






提纲
- 概述
- 流程框架
- 滑动窗口
- 光度标定
- 评述
- 概述
DSO属于稀疏直接法的视觉里程计。它不是完整的SLAM,因为它不包含回环检测、地图复用的功能。因此,它不可避免地会出现累计误差,尽管很小,但不能消除。DSO目前开源了单目实现,双目DSO的论文已被ICCV接收,但目前未知是否开源。
DSO是少数使用纯直接法(Fully direct)计算视觉里程计的系统之一。相比之下,SVO[2]属于半直接法,仅在前端的Sparse model-based Image Alignment部分使用了直接法,之后的位姿估计、bundle adjustment,则仍旧使用传统的最小化重投影误差的方式。而ORB-SLAM2[3],则属于纯特征法,计算结果完全依赖特征匹配。从方法上来说,DSO是新颖、独树一帜的。
直接法相比于特征点法,有两个非常不同的地方:
- 特征点法通过最小化重投影误差来计算相机位姿与地图点的位置,而直接法则最小化光度误差(photometric error)。所谓光度误差是说,最小化的目标函数,通常由图像之间的误差来决定,而非重投影之后的几何误差。
- 直接法将数据关联(data association)与位姿估计(pose estimation)放在了一个统一的非线性优化问题中,而特征点法则分步求解,即,先通过匹配特征点求出数据之间关联,再根据关联来估计位姿。这两步通常是独立的,在第二步中,可以通过重投影误差来判断数据关联中的外点,也可以用于修正匹配结果(例如[4]中提到的类EM的方法)。
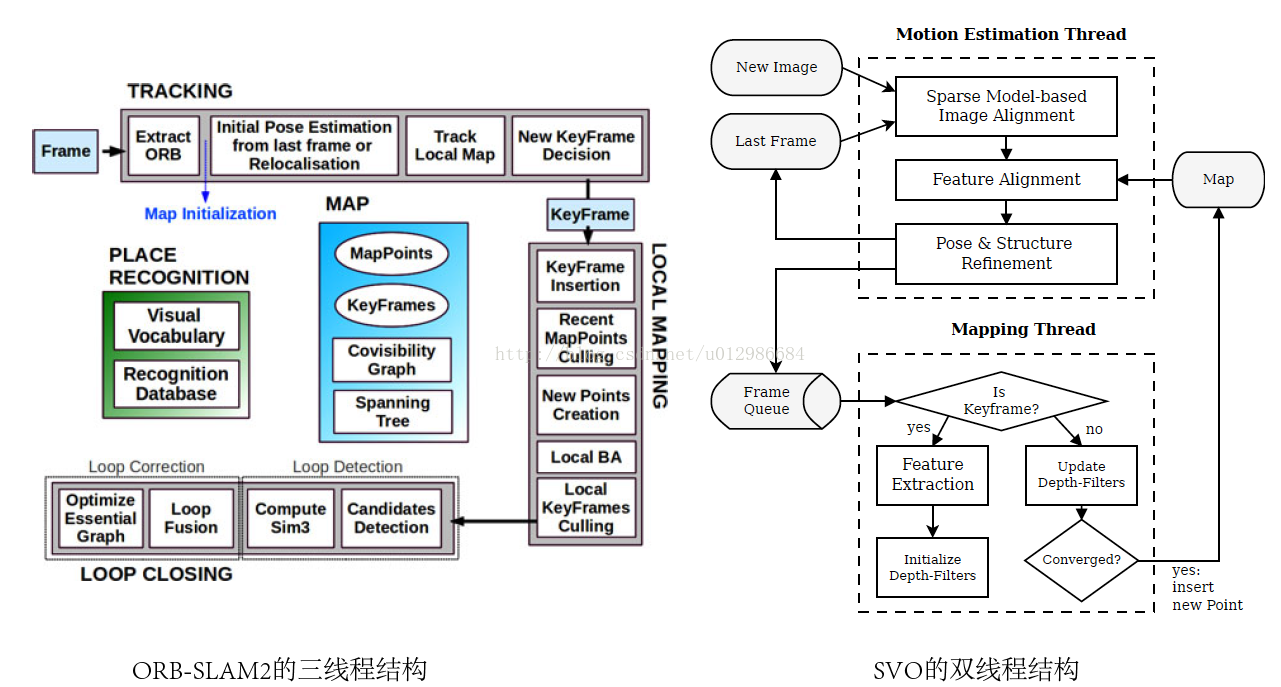
从后端来看,DSO使用一个由若干个关键帧组成的滑动窗口作为它的后端。这个窗口在整个VO过程中一直存在,并有一套方法来管理新数据的加入以及老数据的去除。具体来说,这个窗口通常保持5到7个关键帧。前端追踪部分,会通过一定的条件,来判断新来的帧是否可作为新的关键帧插入后端。同时,如果后端发现关键帧数已经大于窗口大小,也会通过特定的方法,选择其中一个帧进行去除。请注意被去除的帧并不一定是时间线上最旧的那个帧,而是会有一些复杂条件的。
后端除了维护这个窗口中的关键帧与地图点外,还会维护与优化相关的结构。特别地,这里指Gauss-Newton或Levenburg-Marquardt方法中的Hessian矩阵和b向量(仅先验部分)。当我们增加新的关键帧时,就必须扩展H和b的维度;反之,如果需要去掉某个关键帧(以及它携带的地图点)时,也需要降低H和b的维度。这个过程还需要将被删掉帧和点的信息,转移到窗口内剩余帧当中,这一步被称为边缘化(Marginalization)。
由于直接法需要比较图像信息,其结果容易受光照干扰。于是,DSO提出了光度标定,认为对相机的曝光时间、暗角、伽马响应等参数进行标定后,能够让直接法更加鲁棒。对于未进行光度标定的相机,DSO也会在优化中动态估计光度参数(具体来说,是一个仿射变化的参数,记作a和b)。这个过程建模了相机的成像过程,因此对于由相机曝光不同引起的图像明暗变化,会有更好的表现。但是,如果由于环境光源发生变化,光度标定也是无能为力的。
2. 框架流程
2.1 代码框架与数据表示
现在我们来看DSO的大体框架。我去除了一些不重要的类和结构,方便读者阅读。

DSO整体代码由四个部分组成:系统与各算法集成于src/FullSystem,后端优化位于src/OptimizationBackend,这二者组成了DSO大部分核心内容。src/utils和src/IOWrapper为一些去畸变、数据集读写和可视化UI代码。先来看核心部分的FullSystem和OptimizationBackend。
如上图上半部分所示,在FullSystem里,DSO致力于维护一个滑动窗口内部的关键帧序列。每个帧的数据存储于FrameHessian结构体中,FrameHessian即是一个带着状态变量与Hessian信息的帧。然后,每个帧亦携带一些地图点的信息,包括:
- pointHessians是所有活跃点的信息。所谓活跃点,是指它们在相机的视野中,其残差项仍在参与优化部分的计算;
- pointHessiansMarginalized是已经边缘化的地图点。
- pointHessiansOut是被判为外点(outlier)的地图点。
- 以及immaturePoints为未成熟地图点的信息。
在单目SLAM中,所有地图点在一开始被观测到时,都只有一个2D的像素坐标,其深度是未知的。这种点在DSO中称为未成熟的地图点:Immature Points。随着相机的运动,DSO会在每张图像上追踪这些未成熟的地图点,这个过程称为trace——实际上是一个沿着极线搜索(2D-2D可得到点的深度坐标哦)的过程,十分类似于svo的depth filter。Trace的过程会确定每个Immature Point的逆深度和它的变化范围。如果Immature Point的深度(实际中为深度的倒数,即逆深度)在这个过程中收敛,那么我们就可以确定这个未成熟地图点的三维坐标,形成了一个正常的地图点。具有三维坐标的地图点,在DSO中称为PointHessian。与FrameHessian相对,PointHessian亦记录了这个点的三维坐标,以及Hessian信息。与很多其他SLAM方案不同,DSO使用单个参数描述一个地图点,即它的逆深度。而ORB-SLAM等多数方案,则会记录地图点的x,y,z三个坐标。逆深度参数化形式具有形式简单、类似高斯分布、对远处场景更为鲁棒等优点[5],但基于逆深度参数化的Bundle adjustment,每个残差项需要比通常的BA多计算一个雅可比矩阵。为了使用逆深度,每个PointHessian必须拥有一个主导帧(host frame),说明这个点是由该帧反投影得到的。
于是,滑动窗口的所有信息(策略的改进也是作者想法中比较经典的处理方式),可以由若干个FrameHessian,加上每个帧带有的PointHessian来描述。所有的PointHessian又可以在除主导帧外的任意一帧中进行投影,形成一个残差项,记录于PointHessian::residuals中。所有的残差加起来,就构成了DSO需要求解的优化问题。当然,由于运动、遮挡的原因,并非每个点都可以成功地投影到其余任意一帧中去,于是我们还需要设置每个点的状态:有效的/被边缘化的/无效的。不同状态的点,被存储于它主导帧的pointHessians/pointHessianMarginalized/PointHessiansOut三个容器内。
除此之外,DSO将相机的内参、曝光参数等信息,亦作为优化变量考虑在内。相机内参由针孔相机参数fx, fy, cx, cy表达,曝光参数则由两个参数a,b描述。这部分内容在光度标定一节内。
后端优化部分单独具有独立的Frame, Point, Residual结构。由于DSO的优化目标是最小化能量(energy,和误差类似),所以有关后端的类均以EF开头,且与FullSystem中存储的实例一一对应,互相持有对方的指针。优化部分由EnergyFunctional类统一管理(具有全局优化的功能)。它从FullSystem中获取所有帧和点的数据,进行优化后,再将优化结果返回。它也包含整个滑动窗口内的所有帧和点信息,负责处理实际的非线性优化矩阵运算。
2.2 VO流程
每当新的图像到来时,DSO将处理此图像的信息,流程如下:
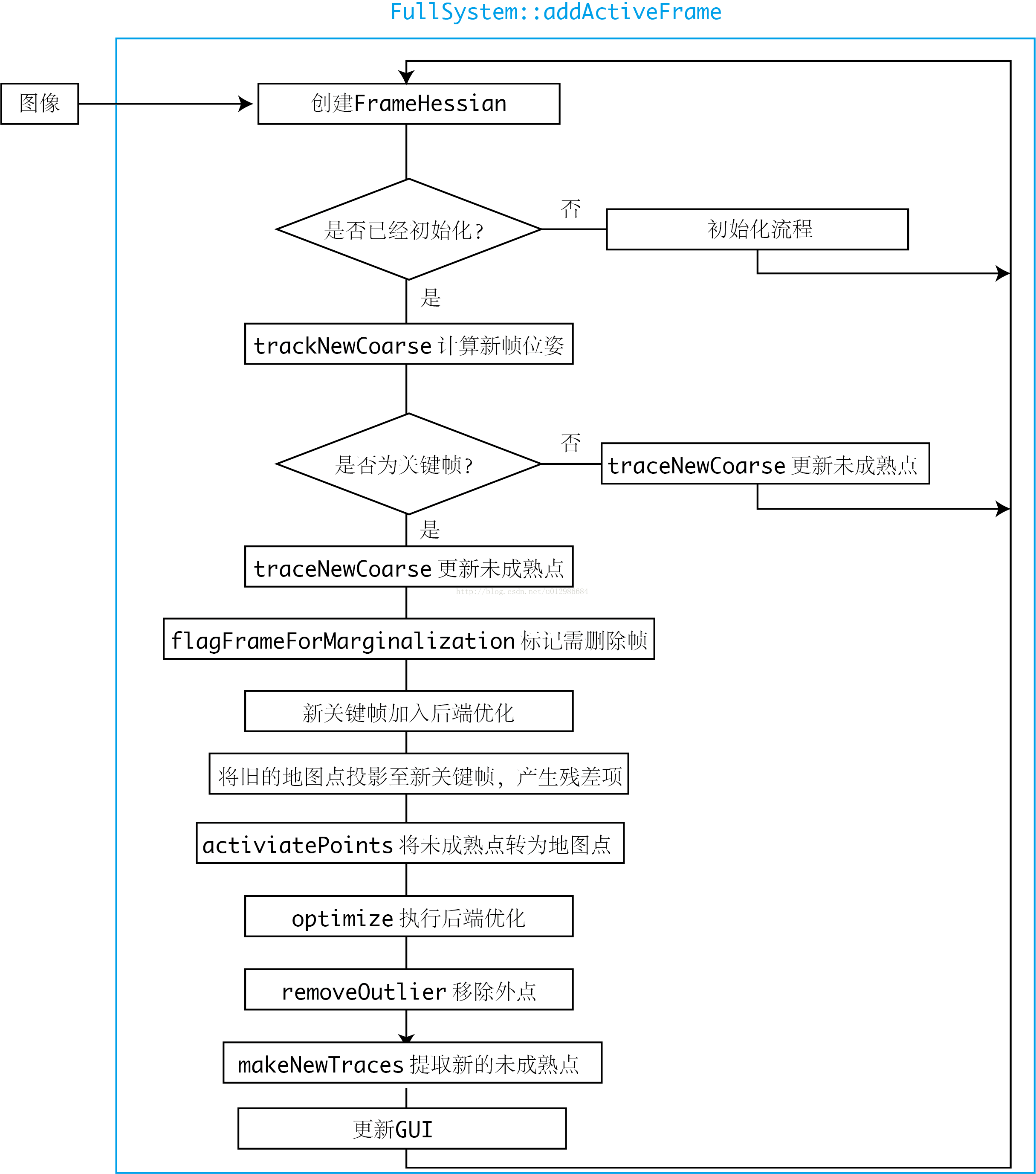
尽管没有解释每一步的具体用意,但可以看出DSO的大致流程。从上图可以简单总结出DSO的行为:
- 对于非关键帧(主要用于跟踪),DSO仅计算它的位姿,并用该帧图像更新每个未成熟点的深度估计;
- 后端仅处理关键帧部分的优化。除去一些内存维护操作(内存的调用在并行运算中是很重要的一个问题Hash列表的引入可以很大程度的提高搜索的效率,从而加快计算的速度,数据的关联与出栈入栈,语义的加入与词包的使用可以使得效率得到本质上的提升),对每个关键帧主要做的处理有:增加新的残差项、去除错误的残差项、提取新未成熟点。
- 整个流程在一个线程内,但内部可能有多线程的操作。
3. DSO详细介绍
3.1 残差的构成与雅可比
在VO过程中,DSO会维护一个滑动窗口(里面有一个全局优化的思想,使得结果兼顾效率与速度,策略的不同使得架构有了本质提升),通常由5-7个关键帧组成,流程如前所述。DSO试图将每个先前关键帧中的地图点投影到新关键帧中,形成残差项。同时,会在新关键帧中提取未成熟点,并希望它们演变成正常地图点。在实际当中,由于运动、遮挡的原因,部分残差项会被当作outlier,最终剔除;也有部分未成熟地图点无法演化成正常地图点,最终被剔除。
滑动窗口内部构成了一个非线性最小二乘问题。表示成因子图(或图优化)的形式,如下所示:
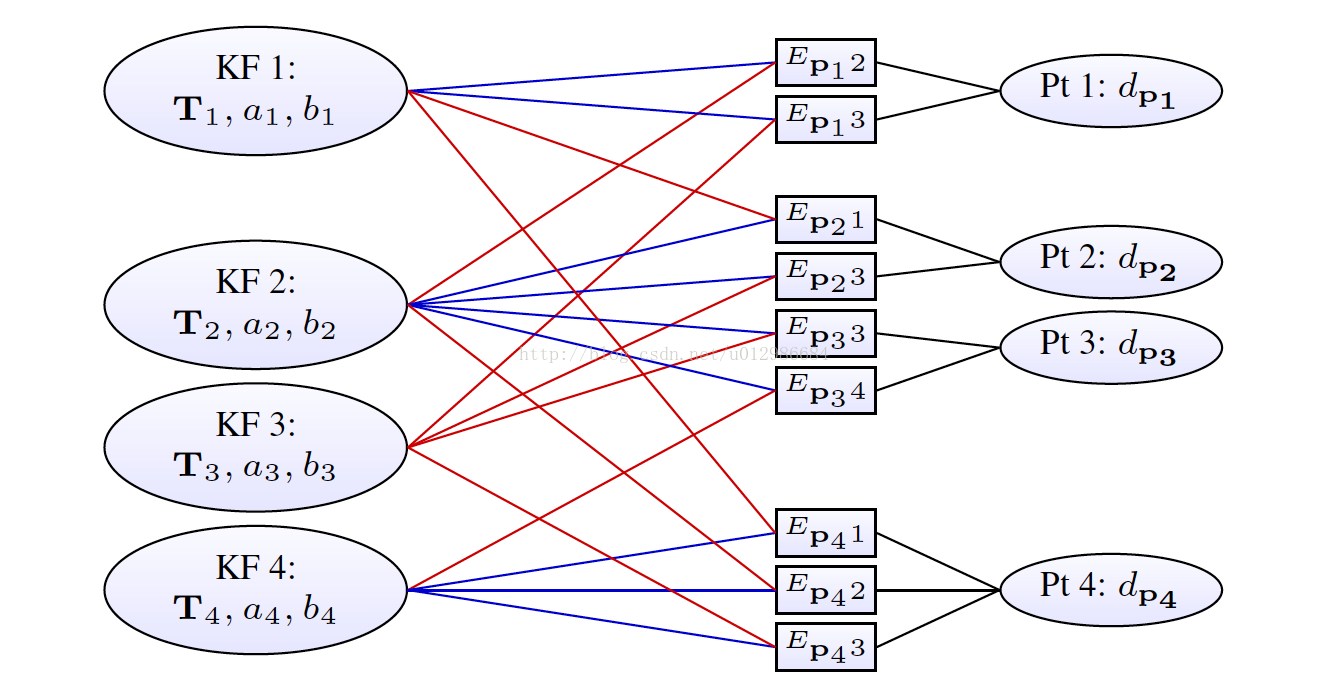
每一个关键帧的状态为八维:六自由度的运动位姿加上两个描述光度的参数;每个地图点的状态变量为一维,即该点在主导帧(Host)里的逆深度。于是,每个残差项(或能量项E),将关联两个关键帧与一个逆深度。事实上,还有一个全局的相机内参数亦参与了优化,但未在此图中表示。
现在我们来考虑如何计算残差。这部分推导和LSD-SLAM的会议论文[6],以及我的书[7]是类似的。如果读者觉得有困难,可以参照它们。
设相机模型由针孔模型描述,那么内参矩阵为:
设有两个帧,一个称为Host,一个称Target,它们各自到世界坐标的变换矩阵记为 ,这二者又可以拆开为旋转和平移。考虑Host帧中一个像素点:
其中 为该点的像素坐标,这里使用了齐次坐标以方便矩阵运算。同时,该点的逆深度为:
其中 为该点的深度值。那么,这个点在Target帧中的投影为:
注:(i). 为方便起见,我们略去了此公式中的齐次坐标至非齐次的转换,默认它们是自动转换的;(ii). 我们定义了中间变量 ,即点的世界坐标,以及Host至Target的相对变换。
由此可以定义该点的残差。设Host和Target的图像分别是 ,那么残差为:
但是在实现中,DSO会同时估计图像的光度参数a,b,所以在计算误差时,会用到去掉光度参数之后的那个值。但是这里我们先不谈光度标定部分,所以暂时把 看成原始图像。
接下来我们要谈论雅可比。在完整DSO中,雅可比由三部分组成:
- 图像雅可比,即图像梯度;
- 几何雅可比,描述各量相对几何量,例如旋转和平移的变化率;
- 光度雅可比,描述各个量相对光度参数的雅可比;
作者认为,几何和光度的雅可比,相对自变量来说通常是光滑函数;而图像雅可比则依赖图像数据,不够光滑;所以,在优化过程中,几何和光度的雅可比仅在迭代开始时计算一次,此后固定不变[1]。而图像雅可比则随着迭代更新。这种做法称为First-Estimate-Jacobian(FEJ),在VIO中也会经常用到[8]。它可以减小计算量、防止优化往错误的地方走太多,也可以在边缘化过程中保证零空间的维度不会降低,后者我们还要在后文继续谈。
下面来看几何雅可比的具体计算。记 为李代数表示的
,并定义:
根据[7]的推导加一些变化,可知:
再考虑对于Host帧中的逆深度 之雅可比:
显然:
对于后者,首先记:
那么:
其中下标1表示取第一行,3表示第三行。于是
最后的式子中我们重新把 代回去,使得式子更加简洁。同理有:
于是得:
接下来考虑残差相对于相机内参的雅可比,这部分相对于其余部分稍为复杂,我们仅展示残差对 之导数,其余部分类似可得,因此留给读者。由于:
该式略去了 的下标,以保持行文简洁。展开后式,有:
于是:
现在想要求第一行关于 之导数,由链式法则:
而
第一项中,由前述,有:
于是
第二项:
因此:
于是,得到了投影点关于 的导数。关于
的结论可类似推出,不再赘述。以上计算均实现于PointFrameResidual::linearize函数。
值得一提的是,在DSO中,每个投影点,除了自身的位置之外,一共提供八维残差,这是为了更好利用该点的信息。这八维残差由这个点与周围几个点组成的Pattern定义,如下图所示:
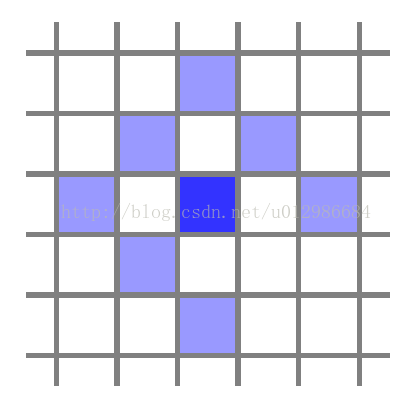
选八个点是为了方便SSE(Super Strong Erection),其实在settings.cpp中还有许多别的Pattern。所以,在DSO的直接法中,我们实际上假设了这八个点在不同图像中保持灰度不变。并且,它们在优化中共享中间点的深度,所以也不能简单地看成八个独立的点。(文中作者用实验的方法探索出最合适的模版类型,也就是上面这个了)
3.2 滑动窗口的维护与边缘化
若干和关键帧,与它们关联的地图点组成的残差项,构成了整个滑动窗口中的内容。为了优化这些帧和点,我们会利用Gauss-Newton或Levernberg-Marquardt方法进行迭代。在迭代中,所有的残差项可以拼成一个大型的线性方程:
其中 分别为拼接后的雅可比、权重和残差,
为整体的优化更新量。左侧可以记成:
,即Hessian矩阵。这个矩阵在整个优化过程中都会一直维护于内存中。注意这种做法和ORB-SLAM2是不同的。在ORB-SLAM2的后端中,我们会不停地重构整个优化问题,求解,然后存储优化后的结果,但这个H矩阵是不会一直存在的。而在DSO中,由于H是一直维护的,所以之后的优化可以利用先前的结果,或者说,先前的优化为下一步提供了先验(Prior)。但是,为了维护这个H信息,DSO必须手动地增加/删除每一个帧和点,而不像ORB-SLAM2那样,可以无视帧和点的变化。
我们知道,H实际上有一个特殊的形状(箭头形矩阵,Arrow-like Matrix)[1,7,9],如下图所示:
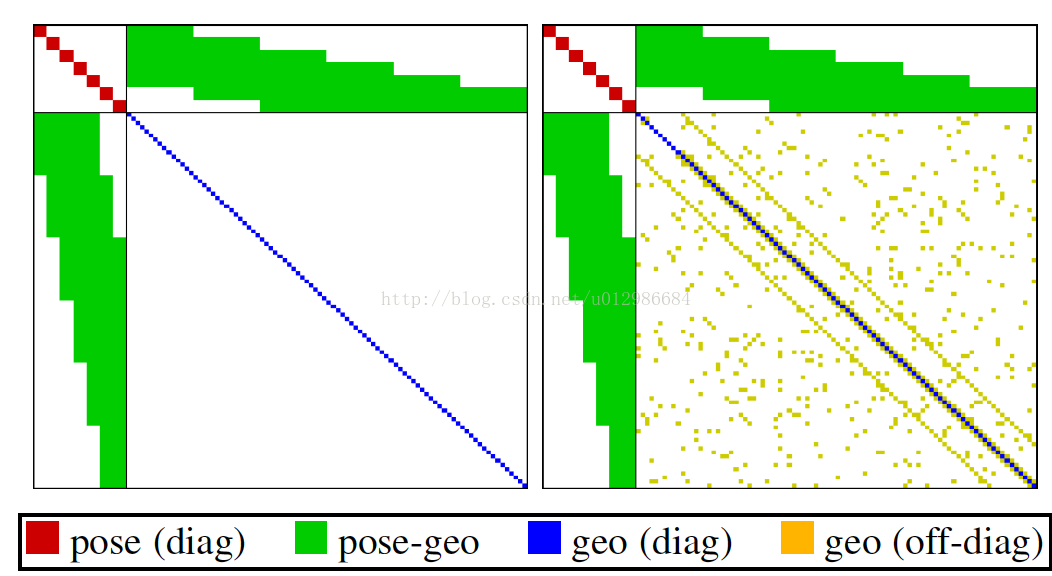
众所周知,这个形状是由BA本身的结构导致的。把它的分块记为:
那么右下角的 是一个对角块矩阵(因为没有结构的先验,即点——点的残差)。块的大小取决于地图点的参数化维度,在DSO中是一维,在ORB-SLAM2中是三维。接下来,在传统BA中(类似于ORB-SLAM2)的做法是这样的:
- 通过图优化构建这个H;
- 用高斯消元法(即舒尔补(这个又很复杂的数学推到,简单的说就是一个补集))将右下角部分消元:
即:
- 此时方程解耦,于是先解左上部分(维度很小);再用左上部分的结果解右下部分。
这个过程也称为边缘化(Marginalization),此时我们边缘化掉了所有的点,将他们的信息归到了位姿部分中,形成了相机位姿部分的先验。这部分知识,对于每位SLAM研究者来说应当是熟知的。
那么在DSO中,有哪些地方用了边缘化?
首先,DSO的BA,也和传统BA一样,有上述步骤。因此DSO在解BA时,边缘化了所有点的信息,计算优化的更新量。然而,与传统BA不同的是,DSO的左上角部分,即公式中的 ,并非为对角块,而是有先验的。传统BA中,这部分为对角块,主要原因是不知道相机运动的先验,而DSO的滑动窗口,则通过一定手段计算了这个先验。这里的先验主要来自两个部分:
- 边缘化某个点时,这个点的共视帧之间产生先验;
- 边缘化某个帧时,在窗口内其他帧之间产生先验;
这里的“边缘化”,具体的操作和上面讲的边缘化,是一样的。也就是说,通过舒尔补,用矩阵的一部分去消元另一部分。然而实际操作的含义却有所不同。在BA的边缘化中,我们希望用边缘化加速整个问题的求解,但是解完问题后,这些帧和点仍旧是存在于窗口中的!而滑动窗口中的边缘化,是指我们不再需要这个点/这个帧。当它被边缘化时,我们将它的信息传递到了之后的先验中,而不会再利用这个点/这个帧了!请读者务必理清这层区别,否则在理解过程中会遇到问题。我们不妨将后者称为“永久边缘化”,以示区分。
那么DSO如何永久边缘化某个帧或点?它遵循以下几个准则:
- 如果一个点已经不在相机视野内,就边缘化这个点;
- 如果滑动窗口内的帧数量已经超过设定阈值,那么选择其中一个帧进行边缘化;
- 当某个帧被边缘化时,以它为主导的地图点将被移除,不再参与以后的计算。否则这个点将与其他点形成结构先验,破坏BA中的稀疏结构[10]。
在边缘化的过程,DSO维护了帧与帧间的先验信息(见EnergyFunctional::HM和bM),并将这些信息利用到BA的求解中去。
3.3 零空间,FEJ
在SLAM中,GN或LM优化过程中,状态变量事实上是存在零空间(nullspace)的。所谓零空间,就是说,如果在这个子空间内改变状态变量的值,不会影响到优化的目标函数取值。在纯视觉SLAM中,典型的零空间就是场景的绝对尺度,以及相机的绝对位姿。可以想象,如果将相机和地图同时扩大一个尺度,或者同时作一次旋转和平移,整个目标函数应该不发生改变。零空间的存在也会导致在优化过程中,线性方程的解不唯一。尽管每次迭代的步长都很小,但是时间长了,也容易让整个系统在这个零空间中游荡,令尺度发生漂移。
另一方面,由于边缘化的存在,如果一个点被边缘化,那它的雅可比等矩阵就要被固定于被边缘化之时刻,而其他点的雅可比还会随着时间更新,就使得整个系统中不同变量被线性化的时刻是不同的。这会导致零空间的降维——本应存在的零空间,由于线性化时刻的不同,反而消失了!而我们的估计也会变得过于乐观。
DSO作者提出了一个很好的例子以展现这件事情。见下图。
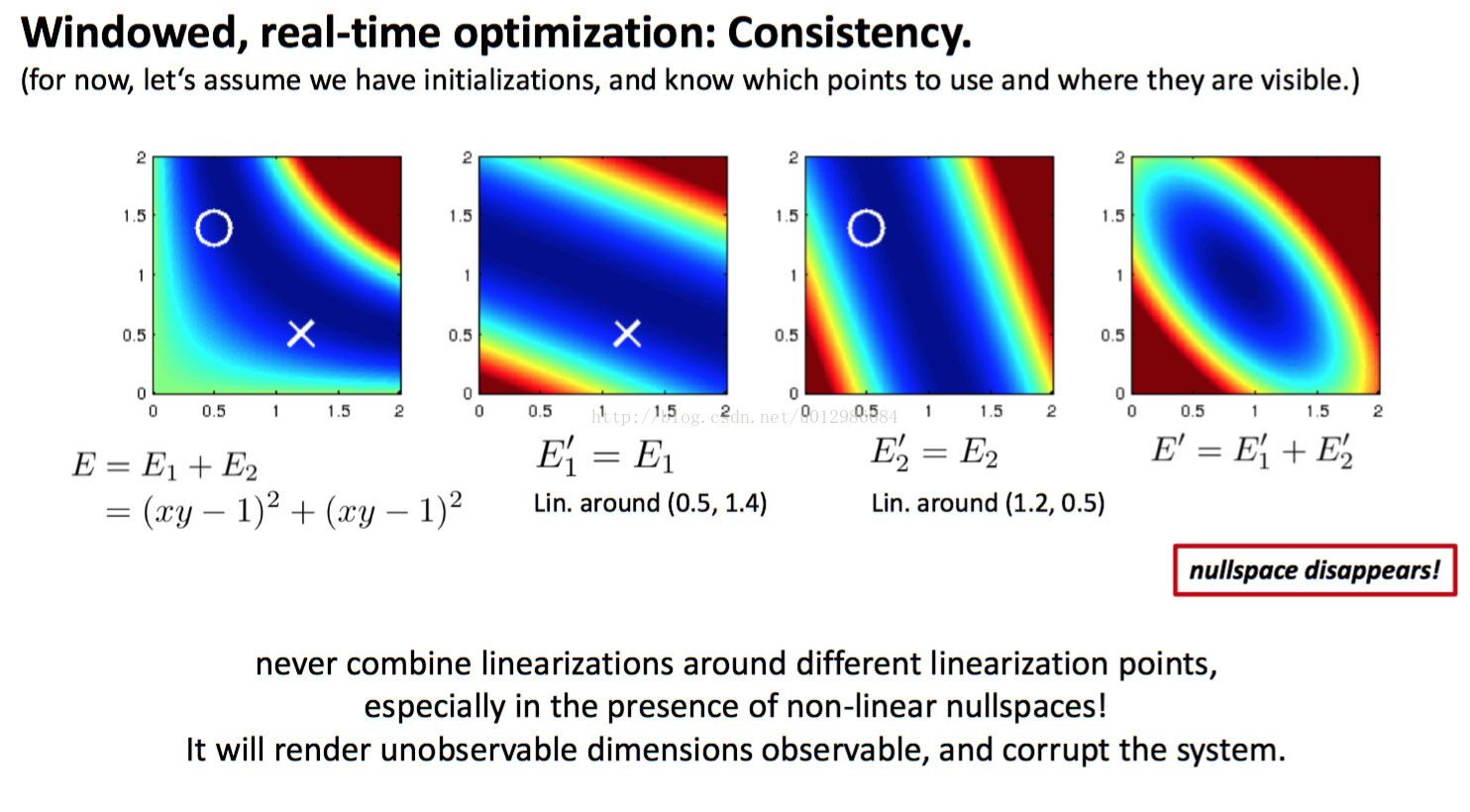
在这个例子中,我们最小化 ,那么显然
这条曲线就是优化问题的最优解,正好是一维的零空间。但是,如果
和
在不同点上线性化,那么求得的
可能会让这一维的零空间消失(如图例),这时最优解变成了一个点。
因此,在DSO实际使用时,仅在优化的初始时刻计算几何和光度的雅可比,并让它们在随后的迭代过程中保持不变,即First-Estimate-Jacobian。FEJ强制让每个点在同一个时刻线性化,从而回避了零空间降维的问题,同时可以降低很多计算量。DSO中的每个地图点,由前面定义的pattern产生8个残差项,这些残差项也会共享FEJ。由于几何和光度函数都比较光滑,实践当中FEJ近似是十分好用的。
3.4 其他零散的模块和算法
除去上述主干以外,DSO还有一些枝节上的算法,例如:
- DSO是怎么初始化的?
- DSO的CoarseTracker如何估计新帧的位姿?
- 未成熟点是如何转换到正常地图点的?
4. 光度标定
我发现已经有一些文章介绍DSO的光度标定了[11],所以我考虑不再重复介绍一遍了。如果需要的话我会补上。
5. 评述
DSO的出现将直接法推进到一个相当成熟可用的地位,许多实验已表明它的精度与鲁棒性均优于现在的ORB-SLAM2,而相比之下LSD-SLAM则显然没有那么成熟。在我自己的实物相机实验中,我发现LSD-SLAM很难一次上手即通,而DSO则鲁棒的多。
在大部分数据集上,DSO均有较好的表现。虽然DSO要求全局曝光相机,但即使是卷帘快门的相机,只要运动不快,模糊不明显,DSO也能顺利工作。但是,如果出现明显的模糊、失真,DSO也会丢失。
直接法相比传统特征点法,最大的贡献在于,直接法以更整体、更优雅的方式处理了数据关联问题。特征点法需要依赖重复性较强的特征提取器,以及正确的特征匹配,才能得正确地计算相机运动。在环境纹理较好,角点较多时,这当然是可行的——不过直接法在这种环境下也能正常工作。然而,如果环境中出现了下列情况,对特征点法就不那么友善:
- 环境中存在许多重复纹理;
- 环境中缺乏角点,出现许多边缘或光线变量不明显区域;
这在实际图像中很常见,我们以道路环境为例(取自kitti):

显然,路面上角点甚少,仅有车道线的起始/终止处存在角点,其他地方纹理不足;天空通常也没有纹理;路旁栏杆和障碍物重复纹理非常明显。这些都是特征点法必须面对的问题,所以特征点法通常只能依赖一些车辆、行人、交通告示板来确定明显的特征匹配,这会影响整个SLAM系统的稳定性。其根本原因在于:无法找到有用的匹配点、或者容易找到错误的匹配点。例如,车道线边缘上的点外观都非常相似,栏杆附近的点则由于栏杆本身纹理重复,容易出现错配。
而直接法,如前所示,则并不要求一一对应的匹配。只要先前的点在当前图像当中具有合理的投影残差,我们就认为这次投影是成功的。而成功与否,主要取决于我们对地图点深度以及相机位姿的判断,并不在于图像局部看起来是什么样子。举个例子,如果用特征法或光流法追踪某个位于边缘的像素,由于沿着边缘方向图像局部很相似,所以这个匹配或追踪的结果,可能被计算成此边缘方向的另一个点——这主要是因为图像局部的相似性;而直接法的约束则来自更为整体的相机位姿,所以即使单个点无法给出足够的信息,还可以靠其他点来修正它的投影关系,从而找到正确的投影点。
这是一把双刃剑。直接法给予我们追踪边缘、平滑区块的能力,但同时也要付出代价——正确的直接法追踪需要有一个相当不错的初始估计,还需要一个质量较好的图像。由于DSO严重依赖于使用梯度下降的优化问题求解,而它成功的前提,是目标函数从初始值到最优值之间一直是下降的。在图像质量不佳或者相机初始位姿给的不对的情况下,这件事情往往无法得到保证,所以DSO也会丢失。
这种做法一个显而易见的后果是,除非存储所有的关键帧图像,否则很难利用先前建好的地图。退一步说,即使有办法存储所有关键帧的图像,那么在重用地图时,我们还需要对位姿有一个比较准确的初始估计——这通常是困难的,因为你不知道误差已经累计到了多大的程度(所以该法对于重定位与跟踪丢失具有较差的鲁棒性)。而在特征点法中,地图重用则相对简单。我们只需存储空间中所有的特征点和它们的特征描述,然后匹配当前图像中看到的特征,计算位姿即可。
我们看到,数据关联和位姿估计,在直接法中是耦合的,而在特征点法中则是解耦的。耦合的好处,在于能够更整体性地处理数据关联;而解耦的好处,在于能够在位姿不确定的情况下,仅利用图像信息去解数据关联问题。所以直接法理应更擅长求解连续图像的定位,而特征点法则更适和全局的匹配与回环检测。读者应该明了二者优缺点的来由。
当然DSO也不是万能的。最容易看到的缺点,就是它不是个完整的SLAM——它没有回环检测、地图重用、丢失后的重定位,而这些在实际场景中往往又是必不可少的功能。DSO的初始化部分也比较慢,当然双目或RGBD相机会容易很多。如果你想要拓展DSO的功能,首先你需要十分了解DSO的代码结构。
资料与参考文献:
[1]. Engel J, Koltun V, Cremers D. Direct sparse odometry[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[2]. Forster, C.; Pizzoli, M. & Scaramuzza, D., SVO: Fast semi-direct monocular visual odometry,Robotics and Automation (ICRA), 2014 IEEE International Conference on,2014, 15-22.
[3]. Mur-Artal, R.; Montiel, J. & Tardós, J. D. ORB-slam: a versatile and accurate monocular slam system,IEEE Transactions on Robotics, IEEE,2015, 31, 1147-1163.
[4]. Bowman, S. L.; Atanasov, N.; Daniilidis, K. & Pappas, G. J. Probabilistic data association for semantic SLAMRobotics and Automation (ICRA), 2017 IEEE International Conference on,2017, 1722-1729.
[5]. Civera, J.; Davison, A. J. & Montiel, J. M. Inverse depth parametrization for monocular SLAM,IEEE transactions on robotics, IEEE,2008, 24, 932-945.
[6]. Engel, J.; Sturm, J. & Cremers, D. Semi-dense visual odometry for a monocular cameraProceedings of the IEEE international conference on computer vision,2013, 1449-1456
[7]. 高翔, 张涛, 刘毅, 颜沁睿, 视觉SLAM十四讲:从理论与实践,电子工业出版社, 2017
[8]. Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R. & Furgale, P. Keyframe-based visual-inertial odometry using nonlinear optimizationINTERNATIONAL JOURNAL OF ROBOTICS RESEARCH,2015, 34:314-334
[9]. Barfoot, T. State Estimation for Robotics: A Matrix Lie Group Approach,Cambridge University Press,2017
[10]. SLAM中的marginalization 和 Schur complement
[11]. DSO之光度标定 - 路游侠 - 博客园
[12]高翔,知乎:半闲居士
[13]dso详解 :https://zhuanlan.zhihu.com/p/29177540















 5982
5982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











