 深入解析Linux基础三件套
深入解析Linux基础三件套





目录
0.写在前面
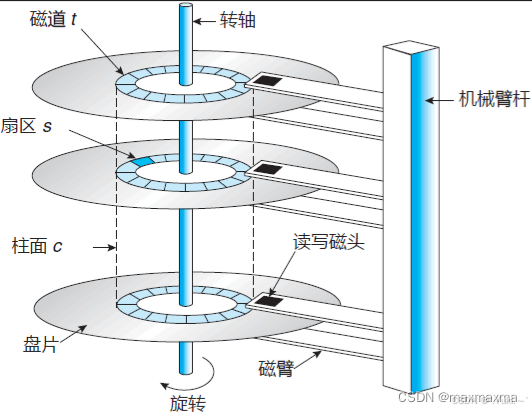
在了解文件系统的内核结构之前,可以补充一点计算机组成原理:关于数据在磁盘上是如何存储的?(以机械硬盘为例!)
数据在计算机中以二进制形式存在(0 和 1)。机械硬盘利用磁性材料的特性,将这两种状态表示为盘片表面上微小区域的不同磁化方向。

主要组成部分:
盘片:通常由铝合金或玻璃制成,表面涂覆一层薄薄的磁性材料(如钴基合金)。数据就存储在这些磁性涂层上。一个硬盘内通常有多个盘片叠放在一起,固定在主轴上同步旋转。
读写磁头:每个盘片的表面(上下两面)都有一个独立的读写磁头。它们安装在磁头臂上,由音圈电机驱动,可以在盘片半径方向快速移动。
关键特性: 磁头在工作时并不接触盘片表面!它们依靠盘片高速旋转产生的空气动力学效应,悬浮在距离盘片表面仅几纳米(现代硬盘大约 0.5 微米或更小)的高度飞行。这个间隙比一粒灰尘还要小得多。
读操作: 磁头感应盘片下方磁性区域产生的微小磁场变化,将其转换为电信号(电流),进而识别为 0 或 1。写操作: 磁头线圈通过电流,产生一个精确的磁场,改变盘片下方磁性区域的磁化方向,从而写入 0 或 1。
主轴电机:驱动盘片高速旋转。常见的转速有 5400 RPM(每分钟转数)、7200 RPM、10000 RPM 甚至 15000 RPM(主要用于企业级硬盘)。转速越快,通常数据传输速度越快。
数据是如何组织和存储的?
磁道:盘片旋转时,磁头悬浮的位置在盘片上画出的一个圆形轨迹称为一个磁道。盘片上有成千上万个同心圆磁道。
扇区:磁道被进一步划分为固定大小的弧段,称为扇区。这是硬盘读写数据的最小物理单元。传统扇区大小是 512 字节,现代硬盘(高级格式化硬盘)通常使用 4096 字节(4K)的扇区以提高效率和纠错能力。每个扇区除了存储用户数据外,还包含地址信息(磁道号、扇区号)和用于错误检测与纠正的校验码。
柱面:所有盘片上相同半径位置的磁道组成一个柱面。想象一下,多个盘片的同一个磁道上下对齐,形成一个圆柱面。磁头臂移动时,所有磁头是一起移动的。因此,访问同一柱面上的不同磁道(即不同盘片)不需要移动磁头臂,速度最快。
簇 / 分配单元:这是操作系统管理文件时使用的最小逻辑存储单元(文件系统层面)。一个簇由一个或多个连续的扇区组成。操作系统读写文件时,以簇为单位进行分配和管理,而不是直接操作单个扇区。
读写数据的过程:
接收指令: 硬盘控制器接收到来自计算机操作系统的读写请求(包括要访问数据的逻辑地址 - LBA)。
地址转换: 控制器将逻辑地址转换为物理地址(柱面号、磁头号、扇区号 - CHS,或直接映射)。
(补充:转换过程可以将整个磁盘看作线性数组,算出LBA逻辑地址的编号对应的具体盘数,磁道,扇区)
移动磁头臂(寻道): 音圈电机驱动磁头臂移动到目标数据所在的柱面位置。这个移动过程所需的时间称为寻道时间,是影响硬盘速度的关键因素之一。
等待旋转(旋转延迟): 磁头到达目标磁道后,需要等待盘片旋转,直到目标扇区转动到磁头正下方。这个等待时间称为旋转延迟。平均旋转延迟是盘片旋转半圈所需的时间~
以上是对磁盘的介绍,有了这些铺垫,来看看文件系统与磁盘管理是如何结合的?
1.文件系统
1. 对磁盘进行分区管理
文件由文件内容以及文件属性组成,但是内容和属性并不储存在一起,并且磁盘上也有寄存器,eg:控制/数据/地址/状态寄存器,磁盘很大,一般分区进行管理:
磁盘都是很大的,500G 的空间如果要全部管理起来会很费劲,但是由于所有的磁盘区域都能够使用同一个管理方法,因此可以对磁盘使用分区管理。
500G 和 100G 的管理方法一样,将 500G 分成 5 个 100G 管理就会轻松很多。如:将一块磁盘分成 C D E F … 盘,管理起来明显会变轻松。

2. 对磁盘分区进行分组管理
管理一块 500G 的磁盘可以复用管理一块 100G 区域的管理方式,这 100G 的空间也可以划分成块组进行管理。不同文件系统有不同的分组方式,此时假设以 2G 为一块组对一个 100G 的磁盘分区划分出 50 个块组。只要能管理好 1 个组,就能管理 50 个块组 (1 个磁盘分区),能管理好 1 个磁盘分区就能管理好整个磁盘!
首先一个磁盘分区可以这样划分:
- Boot Block:Boot Block 属于固件(像主板 BIOS、设备 Bootloader 等里的一段特殊程序 )的一部分,存储着最基础的启动初始化代码,这不是重点,了解即可。
- Block group:需要重点了解的分组:
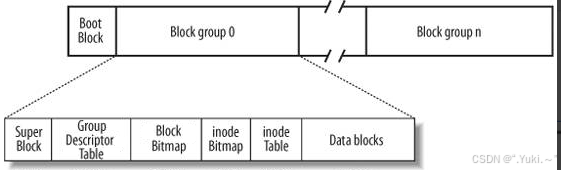
将一个Block group可以这样进行分组:
- super block:记录ext2文件系统的整体信息(整块分区),如一共有多少组,每个组的大小,每个组的inode数量,每个组的起始inode,文件系统的类型与名称(请注意,super block并不是每一个block group都会存在,通常只有一个,但也会存在备份,数量不会太多)
- group descriptor table:描述每个块组的属性,如块组中 inode 位图起始位置、数据块起始位置等,方便系统管理各个块组
- block bitmap:将比特位的位置与块的位置对应起来,用0/1标记data blocks中哪些块被使用,删除文件只需要更改比特位0/1就行了
- inode bitmap:将比特位的位置与inode的位置对应起来,用0/1标记inode table中哪些位置被使用,删除文件还需要更改inode的比特位
- inode table:一个文件对应一个inode(存储单个文件所有属性),大小为128字节,多个文件的inode组成表,用编号标识每个inode
-
data blocks:存储文件内容的区域,分为百万计的小块(4KB)
(ls -li查看文件对应的inode编号)inode是inode table中的数组下标,数组存储着struct inode* 地址,inode编号的数量在一块分区内是一定的,所以存在inode用完块没用完或者inode没用完但块已经用完的情况
让我们看看存储了文件属性的struct inode:
struct inode {
/* 1. 哈希与链表管理 */
struct hlist_node i_hash; /* 用于inode哈希表的链表节点 */
struct list_head i_list; /* 用于超级块或内存管理的inode链表 */
struct list_head i_sb_list; /* 所属超级块的inode链表 */
struct list_head i_dentry; /* 关联的目录项(dentry)链表头 */
/* 2. 基本标识信息 */
unsigned long i_ino; /* inode编号(唯一标识) */
atomic_t i_count; /* 引用计数(被多少进程打开) */
umode_t i_mode; /* 文件类型与权限(如S_IFREG、0644等) */
unsigned int i_nlink; /* 硬链接数量 */
uid_t i_uid; /* 所有者用户ID */
gid_t i_gid; /* 所有者组ID */
kdev_t i_rdev; /* 设备号(若为设备文件) */
/* 3. 尺寸与时间信息 */
loff_t i_size; /* 文件大小(字节) */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改时间(内容变更) */
struct timespec i_ctime; /* 最后状态变更时间(元数据变更) */
/* 4. 块设备相关属性 */
unsigned int i_blkbits; /* 块大小位数(如12表示4KB) */
unsigned long i_blksize; /* 块大小(字节) */
unsigned long i_blocks; /* 占用的512B扇区总数 */
/* 5. 版本与同步控制 */
unsigned long i_version; /* 版本号(每次修改递增,用于NFS) */
struct semaphore i_sem; /* 保护inode操作的信号量 */
struct rw_semaphore i_alloc_sem; /* 分配操作的读写信号量 */
/* 6. 操作函数表 */
struct inode_operations *i_op; /* inode相关操作(如创建、删除等) */
struct file_operations *i_fop; /* 文件操作函数表(如读、写等) */
struct super_block *i_sb; /* 所属超级块指针 */
/* 7. 锁与缓存管理 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 地址空间(页缓存映射) */
struct address_space i_data; /* 内嵌的地址空间结构(核心!) */
/* 8. 扩展属性与配额 */
struct dquot *i_dquot[MAXQUOTAS]; /* 磁盘配额数组 */
struct list_head i_devices; /* 设备文件链表(字符/块设备) */
/* 9. 特殊文件类型信息 */
struct pipe_inode_info *i_pipe; /* 若为管道文件,指向管道信息 */
struct block_device *i_bdev; /* 若为块设备文件,指向块设备 */
struct cdev *i_cdev; /* 若为字符设备文件,指向字符设备 */
/* 10. 通知与状态标志 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知结构 */
unsigned long i_state; /* 状态标志(如I_DIRTY、I_LOCK等) */
unsigned int i_flags; /* 文件系统标志(如S_SYNC、S_APPEND等) */
/* 11. 其他属性 */
unsigned char i_sock; /* 1表示为套接字文件,0为普通文件 */
atomic_t i_writecount; /* 写者计数(控制并发写) */
void *i_security; /* 安全模块私有数据 */
__u32 i_generation; /* 生成号(用于文件系统一致性检查) */
/* 12. 文件系统私有数据(联合体) */
union {
struct minix_inode_info minix_i;
struct ext2_inode_info ext2_i;
struct ext3_inode_info ext3_i;
struct ext4_inode_info ext4_i;
struct reiserfs_inode_info reiserfs_i;
struct jfs_inode_info jfs_i;
struct xfs_inode_info xfs_i;
struct btrfs_inode_info btrfs_i;
struct nfs_inode_info nfs_i;
struct msdos_inode_info msdos_i;
struct umsdos_inode_info umsdos_i;
struct ntfs_inode_info ntfs_i;
struct hpfs_inode_info hpfs_i;
struct sysv_inode_info sysv_i;
struct affs_inode_info affs_i;
struct ufs_inode_info ufs_i;
struct jffs2_inode_info jffs2_i;
struct romfs_inode_info romfs_i;
struct squashfs_inode_info squashfs_i;
struct tmpfs_inode_info tmpfs_i;
struct ubifs_inode_info ubifs_i;
void *generic_ip; /* 通用指针(其他文件系统) */
} u;
};
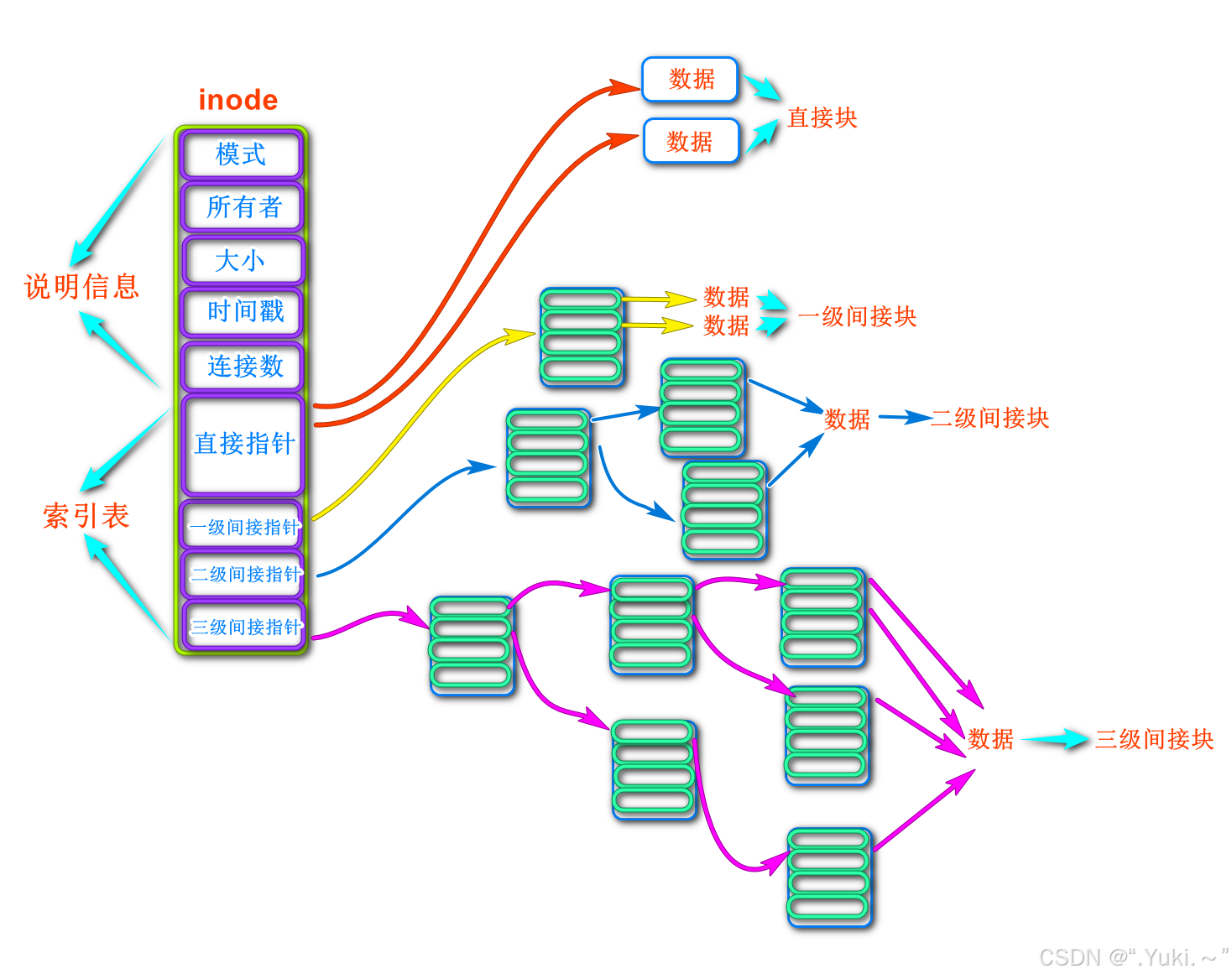
其中多级索引结构被包含在具体文件系统的私有数据里,对应struct inode的u联合体(文件系统私有数据)。以最典型的 ext2/ext3 文件系统为例:
多级索引结构定义在struct ext2_inode_info中(属于struct inode的u.ext2_i成员),其中包含一个 15 元素的数组i_block,是文件的多级索引:
- 直接索引:
i_block[0]到i_block[11](共 12 个),直接存储数据块编号。 - 一级间接索引:
i_block[12],存储的是 “间接块” 的编号(该块中存放的是数据块编号列表)。 - 二级间接索引:
i_block[13],存储的是 “一级间接块的索引块” 编号(嵌套两层)。 - 三级间接索引:
i_block[14],存储的是 “二级间接块的索引块” 编号(嵌套三层)。
每一个分区在被使用之前,都必须提前先将部分文件的属性信息提前设置进对应的分区中,方便我们后续使用这个分区,这个过程可以称作格式化,(个人可以理解为初始化,bitmap什么的都会清空,等于设置为出厂模式),但是对文件进行操作还需要文件的inode,如何将文件名和inode对应起来?这就是目录文件的作用:目录文件的数据块中记录的是键值对:将文件名和inode对应起来,这样就可以将目录下的文件对应到相应的inode,但是,如何知道目录文件的inode?只好去找目录的上级目录,层层递归直到根目录,由于递归费时费力,Linux存在dentry缓存将常用的文件inode保存起来,了解了上面,文件的增删查改就可以具体化:
一、创建文件(增)
分配 inode:系统从分区的 inode 位图(位于某个 block group 中)中查找空闲的 inode 位(标记为未使用)。选中一个 block group 后,在其 inode 表 中分配一个空闲 inode,记录文件元数据(如权限、所有者、时间戳等),并将 inode 位图中对应的位标记为 已使用。选择 block group 的策略:通常基于负载均衡,优先选择空闲 inode 和数据块较多的 block group。
分配数据块:根据文件大小,从该 block group 的 块位图 中查找空闲的数据块位,分配对应的物理数据块。将数据块地址记录到 inode 的数据块指针中,并将块位图中对应的位标记为 已使用。若单个 block group 内的空闲块不足,可能跨多个 block group 分配数据块。
更新目录项:在父目录的 数据块(存储目录项)中添加一条记录,关联文件名和 inode 编号。父目录所在的 block group 的数据块可能被修改。
二、删除文件(删)
减少 inode 引用计数:通过文件名找到对应的 inode 编号,从所在 block group 的 inode 表中读取 inode,将其 引用计数减 1。若引用计数变为 0,说明文件已无有效引用,进入删除流程。
释放数据块:根据 inode 中的数据块指针,遍历所有关联的数据块,将这些块在所属 block group 的 块位图 中标记为 未使用,并将数据块置为空闲状态。若数据块跨多个 block group,需逐个释放各 block group 中的块。
释放 inode:将 inode 在所属 block group 的 inode 位图 中标记为 未使用,并清空 inode 表中的元数据。更新分区的 super block 中 空闲 inode 计数 和 空闲块计数。
删除目录项:在父目录的数据块中移除该文件的目录项,可能释放父目录数据块的空间(若目录项删除后数据块空闲)。
三、查询文件(查)
通过目录遍历定位 inode:根据文件路径逐层查找目录项,例如:/home/user/file.txt 需要先查找根目录 / 的数据块,找到 home 目录的 inode 编号,再进入 home 目录的数据块查找 user 目录的 inode,最后在 user 目录中找到 file.txt 的 inode 编号。每个目录项所在的 block group 需读取其数据块内容。
读取 inode 元数据:根据 inode 编号从对应的 block group 的 inode 表 中读取元数据,获取文件类型、权限、数据块地址等信息。若文件存在,无需修改 block group 中的任何位图或表结构,仅读取数据。
四、修改文件(改)
1. 修改元数据(如权限、时间戳):直接更新 inode 表中对应的 inode 条目,无需涉及数据块或位图的修改。操作发生在 inode 所在的 block group 中,仅修改 inode 表内容。
2. 修改文件内容(如写入新数据):
情况 1:未超出现有数据块容量:直接写入已分配的数据块,更新 block group 中的数据块内容,无需修改位图或分配新块。
情况 2:需要扩展数据块:按创建文件时的逻辑,从 block group 的块位图中分配新的空闲块,更新 inode 的数据块指针,并标记块位图为 已使用。
情况 3:删除部分数据(如截断文件):释放被截断的数据块,在所属 block group 的块位图中标记为 未使用,并更新 inode 中的文件大小信息。
2.软硬链接
1.软连接:
软连接是一个独立的文件,有独立的inode,也有独立的数据块,数据块中保存的是指向文件的路径,相当于windows的快捷方式
应用场景:为复杂路径创建简短的软链接(如 /usr/local/bin 中的命令链接到实际执行文件)
#建立软连接:
ln -s 目标文件或目录路径名 链接名 // 用自己定义的链接文件去链接目标文件或目录
#删除软连接:
rm -rf 目标文件2.硬链接:
本质就是在特定目录的数据块中新增文件名和指向文件的inode编号的映射关系,改变inode内部的引用计数和文件属性中硬链接计数,相当于取别名
应用场景:通常用来进行路径定位,采用硬链接,可以进行目录间切换(eg.cd ..)
#建立硬链接:
ln 目标文件路径名 链接名 // 用自己定义的链接文件去链接目标文件
#删除硬链接:
unlink 硬链接名
为了更加清晰直观了解软硬链接,提供对比表格:
| 对比维度 | 硬链接 | 软链接(符号链接) |
|---|---|---|
| 本质 | 多个文件名共享同一个 inode | 独立文件,存储目标文件的路径字符串 |
| inode 是否相同 | 是(所有硬链接共享同一 inode) | 否(软链接自身有独立 inode) |
| 目标删除影响 | 不影响(只要有一个硬链接存在,数据不丢失) | 链接失效(成为 “死链接”) |
| 能否链接目录 | 否(内核禁止,避免目录结构循环) | 是 |
| 存储空间占用 | 几乎不占用(仅增加 inode 引用计数) | 占用少量空间(用于存储目标路径字符串) |
| 创建命令 | ln 源文件 硬链接 | ln -s 目标文件 软链接 |
3.动静态库
1.静态库
制作静态库:ar -rc命令,
ar -rc $@ $^制作后编译使用gcc main.c -I ./lib/include/ -L ./lib/mylib/ -lmylib
-I标识include -L代表库 -l代表链接
这是使用第三方库必须指明的,-l必不可少指明库的名字(注意libc.so -> c库,去掉前缀lib,去掉后缀.so/.a)
注意:如果只有静态库,那么链接时默认只能静态链接,并且gcc可以链接多个库
eg.gcc main.c mylib.c -I ./lib/include/ -L ./lib/mylib/ -lmylib如果你不想指定链接库的路径,那么可以将静态库和头文件复制到系统默认搜索路径下:
(/usr/include /lib64),也可以制作软连接,在.c文件中直接包含路径下的头文件即可
sudo ln -s /home/drw1/linux/testLIB/lib/include /usr/include/mylib.h
sudo ln -s /home/drw1/linux/testLIB/lib/mylib/libmylib.a /lib64/libmylib.a(别把lib64删了 小子!)不要轻易使用unlink,这样gcc就不需要-I -L了,但是还是需要-l指明静态库名称!
2.动态库
制作动态库:先制作.o文件, gcc -fPIC -c $^ -o $@ ,需要带上fPIC!(生成与位置无关码)gcc -shared $^ -o $@ 命令;
直接编译:gcc main.c -I mylib/include -L mylib/lib -lmyloga -lmylogso -o log.exe
制作后编译还有四种方法:
1.将动态库复制到系统默认搜索路径下(实际用这种方式较多)
2.建立软连接(动静结合给出)
sudo ln -s /home/drw1/linux/testLIB2/mylib/lib/libmyloga.a /lib64/libmyloga.a
sudo ln -s /home/drw1/linux/testLIB2/mylib/lib/libmylogso.so /lib64/libmylogso.so3.修改坏境变量$LD_LIBRARY_PATH(只和动态链接有关),如果想要永久保存修改的环境变量,vim ~/.bash_profile 将修改的环境变量export
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/drw1/linux/testLIB2/mylib/lib4.修改/etc/ld.so.conf.d文件,新建一个任意名字文件,在文件中保存动态库的路径
//下面是分别使用一个动静态库制作并编译的makefile文件
(相关头文件和库文件已经建立软连接!)
static-lib=libmylog.a
dynamic-lib=libmylog.so
mylog.exe:main.c all
gcc main.c -lmyloga -lmylogso -o mylog.exe
.PHONY:all
all:$(static-lib) $(dynamic-lib)
$(static-lib):mysort.o
ar -rc $@ $^
$(dynamic-lib):mystring.o
gcc -shared $^ -o $@
mysort.o:mysort.c
gcc -c $^ -o $@
mystring.o:mystring.c
gcc -fPIC -c $^ -o $@
.PHONY:clean
clean:
rm -rf *.o *.a *.so *.exe
.PHONY:output
output:
mkdir -p ./mylib/include
mkdir -p ./mylib/lib
cp *.h ./mylib/include
cp *.a ./mylib/lib
cp *.so ./mylib/lib对比区别:动态库在进程运行的时候,是要被加载的,而静态库就没有,常见的动态库被所有的可执行程序(动态链接的)都要使用,所以动态库在系统中加载之后,会被所有进程共享,本质上是动态库从磁盘中加载到内存中,经过页表映射到虚拟地址空间的共享区中,如果动态库有多个,那么还是先描述再组织,由于存储在进程地址空间,会发生写时拷贝。
————————————~本文结束~————————————


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









