






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models
论文链接:https://arxiv.org/pdf/2503.14489
开源代码:https://github.com/Stability-AI/stable-virtual-camera

导读
新颖视图合成(Novel View Synthesis,NVS)的目标是在给定任意数量带有相机位姿的输入视图的情况下,从任意相机视角生成场景的逼真、三维一致的图像。传统方法依赖于密集的输入视图,将NVS视为一个三维重建和渲染问题,但这种方法在输入稀疏时会失败。生成式视图合成通过利用现代深度网络先验解决了这一限制,无需为每个场景捕获大量图像集,就能在不受控的环境中实现沉浸式的三维交互。
简介
我们提出了稳定虚拟相机(STABLE VIRTUAL CAMERA,简称SEVA),这是一种通用的扩散模型,给定任意数量的输入视图和目标相机,它可以创建场景的新视图。现有方法在生成大视角变化或时间上平滑的样本时存在困难,并且依赖于特定的任务配置。我们的方法通过简单的模型设计、优化的训练方案和灵活的采样策略克服了这些限制,这些策略在测试时可以跨视图合成任务进行泛化。因此,我们的样本在不需要额外的基于表示的蒸馏的情况下保持了高度一致性,从而简化了实际场景中的视图合成。此外,我们表明我们的方法可以生成长达半分钟的高质量视频,并且具有无缝的循环闭合。大量的基准测试表明,SEVA在不同的数据集和设置下都优于现有方法。
方法与模型
我们将在3.1节中描述我们的模型设计和训练策略,然后在3.2节和3.3节中描述测试时的采样过程。图4提供了系统概述。
1. 模型设计与训练
我们考虑一个“进出”的多视图扩散模型,如2.2节中所标注的。我们将这个学习问题表述为一个标准的扩散过程[21],不做任何更改。
架构。我们的模型基于公开可用的Stable Diffusion 2.1 [25],它由一个自动编码器和一个潜在去噪U型网络(U-Net)组成。遵循文献[8]的方法,我们将U型网络中每个低分辨率残差块的二维自注意力机制扩展为三维自注意力机制[26]。为了提高模型的容量,我们通过跳跃连接[27, 28]在每个自注意力块之后沿视图轴添加一维自注意力机制,使模型参数从增加到。可选地,我们通过跳跃连接在每个残差块之后引入三维卷积,将该模型进一步转换为视频模型,类似于文献[22, 29],最终模型的总参数达到15亿。当已知一次前向传播中的帧在空间上有序时,可以在推理过程中启用时间路径,以增强输出的平滑度。
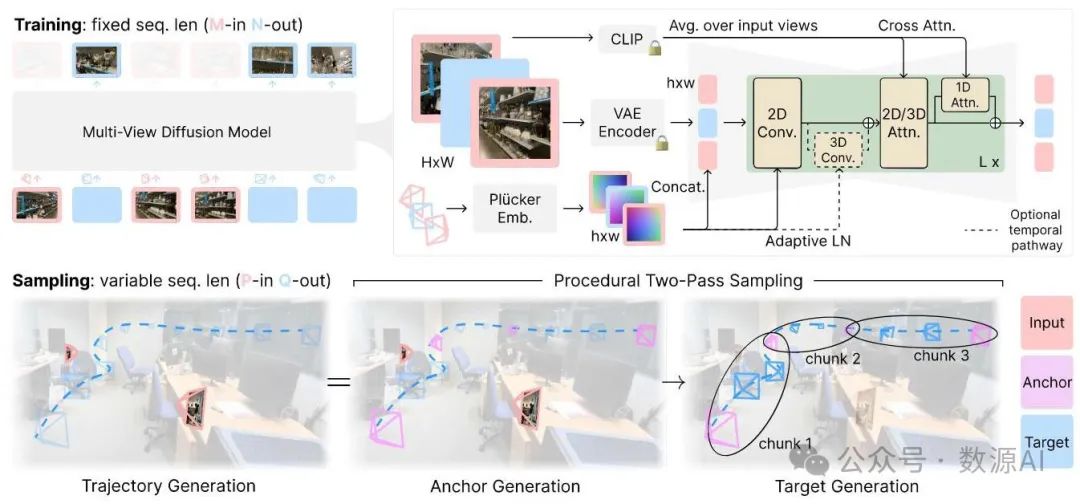
图4. 方法。SEVA以固定序列长度作为一个“进出”的多视图扩散模型进行训练,采用标准架构。它以CLIP嵌入、输入视图的变分自编码器(VAE)潜在表示以及它们对应的相机位姿作为条件。在采样过程中,SEVA可以被视为一个生成式的“进出”渲染器,可处理可变的序列长度,其中和不必等于和。为了增强生成视图之间的时间和三维一致性,特别是在沿轨迹生成时,我们提出了程序性两遍采样作为一种通用策略。
条件设置。为了将我们的基础模型微调为多视图扩散模型,我们通过拼接[8]和自适应层归一化[31]添加相机条件,将其表示为普吕克嵌入(Plücker embedding)[30]。我们对和进行归一化处理,首先计算相对于第一个输入相机的相对位姿,然后对场景尺度进行归一化,使所有相机位置都在一个的立方体范围内。对于每个输入帧,我们首先对其潜在表示进行编码,然后将其与普吕克嵌入和一个区分输入视图和目标视图的二进制掩码[8, 22]进行拼接。对于每个目标帧,我们使用其潜在表示的噪声状态。此外,我们发现通过CLIP [32]图像嵌入注入高级语义信息也很有帮助[19]。我们对第一层中额外通道的新权重进行零初始化。在我们的实验中,我们发现我们的模型可以快速适应这些条件变化,并在少至次迭代后生成逼真的图像。
训练。我们定义训练上下文窗口长度为。一个自然的目标是支持较大的,以便我们能够生成更多的帧。然而,我们发现简单的训练容易导致模型发散,因此我们采用两阶段训练方案。在第一阶段,我们以的长度、1472的批量大小对模型进行次迭代训练。在第二阶段,我们以的长度、512的批量大小对模型进行次迭代训练。给定一个训练视频序列,我们随机采样输入帧的数量和这些帧。我们发现联合采样并使用较小的下采样步长很重要,以确保足够的时间粒度,并以较小的概率(实际中使用0.2)避免错过关键过渡。在可选的视频训练阶段,我们仅使用以较小下采样步长采样的数据和512的批量大小对时间权重进行次迭代训练。在所有阶段,我们都会调整信噪比(SNR),因为在使用更多帧进行训练时,需要更多的噪声来破坏信息,这与文献的发现一致。模型使用边长为的方形图像进行训练。
2. 采样新视图
一旦扩散模型训练完成,我们可以在测试阶段将其用于广泛的新视角合成(NVS)任务。形式上,让我们考虑测试期间的一个“ 输入 输出”的新视角合成任务,其中我们会得到 个输入帧,并旨在生成 个目标帧。我们的目标是设计一种通用的采样策略,使其适用于所有 和 的配置,其中 和 不必等于 和 。
我们有两个关键发现:首先,在单次前向传播中,如果模型训练良好,预测结果在三维空间上是一致的。其次,当 时, 必须被分割成大小为 的小块,使得第 次前向传播满足 。我们将这种做法称为单遍采样。然而,除非这些前向传播共享共同的帧以在空间邻域内保持局部一致性,否则这些前向传播的预测结果将不一致。基于这些发现,我们总结了两种场景下的采样过程: 和 。
。为了简单和一致性,我们将任务纳入单次前向传播。如附录 D 所示,我们发现与零样本改变上下文窗口 相比,通过重复第一个输入图像来填充前向传播,使其恰好有 帧的效果更好。
。我们提出了程序性两遍采样方法:在第一遍中,我们使用所有输入帧 生成锚帧 。在第二遍中,我们将 分割成小块,并根据 和 的空间分布,使用 (可选地使用 )来生成这些小块。鉴于我们关注的两个任务——集合新视角合成和轨迹新视角合成——的不同性质,例如,视图顺序可用性的差异,我们为每个任务设计了量身定制的分块策略。
对于集合新视角合成,我们考虑最近邻程序性采样。我们首先基于预定义的轨迹先验生成 ,类似于文献 [8],例如,以物体为中心的场景采用 360 度轨迹,或者前向场景采用螺旋轨迹。然后,我们使用最近邻方法相对于 将 分割成小块。具体来说,第 次前向传播包括:
我们考虑了两种程序性采样策略:上述的最近邻策略,以及通过在每次前向传播中添加 的真实值 + 最近邻策略。我们发现真实值 + 最近邻策略的表现优于最近邻策略,因此默认使用该策略。在没有轨迹先验的情况下,我们恢复使用单遍采样。实际上,采用最近邻锚点可以在一定程度上提高定性一致性。
对于轨迹新视角合成,我们考虑插值程序性采样。我们首先通过以步长 均匀跨越目标相机路径,生成目标帧的一个子集作为 。然后,我们将 的其余部分生成为这些锚点之间的片段:
由于模型的输入是有序的,我们可以利用时间权重来进一步提高平滑度(第4.3节)。同样地,通过将与拼接可以实现插值(interp)。我们发现插值方法足够稳健,并将其选为默认选项。插值策略在时间平滑度方面明显优于其他方法(例如,单遍处理或真实值(gt)+最近过程采样)。
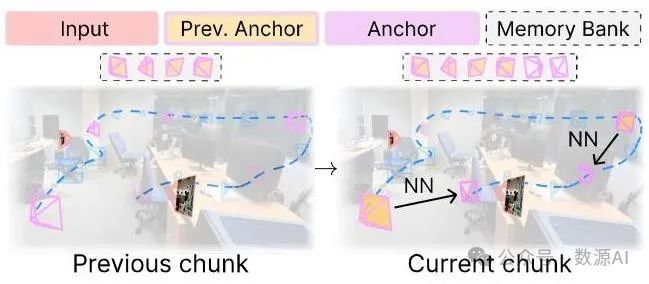
图5. 当时的锚点生成。我们引入了一个由先前生成的锚点视图及其相应相机位姿组成的内存库。对空间邻域的查找有助于提高长期的3D一致性。
3. 针对大和的缩放采样
接下来,我们研究当时的两种特殊情况:和。在这里,我们为第一遍的锚点生成进行了定制设计,而保持第二遍的目标生成不变。
。在半密集视图模式下(例如,),我们将上下文窗口长度进行零样本扩展,以便在锚点生成的单遍处理中容纳所有个输入视图和锚点视图。根据经验,甚至可以扩展到数百,而生成输出的真实感不会严重下降。我们发现,只要输入视图覆盖了场景的大部分区域,扩散模型在这种情况下具有良好的泛化能力,将任务从生成主要转变为插值。在稀疏视图模式下(即,),与我们在时的发现相比,我们观察到由于的零样本扩展导致了类似的性能下降。详细讨论请参考第4.5节。
。当目标视图的数量很大时,例如在大集合新视图合成(NVS)或长轨迹新视图合成中,即使是锚点在第一遍处理中也会被分块处理,导致锚点不一致。为此,如图5所示,我们维护一个先前生成的锚点视图的内存库。我们通过从内存库中检索空间上最近的锚点来自回归地生成锚点,类似于上面为第二遍处理引入的最近策略。在第4.4节中,我们表明,在长距离3D一致性方面,特别是对于困难轨迹,这种策略明显优于长视频文献[24]中重用先前生成的时间上最近的锚点的标准做法。
实验与结果
我们针对一系列设置使用单个模型,发现SEVA模型在三个标准下具有良好的泛化能力(表1)。我们涵盖了不同的新视图合成任务(集合新视图合成和轨迹新视图合成),并研究了一个特别感兴趣的任务——长轨迹新视图合成。我们还涵盖了不同的输入模式(单视图、稀疏视图和半密集视图)。第4.5节对几个关键属性进行了讨论。
1. 基准测试
数据集、划分以及输入视角的数量。我们考虑(1)物体数据集,例如OmniObject3D [35](OO3D)和GSO [36];(2)以物体为中心的场景数据集,例如LLFF [37]、DTU [38]、CO3D [39]和WildRGBD [40](WRGBD);以及(3)场景数据集,例如RealEstate10K [41](RE10K)、Mip - NeRF 360 [42](Mip360)、DL3DV140 [43](DL3DV)和Tanks and Temples [44](T&T)。我们考虑了广泛的输入视角数量,范围从稀疏视角到半密集视角,以评估模型的输入灵活性。为了与基线模型进行全面且严谨的比较,我们考虑了先前工作中使用的不同数据集划分,且输入视角配置相同,除非指定为我们的划分(O)。这些划分包括4DiM [12](D)、ViewCrafter [9](V)、pixelSplat [16](P)、ReconFusion [7](R)、SV3D [19](S)和Long - LRM [18](L)中使用的划分。例如,RE10K数据集上的4DiM [12](D)划分是在所有6711个测试场景中选取128个,且视角数量为。
小视角与大视角的新视角合成(NVS)。对所有数据集、划分和输入视角配置进行全面分析,揭示了多种不同的实验设置基准。为了更好地评估模型的生成能力和插值平滑度(第2.1节),我们建议根据和之间的差异,将这些设置分为两组——小视角新视角合成和大视角新视角合成。差异较小的小视角新视角合成强调与附近输入视角的插值平滑度和连续性,而差异较大的大视角新视角合成则要求模型从输入观测中生成显著的未见区域,主要评估模型的生成能力。完整列表见表格7。数据集、划分、输入视角数量的详细选择以及差异测量方法见附录C。
基线模型。我们考虑了一系列专有模型,包括ReconFusion [7]、CAT3D [8]、4DiM [12]、LVSM [11]和Long - LRM [18]。我们还考虑了各种开源模型,包括SV3D [19]、MVSplat [17]、depthSplat [45]、MotionCtrl [46]和ViewCrafter [9]。如第2.2节所述,这些基线模型涵盖了基于回归和基于扩散的方法,为比较提供了一个全面的框架。
2.集合新视角合成(Set NVS)
在本节中,鉴于集合新视角合成是一个已经被广泛探索的任务,我们专注于将我们的模型与先前的工作进行比较。
定量比较。输入视角和目标视角按照先前方法中使用的划分来选择。目标视角的顺序不做保留,即。我们使用标准指标峰值信噪比(PSNR)、学习感知图像块相似度[48](LPIPS)和结构相似性指数[49](SSIM)。由于篇幅限制,这里仅展示PSNR,其余指标推迟到附录D.2。根据经验,我们的方法在LPIPS上显示出更大的性能提升,反映了我们结果的照片级真实感。
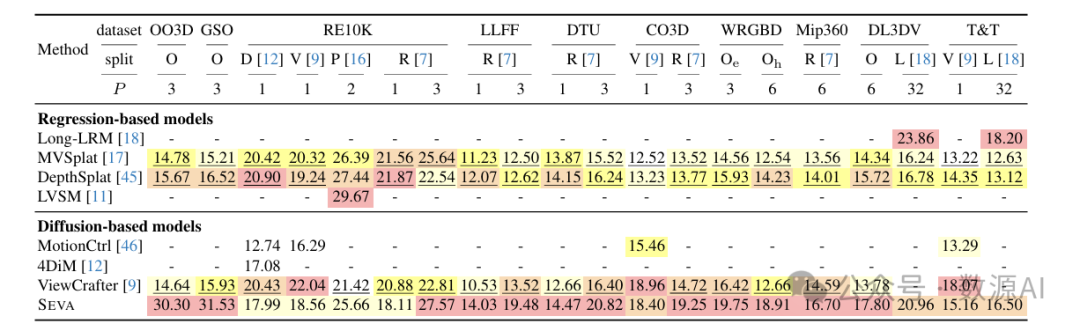
对于小视角集合的新视角合成(NVS),表2显示,SEVA在大多数分割中都取得了最先进的成果。在稀疏视角情况(即)下,当时,SEVA在不同数据集上表现出色。例如,在LLFF数据集上,当时,PSNR性能提升了6.0 dB。在半密集视角情况(例如)下,尽管SEVA并非专门为此设置而设计,但它出人意料地优于专门模型[18]。例如,在数据集上,SEVA仅比最先进的方法[18]落后。在物体数据集和上,与所有其他方法相比,SEVA实现了显著更高的最先进PSNR值。
值得注意的是,对于RealEstate [41]数据集上的小视角集合新视角合成(NVS),在单视角情况(即)下,SEVA的表现不佳。这个问题源于模型中的尺度模糊性,原因有两个:(1)训练期间模型总是接收单位归一化的相机参数;(2)模型在多个具有不同尺度的数据集上进行训练。这个挑战在RE10K数据集上最为明显,该数据集以平移运动为主。此外,缺少第二个输入视角消除了任何尺度相对性。为了解决这个问题,对于所有的结果,我们将相机归一化的单位长度从0.1到2.0进行遍历(训练期间使用2.0),为每个场景选择最佳尺度。在分割且的情况下,我们观察到扩散模型落后于在小视角插值方面具有优势的基于回归的模型。SEVA通过比最先进的基于扩散的模型提升来缩小了这一差距。在分割且的情况下,SEVA的优势明显,比之前的最佳结果高出1.9 dB。值得注意的是,ViewCrafter在V分割上表现出色,因为它能够处理宽高比图像,因此比处理方形图像的其他模型有更多的输入像素。由于大部分信息像素位于中心位置,ViewCrafter在V分割上在CO3D数据集上的优势减弱。
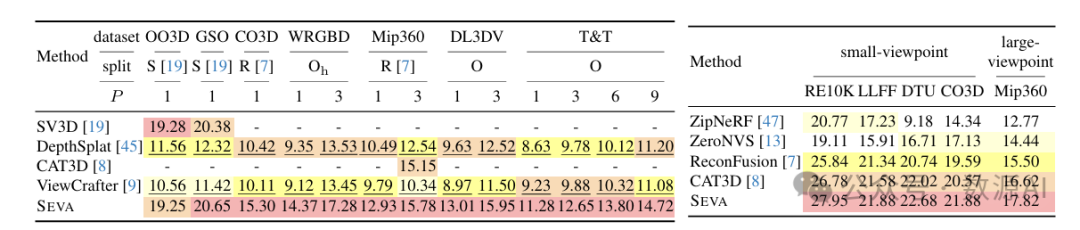
对于大视角集合的新视角合成(NVS),表3显示,SEVA的量化优势在这里更加显著,揭示了当相机跨越较大空间范围时,SEVA在生成能力方面的明显优势。在Mip360数据集上,当时,SEVA比之前最先进的方法CAT3D [8]的PSNR提高了0.6 dB。在像DL3DV和T&T这样具有不同输入视角配置的更具挑战性的场景中
在这些情况下,SEVA取得了明显的性能领先。在OO3D和GSO上使用时,尽管SEVA和先前的最先进方法[19]的性能相似,但我们从定性上观察到我们的模型输出的图像更具真实感且更清晰。
定性比较。图6上半部分展示了与各种基线方法的定性比较。对于小视角集合NVS,SEVA在最佳尺度下的输出与真实值具有理想的对齐度,同时在细节上更具真实感。与RE10K的P分割上的LVSM [11]相比,SEVA生成的图像更清晰,这也证实了较低的PSNR是由尺度模糊而非插值质量引起的。在DL3DV上使用与Long - LRM [18]相比时,也有类似的趋势。对于大视角集合NVS,我们在DL3DV上使用与DepthSplat [45]进行比较。当视角变化过大时,Depth - Splat无法产生合理的结果,并且在整体视觉质量上有所欠缺。

图6. 不同数量输入视角下集合NVS(上)和轨迹NVS(下)的最先进方法比较。我们与开源方法——ViewCrafter [9](VC)和DepthSplat [45](DS)——以及专有方法进行比较,包括LVSM [11]、Long - LRM [18](LLRM)、4DiM [12]和CAT3D [8]。当输入包含多个视角时,我们将它们排列成使得最接近目标的视角位于每个集合的顶部。
3D重建比较。为了能够与先前的工作进行直接的定量比较,我们采用了[8]中描述的少视角3D重建流程。对于每个场景,我们首先根据相同的输入视角沿着不同的相机路径生成8个视频,总共生成720个视角。然后,将输入视角和生成的视角都提炼成3DGS - MCMC [50]表示,而无需点云初始化。我们在提炼过程中优化相机参数并应用LPIPS损失[51]。最后,我们在测试视角上渲染提炼后的3D模型,并在表4中报告性能。SEVA显示出持续的性能领先。
3. 轨迹新视角合成(Trajectory NVS)
在本节中,鉴于轨迹新视角合成是一个尚未充分探索的任务,我们将重点进行定性演示。然后,我们将从定性和定量两方面与先前的方法进行比较。

定性结果。图2展示了定性结果,说明了不同复杂度的轨迹,这些轨迹具有不同数量的输入视角,涵盖了多种类型,包括以物体为中心的场景级、场景级、真实世界以及来自图像扩散模型[25]的文本提示等。
在单视角模式(即)下,我们手动设计了一组常见的相机移动/效果,例如360度注视、螺旋移动、平移、放大、缩小、推拉变焦等。我们观察到SEVA能够推广到广泛的图像,并展示出准确的相机跟随能力。令人兴奋的是,我们的模型能够产生具有推拉变焦效果的合理输出(图2第二行)。在图2第三行的FERN场景中,我们的模型展示了即使在靠近或穿过物体时也能生成合理输出的能力——尽管从未针对此类场景进行过明确训练。这凸显了我们模型的表现力。图15至图18提供了在4种类型图像上广泛的相机移动扫描结果。
在输入视角较少的稀疏视角模式(即)下,我们观察到SEVA对真实世界图像表现出很强的泛化能力,并且能够灵活适应不同数量的输入视角。输出形成了一个平滑的轨迹视频,只有轻微的时间闪烁,显示出其在视角之间进行平滑插值的能力。在图2最后一行,我们的模型在轨迹末端(输入观测中未见过的区域)生成了合理的结果,展示了其强大的生成能力。在半密集视角模式(即)下,我们同样发现SEVA能够令人惊讶地生成平滑的轨迹视频,且伪影最少。请查看网站获取视频结果。
定性比较。图6的底部面板展示了与多种基线方法的定性比较。在单视图模式(即 )下,我们将其与 和CAT3D [8] 进行比较。我们发现我们的模型输出的结果更具照片真实感且更清晰,特别是在以物体为中心的场景的背景区域。由于 模型仅在RE10K数据集上进行训练,其输出往往带有卡通风格且过于简单。在输入视图较少的稀疏视图模式(即 )下,我们与CAT3D进行比较,发现我们的模型展现出更具照片真实感的纹理,尤其是在背景部分。对于ViewCrafter [9] 中考虑的起始 - 结束视图插值( ),我们的模型在轨迹上产生了平滑的过渡,尽管在相邻帧之间会出现轻微闪烁,特别是在高频细节显著的区域。
定量比较。对于每个划分,我们使用与新视角合成(NVS)集合中相同的输入视角。我们将每个场景的所有帧用作目标视角,使它们形成一个平滑过渡的轨迹视频,即 。我们使用峰值信噪比(PSNR)作为指标,并在表5中与基线方法进行比较。
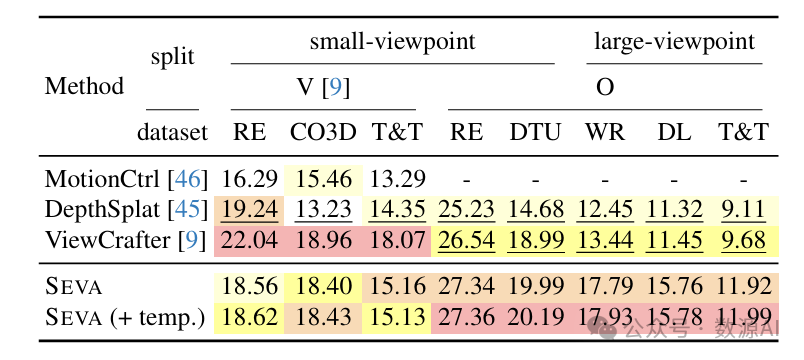
对于小视角轨迹新视角合成(NVS),表5比较了SEVA和基线方法在峰值信噪比(PSNR)方面的表现。在 划分且使用 的情况下,SEVA相对于其他方法表现更优。ViewCrafter的性能优势主要归功于其在高分辨率图像上的训练。对于使用 的大视角轨迹新视角合成(NVS),SEVA的一致性创造了新的最优结果。应用时间路径进一步提升了性能并改善了平滑度,这表明了门控架构的优势。
对两次通过过程采样的消融实验。我们进行了一项消融研究,比较了默认的插值过程采样与单次通过采样以及其他过程采样策略。
从定量角度来看,除了评估单个视角的峰值信噪比(PSNR)外,我们还使用相同视角的3D渲染的PSNR和SED 分数来评估3D一致性。为了计算SED分数,我们首先应用尺度不变特征变换(SIFT) [54] 来检测两幅图像中的关键点。对于第一幅图像中的每个关键点,我们确定其在第二幅图像中对应的对极线,并测量其与匹配点的最短距离。此外,我们报告了来自VBench [52] 的运动平滑度(MS),这是一个用于评估视频生成模型中时间连贯性的基准。如表6所示,插值过程采样相对于其他方法具有明显优势,时间路径的整合进一步强化了其优越性。
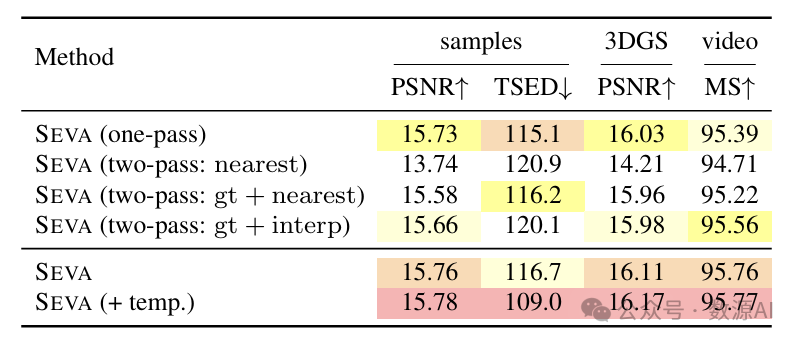
图7中的定性比较表明,单次通过采样会引入明显的时间闪烁和突然的视觉变化。相比之下,插值采样产生的过渡最平滑,优于gt + 最近采样,并减轻了明显的闪烁。

图7. 时间质量。来自Mip - NeRF360 [42] 的BONSAI场景中渲染的新相机路径的垂直切片展示了相邻视角间的时间质量。单次通过或gt + 最近过程采样会导致明显的闪烁,而插值过程采样可确保时间上的平滑渲染。
4. 长轨迹新视角合成(NVS)
图8展示了长达1000帧的长轨迹新视角合成(NVS)的定性演示。当相机围绕电话亭旋转多圈时,每一圈中来自相似视角的生成视图可能会有很大差异,因为它们在时间上相隔较远。通过记忆库维护先前生成的锚点,SEVA在长轨迹新视角合成(NVS)中实现了强大的3D一致性,例如电话亭前面的建筑和后面的植被。与使用先前生成的时间最近锚点相比,使用空间最近锚点显示出明显优势。记忆机制在先前的工作 中已被同时探索,利用了显式的中间 表示,如DUSt3R [56] 预测的密集点云。相比之下,我们的模型对野外数据表现出更强的鲁棒性和泛化能力,因为它不受DUSt3R输出质量的限制,而DUSt3R的输出质量在其训练域之外的数据(如文本提示图像)上往往不可靠。
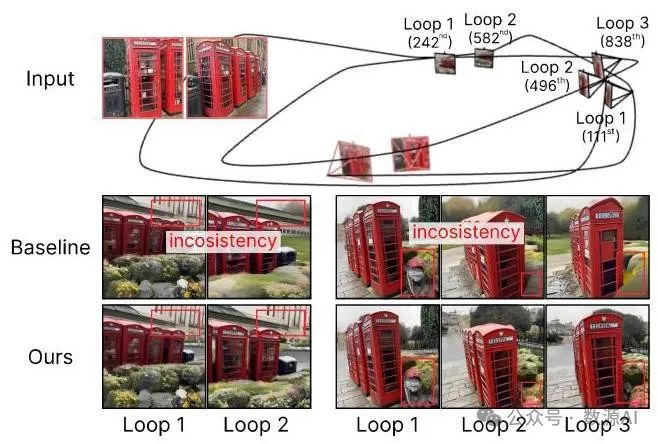
图8. 长距离3D一致性。我们可视化了相机路径围绕电话亭场景循环三次的样本。与使用时间邻居查找(基线方法)相比,使用记忆库中的空间邻居查找(我们的方法)显著提高了视图一致性,并减少了不同循环中重复位置的伪影。
结论
我们提出了 虚拟相机表格(SEVA),这是一种用于新视角合成的通用扩散模型,它在支持灵活的输入和目标配置的同时,平衡了大视角变化和平滑插值。通过设计一种无需三维表示的基于扩散的架构、一种结构化的训练策略和一种两遍程序采样方法,SEVA在各种新视角合成(NVS)任务中实现了三维一致的渲染。大量的基准测试证明了它优于现有方法,并且对现实场景具有很强的泛化能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









