







Recently, more and more deep learning papers comes out since the big success of deep learning in some traditional computer vision tasks, like object detection, localization and image/scene classification in ImageNet. The success motivates experts in computer vision and natural language processing to apply deep learning techniques in more and more traditional research areas. One of these areas is dense prediction.
Dense prediction refers to per-pixel prediction from one or more input images. If the input is one image, it could be depth map[1][2][3][5][6], surface normal prediction[3][4][6], scene labeling[6] problem. If the input is two or more images, it could be optical flow[7] prediction problem. Actually, since VOC Challenge started the object segmentation competition, a lot of papers in scene labeling have been published, check the leaderboard of object segmentation in their page.
In this paper, I will summarize the methods used in several DL papers in depth map prediction.
Before we introduce these papers, let’s talk about some knowledge of depth map. Estimating depth from a single monocular image is a ill-formed problem, since one captured image corresponds to numerous real world scenes. As you know, for an ill-posed problem, the general solution for it is to enforce some assumptions/limitations. For example, if it’s a depth map, usually it’s smooth, the spatial layout of an indoor/outdoor scene is quite similar with each other. The problem of assumptions is it can only deal with that kind of examples, for a real world scene that changes dramatically or is not the usual indoor/outdoor scene, the method will not work. Another way to deal with this problem is based on some third-party dataset. Say, to infer the depth of an image of indoor scene, we want to retrieve a similar image in a big indoor scene dataset with depth ground truth. It’s based on the idea that scenes with similar semantic appearances should have similar depth estimations. Actually, this is quite like deep learning. Given a new image, how we know its depth is based on the knowledge we learned from priors/dataset.
Because of the ill-posed nature of inferring a depth from a single image, it gives chance for deep learning to flex its muscles. However, this is not enough. Without the tremendous ImageNet, object detection/localization problem won’t be developed so well. There are two indoor (NYUv2) and outdoor (Make3D) depth map benchmark available for deep learning to be trained on. NYUv2 contains 795 images and Make3D contains 534 images.
So first let’s talk about this guy, Chunhua. He published three papers about depth map prediction on top conference/journals in one year. But actually, he proposed two different methods to do that, since [2] comes from [1], their details are quite the same.
In their first work [1], they proposed to formulate the depth estimation as a deep continuous CRF learning problem. The main contribution in this paper is that they incorporated the optimization problem in CRF into the deep learning structure. This idea is so that brilliant I have never seen it before. With this structure, the network will learn an optimization process that is far more smarter than predicting something directly. Also, because of this, the authors didn’t release their codes..
The illustration of their network is as following. The pipeline of this network is like this:
1. Segment the image into multiple superpixels.
2. For each single superpixel, predict the potential term and for every neighbouring superpixel pair, predict the pairwise term.
3. Compute the CRF loss for backpropagation.
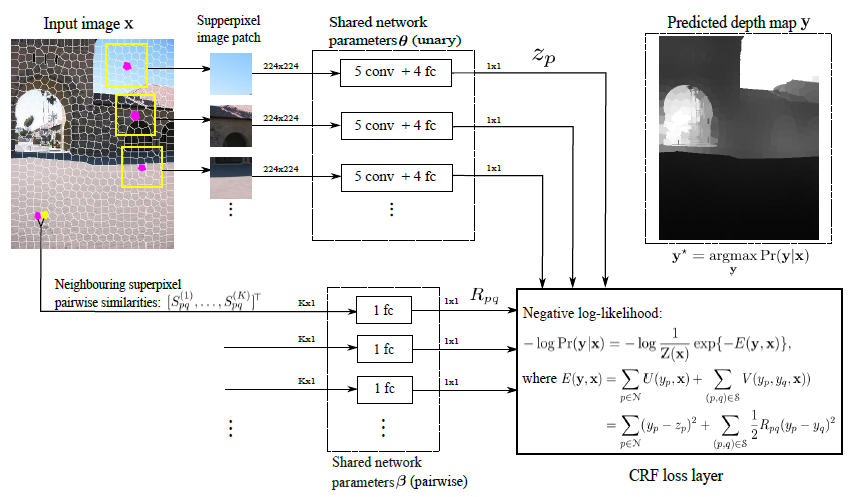
Is this idea similar? Right, you are damn right, this paper just copied the idea in [8] and implement it in DL network! [8] published that paper in CVPR one year before, and [1] got inspired by that one. Check [8] out! But still, even if Chunhua copied their idea, but the implementation of CRF in deep learning is still very cool! (I have no idea how to implement that..)
One more thing you maybe wonder is there are only less than 1000 images for training, will it overfit? Well, that’s a good problem. But since what their network is dealing with is patches around a superpixel, not an image, so I guess that would not be a concern. Check this figure out.
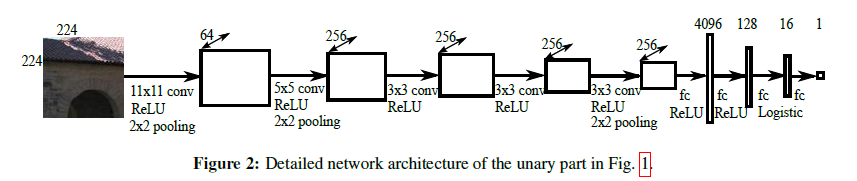
One drawback of the superpixel thing is the result won’t look very smooth, since it’s not a continuous field, it’s a discrete field. I mean their results depends on the superpixel tech very heavily, like this one.

[1] Chunhua Shen, Deep Convolutional Neural Fields for Depth Estimation from a Single Image, CVPR 2015.
[2] Chunhua Shen, Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields, PAMI 2015.
[3] Chunhua Shen, Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs, CVPR 2015
[4] Xiaolong Wang, Designing Deep Networks for Surface Normal Estimation, CVPR 2015.
[5] David Eigen, Depth Map Prediction from a Single Image using a Multi-Scale Deep Network, NIPS 2014.
[6] David Eigen, Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture, ICCV 2015.
[7] Philipp Fischer, FlowNet: Learning Optical Flow with Convolutional Networks, ICCV 2015.
[8] Miaomiao Liu, Discrete-Continuous Depth Estimation from a Single Image, CVPR 2014.
Well, this is my first blog in CSDN, and it’s my first time to write a blog in English, so if you like it, please give a like. I will write more about depth map estimation later, since this one cost me a lot of effort, I need to rest..














 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









