







文章目录
【C++】多线程与异步编程【四】
0.三问
同步,异步,多线程之间是什么关系?异步比同步高效在哪?多线程比单线程高效在哪? 捋一下, 想一下怎么回答。
1.什么是异步编程?
1.1同步与异步
前面谈到并发,互斥锁与条件变量, 前面提到的线程同步主要是为了解决对共享数据的竞争访问问题,所以线程同步主要是对共享数据的访问同步化(按照既定的先后次序,一个访问需要阻塞等待前一个访问完成后才能开始)。这篇文章谈到的异步编程主要是针对任务或线程的执行顺序,也即一个任务不需要阻塞等待上一个任务执行完成后再开始执行,程序的执行顺序与任务的排列顺序是不一致的。下面从任务执行顺序的角度解释下同步与异步的区别:
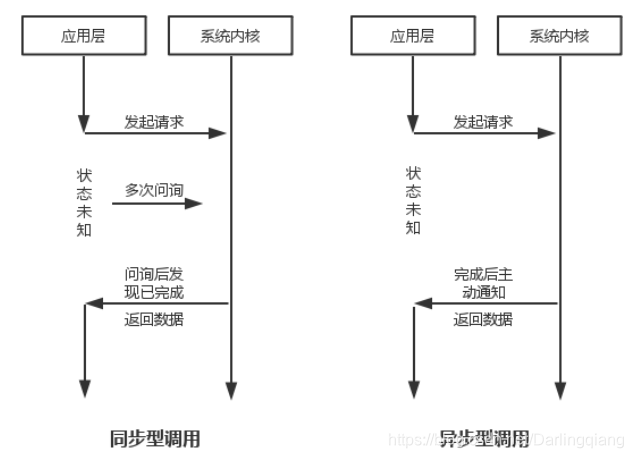
- 同步:就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。
- 异步:调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。 而是在调用发出之后,被调用者通过“状态”、“通知”、“回调”三种途径通知调用者。
可以使用哪一种途径依赖于被带调用者的实现,除非被调用者提供多种选择,否则不受调用者控制。如果被调用者用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低。如果使用通知和回调的方式,效率则很高。因为被调用者几乎不需要做额外的操作。
举个栗子:
你打电话问书店老板有没有《程序员的自我修养》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
1.2 阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态。
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
举个栗子:
爱喝茶的老张,有两把水壶(普通水壶,简称水壶;会响的水壶,简称响水壶)。
- 老张把水壶放到火上,立等水开,然后泡茶。(同步阻塞)老张觉得自己有点傻。
- 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有,然后泡茶。(同步非阻塞)。
- 老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开后,能大声发出嘀~~~的噪音。
- 老张把响水壶放到火上,立等水开泡茶。(异步阻塞)。
- 老张觉得这样傻等意义不大,老张把响水壶放到火上,去客厅看电视,水壶响后泡茶。(异步非阻塞)。
- 这里所谓同步异步,只是对于事件烧水和事件看电视。普通水壶,同步,指水壶烧水(线程)和来张(主线程)同时开始;响水壶,异步。虽然都能干活,但响水壶可以在自己完工之后,烧水事件,提示老张(主线程)水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
- 所谓阻塞非阻塞,仅仅对于老张的状态(主线程)而言。立等的老张,阻塞,主线程不能进行其他工作;看电视的老张,非阻塞,主线程可以进行其他工作。
情况1和情况3中老张就是阻塞的,主线程(老张的状态)不能去做其他任何事情,媳妇喊他都不知道。虽然4中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
这里针对多核的CPU在阻塞的情况下,计算量比较大的情况下,可以采用异步的方法,在将第i次的烧水和泡茶采用异步实现,使得喝茶这个目标的实现可以更加的高效。
2、如何使用异步编程
在线程库< thread >中并没有获得线程执行结果的方法,通常情况下,线程调用者需要获得线程的执行结果或执行状态,以便后续任务的执行。那么,通过什么方式获得被调用者的执行结果或状态呢?
2.1 使用全局变量与条件变量传递结果
前面谈到的条件变量具有“通知–唤醒”功能,可以把执行结果或执行状态放入一个全局变量中,当被调用者执行完任务后,通过条件变量通知调用者结果或状态已更新,可以使用了。
实例1:
//future1.cpp 使用全局变量传递被调用线程返回结果,使用条件变量通知调用线程已获得结果
#include <vector>
#include <numeric>
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>
#include <condition_variable>
int res = 0; //保存结果的全局变量
std::mutex mu; //互斥锁全局变量
std::condition_variable cond; //全局条件变量
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last)
{
int sum = std::accumulate(first, last, 0); //标准库求和函数
std::unique_lock<std::mutex> locker(mu);
res = sum;
locker.unlock();
cond.notify_one(); // 向一个等待线程发出“条件已满足”的通知
}
int main()
{
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::thread work_thread(accumulate, numbers.begin(), numbers.end());
std::unique_lock<std::mutex> locker(mu);
//如果条件变量被唤醒,检查结果是否被改变,为真则直接返回,为假则继续等待
cond.wait(locker, [](){ return res;});
std::cout << "result=" << res << '\n';
locker.unlock();
work_thread.join();//阻塞等待线程执行完成
getchar();
return 0;
}
result=21
从上面的代码可以看出,虽然也实现了获取异步任务执行结果的功能,但需要的全局变量较多,多线程间的耦合度也较高,编写复杂程序时容易引入bug。有没有更好的方式实现异步编程呢?C++ 11新增了一个< future >库函数为异步编程提供了很大的便利。
2.2 使用promise与future传递结果
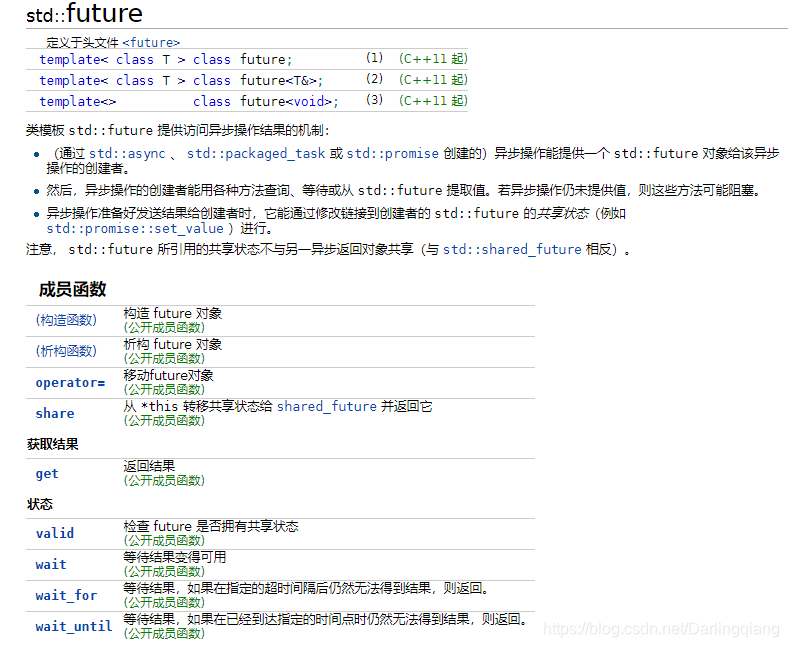
< future >头文件功能允许对特定提供者设置的值进行异步访问,可能在不同的线程中。
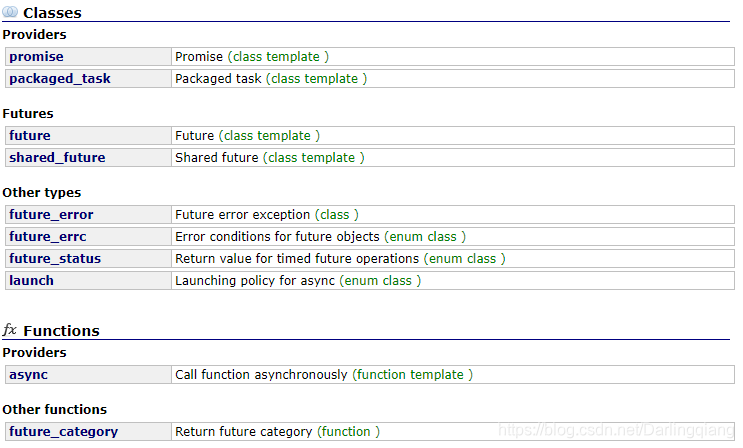
这些提供程序(要么是promise 对象,要么是packaged_task对象,或者是对异步的调用async)与future对象共享共享状态:提供者使共享状态就绪的点与future对象访问共享状态的点同步。< future >头文件的结构如下:
实例2
std::promise< T >构造时,产生一个未就绪的共享状态(包含存储的T值和是否就绪的状态)。可设置T值,并让状态变为ready。也可以通过产生一个future对象获取到已就绪的共享状态中的T值。继续使用上面的程序示例,改为使用promise传递结果,修改后的代码如下:
实例3
//future2.cpp 使用promise传递被调用线程返回结果,通过共享状态变化通知调用线程已获得结果
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
#include <chrono>
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last,
std::promise<int> accumulate_promise)
{
int sum = std::accumulate(first, last, 0);
accumulate_promise.set_value(sum); // 将结果存入,并让共享状态变为就绪以提醒future
}
int main()
{
// 演示用 promise<int> 在线程间传递结果。
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::promise<int> accumulate_promise;
std::future<int> accumulate_future = accumulate_promise.get_future();
std::thread work_thread(accumulate, numbers.begin(), numbers.end(),
std::move(accumulate_promise));
accumulate_future.wait(); //等待结果
std::cout << "result=" << accumulate_future.get() << '\n';
work_thread.join(); //阻塞等待线程执行完成
getchar();
return 0;
}
result=21
std::promise< T >对象的成员函数get_future()产生一个std::future< T >对象,代码示例中已经展示了future对象的两个方法:wait()与get(),下面给出更多操作函数供参考:
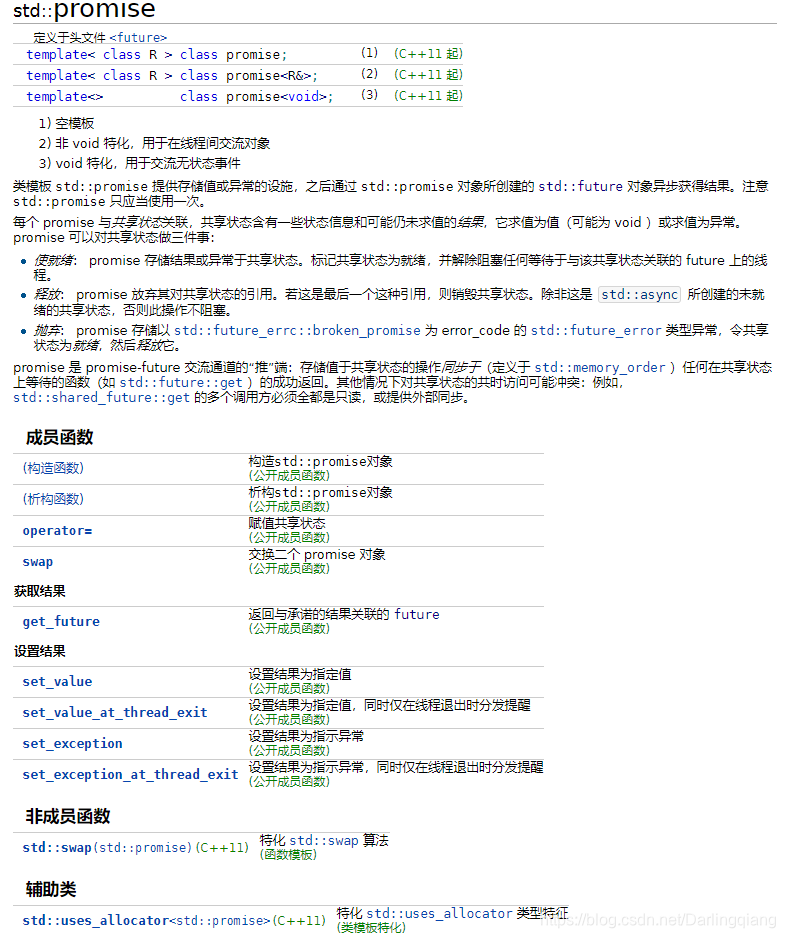
值得注意的是,std::future< T >在多个线程等待时,只有一个线程能获取等待结果。当需要多个线程等待相同的事件的结果(即多处访问同一个共享状态),需要用std::shared_future< T >来替代std::future < T >,std::future< T >也提供了一个将future转换为shared_future的方法f.share(),但转换后原future状态失效。这有点类似于智能指针std::unique_ptr< T >与std::shared_ptr< T >的关系,使用时需要留心。
2.3使用packaged_task与future传递结果
除了为一个任务或线程提供一个包含共享状态的变量,还可以直接把共享状态包装进一个任务或线程中。这就需要借助std::packaged_task< Func >来实现了,其具体用法如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CpRCBIyA-1609675314863)(C:\Users\guoqi\AppData\Roaming\Typora\typora-user-images\1609669883139.png)]
std::packaged_task< Func >构造时绑定一个函数对象,也产生一个未就绪的共享状态。通过thread启动或者仿函数形式启动该函数对象。但是相比promise,没有提供set_value()公用接口,而是当执行完绑定的函数对象,其执行结果返回值或所抛异常被存储于能通过 std::future 对象访问的共享状态中。继续使用上面的程序示例,改为使用packaged_task传递结果,修改后的代码如下:
实例4
//future3.cpp 使用packaged_task传递被调用线程返回结果,通过共享状态变化通知调用线程已获得结果
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
#include <chrono>
int accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last)
{
int sum = std::accumulate(first, last, 0);
return sum;
}
int main()
{
// 演示用 packaged_task 在线程间传递结果。
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::packaged_task<int(std::vector<int>::iterator,std::vector<int>::iterator)> accumulate_task(accumulate);
std::future<int> accumulate_future = accumulate_task.get_future();
std::thread work_thread(std::move(accumulate_task), numbers.begin(), numbers.end());
accumulate_future.wait(); //等待结果
std::cout << "result=" << accumulate_future.get() << '\n';
work_thread.join(); //阻塞等待线程执行完成
getchar();
return 0;
}
result=21
一般不同函数间传递数据时,主要是借助全局变量、返回值、函数参数等来实现的。上面第一种方法使用全局变量传递数据,会使得不同函数间的耦合度较高,不利于模块化编程。后面两种方法分别通过函数参数与返回值来传递数据,可以降低函数间的耦合度,使编程和维护更简单快捷。
2.4 使用async传递结果
前面介绍的std::promise< T >与std::packaged_task< Func >已经提供了较丰富的异步编程工具,但在使用时既需要创建提供共享状态的对象(promise与packaged_task),又需要创建访问共享状态的对象(future与shared_future),还是觉得使用起来不够方便。有没有更简单的异步编程工具呢?future头文件也确实封装了更高级别的函数std::async,其具体用法如下:
- std::future std::async(std::launch policy, Func, Args…)
std::async是一个函数而非类模板,其函数执行完后的返回值绑定给使用std::async的std::futrue对象(std::async其实是封装了thread,packged_task的功能,使异步执行一个任务更为方便)。Func是要调用的可调用对象(function, member function, function object, lambda),Args是传递给Func的参数,std::launch policy是启动策略,它控制std::async的异步行为,我们可以用三种不同的启动策略来创建std::async:
- std::launch::async参数 保证异步行为,即传递函数将在单独的线程中执行;
- std::launch::deferred参数 当其他线程调用get()/wait()来访问共享状态时,将调用非异步行为;
- std::launch::async | std::launch::deferred参数 是默认行为(可省略)。有了这个启动策略,它可以异步运行或不运行,这取决于系统的负载。
继续使用上面的程序示例,改为使用std::async传递结果,修改后的代码如下:
实例5
//future4.cpp 使用async传递被调用线程返回结果
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
#include <chrono>
int accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last)
{
int sum = std::accumulate(first, last, 0);
return sum;
}
int main()
{
// 演示用 async 在线程间传递结果。
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
auto accumulate_future = std::async(std::launch::async, accumulate, numbers.begin(), numbers.end()); //auto可以自动推断变量的类型
std::cout << "result=" << accumulate_future.get() << '\n';
getchar();
return 0;
}
result=21
从上面的代码可以看出使用std::async能在很大程度上简少编程工作量,使我们不用关注线程创建内部细节,就能方便的获取异步执行状态和结果,还可以指定线程创建策略。所以,我们可以使用std::async替代线程的创建,让它成为我们做异步操作的首选。
此外,还有什么机制可以通过底层实现,提高性能,解决锁机制的问题,下面将会学习基于原子数据类型和对应的原子操作无锁编程的的思想。
3.小结
-
多线程比单线程高效的原因就是利用了CPU的多核计算把一个大的任务分而治之从而加速任务计算。
-
异步比同步高效的原因是前者释放了调用线程,让调用线程可以做更多的事情而不至于被windows强制休眠浪费线程资源。
-
就能方便的获取异步执行状态和结果,还可以指定线程创建策略。所以,我们可以使用std::async替代线程的创建,让它成为我们做异步操作的首选。
-
此外,还有什么机制可以通过底层实现,提高性能,解决锁机制的问题,下面将会学习基于原子数据类型和对应的原子操作无锁编程的的思想。















 4685
4685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











