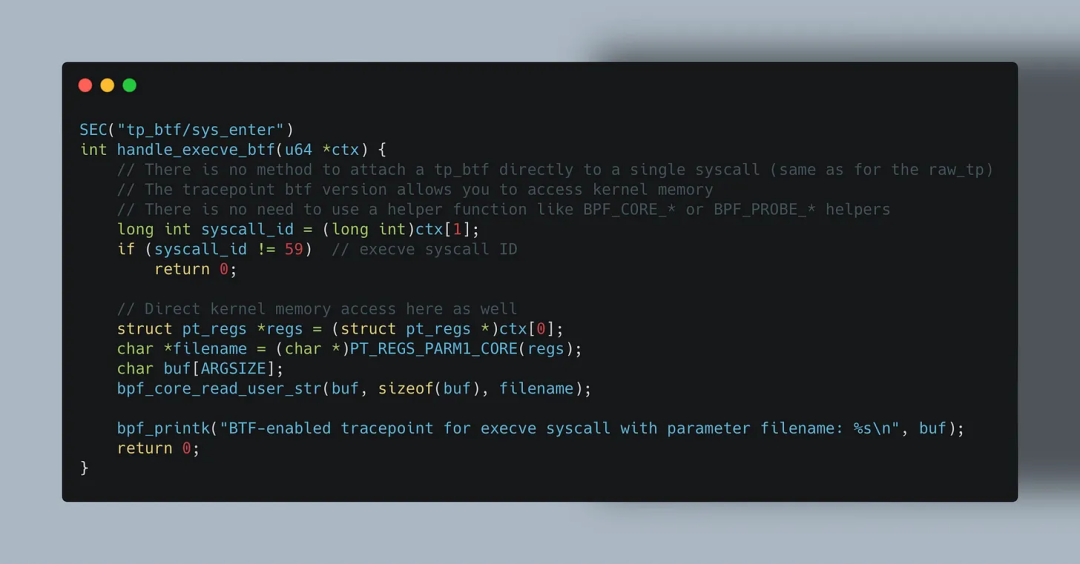
这使得 BTF-enabled Tracepoint 相较于普通的 Tracepoint 或 Raw Tracepoint 更易于开发。
Fprobes(fentry/fexit)
正如上文所述,fprobes 也启用了 BTF,允许直接访问传入函数的参数,这些参数以 u64 数组的形式提供。
你可以将 fprobes 视为“支持 CO-RE 的 kprobes”,尽管严格来说并不完全正确。之所以这么说,是因为 fprobes 能像我们在 tp_btf tracepoint 示例中那样使用 BTF,并且几乎可以挂载到任何内核事件。
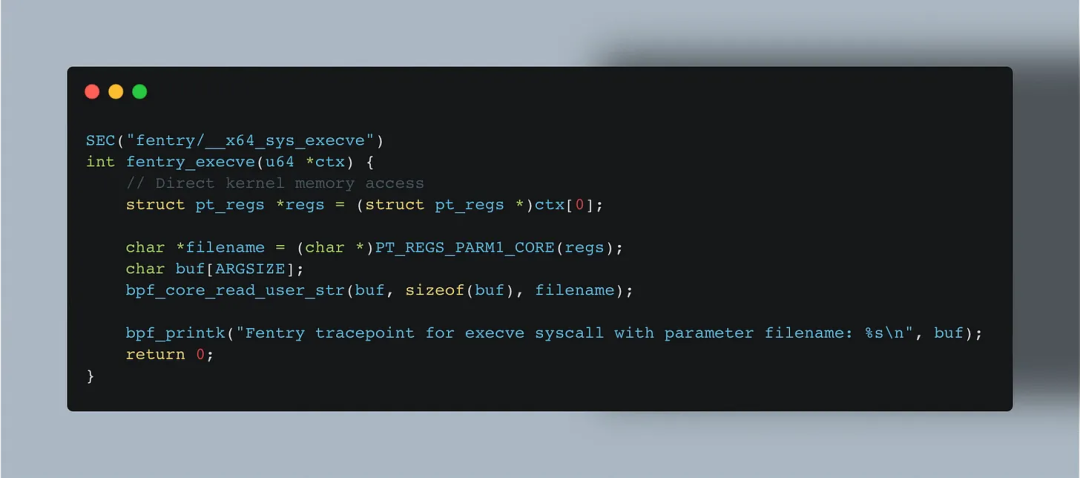
与 kprobes 不同,fprobes 只能挂接在函数入口(fentry)或函数退出点(fexit),这是因为它们的挂接机制(eBPF trampoline)与 kprobes 不同。这种机制使得 fprobes 的挂接和卸载速度更快。
fprobes 程序可以附加到 XDP、TC 或 cGroup 等 BPF 程序上,这使得调试 eBPF 程序更方便。而 kprobes 不支持这种方式。另一个优势是:fexit 钩子可以访问函数的输入参数,而 kretprobe 却不行。
需要注意的是,fprobes 要求至少 5.5 版本的内核。如果你需要兼容较老的内核,这可能是个问题。但除了这一点,fprobes 在大多数方面都优于 kprobes。
💡 在 Linux 内核 5.7 中,引入了另一种 fprobe 程序类型:fmodify_return,它运行在 fentry 执行之后、目标函数真正开始执行之前。
原文地址:https://ebpfchirp.substack.com/p/tracepoints-kprobes-or-fprobes-which
****************************************************************************************************
DBdoctor免*费下载地址:https://www.dbdoctor.cn/?utm=02
点击下方添加小助手微信,官方技术支持服务+加入技术交流群+赠送高阶License


















 4872
4872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









